基于有序多任务学习的司法二审判决预测方法
2022-04-19韩晓晖王文同宋连欣刘广起崔超然尹义龙
韩晓晖,王文同,宋连欣,刘广起,崔超然,尹义龙
(1.齐鲁工业大学(山东省科学院)山东省计算中心(国家超级计算济南中心),山东 济南 250014;2.山东省计算机网络重点实验室,山东 济南 250014;3.山东大学 软件学院,山东 济南 250101;4.山东财经大学 计算机科学与技术学院,山东 济南 250014)
0 引言
近年来,随着以裁判文书为代表的司法大数据不断公开,如何利用机器学习、自然语言处理等技术来赋予计算机理解法律文本、学习法律知识、解决法律问题的智能逐渐成为司法和计算机交叉领域的研究热点。相关技术既可以为法官、律师等专业人员提供辅助参考,提高他们的工作效率,也可以为缺乏法律知识的非专业人士提供低成本的法律援助,因而具有重要的应用价值和社会意义。
司法判决预测(Law Judgement Prediction,LJP)是司法智能研究的主要方向之一。相关研究大都将LJP视为分类问题求解,以判决结果的各种可能性作为类别,以案件的事实描述等信息作为分类模型的输入,输出类别的预测值。目前,研究者已经在胜诉/败诉预测、适用法律条文(以下简称法条)预测、刑事案件的罪名及刑期预测等LJP任务上取得了不错的进展[1-7]。
在已有LJP工作中,二审判决预测任务尚未受太多关注。该任务旨在基于一审审判情况及上诉材料(如新发现的事实、上诉理由等)来预测二审程序的判决结果。二审判决预测一方面可以帮助上诉人预估自己的上诉收益;另一方面也可以辅助一审法院提前排查其判决中的不足[8]。针对此任务,Katz等[9]提出一种随机树模型来预测美国上诉法院是否会改变下级法院的判决,但该模型使用的部分特征是针对美国法律体系的特点设计的,如法官、法院的历史行为等,因而不具有良好的普遍适用性。
由于涉及两阶段的审判程序,二审判决预测是一项具有挑战性的任务。首先,司法审判是对案件事实的一种回溯性认知活动,二审程序通过再一次审查和认知案件事实来衡量一审判决在事实认定、适用法律、定罪量刑方面是否正确,从而作出维持原判、改判或发回重审的裁决[8]。因此,二审判决结果实质上取决于一、二审法院对案件事实的认知是否一致。如何捕捉两审法院的认知异同,是二审判决预测的关键问题和难点所在。其次,尽管深度学习模型在LJP任务中已表现出较好的预测性能,但模型的黑盒特性使得预测不具有很好的可解释性,往往难以被司法专业人士认可。部分研究通过在模型中引入注意力机制等方式来定位案件事实中对结果贡献大的部分,以此作为对预测原理的一种解释[10],但这种方式通常难以很好地表达二审法院改变一审判决的原因。因此,如何提升可解释性是二审判决预测面临的另一个挑战。
针对上述挑战,本文提出了一种基于有序多任务学习的二审判决结果预测方法SIJP-SML(Second Instance Judgement Prediction framework based on Sequential Multi-task Learning),该模型通过两个时序依赖的多任务学习部分对从一审到二审的完整审判逻辑建模。前序多任务学习模型对一审程序建模,以捕捉一审法院对案情的认知;后序多任务学习模型对二审程序建模,在捕获二审法院案情认知的基础上融合两审法院的认知来预测二审判决结果。本文的主要贡献包括以下三点:
(1)提出的SIJP-SML以案情和上诉理由为输入,通过端到端的方式完成二审判决预测,无须人工设计特征,普遍适用性更好。
(2)为增强预测的可解释性,SIJP-SML在多任务学习中引入了法院观点生成任务,在对二审判决结果预测的同时,模拟生成法院对判决的解释。
(3)在6万余份二审裁判文书数据上构建的实验证明了SIJP-SML的有效性和合理性,其F1值达到63.9%,优于所有基线方法。
本文接下来第1节简述并分析现有的相关研究工作;第2节给出二审判决预测任务的形式化定义;第3节介绍本文提出的SIJP-SML;第4节使用真实二审裁判文书数据集对SIJP-SML进行实验分析;第5节总结全文并讨论未来可能的研究工作。
1 相关工作
1.1 司法判决预测
LJP研究最早可追溯到20世纪60年代前后。初期的研究探讨了使用数学和统计学模型来预测判决结果的可能性,并在小规模的数据集上取得了一定的成功[11-15]。之后,出现了一些基于规则的司法预测专家系统[16-17],但规则的质量严重依赖于其制定者对法律的理解程度,并且随着规则数量的增加,规则之间的冲突也愈发严重。
随着机器学习技术的发展,研究者开始将LJP任务作为一个自动分类问题来求解。起初,一些研究尝试从案件信息中提取浅层文本特征,并使用SVM、随机森林等经典的分类模型来预测判决结果。如Lin等[18]使用了21种法律标签作为特征;Aletras等[19]、Sulea等[20]使用了n-gram特征。由于浅层特征的语义表示能力有限,这类方法的性能和泛化能力往往较弱。
近期,得益于基于深度学习的自然语言处理技术的突破,越来越多研究者使用卷积神经网络(Convolutional Neural Networks,CNN)、门控循环单元(Gated Recurrent Unit,GRU)、长短时记忆网络(Long Short-Term Memory,LSTM)等深度神经网络构建LJP模型,在利用上述模型对案件事实进行编码的基础上,预测民事判决结果[1]、判决适用法条[2-3]、刑事案件的罪名[4-5]和刑期[6-7]等,获得了比SVM、随机森林等分类模型更好的性能。许多研究还利用预测任务之间的互补性,基于多任务学习对两个以上的任务进行联合建模,使它们相互促进,提高彼此的性能。如刘宗林等[21]提出了一种罪名和适用法条的联合预测模型,通过融合案情语义编码表示和罪名关键词向量,提升易混淆罪名的预测精度。Li等[22]提出一种多通道注意力神经网络模型MANN,来对罪名、适用法条和刑期进行联合预测。Xu等[23]提出一种基于“法条蒸馏”的注意力网络模型LADAN,在对法条进行社群划分的基础上使用图神经网络来学习易混淆法条之间的细微差别,进而利用学习到的差异来构建适用法条、罪名、刑期的联合预测框架。Zhong等[24]认为司法判决的各子任务之间存在先后顺序,因此提出一种基于拓扑的多任务学习模型TOPJUDGE,用有向无环图表示子任务之间的依赖,以此确定任务的学习顺序。Yang等[25]在该工作的基础上考虑了后续任务的预测结果对前序任务输出的验证作用,提出一种多视角双反馈神经网络MPBFN。
在已有LJP研究中,仅少数工作关注了二审判决预测任务。Katz等[9]提出一种随机树模型来预测美国上诉法院的判决结果,但该模型使用了部分针对美国法律体系设计的特征,如法官、法院的历史行为等,因而不具有很好的普适性。本文提出将SIJP-SML模型以案情和上诉理由为输入,通过一种有序多任务学习框架对一、二审程序的完整审判逻辑进行建模,预测过程以端到端的形式进行,普适性更好。
1.2 判决预测可解释性
由于许多机器学习模型的黑盒特点,预测的不可解释性一直是制约LJP技术被广泛接受和应用的瓶颈问题。针对此问题,Jiang等[26]在构建罪名分类器时,使用深度强化学习从输入的文本中提取简短、易读且具有决定性意义的片段作为理据,为预测结果提供了一种“反省解释”。Ye等[10]提出一种带注意力机制的序列到序列模型(Sequence to Sequence,Seq2Seq),根据案件的事实描述生成具有罪名区分性的解释文本。Yang等[27]在罪名预测模型中引入判决解释生成步骤来提高预测的可解释性。受该项工作启发,本文提出将SIJP-SML引入法院观点生成作为子任务,并进一步通过注意力机制在法院观点生成过程中融入上诉理由的影响。
2 问题定义
本文通过在刑事二审裁判文书中抽取一、二审相关的文本内容作为学习语料来对提出的SIJP-SML进行训练。首先给出一份刑事二审裁判文书d的形式化表示如式(1)所示。
d=[f1st,r1st,v1st,p2nd,f2nd,r2nd,v2nd]
(1)
其中:
(1)f1st为一审程序认定的案件事实,包括犯罪行为、犯罪结果、犯罪工具等信息。
(2)r1st为一审判决结果,可包括罪名、刑期、适用法条等。由于罪名和刑期是在事实认定的基础上依据法律条款确定的,为简化问题,本文只关注适用法条集合l1st。
(3)v1st为一审法院观点,是一审法院对判决作出的解释性说明。
(4)p2nd为当事人依法向二审法院提出的不服原审判决的上诉理由。
(5)f2nd为二审法院认定的案件事实,其中可能包括新发现事实fnew,即f2nd=[f1st;fnew]。
(6)r2nd为二审判决结果,包括二审对一审结果作出的裁决y∈{0,1}(其中y=0表示“维持原判”,y=1表示“改判/发回重审”)(1)由于在司法实践中,改判和发回重审的裁决标准有一定重合,本文将二者视为一类看待,详见《刑事诉讼法》第二百三十六条。及二审适用法条集合l2nd,即r2nd=[y,l2nd]。
(7)v2nd为二审法院观点,是二审法院对判决作出的解释性说明。
通常,完整的d只有在二审程序完成后才能获得,即对于二审判决预测任务来说,输入只有一审情况[f1st,r1st,v1st]、上诉理由p2nd和新发现事实fnew,目标输出为[r2nd,v2nd]。定义1形式化描述了二审判决预测任务。

(2)
3 方法
本文提出的SIJP-SML方法(图1)通过两个时序依赖的多任务学习部分来对一审到二审的完整审判逻辑进行建模。前序一审判决模型M1st和后续二审判决模型M2nd均使用编码层将输入的文本进行编码后传递给各子任务。M1st和M2nd的子任务中均包括一个适用法条预测任务和一个法院观点生成任务来引导模型对案情认知。在此基础上,M2nd进一步加入一个二审判决预测子任务来预测二审结果。下面从编码层开始详细介绍SIJP-SML方法的细节。
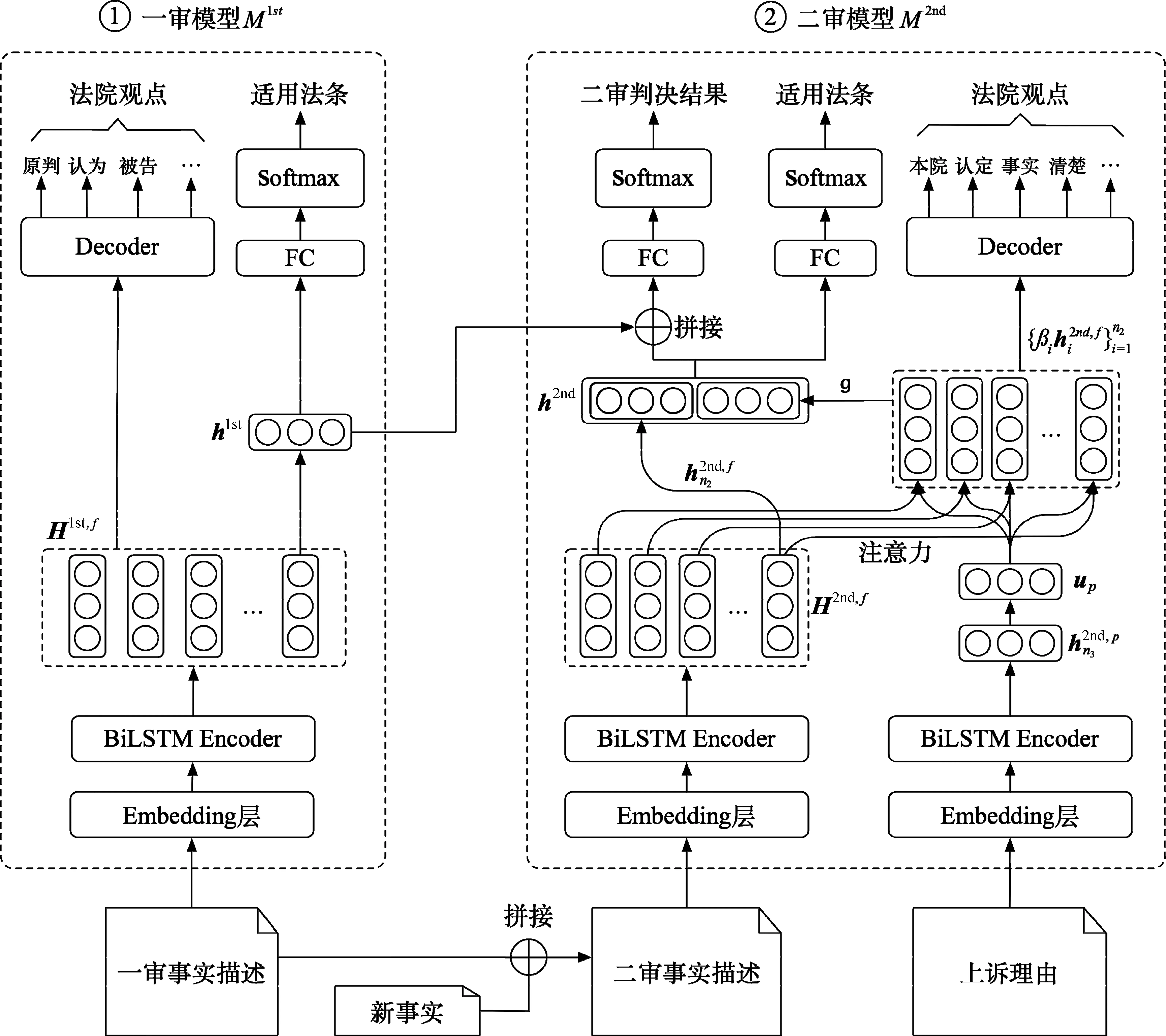
图1 SIJP-SML框架示意图
3.1 编码层
很多模型可以用来对案情描述等文本进行编码表示,如双向长短时记忆网络(Bi-directional Long Short-Term Memory,BiLSTM)、GRU、CNN、BERT(Bidirectional Encoder Representations from Transformers)、GPT(Generative Pre-Training)等。尽管BERT、GPT等大规模预训练模型在很多自然语言处理场景中展现出强大的能力,但有研究指出BERT因长度限制需要对普遍较长的案情描述进行截断,导致在司法文本处理中表现一般[28]。此外,使用案情描述这类长文本对BERT、GPT进行fine-tuning所需的计算资源和时间开销也非常大。考虑到编码器的选择并不是本文关注的重点,因此在SIJP-SML中,采用了在LJP研究中使用较多且性能较好的BiLSTM。
由于一、二审判决模型的编码过程不同,以下分别进行介绍。
3.1.1M1st编码层

3.1.2M2nd编码层

(3)

(4)
其中,Wf,p为权重矩阵。则受注意力影响之后的序列编码向量表示g通过式(5)计算:
(5)

3.2 适用法条预测任务

(6)

(7)

3.3 法院观点生成任务

(8)


(13)
其中,ni为第i个训练案例中一审或二审法院观点的词汇数量。
3.4 二审判决预测任务

(14)
对应的损失函数如式(15)所示。
(15)

3.5 模型训练
SIJP-SML的学习目标是最小化有序多任务学习框架的总体损失L,L由各子任务的损失加权融合得到:
(16)

3.6 预测
4 实验与分析
本节通过在真实二审裁判文书数据集上构建实验来分析SIJP-SML的性能。所有的实验均在一台配置为双路32核Intel Xeon CPU/256G内存/12GB显存TITAN XP×2的服务器上完成。
4.1 实验数据集
本文使用的实验数据集收集自中国裁判文书网(2)https://wenshu.court.gov.cn,共包含61 236个刑事案例的二审裁判文书,其中维持原判的50 776例,改判或发回重审的10 460例。在所有的案例中,共涉及618项罪名、15 756项法条。参照Zhong等[24]的工作,本文过滤掉不常见的法条,只关注出现频率不少于100的法条,共计345条。对于数据集中的每份裁判文书,使用正则表达式提取其中的“一审案情”“一审法院观点”“一审适用法条”“上诉理由”“二审案情”“二审法院观点”“二审适用法条”“二审判决结果”部分作为训练语料。在实验中,每一类别的70%作为训练集,10%作为验证集,20%作为测试集。
4.2 实验设置
本文首先使用百度中文词法分析器(Lexical Analysis of Chinese,LAC)(3)https://github.com/baidu/lac对裁判文书进行分词,然后使用Word2Vec对词汇进行向量化,词向量的维度设为200,整个数据集的词汇量为135.2万。SIJP-SML模型中BiLSTM的隐层维度设为256。在SIJP-SML模型的训练过程中,batch的大小设为50,学习率为0.003,dropout值为0.5。
本文使用宏观精确率(Macro-Precision,MP)、宏观召回率(Macro-Recall,MR)和宏观F1值(Macro-F1,F1)作为模型性能的评价测度,计算如式(17)~式(19)所示。
其中,TP、FP、FN分别为预测结果中真正例、假正例、假负例的个数。
4.3 基线方法


TextCNN[31]: 该模型对输入的词向量序列使用CNN进行编码,通过过滤器(filter)从输入中获得语义特征,经过一个全连接层后,由sigmoid()函数输出二审判决结果的预测值。过滤器窗口的大小设为[3,4,5],每个过滤器窗口100个feature map,采用ReLU(Rectified Linear Units)作为激活函数。
Seq2Seq[32]: 该模型使用一个LSTM编码器和一个LSTM解码器对输入文本向量序列进行编码和解码,基于学习到的隐藏状态向量使用一个全连接层和sigmoid函数输出二审判决结果的预测值。
HAN(Hierarchical Attention Network)[33]: 该模型使用BiGRU获得词汇级别和句子级别的注意力来对文本进行嵌入表示,然后分别经过一个多层感知机和一个全连接层后,由sigmoid()函数输出二审判决结果的预测值。
TOPJUDGE[24],(4)https://github.com/thunlp/TopJudge: 基于拓扑的多任务学习模型,该模型使用有向无环图来描述子任务之间的依赖关系。本文将二审判决预测任务添加为原始TOPJUDGE模型中最终任务的后续任务。
在TextCNN、Seq2Seq、HAN和TOPJUDGE的训练过程中,词向量维度、学习率、dropout、batch的大小均与4.2节SIJP-SML的设置相同。
4.4 实验结果与分析
SIJP-SML与基线方法的实验结果如表1所示。

表1 SIJP-SML与基线方法性能比较
从表1中可以看出:
(1)在二审判决预测任务上,基于深度学习的方法依然优于基于浅层文本特征的方法。TFIDF+SVM在各项评测指标上的性能均低于其他方法,印证了基于CNN、LSTM、GRU等深度神经网络的编码器能够更好地捕捉案件事实描述中丰富的语义信息,使得预测的效果得到提升,这与大部分已有LJP研究的实验结果一致。
(2)在基于深度神经网络的单任务预测模型中,基于LSTM的Seq2Seq方法比TextCNN、HAN整体性能要好。尽管Seq2Seq的MP值低于TextCNN,但其MR和F1值均高于后者,其中F1值较TextCNN有11.83%的提升,主要原因是: 案件的事实描述文本通常较长,由于LSTM能够更好地建模词汇序列的长距离依赖,因此表现得更好一些。尽管HAN在词汇级编码的基础上又进行了句子级别的编码,但其整体性能要略低于Seq2Seq。分析可能的原因是: 影响二审是否会改变一审判决的因素往往在于案件的细节,而词汇级的表示学习更能捕捉文本的语义细节,将语义表示进一步抽象到句子级别反而会降低预测的性能。
(3)基于多任务学习的方法的性能优于单任务学习的方法。TOPJUDGE虽在MP指标上低于TextCNN和Seq2Seq,但由于其考虑了多任务之间的共性和依赖性,在综合性能上高于其他的基线方法,其F1值较TextCNN、Seq2Seq和HAN的提高分别为15.5%、3.28%和5.66%。
(4)SIJP-SML在所有的方法中获得了最好的综合性能。尽管其MP值略低于TextCNN、MR值略低于TOPJUDGE,但F1值却远高于其他方法。相较于基线方法中综合性能最好的模型TOPJUDGE,SIJP-SML的F1值有14.1%的提升。这表明SIJP-SML通过有序多任务学习框架对一审到二审的完整审判逻辑进行建模,比将二审判决预测直接视为一个单审判阶段的LJP任务效果更好,证明了SIJP-SML的模型结构的合理性。
4.5 消融实验
为了进一步验证SIJP-SML中针对上诉理由的注意力机制及整个有序多任务学习框架的重要性,本文对SIJP-SML进行了消融实验,具体结果如表2所示。

表2 SIJP-SML模型消融实验结果
其中,除SIJP-SML之外的各模型定义如下:

SIJP-SML-att: 在SIJP-SML的M2nd中只使用f2nd作为输入,不考虑上诉理由的影响。
由表2可见,SIJP-SML在所有评价测度上的性能远高于M1stM2nd先独立学习一、二审的认知向量再求向量相似度的方式。这表明,SIJP-SML基于有序多任务学习对两审程序按时序依赖关系进行联合建模的方式更符合二审判决时的裁决逻辑,因而达到了更好的预测性能。与SIJP-SML-att相比,SIJP-SML在MP、MR和F1测度上的提升分别为23.53%、14.3%和35.41%。分析原因发现,在SIJP-SML的二审认知向量学习的过程中,通过注意力机制来纳入上诉理由的影响,能够指导模型更加聚焦于二审事实中影响判决的关键要素,进而提高了预测的准确性。综上,有序多任务学习框架和针对上诉理由的注意力机制都对SIJP-SML的性能提升有正面影响。
4.6 法院观点生成分析
为了直观地分析SIJP-SML中法院观点生成任务对提升预测可解释性的帮助,本节首先分别以二审判决结果为“维持原判”和“改判/发回重审”的案例为例,列举了SIJP-SML生成的法院观点,见表3和表4。在案例1(表3)中,被告人的罪名为“贩卖毒品罪”,上诉理由为“量刑过重”,请求法院“从轻处罚”;在生成的一审法院观点中,准确覆盖了判处“贩卖毒品罪”的理据“贩卖”“其”“毒品”,并且包含“从轻处罚”的依据“如实”“供述”“犯罪”“事实”,与真值中提及的依据一致;在生成的二审法院观点中,包含了维持原判的依据“上诉”“理由”“不能”“成立”。在案例2(表4)中,被告的罪名为“交通肇事罪”,上诉理由为“量刑过重”“请求缓刑”;在生成的一审法院观点中,包含了定罪的理据“重大”“交通”“肇事”“死亡”等关键词汇,并成功地生成了真值中描述的“从轻处罚”依据“投案自首”,但是未能包含“不宣告缓刑”的依据;而在生成的二审法院观点中,成功地捕捉到了改判缓刑的关键要素,即“上诉人”获得了“被害人”(亲属)的“谅解”。

表3 法院观点生成案例1

表4 法院观点生成案例2
可见,生成的法院观点内容覆盖法院观点真值的内容越多,越有助于提升预测的可解释性。因此,本文进一步分析了生成的法院观点词汇对法院观点真值中词汇的覆盖率情况(去除停止词),如式(20)所示。

(20)
图2给出了测试样本的覆盖率分布情况。通过分析发现,52%以上的测试样本覆盖率超过50%,即SIJP-SML生成了一半以上的真值中的词汇;69%以上的测试样本覆盖率超过40%。
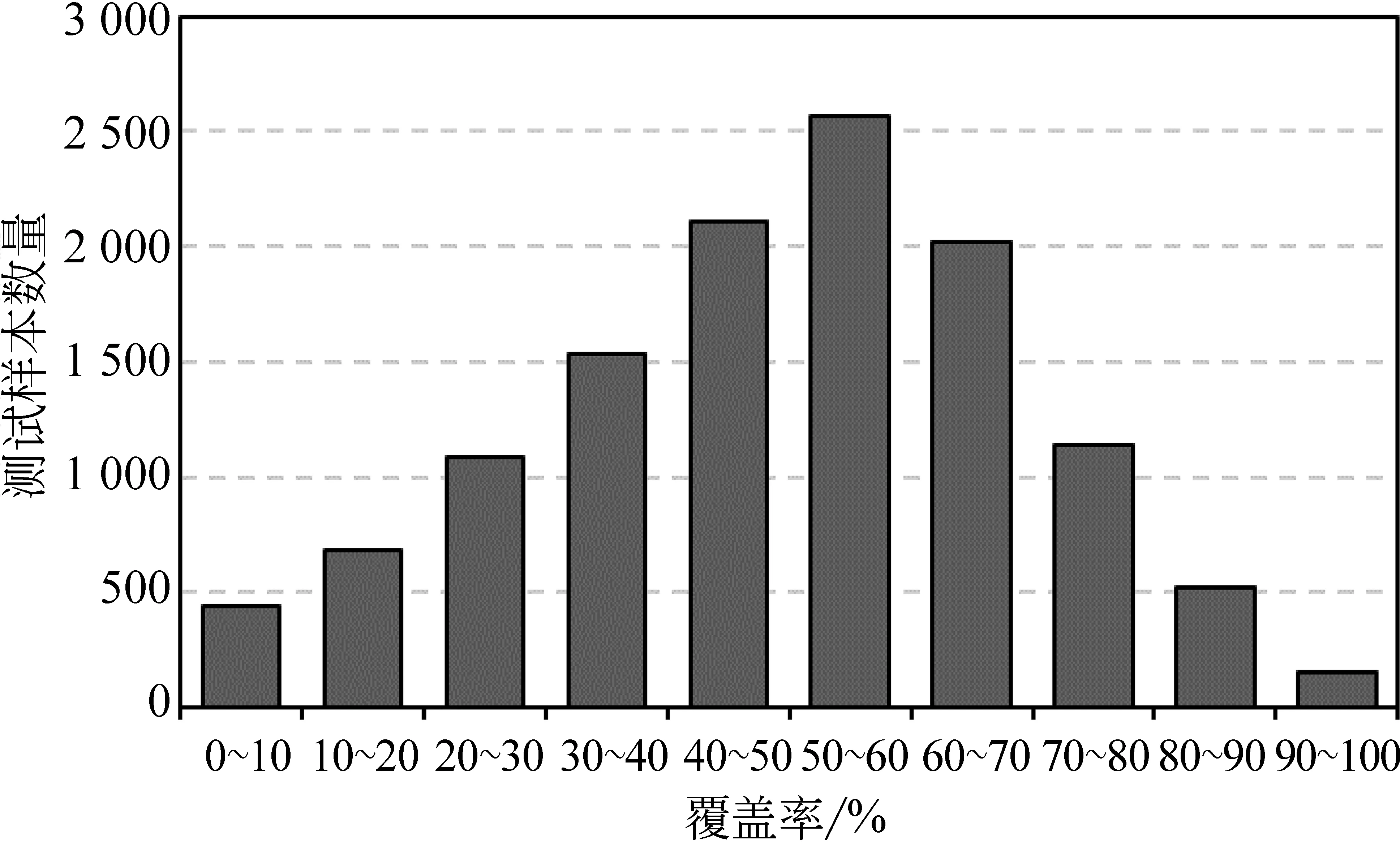
图2 生成的法院观点对法院观点真值的词汇覆盖率
上述分析证明,通过引入法院观点生成任务,能够使SIJP-SML的预测具有一定的可解释性。
5 总结与展望
本文提出一种基于有序多任务学习的二审判决预测方法SIJP-SML。该方法通过两个时序依赖的多任务学习部分来对从一审到二审的完整审判逻辑进行建模,通过捕捉两审法院对案情的认知异同来预测二审判决结果。同时,为增强预测的可解释性,SIJP-SML引入法院观点生成作为子任务。在6万余份二审裁判文书数据上的实验结果表明,SIJP-SML比TOPJUDGE、HAN、Seq2Seq等基线LJP模型在二审判决预测任务上表现出更好的综合性能,其F1测度上的分数相较于性能最好的基线方法TOPJUDGE有14.1%的提升。通过消融实验,证明了SIJP-SML的设计合理性。通过案例分析和覆盖率统计,证明了生成的法院观点文本使SIJP-SML的预测具有较好的可解释性。在未来的工作中,将考虑在有序多任务学习中引入罪名、刑期预测等更多的子任务,并探索更好的模型架构,以期进一步提升SIJP-SML的性能;此外,减轻类别间数据不平衡给预测性能带来的负面影响也是需要进一步研究的问题。
