基于BERT的多特征融合农业命名实体识别
2022-04-16赵鹏飞赵春江吴华瑞
赵鹏飞,赵春江,2※,吴华瑞,王 维
(1. 山西农业大学工学院,太谷 030801;2. 国家农业信息化工程技术研究中心,北京 100097;3. 北京农业信息技术研究中心,北京 100097;4. 北京农业智能装备技术研究中心,北京 100097)
0 引 言
面对海量的非结构化农业文本数据,农业命名实体识别任务能够快速准确的识别农业实体,获取高质量的语义知识,为农业信息抽取与语义检索提供支撑,最终为基层农业技术员提供专业、个性化的决策信息服务。
命名实体识别(Named Entity Recognition,NER)任务中,基于统计机器学习的方法将实体识别当作序列标注任务来处理,常见的模型有隐马尔可夫模型、最大熵模型和条件随机场等。文献[5-7]基于条件随机场模型,构建不同组合的特征模板,对农业领域实体进行识别。但是,机器学习方法依赖人工制定的特征模板,耗时耗力,不具备领域通用性。近年来,基于深度学习的NER研究相继展开。与机器学习方法相比,深度学习通过自动学习特征,以端到端的形式训练模型,在生物化学、医疗文本、军事等领域取得了突破性进展。研究者使用Word2vec工具,预训练获取字向量,作为模型的输入。王欢等提出一种基于BiLSTM与具有回路的条件随机场相结合的方法,对机床设备故障领域的实体展开了研究。龚乐君等提出了一种基于领域词典和条件随机场的双层标注模型,从病历文本识别出疾病、症状、药品、操作四类实体。但是Word2vec生成的字向量是静态的,表征单一,无法解决一词多义的问题。为更好地提取文本特征信息,BERT被广泛应用于NER任务中。尹学振等提出BERT-BiLSTM-CRF实体识别模型,基于BERT的字向量表达层获取字级别特征,在军事领域进行实体识别研究。李建等将中文特征和句法语义特征相结合,完成对专利文本实体的识别。陈剑等基于BiLSTM-CRF模型融入BERT层,在司法文书语料库上进行实体识别,解决特征提取效率低的问题。此外,毛明毅等基于BERT-BiLSTM-CRF模型,有针对性的减少BERT嵌入层数,在中文数据集上验证了模型的有效性。
在农业领域,缺少公开标注的数据集,相关研究仍处于起步阶段。Guo等基于卷积神经网络和注意力机制搭建NER模型,有效识别农业病虫害等实体。目前农业领域的命名实体识别存在以下问题:1)模型无法解决一词多义的现象;2)罕见或未知实体的识别率低;3)农业外部词典利用不充分。
针对上述问题,本文面向农业领域提出一种基于BERT 和词典特征融合的命名实体识别模型BERT-Dic-BiLSTM-CRF,该模型引入BERT双向编码器,进行预训练,获取丰富的字级语义信息,解决一词多义的问题;针对农业领域外部词典丰富的特点,引入词典特征信息,提升模型对罕见实体的识别率。然后将字级向量与词典特征拼接,作为BiLSTM-CRF层的输入,最终获得全局最优的标记序列。
1 语料集构建
1.1 数据获取
本文使用轻量级爬虫框架Scrapy,在中国农药信息网、中国作物种质信息网、百度百科、国家农业科学数据中心等权威机构获取相应的文本数据,通过数据清洗、去噪、去冗等预处理,保证数据可靠性。结合领域专家知识对语料进行类别划分和标注,构建农业语料集,包含5 295条标注语料,共29 483个实体,涵盖农作物病害、农作物虫害、农药名称、农机名称、农作物品种名称5类实体。
1.2 标注体系
本文采用BIOE标注体系,其中,B-*代表实体的起始位置、I-*代表实体内部、E-*代表实体的结束位置、O代表非实体部分、*代表实体类别标签,标注示例如表1所示。

表1 语料库标注示例Table 1 Corpus labeling example
农业实体具有很强的领域专业性,通过制定标注策略,更好地确定实体边界,保证实体完整性。标注策略描述如下:
现象1:同一病害危害不同种类农作物,例如:水稻纹枯病、小麦纹枯病。
策略1:病害与农作物名称相连,区分不同农作物病害。
现象2:部分实体包含英文字母、特殊符号。例如:蚕豆萎蔫病毒(Broad Bean Wilt Virus,BBWV)病。
策略2:英文字母、特殊符号与实体相连作为一个整体。
现象3:同一虫害可危害不同种类农作物,例如:水稻管蓟马、小麦管蓟马。
策略3:虫害与农作物名称相连,区分不同农作物虫害。
2 命名实体识别模型
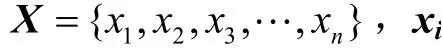
2.1 BERT
自然语言处理领域中,丰富、无监督的预训练是语言理解系统不可或缺的部分,Word2Vec是使用最广泛的模型。但Word2Vec提取的语义信息不足,无法表征字的多义性。农业文本中,实体存在不同语境下不同含义的现象,比如“油葫芦”在不同语境下属于虫害,危害棉花、花生等农作物,也可属于檀香科檀梨属植物—油葫芦。
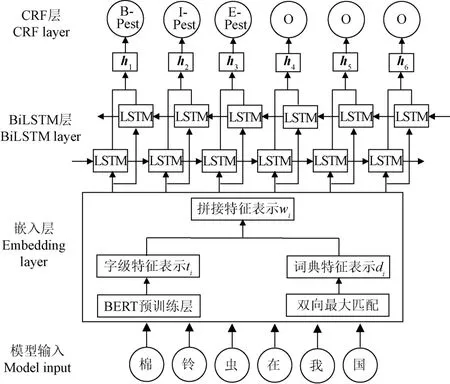
图1 BERT-Dic-BiLSTM-CRF模型结构Fig.1 Main framework of BERT-Dic-BiLSTM-CRF
为充分利用语句上下文信息,获取丰富的字级语义表示,本文引入BERT预训练模型,完成对语料集字级特征向量表示。BERT预训练模型基于双向Transformer编码器,通过遮蔽语言模型获取词级特征表示、以及下一句预测模型学习文本序列句子级的语义关系,更好的提取文本特征信息。
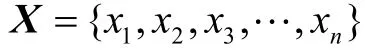

图2 BERT模型输入表示Fig.2 Input representations of BERT
2.2 词典特征
对于小规模语料库,模型学习到的实体信息有限,难以识别罕见或未知的实体。农业领域存在丰富的外部词典,词典与语料库文本存在着联系,可完成对语料库的信息补充。本文引入词典特征信息,将词典特征与通过BERT获取的字级向量融合,增强序列的语义信息,进一步提升模型性能。选取《农业大词典》中农药、农业机械、农作物等词目,并添加搜狗农业词汇大全词典、百度病害词典进行最新词汇的更新,完成外部词典的构建。词典涵盖5类实体,共9 185词汇。本文设计了N-gram特征模板法和双向最大匹配法两种方式抽取词典特征,用于增强农业实体的外部信息。试验结果表明双向最大匹配法优于N-gram特征模板法,适用于农业领域NER任务。
2.2.1 N-gram特征模板法


表2 N-gram特征模板Table 2 N-gram feature templates
本文构建的语料库中包含5种不同类型的实体,每个模板将对应一个5维的特征向量,表示其对应的实体类型。基于N-gram特征模板法,当=10时,字符将产生50维的词典特征向量,包含实体边界信息和类型信息,如图3所示。
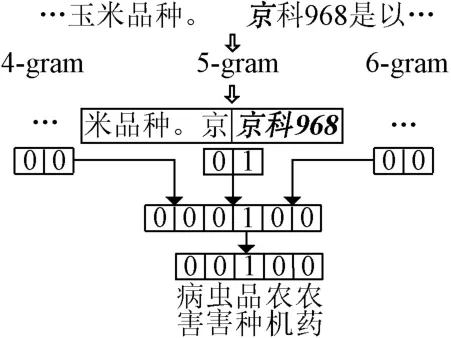
图3 N-gram特征向量Fig.3 The feature vector of N-gram
2.2.2 双向最大匹配法
基于双向最大匹配算法(Bi-Directional Maximum Matching,BDMM),完成对序列的切分,并与词典实体进行匹配,如果匹配成功则进行标记,保证将词典中存在的最长实体切分出来,如表3所示。双向最大匹配算法包含正向最大匹配和逆向最大匹配。其中,正向最大匹配步骤如下:
1)将序列的第一个字符设为当前字符,进行第2)步;
2)从当前字符开始,按照从左到右的顺序切分,得到字符串;在词典中查找字符串,如匹配成功,进行标记,进行第3)步;匹配不成功,进行第4)步;
3)将字符串的下一个字符设为当前字符,进行第2)步;
4)去掉字符串的最后一个字,进行第2)步;
5)重复2)~4)步,处理完序列为止。
最后,将正向匹配和逆向匹配结果进行对比,选择片段数量少的切分结果,并通过独热编码(One-hot Encoding)和特征嵌入(Feature embedding)两种方式构造特征向量,获得词典特征。
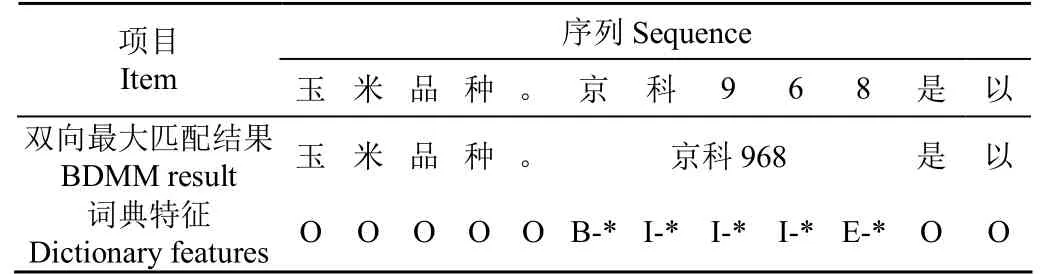
表3 基于双向最大匹配法构造词典特征Table 3 Construction of dictionary features based on bidirectional maximum matching method
2.3 BiLSTM-CRF





3 案例分析
3.1 试验数据集
为验证BERT-Dic-BiLSTM-CRF模型有效性,对自建的语料库按训练集、测试集、验证集为6∶2∶2比例进行划分,验证集用于验证模型训练及优化情况,三个数据集无重复交叉,因此测试集的试验结果可作为模型性能的评价指标。
3.2 试验设置
模型试验参数设置如下:利用BERT-Base模型,含有12个Transformer层,768维隐藏层和12头多头注意力机制。最大序列长度采用256,BiLSTM隐藏层维度为128,dropout设置为0.5,使用Adam优化算法,训练学习率0.001,批处理参数32,迭代次数100。通过准确率(Precision,)、召回率(Recall,)、值三个指标对模型进行评估。
3.3 结果与分析
3.3.1 不同字级嵌入的性能对比
本文以BiLSTM-CRF为基准模型,采用Word2Vec和BERT两种字级嵌入进行对比试验,结果如表4所示。基于BERT的字级嵌入与Word2Vec方式相比,模型准确率提高了5.5个百分点,值提高了5.25个百分点。试验发现,Word2Vec方式无法处理一词多义的问题,错误地把陕北民歌《东方红》识别为农机设备实体“东方红”,如图4所示。“东方红”为一词多义实体,在不同语境下,可表达为陕北民歌《东方红》,也可表达为农机实体“东方红”。BERT的嵌入方式,通过多层Transformer编码器,能够学习更多的语义特征,获取丰富的字级特征信息,正确识别“东方红”这类实体,有效缓解一词多义的问题。

表4 不同嵌入向量模型性能对比Table 4 Performance comparison of model with different embedded vector%

图4 多义词识别结果Fig.4 Result of polysemy recognition
3.3.2 不同词典特征的性能对比
基于BERT-BiLSTM-CRF模型,融入不同词典特征,在农业领域数据集上进行对比试验,结果如表5所示。融入词典特征的模型性能优于基准模型,其准确率分别提高了0.24、0.44、0.3、0.84、1.33个百分点。结果表明,词典特征的融入相较于单一字向量作为模型输入,能够有效补充序列语义信息,提升模型的识别准确度。
基于N-gram特征模板抽取词典特征,模板数量为8、10、12时,模型的准确率分别为93.75%、93.95%、93.81%;召回率分别为92.86%、94.12%、92.95%。从试验结果看出,适当增加模板数量,模型抽取的词典特征信息越丰富,当模板数量为10时,模型性能达到最优。随着模板数量的增加,词典特征信息维度越大,训练周期越来越长,模型识别准确率降低。
相较于N-gram特征模板法,基于双向最大匹配法模型性能得到进一步提升,而将词典匹配结果进行特征嵌入的方式优于独热编码方式。分析得出,N-gram方法忽略了实体内部结构,知识表示能力有限,对模型性能的提升低于双向最大匹配法。而采用特征嵌入的方式将匹配结果映射为低维的向量表示,能够获取更多的潜在信息,优于独热编码,模型准确率提高了0.49个百分点,值提高了0.91个百分点。
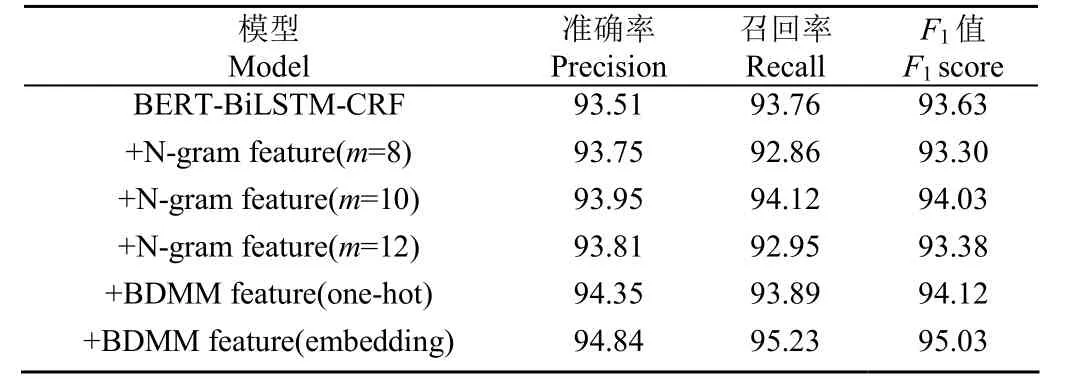
表5 不同词典特征模型性能对比Table 5 Performance comparison of model with different dictionary feature %
3.3.3 不同模型的性能对比
为验证BERT-Dic-BiLSTM-CRF模型在农业语料的识别性能,分别与BiLSTM-CRF 、CNN-BiLSTM-CRF、BERT-BiLSTM-CRF等主流模型进行了对比试验,试验结果如表6所示。BiLSTM-CRF模型准确率为88.01%、值为 88.38%。相较于 BiLSTM-CRF模型,CNN-BiLSTM-CRF模型通过CNN层抽取文本局部特征信息,与Word2Vec训练得到的字向量拼接作为BiLSTM层的输入,模型的准确率提高了1.71个百分点、值提高了0.14个百分点。但CNN-BiLSTM-CRF无法聚焦实体上下文信息,不能解决一词多义的问题。
引入BERT层的BiLSTM-CRF模型,通过BERT预训练模型充分提取字符级和序列上下文特征信息,更好地表征农业实体在不同语境下的语义表示,提升模型识别性能。相较于CNN-BiLSTM-CRF模型,识别准确率提高了3.79个百分点。本文提出的BERT-Dic-BiLSTM-CRF模型识别效果优于其他3种模型,识别准确率最高达到94.84%、值为95.03%。

表6 不同模型性能对比Table 6 Performance comparison of different models %
3.3.4 词典特征对模型性能影响
为验证模型引入词典特征可提高对罕见或未知实体识别准确率,统计测试集中实体在训练集出现的次数,将实体类型分为未知实体、罕见实体、高频实体,进行对比试验,试验结果如表7所示。其中,未知实体:测试集中实体从未出现在训练集;罕见实体:测试集中实体在训练集出现次数少于5次。高频实体:测试集中实体在训练集出现次数高于5次。

表7 不同实体性能对比Table 7 Performance comparison of different entity
由表7可知,因高频实体在训练集出现的次数较多,模型可学习到较丰富的特征信息,BERT-BiLSTM-CRF模型和BERT-Dic-BiLSTM-CRF模型识别准确率分别为94.17%、96.82%。对于未知实体和罕见实体,实体在训练集出现的频率较低,BERT-BiLSTM-CRF模型自身学习能力有限,识别准确率分别为73.85%、85.61%。引入词典特征信息的BERT-Dic-BiLSTM-CRF模型,通过外部领域知识信息的辅助,模型的泛化能力得到提升,相较于BERT-BiLSTM-CRF模型,识别准确率分别提高了6.44个百分点、5.93个百分点。进一步验证融入词典特征,能够提升模型对罕见或未知实体的识别准确率。
为验证词典规模对模型的影响,从自建的外部词典随机抽取60%、70%、80%、90%的实体构造4个大小不同的词典进行对比试验,试验结果如图5所示。
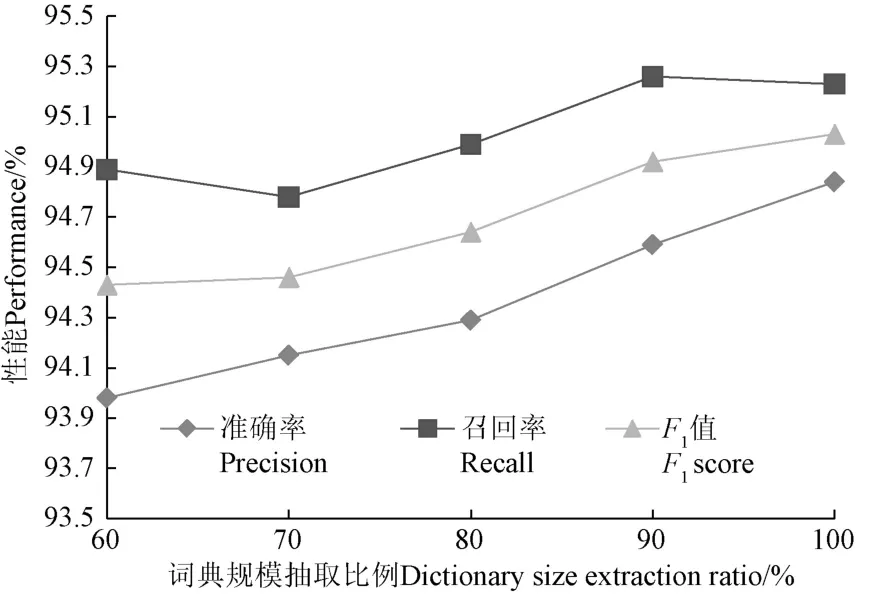
图5 词典规模对模型性能的影响Fig.5 The impact of the different dictionary size on model performance
由图5可知,随着词典规模的增大,模型学习到的特征信息更丰富,模型性能也随之得到提升,准确率达到94.84%。
4 结 论
1)针对农业领域命名实体识别任务,提出BERT-Dic-BiLSTM-CRF模型,该模型结合字向量和词典特征能够处理一词多义问题,提升模型对罕见或者未知实体的识别准确率,模型准确率为94.84%、值为95.03%。
2)基于BERT预训练模型获得字级别的特征表示,能够聚焦实体上下文的语境,丰富农业文本的语义表示,缓解一词多义的问题,提升模型识别性能。
3)本文构建了农业领域外部词典,并设计了2种构建词典特征信息的方法。经试验验证,基于特征嵌入方式的双向最大匹配法能够获取丰富的词典特征,适用于农业NER任务。
随着智慧农业的不断发展,农业信息化决策服务更具体、更快捷。因此,下一步工作是增加农业病虫害病原、病害部位实体丰富语料库,并制定更规范、更完善的标注策略,在保证模型性能的基础上,对模型结构进行优化。
