基于矢量量化生成对抗网络的老电影音频增强算法研究
2022-04-19王雨田
王 童 王雨田 王 晖 张 勤
(中国传媒大学媒介音视频教育部重点实验室,北京 100024)
1 引言
随着科技手段的进步,电影录音设备和录音工艺在不断改进,从最早的无声电影到光学录音,再到如今广泛使用的数字录音,电影音质越来越清晰,观众获得的听感也越来越舒适。虽然运用的感光胶片作为声音存放媒介的时代已经终结,但是这些老电影具有其特殊的历史价值,记录了胶片电影时代影视工作者珍贵的劳动成果和智慧,是值得被好好保护和留存的。由于受到当时录音手段和存放条件的限制,这一时期的老电影音频出现了严重的背景噪声。因此如何对这些受到噪声 “污染”的老电影音频进行修复,让这些老电影焕然新生成为了值得关注的问题。
1930年至1950年间,我国各大电影制片厂使用的录音设备都是光学录音机。其录音方法是将声音转变为光信号,再使用感光胶片作为媒介记录声音。受到录音设备和录音原理的限制,使用光学录音机在记录声音时本身就会产生细小的片面噪声,影响语音质量。另外,感光胶片对存放条件的要求也很苛刻,如果存放不当,使得胶片上出现霉斑、污渍、划痕、手印等痕迹,就会对音频产生损伤,致使还音时出现噪声。
目前对老电影的音频修复主要依赖于人工,使用iZotope和DE-Noise等插件进行声音的数字化修复。数字化修复需要培养专门的修复人员,使用特定软件一帧一帧手动降噪,对修复人员的专业素质要求很高,而且修复时间很长。一段90分钟的电影音频,从还音到修复平均需要约20天的时间,这使得老电影音频的修复效率难以提高。随着人工智能的发展,将深度学习的方法引入到胶片数字化修复当中,为老电影音频修复提供了新的思路。该方法通过训练网络来达到降噪的目的,可以大大减少人力,提高修复效率。
本文将一个基于深度学习的语音增强网络SEGAN应用到了老电影音频降噪当中。该模型是一个端到端的网络,在网络训练前不需要再对音频做变换处理,能够尽最大可能重构音频的幅度和相位信息,保留老电影音频特点,降低对人工的依赖,使老电影音频降噪自动化成为可能。但该模型存在以下两个问题:(1)判别器性能过于强大,易导致生成器失去生成方向;(2)生成器的损失函数只包含时域损失,不适用于宽带噪声、脉冲型噪声和交流电声等老电影音频中普遍存在的噪声。因此本文针对该模型的问题提出了两点改进举措:(1)在判别器中加入矢量量化层,用来减少信息冗余,削弱判别器性能,提高判别器和生成器的性能匹配程度;(2)在生成器的损失函数中加入频域损失,使生成器生成的增强音频不但在时域上能更接近干净音频,在频域上也可以更加相似。结果表明,本文所提出的方法能够进一步提高老电影音频的降噪效果,语音质量感知评估PESQ 和可懂度评价STOI分别提高了0.18和0.05。
2 国内外研究现状
目前,针对老电影音频存在的各类噪声,国内外都没有一个很好的以不破坏原本音质为前提,尽可能去除杂音的解决办法。当前主流的方法还是采用人工修复,先使用光学还音机将感光胶片转换为数字声音格式,再使用软件修复插件对噪声进行去除。该方法一方面需要培养专业的修复人员,修复周期长,无法大批量操作;另一方面,这些软件的核心算法大多采用传统的语音增强方法,比如谱减法和维纳滤波法等,存在一定的局限性。谱减法假定加性噪声与语音相互独立,即从带噪语音的功率谱中减去噪声功率谱来进行语音降噪。但是使用谱减法进行降噪时会产生明显的 “音乐噪声”。维纳滤波法则是通过带噪语音确定滤波器的冲激响应,将带噪语音经过该滤波器后得到干净语音。以上这些插件中所使用的方法在降噪时需要手动进行参数设置,而且针对不同类型的噪声还需要使用不同的操作方法,对于人工的依赖程度很大,费时费力,无法满足海量修复的需求。
为了能够实现自动且快速的修复,有学者提出使用非负矩阵分解的方法来进行老电影音频的降噪。这种方法将带噪音频视为非带噪语音和噪声相加后的结果,将语音增强问题转换为盲源分离问题,即从带噪音频中分别提取出干净语音信号和噪声。通过建立老电影音频噪声库,提取噪声的先验特征,再利用非负矩阵分解,将噪声从老电影音频中提取出来。这种方法相比于人工修复能够节省部分时间,减少人工干预,但是由于很难从现有的老电影中获取大量的纯粹噪声片段,其降噪效果受到了很大的限制。
近十几年来,深度学习发展迅速,众多学者都在语音增强方面进行了大量的研究工作,为语音降噪提供了新的思路和方法。将其应用在老电影音频修复当中,或将实现海量电影的自动修复。
基于深度学习的语音增强方法大致可以分为两类:其中一类是基于时频掩蔽的方法,另一类则是基于特征映射的方法。基于时频掩蔽的语音增强算法利用神经网络来判断带噪语音的每一个时频点是由语音主导还是由噪声主导,若是由语音主导则保留,若是由噪声主导则去除。2012年Wang首次提出了理想二值掩蔽 (Ideal Binary Mask,IBM)和理想浮值掩蔽 (Ideal Ratio Mask,IRM),将语音增强问题转化为时频单元的分类问题。基于特征映射的方法则是将带噪语音的特征直接映射为相应的干净语音特征。这类方法使用大量的带噪语音及其配对的干净语音进行训练,使网络学习到带噪语音和干净语音的映射关系,从而达到降噪的目的。
本文将一个基于时域特征映射的语音增强模型SEGAN 应用到了老电影音频修复当中,并针对老电影音频存在的噪声类型对模型进行了改进,提高了增强效果。在使用该模型进行修复时,不需要人工设置参数,增加了其修复海量音频的可行性;也不用像论文[9]中使用的非负矩阵分解的方法一样,需要提前获取大量的老电影噪声片段,为网络训练建立专门的老电影音频数据库,因此更具有普遍性。
3 基于生成对抗网络的老电影音频增强方法
本章节详细描述了基于矢量量化生成对抗网络的老电影音频增强方法,主要分为以下两个部分进行阐述:第一部分简述了SEGAN 的网络结构,并分析了该模型存在的一些问题;第二部分针对其问题提出了相应的改进方法。
3.1 SEGAN 生成对抗网络
SEGAN (Speech Enhancement Generative Adversarial Network)是一个采用生成对抗网络GAN来进行端到端语音增强的经典模型。该模型利用生成器G 和判别器D 之间的博弈对音频进行降噪处理。生成器用来生成降噪后的音频,判别器将生成器生成的音频判别为假,将真实的干净音频判别为真。SEGAN 采用对抗训练的方式进行学习。首先,生成器先生成一段音频交给判别器,判别器评判该音频为真的概率,也就是告诉生成器该音频与干净音频的相似程度。接着,生成器根据反馈调整自己的网络参数,生成新的音频送入判别器。如此循环往复,直到生成器生成的样本可以 “欺骗”过判别器,二者达到纳什平衡。
虽然将SEGAN 模型应用在老电影音频降噪中,能够在一定程度上解决噪声污染的问题,但是该模型存在以下两个问题。
(1)判别器性能过于强大,与生成器不匹配。如果判别器的性能远远大于生成器的性能,那么无论生成器如何改进,判别器都可以判别出真假,导致生成器难以根据判别器的反馈有目的的调整网络参数,使音频生成朝着干净音频的方向进行改进。图1 (a)展示了SEGAN 的训练情况,其中D_fake表示的是将生成器生成的音频判别为假的错误率,D_real表示的是将干净音频判别为真的错误率。从图1 (a)中可以看出,判别器损失在很早的时候就降为了0,这说明SEGAN 的判别器在早期就可以对样本的真假进行正确判断,无论生成器生成什么样的语音,都无法 “欺骗”判别器,以致判别器对生成器失去了有效的指导作用。
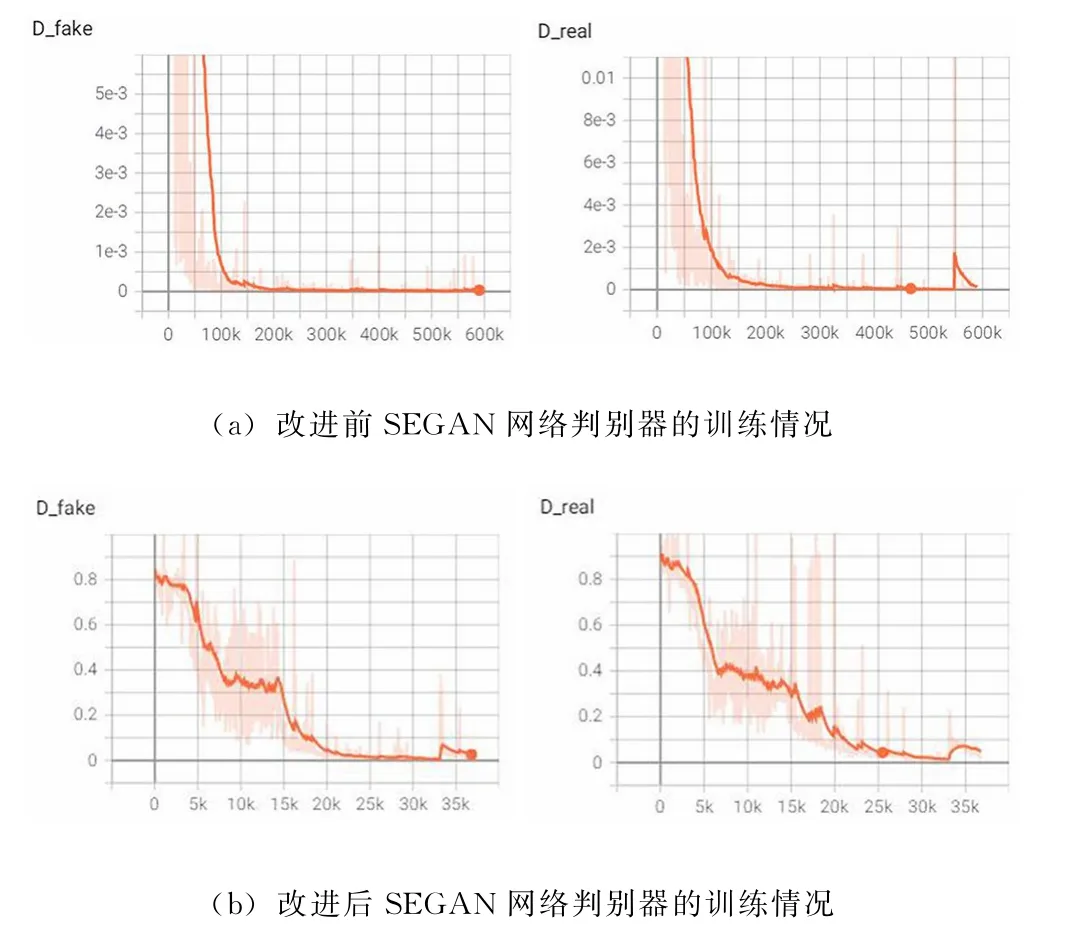
图1 改进前后SEGAN 网络判别器的训练情况
(2)SEGAN 网络训练所使用的时域损失函数不适用于老电影音频。SEGAN 生成器训练的损失函数定义如式(1)所示。
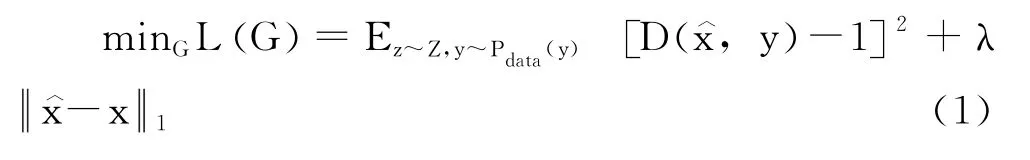
相比于其他音频,老电影音频存在的噪声更多的为高斯白噪声等宽带噪声,或是爆破声、咔嗒声等脉冲型噪声以及交流电声等噪声。这些噪声在时域和频域上具有不同的特点。
图2展示了不同噪声类型的时域表现和频域特征,其中,第一行为被各种噪声污染的音频时域波形,第二行分别为其对应的频谱。第一列为干净音频的时频域特。通过对比可以观察到,第二列所示的宽带噪声在时域上看起来杂乱无章,频域上所占用的频带较宽,与有用信息重合度高。脉冲型噪声在时域上表现为持续时间很短的冲激信号,表现在频域上就为全频带的噪声,如第三列所示。第四列展示的是交流电噪声,它所造成的影响在时域中表现并不明显,但是通过频谱可以看出,这种噪声会在某些频率上有规律地产生新的谐波结构,且分布比较分散,中频和低频部分易和有用的语音信号产生重叠。但当和宽带噪声同时存在时,两种噪声的频谱范围有所重叠,可能不易察觉出交流电噪声的存在。
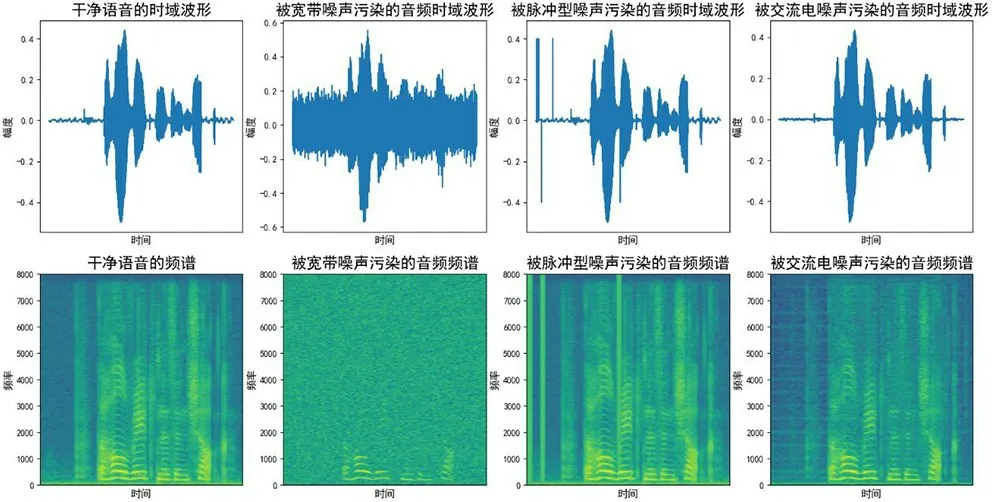
图2 不同噪声类型的时域波形和频谱
通过上面的分析可知,在老电影音频中常出现的这几种噪声当中,有的在时域上就可以很好地辨别,比如宽带噪声;有一部分在时域上持续时间短,而在频域上占有较宽的频带,比如脉冲型噪声;还有像交流电噪声这类在时域中不易察觉但可通过频域区分的噪声。因此生成器使用如式(1)所示的损失函数,仅在时域上判别生成器生成音频的好坏并不全面,可能导致网络无法捕捉到某类噪声独特的特征,学习到有用信息。
以上两个问题均限制了使用SEGAN 网络进行老电影音频降噪的效果,针对这些问题进行了如下改进:(1)在判别器中加入矢量量化(Vector Quantization)层,缩减判别器中的信息,以此来削弱判别器的性能,从而解决SEGAN 网络生成器和判别器性能不匹配的问题;(2)在生成器的损失函数中增加频域损失,在时域和频域两个方面同时约束网络训练,增加网络捕捉特征的能力,进一步提高音频修复的效果。
3.2 基于矢量量化的生成对抗网络算法
3.2.1 在判别器中加入矢量量化层
矢量量化 (VQ)的思想来源于VQ-VAE,其最大特点是将编码后的向量离散化。将VQ 加入到判别器中,对编码器的输出进行量化,限制网络所使用的特征数量,忽略特别细节的东西,从而控制网络性能。
改进后的判别器结构如图3所示。网络的输入为带噪音频和干净音频的拼接向量。网络首先经过四层卷积层,每层卷积后都使用非线性单元PRe LU来增加模型的非线性程度。接着对卷积后得到的深层特征使用矢量量化。网络中先随机生成一组含有k个向量的码本e,e……e,对应图中绿色的部分。接着,将语音通过编码器后得到的隐变量Z与码本中的每一个向量e进行比较,找到最接近的e,并用其替换相应的Z,得到矢量量化后的隐变量Z。最后,将Z输入到后续的全连接层中便可得到判别结果。
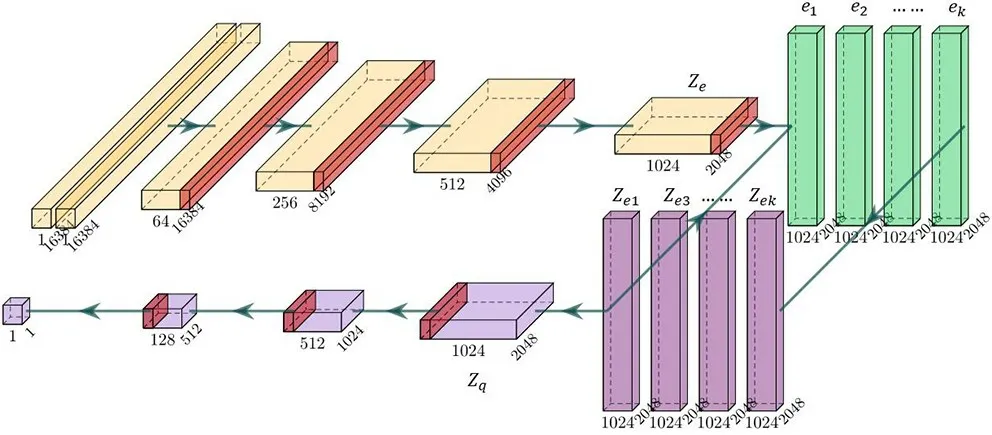
图3 改进后的SEGAN 判别器网络结构
在生成器中加入矢量量化的好处是可以把编码器输出的相似特征向量统一为一种表示形式,减少信息的冗余,使网络更加关注于整体的重要信息,而忽略一些特别细节的特征。在SEGAN 的判别器中加入VQ 后的训练情况如图1 (b)所示。可以看出,与未加入VQ 的网络相比,判别器的损失下降趋缓,一直到训练后期仍可对生成器起到指导作用,说明在判别器中加入矢量量化可以有效地改善SEGAN 网络训练不稳定的缺点。
3.2.2 在生成器的损失函数中加入频域损失
本文使用encoder-decoder结构作为生成器的模型结构,如图4所示。网络输入为带噪音频的时域波形,编码器是由若干卷积层和PReLU 激活函数连接而成的,随着卷积块的堆叠,网络提取的特征逐渐加深。解码是编码的逆过程,使用与编码器相对称的结构,通过反卷积和上采样操作重构出干净音频。该生成器在编码器和解码器之间还加入了跳过连接,使编码器各层输出的多尺度特征影响解码。
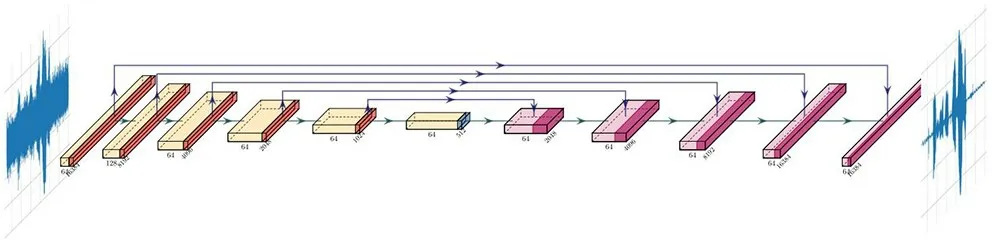
图4 生成器网络结构
原始SEGAN 生成器的损失函数如式 (1)所示,仅在时域上评判生成音频与干净音频的相似程度,而没有考虑频域特征。由3.1节分析可知,老电影音频中存在的某一些噪声在时域上不好捕捉,在频域上却具有很明显的特性,如脉冲型噪声和交流电噪声等。因此本文在原有损失函数的基础上增加了频域上的约束,如式(2)所示。
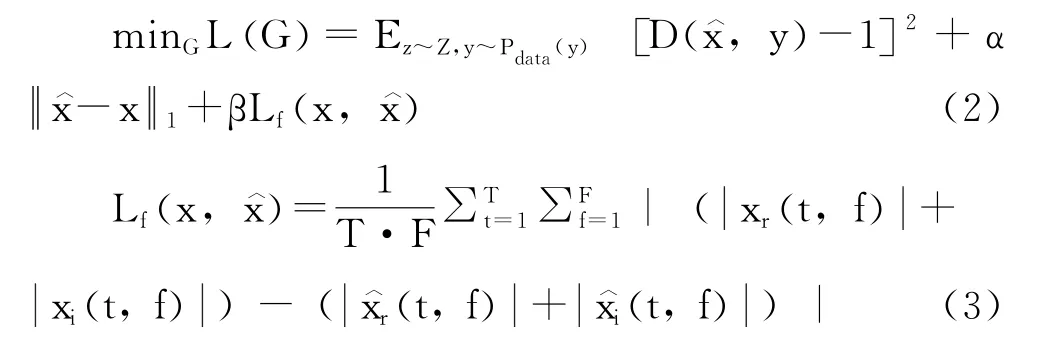
4 实验与结果
本实验使用的训练数据是由Valentini等人发表的voice bank语料库提供的。该语料库的训练集中包含28个说话人和10种不同的噪声,例如办公室环境噪声、谈话声和鸣笛声等。噪声分别以信噪比为15dB、10dB、5dB和0d B与干净语音信号进行混合,共计产生40种不同的噪声条件。所有音频的采样率均为16k HZ。
网络训练时,先将音频以50%的重叠进行分帧。不够长度的音频帧用0进行填充,以匹配批处理中最大的音频长度。本文使用0.00005的学习率和RMSProp优化器用于基于随机梯度下降 (Stochastic Gradient Descent,SGD)的优化。
本文使用一段从老电影中截取的九分钟的音频片段进行测试。该片段是从电影资料馆获得的,并且具有人工手动修复的结果。在客观评价时,使用手动修复的结果作为参考音频。增强音频的客观评价结果如表1 所示。PESQ 是语音质量感知评价,取值范围为[—1.5,4.5],得分越高表明语音失真越小。短时客观可懂度STOI分值越高表明语音越容易被理解,取值范围为 [0,1]。CSIG、CBAK、COVL分别表示语音失真程度、背景噪声影响和总体质量,取值范围均为[0,5],分数越高代表降噪效果越好。表中的SEGAN 为本文的基线模型SEGAN。rSEGAN 和SEGAN-attn 分别表示使用相对loss的SEGAN 和加入自注意力机制的增强模型。VQ-SEGAN 和VQ-SEGAN-tfloss为本文提出的改进后的模型。从表中可以看出,本文改进后的模型VQ-SEGAN 在各项评价指标中均有提升,CSIG、STOI等四项指标可以达到最优。同样,在使用时频损失之后,音频的增强效果也有所提高,其中PESQ 可以取得所有对比模型中的最大值,比基线模型提高了0.19。

表1 客观评价指标结果
图5 (a)展示的是电影从1分58秒至2分10秒的一段声音。第一行代表的分别是老电影原声、使用降噪插件手动修复、使用原始SEGAN 降噪,以及使用本文改进后的算法进行去噪的音频时域波形,第二行分别为对应的频谱。从第一列所示的电影原声的时域波形和频谱中可以看出,该段音频中存在着宽带噪声以及少量脉冲型噪声。使用原始的SEGAN 网络进行修复,对于宽带噪声的去除有一定的效果,但是由于网络性能的不匹配,生成器失去优化方向,导致在增强后的音频中产生了额外的噪声。而本文提出的方法可以更有效地去除宽带噪声和部分脉冲型噪声,对于宽带噪声的去除甚至比人工手动修复的更为干净。图5 (b)截取的是5分15秒至5分20秒这五秒的音频片段。原始的SEGAN 对宽带噪声具有一定的去除能力,但依然保留了微弱的交流电噪声。在生成器使用了时频域损失函数之后,能够在去除宽带噪声的基础上,进一步降低交流电噪声对音频的影响。

图5 不同修复方法的修复结果
本文还对修复的结果进行了主观测试,在9分钟的老电影音频中随机截取了三段长度为10到20秒的音频,作为试听样本。本实验共有15名被试者参加测试,采用平均意见得分MOS (Mean Opinion Score)的5 级评价方法进行测试,标准如表2 所示,得分越高说明音频的听感越好。在所有被试者都打完分数之后,计算其平均值作为最终的主观评价结果。表3列出了人工修复以及不同模型的主观评价分数。
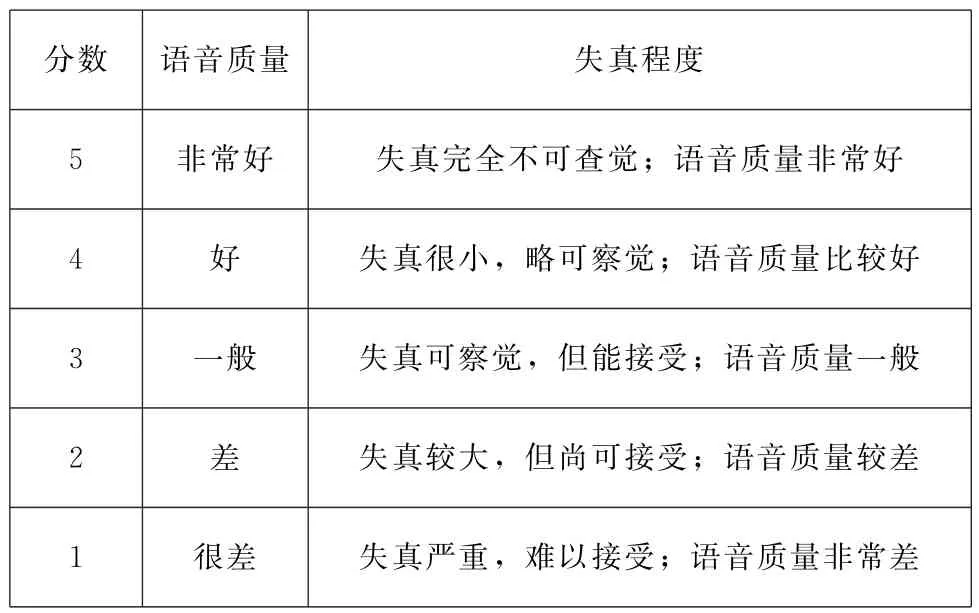
表2 主观评价打分标准

表3 主观评价结果
从表3中可以看出,人工修复的音频获得了最高的主观评价分数,这说明对于该段老电影音频来说,手动修复的老电影音频具有最好的听觉效果,其失真程度更小,语音质量更高,听起来更加自然流畅。使用深度学习模型自动修复的效果均不如人工的好。尤其是本文的基线模型SEGAN,仅得到了1.89的分数,说明修复后的音频失真严重,语音质量很差。但是使用本文改进后的模型进行修复后,MOS得分提高到了3.84,与人工修复的结果仅相差了0.6。这说明本文提出的模型在老电影修复任务上比原始SEGAN 模型更加具有优势,噪声去除得更为干净,降噪后语音失真程度更小。
总的来说,本文提出的基于矢量量化对抗生成网络的老电影音频增强算法具有以下几个优点:(1)在修复时不依赖于人工,且不需要提前获取大量的老电影噪声片段,提高了使用机器代替人工进行老电影音频增强的可行性;(2)改善了SEGAN 网络中存在的判别器和生成器性能不匹配这一问题,提高判别器对生成器的指导作用;(3)在时域和频域两个方面对网络优化方向进行约束,提高网络学习能力,进一步提高老电影音频修复质量。
5 结论
本文提出了一种基于矢量量化对抗生成网络的老电影音频增强算法,在不需要建立大量老电影修复数据的前提下,使用机器学习的方法代替人工修复,大大降低了老电影音频修复的人力支出,提高了修复效率。同时,本文提出的方法在训练时能够更有效地学习带噪音频到干净音频的映射关系,提高去除老电影音频中普遍存在的宽带噪声、脉冲型噪声和交流电噪声的能力。但是从实际听感出发,使用本文所提出的模型修复后的老电影音频,要比人工修复后的在某些地方具有更大的语音失真,语音质量还存在一定的差距。在今后的研究中,笔者将考虑如何有针对性地去除背景噪声,以最佳方案保留配乐和脚步声等配音效果。
