基于多粒度特征的文本生成评价方法
2022-04-19高玉梦黄于欣余正涛张勇丙
赖 华,高玉梦,黄于欣,余正涛,张勇丙
(1.昆明理工大学 信息工程与自动化学院,云南 昆明 650504;2.昆明理工大学 云南省人工智能重点实验室,云南 昆明 650504)
0 引言
目前,机器翻译、文本摘要等生成任务取得了很好的性能,但生成文本的质量评价仍是一个难点问题[1-3],后者可以看作一个计算生成句和标准参考句之间相似度的任务。根据匹配方法的不同,可将其分为基于统计的方法和基于语义相似度的方法两类。
基于统计的方法一般是通过计算生成句和参考句之间的不同粒度语义单元的共现程度来评价模型性能,根据计算方式不同可以分为基于编辑距离的方法和基于词重叠率的方法。基于编辑距离的方法是通过计算生成句改写到参考句所需的编辑操作次数来衡量两个句子之间的相似性。编辑操作次数越多则表示一个句子改写成另一个句子越困难,句子之间的相似性越低。Snover等人[4]将生成句通过增加、删除、替换改写到参考句所需最少操作次数定义为编辑距离,使用参考句的长度对编辑距离归一化得到错误率。与基于编辑距离的方法不同,基于词重叠率的评价是当前的主流评价方法,通过计算生成句与标准参考句之间的字词重叠率来评价模型性能。Papineni等人提出的BLEU[5],以及随后Lin等人提出的ROUGE[6],是机器翻译与文本摘要模型评估中最常用的评价指标。基于此,研究者相继提出了METEOR[7-9]以及ROUGE变体[10-11]等改进的评价方法,其核心均是通过融入外部知识(如WordNet)来解决同义词匹配的问题。综上所述,虽然基于统计的方法能够很好地表征句子之间的重叠度,但是缺乏对句子深层语义的建模,因此可能出现两个句子语义相近,但是重叠词很少的情况下评分较低的现象,如图1(a)所示,两个句子均表示大雪覆盖的含义,语义较为相近,但是重叠的词较少,这在一定程度上限制了生成句的多样性。

图1 评价示意图
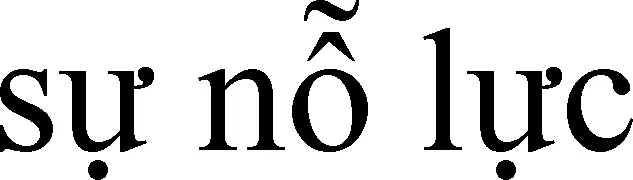
1 基于多粒度特征的文本生成评价方法
基于多粒度特征的文本生成评价方法主要包括两个部分: 多粒度语义表征部分与多粒度特征匹配部分,如图2所示。
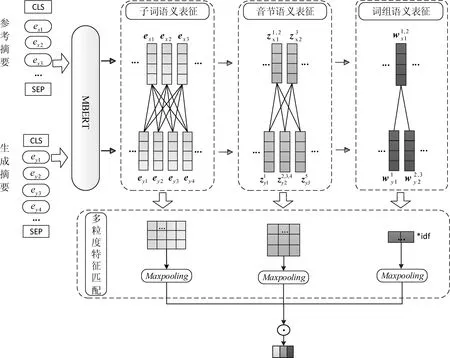
图2 多粒度特征评价方法模型
多粒度语义表征部分包括子词语义表征模块、音节语义表征模块以及词组语义表征模块。首先,为了获取不同粒度的语义特征表示,采用MBERT对参考句与生成句的子词序列进行向量表示。基于此,结合构成音节与词组的子词组合,得到音节语义表征向量以及词组语义表征向量。其次,分别对不同粒度下的参考句与生成句的语义特征向量进行最大余弦相似度匹配,使模型在多个粒度上考虑两个句子间的语义相关关系。
1.1 多粒度语义表征部分
1.1.1 子词语义表征模块
给定一个参考句X和一个生成句Y,首先使用MBERT对X与Y进行子词粒度切分得到参考句子词序列{ex1,ex2,ex3,…,exn}与生成句子词序列{ey1,ey2,ey3,…,eym}。如式(1)、式(2)将得到的子词序列输入MBERT上下文嵌入,得到参考句子词表征向量EX={excls,ex1,ex2,ex3,…,exn,exsep}与生成句子词表征向量EY={eycls,ey1,ey2,ey3,…,eym,eysep},其中,exn表示参考句X中第n个子词。
其中,MBERT表示Multilingual BERT词嵌入。
1.1.2 音节语义表征模块
音节是发音的最小语音单元,相比于子词它是一个更粗的粒度。在越南语与泰语中,音节由元音、辅音、声调构成。越南语书写时,音节与音节之间用空格隔开,因此,可利用空格对越南语进行音节切分。而泰语书写时,音节间无空格,因此,在泰语中需要借助PyThaiNLP[16]工具对泰语进行音节切分。针对中文,大多情况下,子词与音节相同,均由一个汉字构成。因此,本文在中文上不进行音节粒度语义表征。
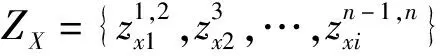
其中,“pooling”表示average pooling。
1.1.3 词组语义表征模块
词组是比音节更粗的粒度,它是语言中能够独立运用的最小语义单位。词组是由单个或多个语素构成的,语素又可分为自由语素与黏着语素,不能够独立成词的语素称为黏着语素。在越南语、泰语等语言中存在大量的黏着语素,音节可构成语素,进而构成词。由此,可以简单理解为词组由音节构成。在各语言中,需采用不同的工具对其进行分词,中文使用结巴分词,越南语使用VnCoreNLP[17]分词,泰语使用PyThaiNLP[16]分词。
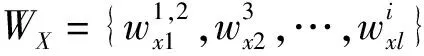
1.2 多粒度特征匹配部分
利用多粒度语义表征部分对参考句与生成句的各粒度序列进行语义特征向量后,在不同粒度下,分别计算召回率与精确率与F值。最后,结合多粒度特征确定两个句子间的语义相关关系。
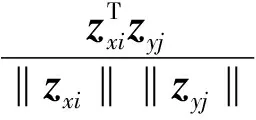
参考式(7)~式(9)可得到在子词粒度下的RE,PE,FE,以及词组粒度下的RW,PW,FW。
idf常用来衡量字或某个词在一个文件集内的重要程度,如式(10)所示。如果文件集中包含词组w的文档越少,idf越大,说明该词在突出文章主题上发挥了关键作用。词组是能够独立运用的最小语义单位,因此,本文认为基于词组计算idf能够更大化地凸显句子中的重要内容,本文可选择idf对词组粒度进行加权,如式(11)所示。
其中,N为总文档数,nw为包括词组的文档数。
最后,本文在多个粒度特征上进行观察,按式(12)计算生成句的精确率P,并计算多粒度特征下的召回率R以及F值。
(12)
2 实验
2.1 实验设置
为了验证本文提出的多粒度特征评价指标的效果,本文在机器翻译、跨语言摘要与跨语言数据集筛选三个任务上进行测评实验。另外,为了比较不同自动评价指标的性能,本文采用与前人相同的研究方法[1,13,18],通过皮尔逊相关系数r、斯皮尔曼等级系数ρ以及肯德尔等级系数τ来判定不同的自动评价指标与人工评价的相关性,r、ρ、τ取值越接近1,表示相关性越好。其中,人工评价由12名精通中文、越南语、泰语的志愿者对文本生成测评数据进行人工打分得到,打分范围为1到5分(1最差,5最好)。
本文中文本生成测评实验数据由两部分构成,一部分是本文在网络上爬取并整理的越南语、泰语句子,将该数据集称为VTSTS(Vietnamese and Thai Dataset);另一部分是公开的中文短文本摘要数据集LCSTS[19]。构建测评数据具体过程如下:
(1)针对机器翻译任务(MT),本文从LCSTS和VTSTS中分别抽取中文、越南语、泰语各200个句子作为目标语言参考句。利用谷歌翻译模型进行回译(将A语言的正向翻译成B,再将B反向翻译成A),反向翻译得到目标语言生成句,构建越中、中越、中泰机器翻译任务测评所需数据。
(2)针对跨语言摘要任务,在LCSTS中抽取200个中文摘要对,用传统的基线方法先摘要后翻译(ST)和先翻译后摘要(TS)构建中-越摘要对。翻译时采用谷歌翻译模型;摘要时,考虑到中-越跨语言摘要缺乏大规模监督数据,采用LexRank[20]这种无监督的抽取式摘要模型,构建中越跨语言摘要任务测评所需数据。
(3)针对跨语言数据集筛选任务(STS),从VTSTS数据集中抽取200个越南语单句,利用谷歌翻译模型,回译构建越-中-越伪平行句。
2.2 基线方法
本文选取以下四种评价方法作为基线方法。在同一文本生成任务中,所有的基线方法测评对象均相同。
BLEU: 基于统计的评价方法,在机器翻译评价任务中使用得最为广泛,将生成句与参考句之间的长短关系作为惩罚因子,基于此,结合参考句与生成句间的N-gram重叠率进行评分,在本文计算中,N最大为4。
ROUGE: 基于统计的评价方法,在文本摘要评价任务中使用得最为广泛,通过对比参考句与生成句间的N-gram重叠率进行评分,本文分别计算ROUGE-1、ROUGE-2、ROUGE-L的F1值。
Bertscore: 基于深度语义匹配的评价方法,用于文本生成任务的评价,通过计算参考句与生成句的子词粒度语义相似度进行评分,本文计算在该评价方法下的三个指标为R召回率、P精确率、F值。
Mgfscore(Ours): 本文提出的评价方法,可用于文本生成任务的评价,综合子词、音节、词组语义特征信息对生成句进行评分,本文计算在该评价方法下的三个指标为召回率R、精确率P及F值。
3 实验结果
3.1 机器翻译
为了探究本文提出的评价方法在评估不同语言中的有效性,本文在越中、中越、中泰机器翻译任务上进行实验。不同评价指标与人工评估的相关系数r、ρ、τ结果如表1所示。其中,MT(vi→zh)表示越中机器翻译测评任务,MT(zh→vi)表示中越机器翻译测评任务,MT(zh→th)表示中泰机器翻译测评任务,Fidf表示进行idf加权后F值得分。
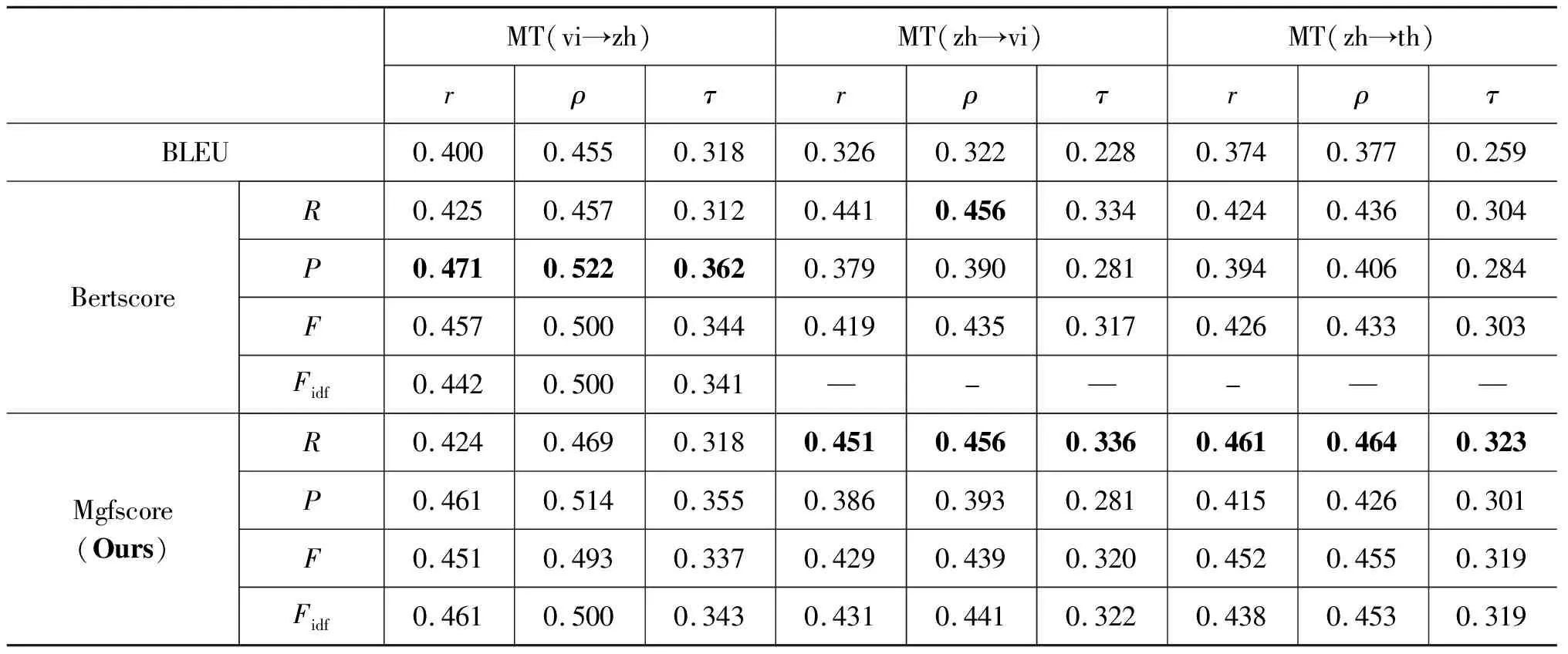
表1 机器翻译测评任务中各指标下的相关系数
从表1可以看出,在越中测评任务上,无idf对重要词组进行加权时,本文提出的方法Mgfscore与人工评价相关性低于Bertscore。这是由于中文上子词属于较粗粒度(中文子词与音节基本相同),子词嵌入表征向量存在误差,导致了多粒度语义特征提取时出现错误传播现象较为严重。
另外,在中越及中泰两个语言对的机器翻译测评任务上,Mgfscore与人工评价的相关性明显高于基线BLEU和Bertscore,证明了本文提出的多粒度特征评价方法的有效性。其中,Mgfscore在中泰测评任务中提升最大,与Bertscore最优结果相比,在相关性系数r、ρ、τ分别得到了3.5%,2.8%,1.9%的提升。
针对idf加权来说,在越中测评任务中使用idf加权时,Mgfscore-Fidf相关性高于Bertscore-Fidf、Mgfscore-F,证明了本文提出在词组粒度进行idf加权的策略的优越性。相比越中任务,在中越及中泰两个语言对任务上,Mgfscore-Fidf与Mgfscore-F相比,性能提升并不明显,甚至出现性能下降,是由于越南语与泰语的分词工具更倾向于将句子切分为音节,且部分词组分词不准确导致的。
3.2 跨语言摘要
为了验证本文提出的评价方法在不同文本生成测评任务上的有效性,本实验在中越跨语言摘要任务上进行验证,对比不同评价指标的好坏。表2展示了TS以及ST作为跨语言摘要模型时,在中越跨语言摘要测评任务上不同评价指标与人工评估的相关系数r、ρ、τ。
从表2可以看出,在中越跨语言摘要测评任务中,相比于ROUGE与Bertscore,本文评价方法Mgfscore取得了最优结果。其中,Bertscore与Mgfscore均是基于MBERT表征进行评价,二者与人工评价的相关性明显高于ROUGE,说明了基于语义相似度评价的方法比基于统计的评价方法更具有优势。在TS模型中,Mgfscore与Bertscore最优结果相比,在相关系数r、ρ、τ上分别提升了1.6%,2.0%,1.9%;类似地,在ST模型中,Mgfscore与Bertscore最优结果相比,在相关系数r、ρ、τ上分别得到1.3%,0.8%,0.2%的提升,证明了本文提出的多粒度特征评价方法与人工评价相关性更高。
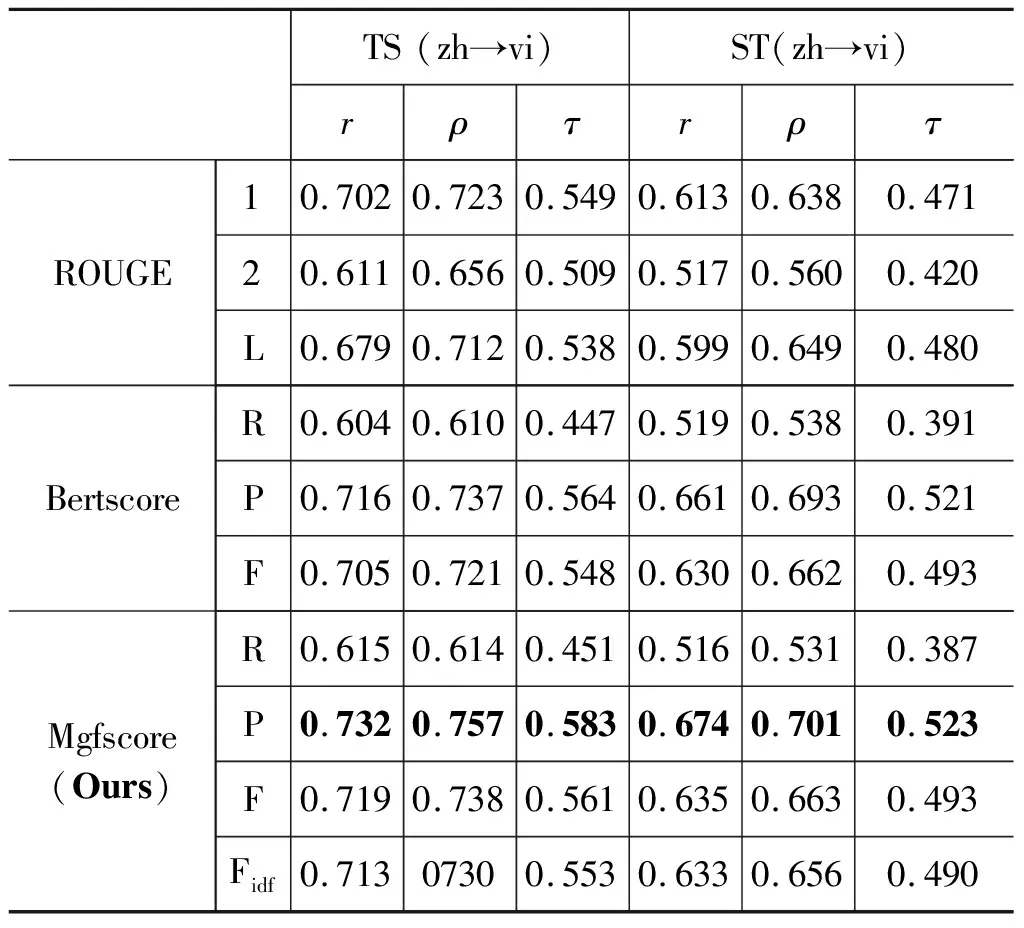
表2 跨语言摘要测评任务中各指标下的相关系数
3.3 跨语言数据集筛选
表3展示了跨语言数据集筛选测评任务中,不同评价指标与人工评估的相关系数r、ρ、τ。
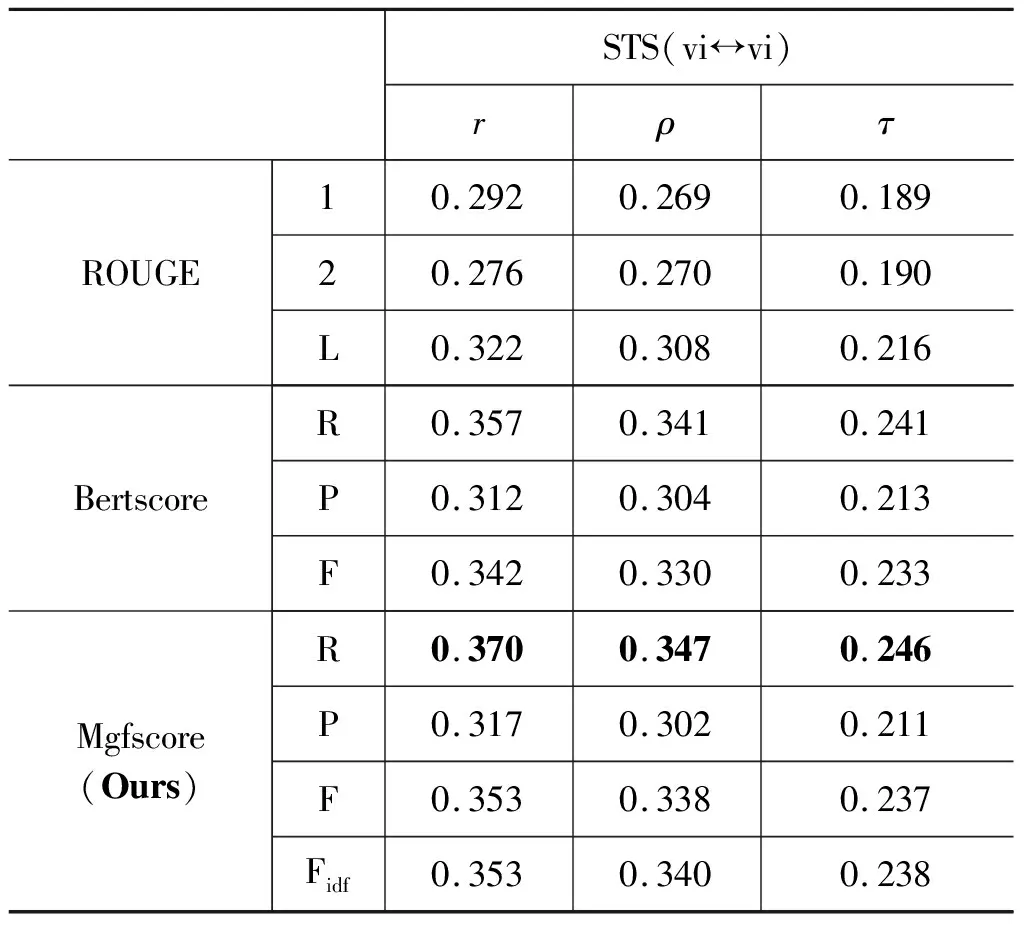
表3 跨语言数据集筛选中各指标下的相关系数
从表3可以看出,在中越跨语言数据集构建问题上,本文提出的评价方法Mgfscore仍是与人工评价相关性最高的方法,使用本文的评价方法能够更准确地筛选出高质量数据。
表2与表3均以中-越人工打分作为基准,与跨语言摘要任务相比,STS任务上相关系数r、ρ、τ均出现大幅降低的现象。对此,将两个任务的测评样本进行对比分析,得出与Chaganty等人[21]类似的结论: 当评价对象是低质量生成文本(人工评价中得分低的文本)时,使用词汇级别的评价方法测评与人工评价的相关系数更高。但在本文三个不同的文本生成测评实验中,可以看出,无论是在测评机器翻译生成的高质量文本,或是测评跨语言摘要生成的低质量文本,乃至测评跨语言数据集筛选任务中的错误传播严重的文本中,本文提出的多粒度特征评价方法Mgfscore均是与人工评价相关性最高的方法。
4 性能分析
为了探究本文提出的基于多粒度特征文本生成评价方法的性能,本节首先进行消融实验,对比了单一粒度特征与结合多粒度特征下的评价方法与人工评价的相关性。其次,本节探究了不同预训练语言模型及层数对多粒度特征评价方法的性能影响。最后,本节对Mgfscore评价方法进行实例分析,探讨本文提出的多粒度评价方法的优缺点。
4.1 消融实验
以中越与中泰两个语言对的测评任务为例探究在不同粒度特征匹配下F值与人工评价的相关系数r、ρ、τ,实验结果如图3所示。
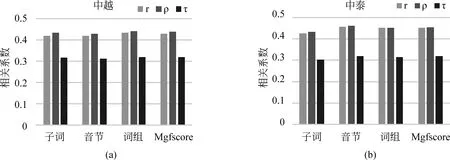
图3 不同粒度下的实验结果
在图3(a)与图3(b)中可以发现,针对r、ρ相关系数来说,在中越测评任务上,基于词组粒度的评价与人工评价相关系数最高;在中泰测评任务上,基于音节粒度的评价与人工评价相关系数最高;但无论是在中泰还是中越测评任务中,本文提出的评价方法Mgfscore与人工评估的相关系数r、ρ均维持在高于中位数水平,由此可见,结合多粒度特征的评价方法具有较高的稳定性。针对相关系数τ来说,Mgfscore与单粒度评价中的最优结果相近。由此,进一步证明了结合多粒度的评价方法具有更加稳定的性能。
4.2 各预训练语言模型及层数对性能的影响
为了验证本文提出方法在不同预训练语言模型上的有效性,以及探究预训练语言模型层数对本文提出的评价方法的性能的影响,本节在MBERT与XLM(xlm-mlm-100-1280)[22]两个预训练语言模型上进行实验,计算不同层表示下Bertscore/Mgfscore的F值与人工评价的皮尔逊相关系数ρ,结果如图4所示。

图4 各预训练语言模型在不同层数下的实验结果
从图4可以看出,一方面,在不同的预训练语言模型中,本文提出的方法Mgfscore与Bertscore相比表现更好。另一方面,在中越与中泰的测评任务中,Mgfscore或Bertscore与人工评估的相关性并没有随着模型层数的增加而不断上升,而是在中间层数取得了更好的结果,说明中间层数的表示包含了更多的语义信息。同时,Mgfscore与Bertscore比较,在低层数表示时性能提升较大,这是由于低层数的表征中包含了更多子词本身的信息,此时更加明显地体现出了基于多粒度的方法能提取更全面的信息。而随着层数的增加,子词表征向量提取到了更多上下文的信息以及一些与语义无关的信息,此时带来的错误传播也更为明显,以致于Mgfscore较Bertscore的性能提升出现了减缓的趋势。
5 实例分析
为了进一步证明多粒度特征的文本生成评价方法的有效性,本节对图1(b)中示例,使用Mgfscore评价并进行分析,各粒度匹配结果如图5所示。
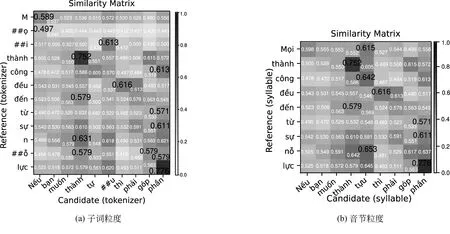
图5 Mgfscore各粒度匹配结果
6 结束语
本文针对越南语、泰语等存在大量黏着语素的语言,提出了一种基于多粒度语义相似度的评价指标,通过MBERT提取不同粒度的语义特征信息,基于此综合考虑不同粒度语义单元的相似度,改善了传统基于统计的评价方法中存在的词汇多样性评价能力弱的问题,也更好反映了生成文本与参考文本间的语义关系。在中泰及中越语言对测评任务中,相比于BLEU、ROUGE以及Bertscore等评价指标,本文提出的多粒度特征评价方法均与人工评价结果更接近。
