基于实体模糊识别的高校心理咨询对话系统
2022-04-21章亮,徐戈,陈芳
章 亮,徐 戈,陈 芳
(1.闽江学院实验室与设备管理处,福建 福州 350108;2.闽江学院计算机与控制工程学院,福建 福州 350108;3.闽江学院学生工作部,福建 福州 350108)
0 引言
2014年以来,随着数据量爆炸式的增长和深度学习模型的引入,对话系统从规则编写时代过度到由数据驱动的深度学习时代,其有效性和实用性得到了广大研究者的肯定。学术界将对话系统的研究主要分为任务型和非任务型两类[1]。在工业界具有代表性的对话系统有微软小冰(xiaoIce)、亚马逊Alexa、苹果Siri、小米小爱同学等。它们已经逐渐进入人们的生活,帮助用户处理相对简单的任务,以提升用户体验[2]。
2020年初,新冠疫情席卷而来,全国高校转向以网络形式开展线上授课,严重地打乱了学生们的正常学习,由此引发的恐惧、焦虑、抑郁等心理问题更加凸显。无法得到及时有效的线下心理咨询和开导,导致更为严重的心理失衡状态和心理应激反应[3]。我国出台的《健康中国行动(2019-2030年)》[注]《健康中国行动(2019-2030年)》国发〔2019〕13号.国家卫键委,2019年7月。文件指出高校应该积极为学生提供心理咨询服务,监控学生心理健康。因此高校应该提供在线预约心理咨询服务、在线测评相关量表(抑郁症、焦虑症)等,加强对学生心理问题的疏导和监控,结合现代科学技术,设计开发一套针对高校的心理咨询对话系统以适应不断变化的就学环境。
任务型对话系统的优化集中在分词、意图识别、对话管理及对话生成算法上,而忽视了由于用户错误的输入导致的实体识别准确率低下的问题,同时现有的实体纠错算法内存占用大、效率低、准确率依旧有待提升。考虑到心理咨询过程中用户输入的不确定性,在意图识别过程中直接使用阈值作为判断用户输入是否属于已知意图的方法过于简单,且正确率较低的问题,本文构建了一套基于实体模糊识别的高校心理咨询对话系统。它包含以下功能:1)预约线下心理咨询师;2)量表测评并反馈;3)常规QA问答。本文的创新点在于:1)提出一种实体模糊识别算法,纠正错误实体,提升实体命中率;2)提出一种构建噪声数据的方案,匹配系统未知意图;3)设计并实现一套应用于高校心理咨询的对话系统。
1 相关研究与技术
任务导向型对话系统以完成特定任务为主要目标,适用于定制化场景。例如教室预约、酒店/机票预订、心理咨询预约等。通过人工制定相关语料完成数据的冷启动问题,任务导向型对话系统可以细分为基于管道框架的对话系统和基于端到端框架的对话系统。
基于管道框架的对话系统将用户输入到结果输出过程中的各个部分结合,数据在不同模块间流转都有明确的输入与输出,优点在于:1)有效降低对话系统的耦合程度,易于理解;2)各模块任务明确,界限清楚,方便独立优化;3)降低模块之间的误差传播[4]。而重点研究3个部分:自然语言理解(NLU)、对话管理、对话生成。自然语言理解(NLU)是理解用户输入的核心部分[5]。使用RNN建立实体提取模型存在长时依赖问题,命名实体识别一般使用Bi-LSTM和CRF[6],其中CRF解决了Bi-LSTM输出独立性,Bi-LSTM又可学习到上下文信息,获得更准确的结果。近年来,由于BERT模型的提出,Wu等人提出了ToDo-BERT模型,该模型显著提高了意图分类的准确率,有效缓解任务型对话系统的数据量少的问题[7]。
对话管理包含对话状态跟踪和对话策略选择两个子任务,根据用户输入历史记录更新当前对话状态,提供对话策略,以便抉择最佳回复或动作。近年来结合transformer的对话管理进展迅速,Tuan等人提出基于BERT的DST模型,该模型的参数数量不会随着本体的大小而增加,模型可以在动态变化下运行,最后应用知识蒸馏的方法压缩模型并取得显著效果[8]。Huang等人提出了MERET模型,是一种对话状态生成器,通过一种梯度强化学习进修微调[9]。Xu等人使用知识图谱提供Action集合的先验知识,通过图形方式(graph-grounded)解决了策略选择问题[10]。
对话生成是将对话管理决策出的回复或动作转换为表层用户可理解的语言,或具体设备执行的指令。Elder等人提出一种限制响应的数据增强方法,虽然牺牲回复的多样性,但增强了对话系统的可靠性[11]。Baheti等人通过多种管道结构来提高生产响应的流畅性和语义的正确性,最后引入BERT对结果进行排名,降低了QA对话的不可靠性[12]。
心理咨询过程中用户输入具有不可预测性,心理咨询领域要求对话回复更严谨、准确,因此对意图识别准确率要求更高。本文在训练数据构建阶段引入噪声构建方法,增加了噪声意图,结合阈值来判断未知意图,提高意图识别的准确率。从基于管道的任务型对话系统框架出发,结合高校心理咨询对话数据集,将实体纠错算法应用到高校心理咨询对话领域,提出了基于实体模糊识别的高校心理咨询对话系统,为验证系统有效性,对实体模糊识别算法和系统整体进行测评,实验表明实体纠错正确率的第一和第二组实验结果分别为94.6%和93.3%,内存占用48.8 MB以及响应速度0.3 ms,显著优于现有算法,且引入噪声数据构建方法在低阈值0.2时可提高未知意图识别率52%。
2 算法设计
2.1 噪声数据构建
高校心理咨询的对话内容属于敏感内容,因此对回复的质量要求较高。为了识别未知意图的能力,有效提高对话系统意图识别的正确率,设置了噪声意图。构建噪声意图的样例数据流程图如图1所示。

图1 噪声数据构建流程图Fig.1 The flow of noise data construction
1)构建乱序噪声数据集:为了更强的鲁棒性,尽量收集包含字母、字符、数字等词语的文本,通过jieba分词后将词打乱构建大型噪声库,词之间用空格隔开,例如:“杰瑞 们 的 你 a b 台 那 哪 c 好 没什么 你 新人 1 你 的 23 的…”。
2)获取所有意图下的样例数据长度:获取本文所构建的高校心理咨询所有已知意图下用于训练的样例句子长度。
3)根据样例数据长度,构建高斯分布。
4)根据高斯分布构建噪声样例数据:从噪声库中顺序取出对应数量的词组成句子,并保证构建的噪声样例数据量与已知意图样例数据量一致。若噪声数据库取到最后一个词,可从噪声数据库起始位置循环取词。
2.2 实体模糊识别算法
鉴于现有的基于CRF等实体提取算法无法提取用户错误输入中的实体,本文设计了实体模糊识别算法,主要包含两个模块(图2):1)模板生成;2)拼音模糊识别。

图2 实体模糊识别算法结构图Fig.2 The structure of entity fuzzy recognition algorithm
模板生成模块在模型训练阶段完成,主要负责将训练数据转换成拼音模糊识别模块所需的实体和词条信息,并保存至内存中,实时更新。拼音模糊识别模块负责接收自然语言理解(NLU)模块的结果P0,判断P0是否进行实体的模糊识别,纠正用户输错的实体。全语料模板TP=[tp0,tp1,…,tpm]共m个模板,其中第k个模板由式(1)给出:
tpk=[regk,ik,ek],
(1)
其中,regk是根据训练语料库中含实体的训练数据自动生成的正则表达式。ik为意图名称。ek对应第k个模板中训练数据的实体列表。例如“我来自[计算机](academy)学院,性别是[男](gender)”是训练语料库中的一条样例数据,意图为academy_and_gender。则regk为:我来自(.*)学院,性别是(.*);ik为:academy_and_gender;ek则代表[academy,gender]。模板生成模块不仅需要构建TP,还需构建实体和词条的关系,得到词条的全拼、模糊拼音、声调信息。
全拼即词条的全拼音表示;声调采用《汉语拼音方案》(1958)中规定的5种,以数字形式表示:阴平对应1;阳平对应2;上声对应3;去声对应4;轻声对应0。本文所提出的模糊拼音采用的对应关系:zh对应z;ch对应c;sh对应s;ang对应an;eng对应en;ing对应in。

定义1用户输入U0,经过NLU模块后得到P0,可根据式(2)给出:
P0=[i0,e0,w0,U0],
(2)
其中i0指意图名称,e0指得到的实体列表,w0指与实体列表对应的词条列表。进入实体模糊识别之前需进行P0的有效性判断。
定义2判断NLU输出P0的有效性用f表示,由式(3)给出:

(3)
当P0中的i0在模板tpk中,且P0中实体个数与tpk中的实体个数相同,则f为True,即P0有效,否则P0无效,进入拼音模糊识别模块。
定义3获取候选模板C_tps由式(4)给出:
C_tps=g(U0,TP),
(4)

定义4计算两个词的相似度分数score
计算候选模板中用户输入与训练语料中实体的词条相似度,本文从字数、全拼、模糊拼音、正确汉字数、相同声调数这5个维度设计了式(5)作为两个词的相识度。

(5)


(6)

(7)

(8)

(9)
其中,same函数判断输入的两个参数是否相同,相同为1,不同为0。α1、α2、α3、α4是超参数,拼音模糊识别算法伪代码如图3所示。

图3 拼音模糊识别伪代码Fig.3 Pseudo code of Pinyin fuzzy recognition

3 高校心理咨询对话系统实现
基于实体模糊识别的高校心理咨询对话系统整体框架如图4所示。用户层为用户的操作终端;接入层采用标准Restful API,便于各类终端接入;代理层是心理咨询对话系统各部件相互沟通的中间部件,通过代理Agent控制数据流按照管道pipeline指定方向流转;AI引擎层是对话系统的核心,包含各子模块的算法,同时与数据库进行交互,提供算法运行时所需知识库数据;数据层用于存放高校心理咨询QA问答数据、量表数据、多轮对话等训练数据,系统内部数据流图如图5所示。

图4 高校心理咨询对话系统整体框架图Fig.4 Overall framework of college psychdogical counseling dialogue system

图5 高校心理咨询对话系统内部数据流图Fig.5 Internal data flow diagram of college psychdogical conseling dialogue system
高校心理咨询对话系统的实现过程包含训练过程和预测过程,图5中的虚线框代表了训练过程。分词模块采用jieba分词,添加高校心理相关词汇,保证分词的准确性,只需要从模型保存与提取模块中提取分词模型即可。特征抽取、实体检测、意图识别、实体模糊识别和对话管理需要结合高校心理咨询领域数据进行训练,将训练后的模型保存到模型保存与提取模块,用于预测阶段对模型的提取。本系统不仅结合高校心理咨询领域数据,还设计自定义Action模块优化对话系统在高校心理咨询领域的应用能力,其中包含:1)对大学生心理咨询量表等用户输入校验;2)对不同量表测评后得分的计算和推送建议;3)对具有严重心理问题学生的预警并转人工服务;4)对未知意图的回复响应等。心理咨询阶段由用户主动发起,并根据图5管道模型中实线箭头引导的方向流转,经过各个模块后返回给用户。
3.1 心理QA问答
心理QA问答主要包含:高校学校心理咨询中心相关信息,例如办公地址、服务时间、咨询师介绍等;还包含其他心理咨询常见问题,例如:什么是抑郁、如何治疗抑郁症等、强迫症有哪些表现、焦虑症会传染吗、焦虑是如何引起的、如何与舍友相处融洽等。
3.2 心理咨询预约
心理咨询预约提供预约心理咨询师的功能,收集学生信息,避免线下资料重新填写。为验证实体模糊识别算法效果,本文将与以下算法进行正确率对比:基于BERT相似度算法[13]、基于Electra纠错算法[14]、基于Pycorrect纠错算法[15]、基于BERT的中文字符纠错算法[15]。实验发现,式(5)中的超参数设置α1=3;α2=2;α3=1;α4=0.8最为合理。
在构建的包括“咨询师姓名”“学院”“咨询心理类型”“专业”等内容的150个高校心理咨询常用实体数据集中进行实体纠错测试,共进行两组实验。第一组任意抽取所有词条中一个字改成同音字或相似字,第二组任意抽取所有词条中词语改成同音词或相似词,实验结果如表1所示。表1结果表明所提出的实体模糊识别算法在实体纠错中表现明显优于其他算法,两组实验中正确率最高为94.6%,由于实体数据集中部分字是多音字,例如“音乐学院”中的“乐”,全拼有“yue”和“le”两种,当“音”字输错为“英”时,纠错失败,因为“英乐学院”中“乐”的拼音是“le”而不是“yue”。基于BERT相似度算法直接将词条的词向量对比,并选择最相似词作为纠正词,随着词条中字数错误数越多,正确率也越低,因此第一组正确率明显要高于第二组正确率。基于Pycorrect纠错算法和基于BERT的中文字符纠错算法虽无需训练就具有在句子中直接纠正词语的能力,可当词语本身无问题时,无法根据已知实体进行纠正,因此第二组结果明显比第一组效果差。
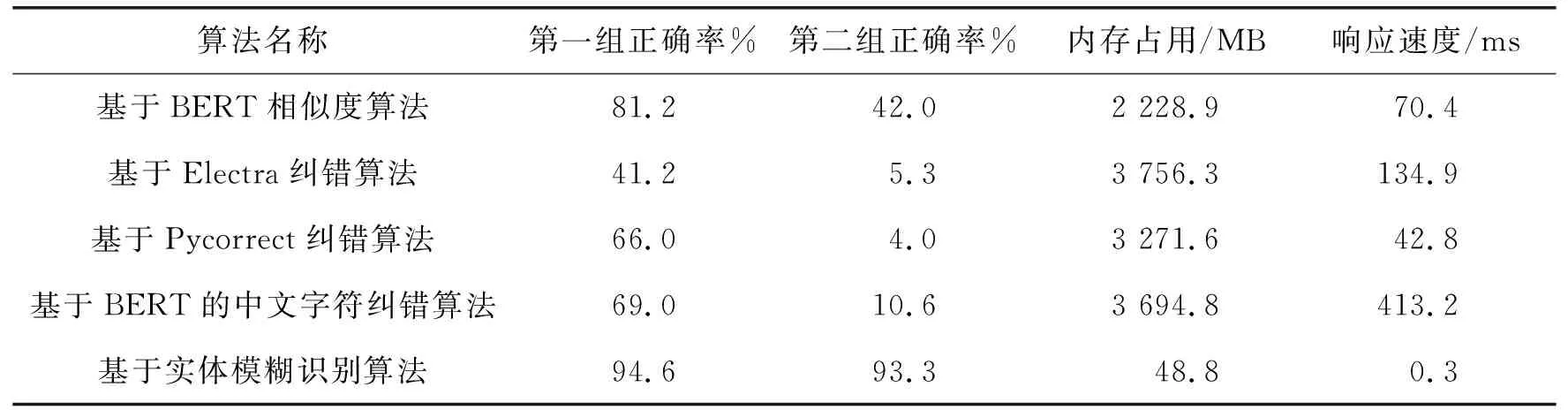
表1 各算法在不同维度性能对比
在实际心理咨询预约中向学生收集个人相关信息时得到的回复信息一般为词槽所填内容。当学生使用语音作为输入,语音转文字易出现同义词错误、同义字错误、音调错误等等。基于实体模糊识别算法通过对拼音、模糊拼音、音调等维度对实体进行纠错,能极大提升实际用户体验效果,因此两组实验都较其他算法更好。
为了进一步验证所提出的算法不仅在正确率上较其他算法具有更强的纠错能力,同时对比了各算法的内存占用和响应速度两个维度。实验结果表明基于实体模糊识别算法无论是内存占用和响应速度上都明显优于其他对比算法。高校心理咨询领域的实体的数量和生成的模板信息有限,因此较其他基于深度学习框架的算法相比内存占用具有天然的优势,且较低的算法启动开销也使得响应速度极大的提升。在对话系统的部署过程中,由于基于深度学习框架的算法参数和结构越复杂,所需使用的内存、耗费的CPU和GPU资源都将大大提升,因此具有较小内存占用和快速的响应速度能降低硬件条件,便于推广和实际应用。
本系统实际运行效果见图6。本文所设计的信息收集部分内容过多,故将未展示的信息使用“..//其他信息收集”代替,从图6中可得到当用户输入“南”“机空学院”“人机关系”这些错误实体时,实体模糊识别算法能保证多轮对话流程正常运行,并在最后给出的总结时,将正确词条“男”“计控学院”“人际关系”展示给用户,也证明了实体模糊识别算法的有效性。

图6 实体模糊识别算法运行效果图Fig.6 Running effect diagram of ertity fuzyy recognition
3.3 量表测评
为了及时了解学生心理状态,本文将心理咨询中常用的量表功能加入系统中。以抑郁症量表为例,实验如图7所示。实验中“..//其他信息收集”代表量表的其他相关问题,最后根据自定义Action计算得分,并反馈用户。

图7 抑郁症量表测试Fig.7 The test of depression scale
3.4 系统整体测评
本文对所设计的系统进行整体测评。采用的实验配置如下:CPU为AMD Ryzen 7 3800X;显卡为NVIDIA GeForce RTX2060 SUPER,内存16G。实验数据来自采集的高校心理咨询相关数据,经过1 000次常见问答测试,平均系统响应时间1.6 s,在网页对话等场景下属于用户可接受的范围。为了验证所提出的噪声数据构建方法,系统整体测评时分成两组:第一组不包含噪声数据及其意图;第二组包含噪声数据及其意图。在保证系统所有算法参数一致的前提下调整阈值,当所识别的意图中最高得分都低于设置的阈值时,将对话转为未知意图类别,所使用的数据为100条闲聊数据,验证未知意图的命中率,结论如表2所示。

表2 噪声数据构建方法对比结果
从表2中可以看出第二组(包含噪声数据构建方法)在低阈值0.2时,未知意图正确率明显高出第一组(不包含噪声数据构建方法)52%,且随着阈值的增加,第一组实验结果都低于第二组实验结果,特别是当阈值取0.2时第二组实验就取得81%的正确率,说明噪声数据构建方法的有效性。当意图越多,通过softmax层得到的每个意图的概率就越小,因此阈值设置较低时正确率越高说明系统的可用性越强,用户体验也越好。系统的实体纠错率可参考表1,第一组正确率和第二组正确率都大于90%,说明了实体纠错效果符合预期,后续的改进会考虑多音字这类特殊情况,以进一步提高系统整体实体纠错率。
4 结论
本文设计并实现了基于实体模糊识别的高校心理咨询对话系统,利用噪声数据的构建方法增强了系统对未知意图的识别能力。实体模糊识别算法主要包含模板生成和拼音模糊识别模块,通过自定义Action,针对高校心理咨询领域进行优化。对比了目前较为流行的文本纠错算法,实验表明,所提出的实体模糊识别算法在第一组和第二组实体纠错实验中正确率分别高于其他对比算法13.4%和51.3%、内存占用48.8 MB以及响应速度0.3 ms明细优于其他比较算法。功能上,高校心理咨询对话系统添加QA问答功能、心理咨询在线预约功能以及量表测试功能,最后测评系统整体性能,进一步验证了基于实体模糊识别高校心理咨询对话系统的有效性。
