基于Rule-BertAtten的中文小说对话人物识别方法
2022-04-19王玉龙刘同存廖建新
王 子,王玉龙,刘同存,李 炜,廖建新
(1.北京邮电大学 网络与交换技术国际重点实验室,北京 100876;2.浙江农林大学 信息工程学院,浙江 杭州,311300)
0 引言
随着移动互联网的发展,阅读中文小说日益成为人们日常生活的重要休闲方式。然而,人们已经不仅仅满足于阅读中文小说所带来的享受,还更希望于中文有声小说带来听觉上的体验。因此,小说供应商在人工合成一部有声小说上需要投入大量的人力和物力,如何运用自然语言处理技术将有声小说阅读进行自动语音合成[1-2],降低合成成本,成为近年来研究的热点。有声小说自动合成的关键在于能够将一条对话的内容识别为某个具体的人物,即小说对话的人物归属识别,再通过人物的性别、年龄、性格等状况来进行相关的符合人物设定的语音自动合成。
本文提出一种Rule-BertAtten的识别方法,首先运用Stanford Parser对中心对话前一句话和后一句话进行依存句法解析,可将小说对话分为四类: 有明确人物名作为主语的对话(Explicit Speaker)、人称代词性别唯一匹配候选人作为主语的对话(Pronoun One)、人称代词性别多匹配候选人作为主语的对话(Pronoun Many)以及其他无任何特征作为主语的对话(Implicit Speaker)。将规则法运用到第一种对话和第二种对话中,直接判断出对应的人物名。BERT词向量的方法运用到第三种对话和第四种对话中,用BERT对附近文本进行整体编码,抽取候选人所在的位置编码,同时为对话附近的文本加入注意力机制来显示文本的位置信息,将此注意力向量和BERT向量进行加权求平均,最后将构造的候选人向量传入两层的神经网络,对输出结果进行局部的softmax,对候选人进行打分,得分最高者作为识别结果。
1 相关工作
目前,学术界对英文小说的对话人物识别进行了深入研究,也构造了大量的数据集。在早期的英文小说对话识别研究工作中,鉴于小说对话环境的复杂度,以及机器学习和深度学习模型的发展迟缓,规则法大行其道,Glass等[3]提出了三步构造规则的方法,首先用Stanford Parse解析出说话的动词(Speech Verb),然后识别出对应的主语说话人(Actor), 最后再利用相应的规则如距离的远近等进行相应的打分,完成最后的人物识别。Louis等[4]除了用常规的句法分析规则处理文本外,加入了对话轮询的方式,同时用逻辑语言对人物的关系进行了关系抽取,将关系抽取的结果加入到规则判断中去,虽然规则判断也体现了候选者的位置信息,但是规则判断可移植性较低,无法全面地表示候选者的语义信息。随着传统机器学习的发展,运用传统的机器学习技术处理特征向量逐渐成为了主流,在特征工程的实现方法上,K.Elson等[5]根据对话类型抽取相应特征,采用了逻辑回归、J48决策树和JRip[6]的方法,Hua He等[7]除了使用常规的特征向量如距离、候选人出现的个数等外,还加入了说话者姓名,即根据人物名出现在中心对话中的位置各异,在中心对话中判断人物名,另外一个创新的特征为性别匹配,即判断性别是否匹配,最后采用SVM_rank算法对候选人进行打分,选出得分最高者,Yuxiang Jia等[8]构造了金庸先生的《射雕英雄传》数据集,同时采用了基于候选人是否存在等的布尔特征、候选人与中心对话的距离等浮点型特征以及候选人存在的个数等的数量特征三种类型共20个特征,取得了较好的效果。在特征向量抽取的方法中,任务的关键在于抽取的特征质量,也面临着无法全面表示候选者的语义等特征信息的困境。传统的文本分类问题将所有的类别作为目标进行训练和预测,Louis等[4]尝试将一条中心对话中及其附近的文本数据输入到GRU,所有的人物进行独热编码,实验结果表明,该方法效果较差,和局部候选人的随机预测结果相当。
然而,英文小说和中文小说存在巨大的差异,主要体现在人物名的表示和对话句式构成上。在人物名表示方面,英文小说人物名一般由单个单词构成,而中文小说人物名包含了大量的别名,同时英文人名能体现人物之间的亲属关系,如Mr.和Mrs.往往是一对夫妻,这在中文人物名方面很难体现。在对话句式方面,英文对话大量使用“quote” said by person和“quote” person “quote”的句式,即说话者在说话动词后和说话者在其对话的中间位置,而中文对话却很少有类似的句式。所以英文小说的人物识别方法难以直接运用到中文小说中,本文针对中文小说的特点,在英文小说人物识别方法的基础上研究中文小说的人物识别方法。
目前,由于中文小说对话人物识别数据集匮乏,只有文献[9]提供的《平凡的世界》中文数据集。作者采用了规则判断和特征工程的方法,抽取了中心对话上下文各10句,将这21句中出现的人物作为此中心对话的候选人。规则打分机制采用文献[3]的方法,不同的是在进行Stanford Parse进行句法解析时,解析器会将作为主语的中文人物名解析出以空格隔离的单个字,这对主语的判断选取无疑引入了噪声。在特征工程方法上,Chen等[9]根据候选人的位置、性别等信息,抽取共16个对应的特征,将抽取到的16个特征向量通过两层的神经网络,最后通过softmax取局部候选人得分最大值作为识别结果。此方法引入了下标特征和每个候选人都会出现的男他女她特征等无用信息,同时忽略了依存句法解析的主语和宾语和候选人性别是否匹配的信息,致使准确率不高。文献[9]采用的规则法和特征工程的方法都忽略了对话的类别信息,在无明确主语的对话情形中,规则法和随机预测的结果相差无几,同时,特征工程的方法在对有明确主语的对话的预测上又不及规则法简单且准确,而且特征工程方法也面临着无法准确表达候选人语义信息的问题。
为了解决上述问题,充分表示对话的类别以及中心对话附近候选人的语义信息,本文采用文献[9]提供的《平凡的世界》数据集进行研究,跳过了小说对话内容的自动抽取[10-11]和小说中人物的自动抽取[5,12]的步骤,提出基于Rule-BertAtten的方法。首先对人物名和说话动词进行相应的数据增强,以解决依存句法解析主语时解析出的单个字的问题,然后按照依存句法分析结果将对话类型大致分为四类,分别为有明确人物名作为主语的对话(Explicit Speaker)、人称代词性别唯一匹配候选人作为主语的对话(Pronoun One)、人称代词性别多匹配候选人作为主语的对话(Pronoun Many)以及其他无任何特征作为主语的对话(Implicit Speaker)。规则判断方法直接运用到前两种对话类别中,BERT[13]在文本分类[14]、QA[13]、语义分析[15]等方面取得了显著成效。为了充分表示候选人的语义信息,将BERT[13]词向量的方法运用到后两种对话类别中,再对中心对话附近的文本语句加入注意力[16]机制来表示候选人所在位置的重要程度,然后将语句中的候选人词向量和注意力权重进行权重相加,构造出候选人对应的词向量,最后将构造的候选人词向量通过两层的感知机,输出通过局部的softmax选取得分最高者作为预测结果。实验结果表明,本文方法具有更高的准确率。
2 识别方法
本节将阐述基于Rule-BertAtten的中文小说对话人物归属识别方法,主要内容分为以下四个部分: ①数据预处理;②对话分类;③规则判断方法;④BertAtten模型;模型架构如图1所示。
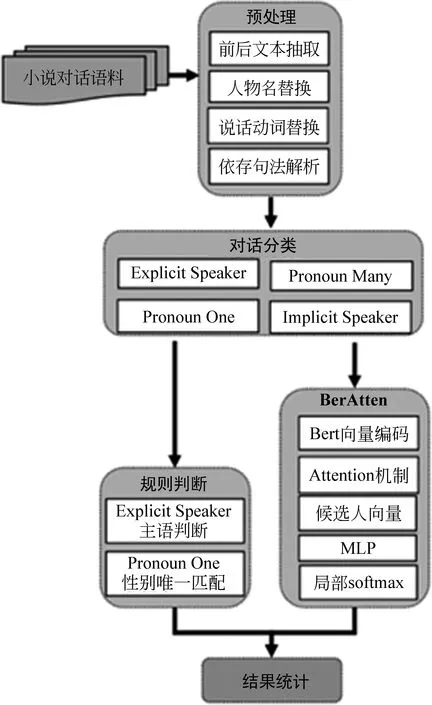
图1 基于Rule-BertAtten的小说对话人物识别架构
2.1 数据预处理
数据预处理主要包括对话内容抽取、人物名替换、说话动词替换和依存句法解析四个部分。
(1)对话内容抽取中文小说对话人物识别的目的在于将一条中心对话归属于小说中的某个人物,这就要求数据集的构造需要涵盖中心对话附近的文本内容,文献[9]方法中抽取了和中心对话前后的各10句文本,共形成21句话,本文采用的方法是抽取中心对话的前10句话和中心对话文本后的一句话,共形成12句话。将这12句话作为中心对话的上下文,最后去除12句话中无任何候选人信息的句子。
(2)人物名替换为了解决依存句法解析中文造成的主语文字分离的情形,将人物名进行数据增强,包括以下两个部分: ①别名换成主名。将中心对话相关的上下文中所有出现的人物别名替换成人物主名。②主名替换成唯一识别的英文字母。按照人物名出现的顺序,将人物名正则替换成唯一可被依存句法解析的字母,按照英文字母顺序递增,即A、B、C、D等。
(3)说话动词替换为了使依存句法解析出的主语和宾语更为准确,运用正则表达式将所有和说话相关的动词都替换成“说”。
(4)依存句法解析对话的形成通常为主语说话人向另一个人物宾语发出,通过依存句法解析,可以解析出一条对话对应的主语和宾语,本文选择Stanford Parse作为依存句法解析器,解析的步骤如下: ①语句选择。选择以冒号结尾的中心对话的前一句,摈弃以引号开始的前一句。选择以句号结尾的中心对话后一句,摈弃以双引号开始的后一句。②句法解析。将前后两句分别通过Stanford Parse解析器进行依存句法解析,解析出相应的主语和宾语,如果不存在就解析为空。
数据预处理结束后的一条中心对话文本内容如图2所示。

图2 数据预处理结果示例
各个字段的解释如表1所示。

表1 数据预处理后的文本内容字段含义
2.2 对话分类
根据上述数据预处理之后的结果可以将小说对话分为四类: 有明确人物名作为主语的对话(Explicit Speaker)、人称代词性别唯一匹配候选人作为主语的对话(Pronoun One)、人称代词性别多匹配候选人作为主语的对话(Pronoun Many)以及其他无任何特征作为主语的对话(Implicit Speaker),具体实例如表2所示。

表2 对话类型实例
2.3 规则判断方法
本节主要阐述规则判断方法识别的过程,对于有明确人物名作为主语的对话(Explicit Speaker),直接判断此中心对话的结果为对应的明确主语人物,对于人称代词性别唯一匹配候选人作为主语的对话(Pronoun One),将此唯一性别匹配的人物名作为识别结果。
2.4 BertAtten模型
为了识别人称代词性别多匹配候选人作为主语的对话(Pronoun Many)以及其他无任何特征作为主语的对话(Implicit Speaker),本文将注意力机制加入到BERT词向量预训练模型中,BERT的预训练模型采用开源库bert-as-service,构造BertAtten模型,如图3所示。模型阐述主要包括两个部分: ①候选人向量构造;②损失函数的表示。为了便于表示,模型用到的符号及其含义如表3所示。

图3 BertAtten模型

表3 主要符号及其含义
2.4.1 候选人向量构造
(1)候选人向量抽取候选人向量抽取即运用BERT词向量的预训练模型来提取与中心对话相关的候选人的语义特征,对上下文中的句子进行编码,每句话抽取的字的长度为Sequence_length,每个字的编码向量长度为Vec_size, 所以对于一条中心对话,经过编码后的向量维度为(Content_length, Sequence_length, Vec_size)。根据每条中心对话中的某个候选人在句子中出现的位置,抽取其对应的词向量,如果在对应的句子中未出现此候选人,则用全0表示,所以经过抽取之后,一个候选人对应的向量维度为(Content_length, Vec_size)。
(2)注意力机制运用为了显示上下文中每句话位置的重要程度,为每句话加上随机的一个权重,形成一个注意力向量Att_vec,最后利用softmax对Att_vec进行归一化,Att_vec的维度为(Content_length, 1)。
(3)候选人向量构造在BERT词向量表示完毕和注意力机制选取结束后,将BERT预训练形成的词向量和注意力机制形成的向量Att_vec进行点积求平均,最后对于一个候选人形成的Canditate Embedding的维度为(1,Vec_size)。
将所有中心对话形成的候选人作为输入,输入的维度为(Candidate_count, Vec_size),其中Candidate_count代表着所有的候选人的个数,假设有n条中心对话,每条中心对话对应的候选人的人数不一,n条对话对应的候选人相加即为Candidate_count。经过两层的MLP, 最后输出的维度为(Candidate_count, 1),代表着每个候选人对应的得分。在梯度反向传播中,选用随机梯度下降SGD, 更新两层MLP和Att_vec的参数。
2.4.2 损失函数计算
由于此任务与一般的分类任务不同,损失函数和准确率函数在计算的时候具有局部性原理,即在每条中心对话中的候选人之间进行比较,将加入注意力机制的BERT词向量模型的输出作为每条中心对话的候选人对应的输出Quoteij,最后将每条中心对话候选人的输出进行局部的SoftMax, 得到一条中心对话每个候选人的得分,输出Scoreij。总体损失和局部损失函数的计算如式(1)所示,其中,n代表中心对话的条数,yij代表第i条中心对话的第j个候选人是否为目标说话者,是为1,否则为0。
(1)
3 实验分析
3.1 数据集介绍
本文选择的数据集是文献[9]构造的中文小说《平凡的世界》数据集,数据集的内容主要有以下四个部分:
(1)原始分句文本将《平凡的世界》文本按照句号进行分句,每句话有对应的下标。
(2)对话文本小说中所有的对话文本,每条对话有对应的下标。
(3)人物名文本小说中的所有人物名文本,存在的格式为:[主人物名][别名1][别名2]……。
(4)对话人物对照文本将小说人物对话的内容对应在原始文本中的下标和人物名文本中的下标相对应,从而形成对话-人物目标对应文本内容。
经过数据预处理形成的有效对话-人物目标对照文本为2 573条。按照对话类型划分训练集和测试集之后的结果如表4所示。

表4 训练集、测试集的对话数量表
3.2 评估标准
中文小说对话人物识别和一般性的文本分类任务不同,识别过程具有局部性的特征,查准率和查全率作为评估标准无相对意义,所以本文选择准确率acc作为评估标准,acc的计算方法如式(2)所示。
(2)
3.3 对比实验
为了证明本文采用方法的有效性,根据是否分句和是否加注意力机制设置了对比实验,具体的算法如下:
(1)RuleCount: 将四种对话类型采用文献[3]用到的纯规则法作为对比方法,不同的是在数据预处理方面对中文人物名和说话动词做了数据增强,从而减少依存句法解析主人物名判断带来的噪声,提高准确率。
(2)Classify1: 将四种对话类型采用文献[9]用到的特征工程方法作为对比方法,也做了相应的数据增强等预处理。
(3)Classify2: 将四种对话类型采用文献[8]中的20种工程方法作为对比方法,同时也做了相应的数据增强等预处理。
(4)Svm: 文献[7]中用到的方法,数据预处理方面也做了相应的数据增强。
(5)BertAtten: 将四种对话类型全部采用加入注意力机制的BERT词向量的方法。
(6)Rule-Bert: Explicit Speaker和Pronoun One两种对话类型用Rule方法,Pronoun Many和Implicit Speaker两种对话类型用不加注意力机制的BERT方法。
(7)Rule-BertAtten: 本文用到的方法,Explicit Speaker和Pronoun One用Rule方法,Pronoun Many和Implicit Speaker用加注意力机制的BERT方法。
(8)Un_Rule-BertAtten: 采用Rule-BertAtten方法,不同的是未经过相应的数据增强。
实验结果如表5所示。

表5 不同算法的对比实验结果
从表5可以看出,本文用到的Rule-BertAtten方法准确率最高,对于Rule方法和BertAtten方法,前者忽略了文本前后的语义信息,导致对于Pronoun Many和Implicit Speaker类型的对话,判断的结果和随机猜测的概率相当,后者忽略了对话的类型,对于Explicit Speaker和Pronoun One类型的对话,准确率低于规则直接判断。同时对于Rule-Bert和Rule-BertAtten来说,前者未加注意力机制,忽略了上下文中文本的前后位置关系,准确率相较于后者稍低。对于特征工程方法,Classify1、Classify2和Svm在前两种对话中的表现相较于Rule直接判断表现不佳,致使整体准确率较低。同时也注意到,Rule-BertAtten和未经数据增强的Un_Rule-BertAtten相比,后者的准确率下降了约4个百分点,证明了数据增强的必要性。
本文用到的Rule-BertAtten算法在各类对话中的分类正确个数如表6所示。

表6 各类对话的原始个数与识别个数
关于参数配置,在BertAtten算法中,最大迭代次数为200,神经网络层数分别为50和10,学习率为0.1,momentum参数设置为0.9。经过训练可知,在109轮询左右,测试集的损失函数最低,准确率最高。无注意力的Bert参数设置同BertAtten。
3.4 参数敏感性分析
中心对话前后语句即content个数的选取和神经网络层数对Rule-BertAtten模型产生很大的影响,本文对content的个数和神经网络的层数进行参数敏感性分析,结果如图4所示,其中各个子图的图标为content前后语句个数,从上到下,从左到右,分别为前10后1、前10后10、前20后1和前20后20。横轴为两层神经网络的单元数,分别为100-10、50-10、30-10和20-10,纵轴为对应的准确率acc。

图4 Rule-BertAtten模型在不同的content个数和不同的layer层数的acc
content选择前10后1时,模型准确率普遍较高。对于中文小说来说,中心对话后语句的选取最多只和后一句相关,选取过多会引入多候选人的噪声,同时中心对话前语句的选取应在目标人物的覆盖和候选人个数之间取一个平衡,过少的语句,目标人物覆盖不足;过多的语句,候选人个数较多,会引入噪声。
4 结束语
本文提出了基于Rule-BertAtten的实验方法,首先对原始数据做了相应的数据增强等数据预处理,然后运用Stanford Parse对中心对话的主语和宾语进行依存句法解析,将对话分为四种类型: 有明确人物名作为主语的对话(Explicit Speaker)、人称代词性别唯一匹配候选人作为主语的对话(Pronoun One)、人称代词性别多匹配候选人作为主语的对话(Pronoun Many)以及其他无任何特征作为主语的对话(Implicit Speaker)。规则判断运用于前两种对话类型,加入注意力机制的BERT词向量方法运用到后两种对话类型。在BERT词向量方法中,对上下文中的每句话进行编码,抽取出候选人所在位置的编码,同时对上下文中的每句话加入注意力机制,用以表示此句话的位置重要性,将BERT词向量的编码和注意力机制的权重进行加权求和,作为此候选人的词向量嵌入信息,然后设计了双层的神经网络(MLP),最后对每条中心对话中的候选人进行SoftMax打分,得分最高者作为预测结果。通过在数据集上的验证,证明本文方法的有效性。未来的工作中将围绕小说人物的自动抽取和对话模型做进一步的优化。
