Senti-PG-MMR: 多文档游记情感摘要生成方法
2022-04-19梁梦英李德玉王素格郑建兴
梁梦英,李德玉,2,王素格,2,廖 健,郑建兴,陈 千
(1.山西大学 计算机与信息技术学院,山西 太原 030006;2.山西大学 计算机智能与中文信息处理教育部重点实验室,山西 太原 030006)
0 引言
随着旅游业的蓬勃发展,景点游记数量也呈指数增长。为了获取海量景点游记中蕴含的丰富知识,需要多文档摘要技术的支持,从而节省人们大量阅读游记文本的时间,可为其他游客出行提供参考,同时为旅游部门进行决策提供依据。
现有的文本摘要针对的文本类型主要是客观存在的事实描述。然而,游客对于景点关心的不仅是简单的景点介绍,更多的是关注其他游客对于景点的主观评价,其中蕴含着大量丰富的情感知识,而这些知识对于游客来说是最有价值的。因此,有必要将同一景点的多篇游记文本进行综合,去除冗余信息,提取重要的信息,同时利用游记中用户的情感信息,生成带有一定情感信息的摘要。这里的情感摘要与已有的情感概括[1]相比,情感概括是针对互联网上某一产品的特定属性,生成对应属性下的摘要概括,最后将同一属性合并排列,作为这一产品的摘要概括。而情感摘要主要是消除大量游记中冗余的文本信息,并提取游客评论中蕴含丰富的情感信息,从而生成该景点的情感摘要。现有的文本摘要方法,对原始文本蕴含的情感信息挖掘不足,而包涵深层次情感信息挖掘并将其加入生成式摘要的相关研究还较少[2]。
为了解决上述问题,本文将情感信息融合于PG-MMR模型[3],提出了一个Senti-PG-MMR模型,该模型为一个端到端的神经网络摘要生成模型,它能将句子的情感属性特征拼接到句子的表示层,作为编码器的输入,通过调整解码器端生成的注意力机制,既保留了句子的重要部分,又降低了句子的冗余程度。实验结果表明,本文提出的方法可以有效地提高多文档情感摘要的性能。
1 相关工作
本文的多文档生成式情感摘要主要关联于生成式自动文摘、多文档摘要和情感摘要。因此,以下介绍这三方面的相关工作。
1.1 生成式自动文摘
现有的自动摘要方法主要分为抽取式和生成式。生成式自动文摘是一种接近人类撰写摘要的方式,也是摘要技术的追求目标。近年来,神经网络模型在生成式摘要的一些具体任务(如标题生成、新闻摘要等)上取得了一定的成果。Rush等[4]提出了一种关于生成式摘要的神经网络模型,使用Gigaword数据集作为训练集,取得了ROUGE-1最高分的成绩。Nallapati等[5]提出了基于循环神经网络的序列到序列模型,在解码器阶段采用的分层注意力机制和词表限制,改善了摘要的效果。Paulus等[6]将输出信息融入到输出隐藏层向量中,避免了重复信息的产生,同时提出使用强化学习的方式训练模型。Ma等[7]通过最大化原文本和摘要之间的语义相似性,确保生成与原文本在语义上表达一致的摘要。Tan等[8]利用序列到序列模型与传统的图模型方法融合,通过增加句子重要度进行摘要生成。
1.2 多文档摘要
多文档摘要旨在研究同一事件主题中若干篇文档的集合,通过相关技术的处理,提炼出该事件主题的精简信息[9]。Logan等[3]提出了一个从单文档摘要到多文档摘要的神经网络结构,利用最大边界相关算法从多文档输入中选择具有代表性的句子,然后再利用编码器-解码器将不同的句子融合成一个抽象的摘要。Chu等[10]提出了一个无监督多文档摘要的神经网络模型Mean-Sum,它由一个自动编码器组成,将所有文档表示的平均值输入解码器中,得到最后的摘要。唐晓波等[11]提出了基于句子主题发现的中文多文档自动摘要方法,在句子层面进行主题探测形成主题簇,然后筛选出较为重要的主题,利用这些筛选出的具有代表性的句子形成重要主题下的摘要内容。
1.3 情感摘要
与普通的文本摘要任务相比,文本情感摘要任务关注文本中的情感因素,其生成的情感摘要使人们能够方便地获取文本的主要内容,了解大众的观点与态度。近年来,文本情感摘要技术已受到国内研究者的关注。张冬梅等[12]提出一种无领域限制的多文档观点摘要方法,利用概率主题模型构建句子集合模型,通过语义情感倾向对句子进行词性分析,依次抽取重要度最高的句子构成文本情感摘要。林莉媛等[13]以PageRank算法为基础,提出了一种生成多文档评论文本的情感摘要,并在计算句子权重时考虑情感因素和主题因素,但对于主题信息的处理完全依赖PageRank算法,存在情感摘要偏离主题的问题。张仰森等[14]通过分析情感词、情感词短语和否定词等情感元素,分析热点话题下句子的情感倾向及情感强度,通过抽取候选文摘句生成具有不同情感态度的文本情感摘要。
2 多文档游记情感摘要(Senti-PG-MMR)
本文研究同一主题下的多篇游记生成带有情感信息的文本摘要任务,即在某一特定景点下的多篇游记的情感摘要。因此,需要引入句子的情感信息。利用大连理工大学情感词汇本体[15]作为情感信息的数据源,为句子生成具有情感层面的向量表示,利用双向LSTM网络结构获得句子词语层面的向量化表示。最后,将两种表示融入基于PG-MMR的多文档游记摘要生成模型中。该模型结合pointer-generator网络结构和MMR算法。使用MMR算法,既能去除多文档生成摘要的冗余,同时保留关键信息。整个模型包括情感特征向量化表示、基于Bi-LSTM的上下文句子语义表示、基于MMR的句子级注意力权重计算和基于指针生成网络的摘要生成 4个模块,模型结构如图1所示。

图1 多文档情感摘要模型整体结构
2.1 情感特征向量化表示
利用大连理工大学情感词汇本体作为情感词典构造情感向量,这种方法比利用词嵌入层生成情感词典更加简洁,能有效提升模型的训练效率[15]。如图1中左半部分所示,最终生成的情感向量是6维向量ssenti=[s1,s2,s3,s4,s5,s6]。
对游记文本中的词在情感词典中进行查找匹配,生成的6维向量表示ssenti分别见式(1)~式(6)。
其中,s1、s2为语句中正向词情感值均值、负向词情感值均值,它们分别代表了语句的正向情感特征和负向情感特征。s3、s4、s5、s6分别代表名词、形容词、动词、副词四类词性的词数与句中总词数之比,代表了语句的结构特征。
2.2 基于Bi-LSTM的上下文句子语义表示
本文利用编码器对文本特征进行词级-句子级向量表示。如图1中右半部分所示,将每个词映射到一个高维的向量空间,使用预先训练好的词向量得到定长的词嵌入。给定一个句子si=[w1,w2,…,wn]。wi表示句子S中的第i个词,对于每个词的嵌入表示如式(7)所示。
(7)
其中,e(v×d)表示词向量嵌入映射,v表示词表大小,d表示向量维度。

(8)

(9)
在句子表示的基础上,将情感信息拼接到句子的表示中,获得每个句子s的向量表示如式(10)所示。
(10)
2.3 基于MMR的句子级注意力权重计算


(11)
句子i与标准摘要句子j相关性度量如式(15)所示。
(15)
(16)
利用MMRi,更新图1中箭头所示的指针生成器模型的句子级注意力权重,将句子中的每个词的注意分数都赋予句子的MMRi分数。
2.4 基于指针生成网络的摘要生成
指针生成网络是一种常用的编码器-解码器摘要模型,一方面可以直接从定义的词表中输出单词,另一方面需要从源文档复制单词。

(20)
指针生成网络设置有一个软开关pgen,最后生成的单词是以pgen和1-pgen的大小来决定是从词汇表中采样生成一个单词pvocab还是以概率pcopy从源序列中复制一个单词。pgen的计算如式(23)所示。
(23)
最终概率分布是词汇分布和复制概率的加权和,计算如式(24)所示。
PV(yt)=pgenPvocab(yt)+(1-pgen)Pcopy(yt)
(24)
使用负对数似然作为损失目标函数,计算如式(25)所示。
(25)
其中,Lsum是标准摘要所包含的单词总数。
3 实验
3.1 实验数据
本文数据集来源于马蜂窝爬取的游记语料,包括2018年上半年山西热门景点游记文本。由于本文只关注景点介绍这一信息,于是将与景点介绍无关的文本信息剔除掉,只保留景点介绍以及蕴含游客丰富情感的评论信息。标准摘要数据集的建立是针对每一热门景点由旅游专业人士进行撰写,其中应包括全面的景点介绍信息,以及丰富的情感信息。
数据规模为5 000条游记-情感摘要对,选取数据集的80%作为训练集,10%作为验证集,10%作为测试集,具体统计见表1。

表1 数据集统计
3.2 评价方法
本文使用标准摘要评价指标和情感信息评价指标。
3.2.1 文本摘要评价指标
ROUGE[17]是基于摘要中n元词(n-gram)的共现信息来评测摘要的评价标准,是一种面向n元词召回率的评价方法。本文主要使用ROUGE-1(单字组),ROUGE-2(双字组),ROUGE-L(最长公共子序列)来评测实验效果,具体计算如式(26)所示。
(26)

对于ROUGE-L(最长公共子序列),详细见文献[17]。
除了自动评估外,本文还进行了人工评估所生成的摘要。选用三个旅游文学专业的评测人员,在不同模型下选用Best-Worst标度[18-19],以衡量模型生成的摘要性能的好坏,以及信息全面性(输入文本中的含义是否保存在摘要中)、流利程度(摘要是否有良好的格式和语法正确)和冗余度(摘要是否避免重复信息)。
3.2.2 情感信息评价指标
情感信息评价指标是利用句子的情感得分作为衡量指标。假设文本情感得分符合线性叠加原理,即将单句的情感值加和作为文本的情感得分。对于句子情感值计算采用如下规则:
R1: 如果分词后的词语包含在情感词典中,则加上该词的情感值。
R2: 如果情感词的前面出现程度副词,则让情感值加倍。
R3: 如果情感词的前面出现否定词,则让情感值减半。
3.3 参数设置
实验模型的相关参数如表2所示。

表2 参数设置
3.4 对比实验
为了验证所提方法的有效性,设置了以下5个对比方法。
PageRank[20]: 使用句子作为图节点,从整个图递归绘制的全局信息来确定图中顶点重要性的一种方式。若一个句子与其他众多句子相似,那么这个句子就可能是重要的。
MMR[21]: 最大边界相关算法,用于计算Query语句与被搜索文档之间的相似度,实现对文档进行排序的算法。
Pointer-Generator Network[22]: 指针生成网络,是在标准seq2seq+attention的基础上采用指针开关,在保留生成新词的同时,从原文中抽取内容,促使生成更准确的摘要。
PG-MMR[3]: 结合Pointer-Generator与MMR算法进行多文档摘要生成。
SemSentSum[23]: 利用两种类型的句子嵌入,分别在一个无关的大的语料库上训练通用嵌入表示,再在特定领域训练过程中学习特定领域上的嵌入,最后经过图注意力网络生成摘要。
3.5 实验结果及分析
对于3.4节所提出的5个对比方法进行实验结果分析。自动评测结果如表3所示。

表3 不同方法自动评测结果
由表3可以得出:
(1)本文提出的Senti-PG-MMR方法优于PageRank、MMR、Pointer-Generator Network、PG-MMR和SemSenSum五种方法,说明本文提出的方法在生成多文档情感摘要方面是有效的。
(2)相比于抽取式的PageRank和MMR方法,生成式Pointer-Generator Network得分较高,表明生成式摘要方法能捕捉到原文的重要性、文本流畅性、句间连贯性以及信息丰富性。
(3)Senti-PG-MMR方法相比于Pointer-Generator Network和MMR两个模型都有一定的性能提升,表明将两者结合更有利于多文档摘要的生成。
人工评测结果如表4所示。
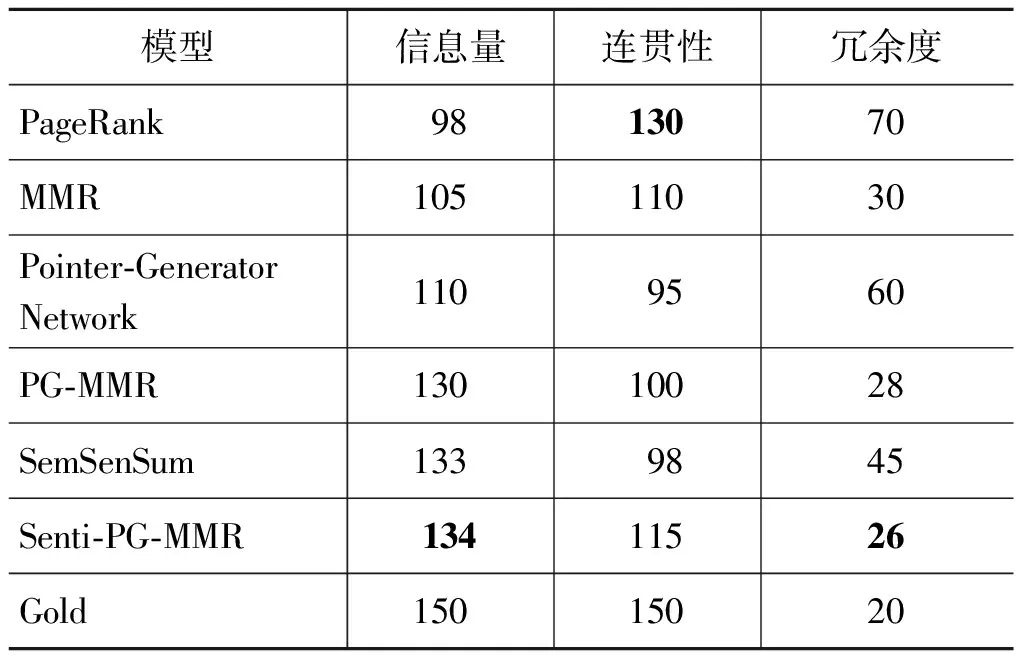
表4 不同方法人工评测结果
由表4可以得出:
(1)Senti-PG-MMR模型相比Pointer-Generator Network模型在信息量和冗余度方面的性能表现较好,说明将MMR算法引入模型学习中可以减少输出摘要的冗余。
(2)由于PageRank是抽取式自动文摘方法,说明其在流畅性方面优于其他生成式摘要的模型方法。
(3)各个模型的结果与标准摘要还有一定差距,表明本文的模型在生成连贯和信息丰富的摘要方面还有较大的提升空间。
3.6 三种方法的情感分布
为了证明Senti模块的有效性,需要展示Senti-PG-MMR获取情感信息的分布情况,因此,将标准摘要、PG-MMR模型和Senti-PG-MMR模型的三种情感信息分布在测试集上进行可视化,具体情感分布如图2~4所示。其中横坐标表示500条测试集摘要文本,纵坐标表示每条文本摘要的情感得分。

图2 标准摘要情感分布图

图3 PG-MMR模型情感分布图

图4 Senti-PG-MMR模型情感分布图
由图2~4可以得出:
(1)标准摘要情感信息分布广泛,存在着大量位于0之外的情感信息丰富的句子。
(2)对于PG-MMR模型生成的情感摘要,其情感分布更多的集中于0附近,同时得分2以上的情感丰富的摘要文本较少。
(3)加入情感模块的模型Senti-PG-MMR所生成的摘要,处于0以外的句子分布广泛,比PG-MMR模型所产生的摘要情感更丰富,表明情感特征向量化表示模块是有效的。同时还可以看到Senti-PG-MMR模型情感的分布相比于PG-MMR模型更加贴近标准摘要的情感分布。
3.7 实例分析
为了进一步说明本文所提方法的性能,将Senti-PG-MMR方法和其他方法进行了实例比较,具体实例如下:
(1)标准摘要: 平遥古城位于……是现存最为完整的古城。平遥古城太值得去了!“又见平遥”观影体验很好,值得推荐。
(2)PG-MMR: 平遥古城位于……是现存最为完整的古城。值得一去。
(3)Senti-PG-MMR: 平遥古城位于……是现存最为完整的古城。最爱县衙,好大啊!值得一去!菜品怎么说呢,在景区真的比较实惠了,口感还可以。
从上述三种结果看,在同等数据集的条件下,相比未融入情感信息的PG-MMR模型,本文提出的Senti-PG-MMR模型,在实例(3)中更注重情感信息的表达,同时也抓住了文本中的关键信息,使生成摘要的情感信息量更加丰富。
4 结束语
本文构建了一个端到端的多文档游记摘要模型,该模型将情感信息融入到句子级别的表示层,在解码器阶段,将最大边界相关算法集成到指针生成器网络中,避免生成的摘要冗余。在构建的旅游数据集上进行实验表明,本文所提出的方法在效果和性能上均有提高,说明建立的数据集对旅游文本的摘要研究能起到支持作用。
由于模型生成摘要的含义准确性和行文连贯性还有待提升,在今后的工作中,将MMR纳入Transformer模型,探索文档之间的更多交互关系,从而生成更加准确、流畅的摘要。
