基与Python的森林资源监测数据分析与可视化研究
2022-05-07冷鸿天杨雨渐杨天淼张占忠
冷鸿天,杨雨渐,杨天淼,张占忠
(云南省林业调查规划院,云南 昆明 650051)
21世纪以来,林业的发展方向逐渐由木材生产向生态建设转变。通过调整监测目标、扩充监测内容、优化监测方法和应用高新技术等做法,森林资源监测水平和服务能力得到进一步提升[1]。为推进生态文明建设,筑牢国家西南生态安全屏障,维护生物安全和生态安全,践行绿水青山就是金山银山的理念,推动绿色循环低碳发展,实现人与自然和谐共生,满足人们日益增长的优美生态环境需要,努力把云南建设成为全国生态文明建设排头兵、中国最美丽省份,云南省通过开展森林督查、森林资源管理“一张图”和森林资源年度监测等工作,加强森林资源管理,建立和完善森林资源统一的监测和管理制度[2]。
数据分析是为了发现数据规律的过程,利用数学和计算机手段来处理和挖掘收集来的数据中包含的信息[3]。由于技术水平的发展,森林资源监测图斑越来越精细,与此同时,数据量也越来越大,特别对于省或更大尺度的监测区需要采用先进的技术方法更加方便快捷地对海量数据进行分析,以适应各种不同需求。Python便是一种可以快速对海量数据进行分析和展示的重要工具。
自1991年诞生以来,Python已成为最受欢迎的动态编程语言之一。Python是一种动态语言,与静态语言相比,其具有自由、灵活、简洁等特征,依托其活跃的社区和大量强大的类库可以快速完成各种使用场景的任务。在过去的10年,Python从一个边缘或“自担风险”的科学计算语言,成为数据科学、机器学习、学界和工业界软件开发最重要的语言之一[4]。
1 环境搭建与数据准备
进行数据分析必要的Python类库主要有Pandas,Geopandas,SQLite3,Numpy和Matplotlib等(表1)。Anaconda是一个免费开源的Python语言的发行版本,用于计算科学(数据科学、机器学习、大数据处理和预测分析),Anaconda拥有进行数据分析的必要类库,也可以简化软件类库管理系统和部署。在Anaconda软件中没有集成Geopandas包,需要进行自行安装。Anaconda中还包含Jupyter Notebook,其是一个支持运行40多种编程语言的交互式笔记本,便于创建和运行数据分析的代码,而且还可以用单元格的方式逐块运行代码,更有利于进行数据分析。
海量地理数据常用的存储方法有文件地理数据库(GDB)、Microsoft SQL server数据库和开源的SQLite数据库等。由于文件地理数据库的查询必须使用闭源收费的Arcpy包,虽然Microsoft SQL server数据库更强大,查询速度更快,但是Microsoft SQL server数据库安装包很大,过于臃肿,因此决定选择轻量开源的SQLite数据库,SQLite数据库集成在Python中,不需要重新安装。
选取的数据为2020年度云南省森林资源监测数据,包含约650万个图斑,数据量较大。根据《云南省2020年森林资源监测操作细则》中要求的成果统计表,选择统计其中较为复杂的各类土地面积统计表为例,表头如表2所示。

表1 数据分析主要类库[4-5]Tab.1 Major class libraries of data analysis[4-5]
2 数据分析与统计
2.1 数据加载
云南省的森林资源监测数据量很大,如果全部使用Pandas进行读取会占用大量的内存空间,所以需要使用数据库进行存储,利用SQL查询语句选择需要使用的数据。首先使用SQLite3.connect连接SQLite数据库,然后通过Pandas包中的read_SQL_query将SQL语句查询分组后的结果存储在DataFrame数据结构中,极大地压缩了读入Pandas中的数据量,减轻了内存占用和运算压力。代码如下:
import sqlite3
with sqlite3.connect(r’C:UsersAdministratorDesktopSLJC2020.sqlite’) as conn:
df=pd.read_sql_query(
’’’select SHENG as 省,SHI as 州市,XIAN as 县,LD_QS as 土地所有权,SEN_LIN_LB as 森林类别,SHI_QUAN_D as事权等级,STQW as 生态区位,
DI_LEI as 地类,sum(MIAN_JI) as 面积
from XZ02

表2 各类土地面积统计
group by SHENG,SHI,XIAN,LD_QS,SEN_LIN_LB,SHI_QUAN_D,STQW,DI_LEI
order by SHENG,SHI,XIAN,LD_QS,SEN_LIN_LB,SHI_QUAN_D,STQW,DI_LEI’’’
,con=conn)
2.2 数据清理
由于森林资源监测数据并不是汉字,而是代码,其中数据也有很多空格和空值混用的情况,这会对数据分析造成不利影响,需要对数据进行清理和代码转换。按照《云南省2020年森林资源监测操作细则》,很多数据分类与统计表中所需要的分类并不相同,因此需要通过选择、赋值和新加列的方法对数据进行重新分类。通过读取csv文件中的编码映射为字典,使用replace可以将统计表中的代码统一替换为汉字,同时也可以对数据中一些空值和空格等难以分辨但又影响分析结果的数据噪声进行处理。将代码替换为汉字的代码如下:
import csv
mydict={}
with open(r‘path’) as code:
reader=csv.reader(code)
code_dict={rows[0]:rows[1] for rows in reader}
replace(code_dict)
tb[’统计单位’]=tb[’统计单位’].replace(code_dict)
2.3 数据重塑
将数据整合为一个DataFrame后,进行数据重塑,以形成统计表的骨架。其中最重要的是pivot_table方法,其功能与Excel中的透视表一样,选择行和列,对聚合的数值进行求和等操作,多个层级的数据会形成多级索引,以符合规定的表头设计。核心代码如下:
tb=pd.pivot_table(df[df.地类!=’非林地’],values=’面积’,/
index=[’省’,’州市’,’县’,’土地所有权’,’森林类别’,’事权等级’],/
columns=[’DILEI_0’,’DILEI_1’,’地类’],aggfunc=’sum’)
2.4 按层级汇总
将数据进行透视表操作后,如果选择多个行和列会形成多级索引。对多级索引进行求和操作即可对所选择的层级进行求和,即对当前层级的汇总,也叫分类汇总。如对列的第一层级进行汇总,其代码为:tb.sum(level=0,axis=1)。将按层级汇总好的数据根据表的设计规则修改列名为总计、合计或小计,并将索引用MultiIndex.from_tuples方法改为符合表的设计规则的多级索引,方便后期实现完整表格的合并。
2.5 数据合并
将按层级汇总后的分表、国土总面积表和总表合并。由于按层级汇总后顺序和表头不变,所以用concat方法直接进行拼接。而土地总面积因索引名称不同,要用merge方法的关键字进行连接。如分层级统计出省、市、县的数据和与其对应的土地总面积与总表进行合并,可以使用如下代码:
pd.concat([sheng,zhoushi,xian]).merge(tdzmj,on=’统计单位代码’)
2.6 表格优化
合并完成后的表头顺序与设计表头顺序不符,由于表头和索引都是字符串,且是复杂的多级索引,不能简单地使用排序功能实现设计的顺序,使用Category数据类型的效果并不理想,只能采取在索引和列名前增加序号的方法进行排序,最后再将序号去掉。统计完成的表格可以直接用to_excel方法生成Excel表格。
3 数据可视化
3.1 扇形图
扇形图适用于表示每一分量所占总量的比例。扇形图可以很好地反映云南省每种森林类别占总量的百分比。将数据按森林类别使用groupby方法进行分组后,即可使用Pandas自带可视化模块进行扇形图绘制(图1)。代码如下:
tb.plot.pie(subplots=True,autopct=’%.2f’,figsize=(8,8),title=’云南省森林类别百分比图’)

图1 云南省森林类别占比Fig.1 Percentage of forest categories in Yunnan Province
3.2 柱状图
柱状图可以用于表示每个表示字段的多少。利用柱状图表示森林类别权属数量特征可以用Pandas自带可视化模块进行绘制。但如果需要对数据绘制一些复杂的可视化效果,或者对可视图形进行更精细的设置,就需要使用Matplotlib库进行绘制(图2)。叠加柱状图的代码如下:
import matplotlib.pyplot as plt
plt.bar(d1.columns.values,d1.loc[’国有’],label=’国有’)
plt.bar(d1.columns.values,d1.loc[’集体’],bottom=d1.loc[’国有’],label=’集体’)
plt.legend()
ymax=d1.loc[’国有’].max()+d1.loc[’集体’].max()
plt.ylim(0,ymax)
plt.ylabel(’面积 单位:万公顷’)

图2 云南省森林类别权属Fig.2 Forest category ownership of Yunnan Province
3.3 地图绘制
对于有位置信息的地理数据,可使用Python绘制专题地图。Geopandas包便是一个用于对地理信息数据进行可视化的一个很好的工具。如果使用全省林地小班数据进行聚类操作再计算森林覆盖率,由于需要进行图形运算,效率会很低,且数据量太大,要进行分块操作。所以要先统计出每个县的覆盖率,并以县为关键字连接到云南省行政区划地图上,用Geopandas中的plot方法简单设置大小和配色后即可完成绘制(图3),地图中颜色越深,表示森林覆盖率越高。地图绘制代码如下:
import geopandas as gpd
gdf=gdf.merge(tb,on=’XIAN’)
fig, ax = plt.subplots(1, 1)
gdf.plot(column=’FGL’, ax=ax,cmap=’OrRd’,legend=True,figsize=(100, 100))
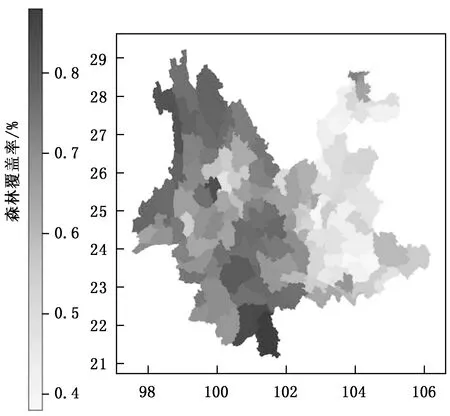
图3 云南省各县森林覆盖率分布Fig.3 Distribution of forest coverage in counties of Yunnan Province
4 结论与讨论
实践证明,使用Python可对森林资源监测海量数据进行快速分析和统计,Python语法结构简单的特性使其可及时地适应不同需求。对于全省上百万条数据,从运行程序到输出统计表的时间只需十几秒,且90%的时间用于SQL语句查询。如果将查询结果用于多张统计表将会极大地提升统计效率。重要的是Python代码可以复用,稍作修改便可使用在各种需求的分析统计中。Python作为一种跨平台的编程语言,将分析方法完整化和系统化后,可以进行界面设计和软件打包,并将软件运行在各种不同的平台。也可以使用Python的web框架,将分析工具部署在服务器上,通过网页端提供更多的服务。
