用于灌溉耕地制图的特征变量优选
2022-04-16朱秀芳
刘 莹,朱秀芳,徐 昆
(1. 北京师范大学遥感科学国家重点实验室,北京 100875;2. 北京师范大学环境演变与自然灾害教育部重点实验室,北京 100875;3. 北京师范大学地理科学学部遥感科学与工程研究院,北京 100875;4. 山东黄河河务局山东黄河信息中心,济南 250013)
0 引 言
灌溉是一种重要的土地管理方式,是用来增加作物产量或者减轻干旱等极端气候所造成的消极影响的重要手段。在过去的50年里,全球灌溉面积增加了接近一倍。灌溉耕地占全球耕地面积的20%,贡献了40%的粮食产量。灌溉一方面能够维持作物产量的稳定,促进作物产量的增长,保证面对气候变化以及干旱、洪水和热浪等极端气候事件时的粮食安全,另一方面又会增加土壤湿度和地表蒸散,降低近地面地表温度,改变热通量的分割和水分的再分配,对水循环、能量循环、生物圈和大气圈的相互作用以及气候变化产生间接影响。
明确灌溉的空间范围、类型以及时序变化有助于开展粮食安全、水资源管理和气候变化等相关研究,灌溉耕地制图的发展也会为相关研究提供更多的数据基础和实践的可能性。目前灌溉耕地制图的方法可以归纳为两个类型:基于遥感分类的灌溉耕地制图和基于统计数据空间化的灌溉耕地制图。基于遥感分类的灌溉耕地制图通常会利用单个或者一系列光谱特征和变量作为灌溉耕地和其他地物类别的区分特征,采用监督或者非监督的分类方法来提取灌溉耕地。基于统计数据空间化的灌溉耕地制图通常分为两个步骤进行:1)建立空间分配规则;2)依据空间分配规则,将表征灌溉耕地信息的统计数据分配到格网上。第一步中用来建立分配规则的特征通常是能够表示灌溉耕地信息相对数量的特征量,例如灌溉设施分布、作物复种指数等。另外,在统计数据空间化方法中,还有一些学者自定义了一些参数来进行灌溉范围的确定。例如,2014年Zhu等利用归一化植被指数(Normalized Difference Vegetation Index, NDVI)和降水数据依据长期作物产量高且稳定的区域有更大几率被灌溉以及灌溉比雨养的作物产量更加稳定的假设创建了三个灌溉潜力指数,依据灌溉潜力指数的大小对灌溉普查数据进行空间分配得到2000年中国1 km空间分辨率的灌溉耕地和雨养耕地密度产品。2019年Zohaib等使用卫星数据集与地表模型模拟的再分析数据集之间土壤湿度的正偏差以及地表温度和地表反照率的负偏差识别灌溉的空间范围,第一次采用自下而上的方法监测了全球实际灌溉区域。
无论是基于遥感分类的灌溉耕地制图还是基于统计数据空间化的灌溉耕地制图,构建和选择表征灌溉耕地信息的特征变量都是最重要的环节之一。以往大量研究均指出特征变量的选择对于分类的精度影响很大。例如,朱秀芳等分析了不同分类特征对冬小麦面积测量精度影响,指出纹理特征和植被指数的加入,不一定能提高分类精度,最优特征和研究区本身的特点以及分类器等都有关系。研究者往往在分类前会对分类特征进行优选。例如,刘杰等基于多时相Landsat 8 OLI数据,提取光谱、纹理、植被指数等217个特征波段,利用随机森林中的基尼系数(GINI Coefficient)优选特征子集,在新疆维吾尔自治区阿克苏地区温宿县进行了作物类型的精细识别。朱秀芳等利用灰度共生矩阵提取无人机影像的纹理特征,使用随机森林算法进行纹理特征优选,在此基础上提取了覆膜农田的面积和分布。王庚泽等提出了改进分离阈值组合式特征优选算法,从多时相的Sentinel 2原始光谱波段、不同时相波段差值和比值、传统植被指数和红边植被指数、第一主成分的纹理特征合计183个特征中选择最佳特征,进而利用随机森林算法提取河北省藁城区的秋粮作物。
目前常用的灌溉耕地制图的特征变量中,各变量对灌溉耕地识别精度的贡献并不相同。明确变量贡献大小可以指导后续其他地区进行灌溉耕地制图特征变量的选择,进而提高灌溉耕地的特征变量的选择效率和最终的识别精度。为此,本研究基于随机森林,在美国内布拉斯加州,对灌溉耕地制图中4类82个特征变量进行比较分析,优选最佳特征变量,为后续相关研究中特征变量的选择提供参考。
1 研究区概况
本研究选择美国的内布拉斯加州(Nebraska)作为研究区(图1),该州纬度位置位于40°N~43°N之间,经度位置位于95°W~105°W之间。内布拉斯加州有39%的土地面积被用于农业生产,是美国主要的农业生产地区之一。该州有超过10万的活跃灌溉水井,并且每十年的灌溉水井增量达1万个,是世界上灌溉最密集的区域之一。该州主要的种植作物包括玉米(2017年收获面积占比50%)和大豆(2017年收获面积占比30%),其他次要作物包括冬小麦,高粱和苜蓿(2017年总收获面积占比约11%)。4-10月是该州主要作物的生长季。近年来有学者制作了包含该地区的长时间序列中高分辨率灌溉耕地分布图。选择该州作为研究区便于利用已有的灌溉耕地数据产品选择样本数据进行灌溉特征变量的对比分析。
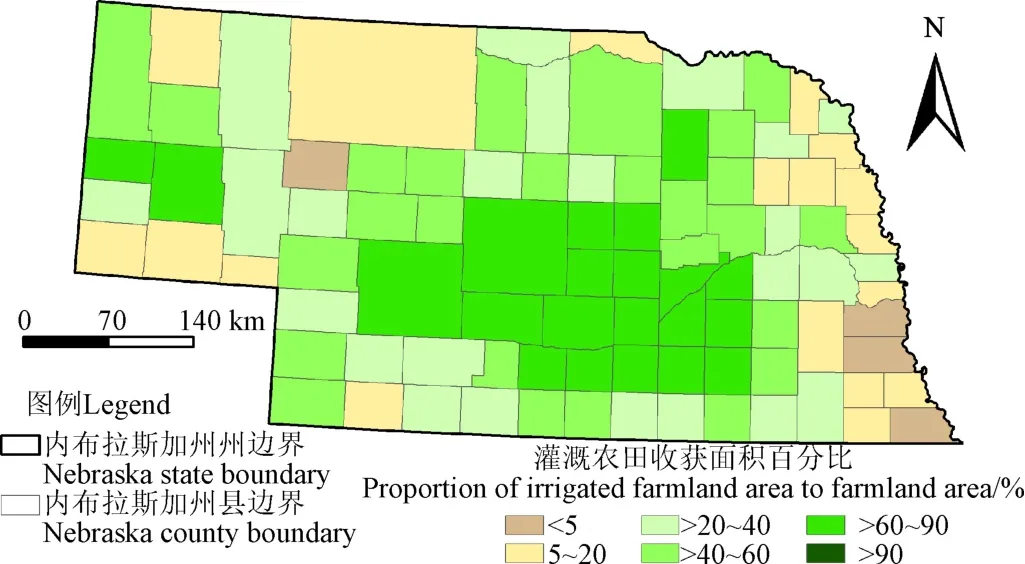
图1 2017年美国内布拉斯加州灌溉农田面积占农田面积比例Fig.1 Proportion of irrigated farmland area to farmland area in Nebraska, United States in 2017
2 数据与方法
2.1 数据说明
本研究的输入数据主要包括4个部分:气象数据、遥感数据、灌溉数据和辅助数据(表1)。数据的基本信息和预处理过程如下:
1)气象数据为Prism降水数据,来源于俄勒冈州立大学的 PRISM 气候研究组,下载网址为:http://prism.oregonstate.edu/recent/。该数据的空间分辨率为0.04°,空间参考为GCS North American 1983。
2)遥感数据包括MOD09A1 反射率,MOD11A2 地表温度数据(Land Surface Temperature, LST),MOD13A1的增强型植被指数(Enhanced Vegetation Index, EVI)和标准化差值植被指数(NDVI),MOD16A2实际蒸散发(Actual Evapotranspiration, AET)和潜在蒸散发(Potential Evapotranspiration, PET),下载网址为https://lpdaac.usgs.gov/products/。这些数据的空间参考类型为GCS WGS 1984,空间分辨率为500 m或者1 000 m,时间分辨率为8 d或者16 d。
3)灌溉数据包括美国高平原含水层年度灌溉图(Annual Irrigation Maps-High Plains Aquifer,AIM-HPA)、中分辨率成像光谱仪灌溉农业数据集(The Moderate Resolution Imaging Spectroradiometer Irrigated Agriculture Dataset for the United States,MIrAD-US)、内布拉斯加州灌溉设施分布图和已注册灌溉水井矢量数据。AIM-HPA是覆盖美国高平原含水层的1984-2017年每年30 m空间分辨率的灌溉耕地数据集。该数据集是由Deines等利用Landsat影像、环境变量和地面实况数据,基于随机森林分类器分类,并在分类后应用贝叶斯土地覆盖更新算法填补图像空白,降低灌溉时间序列中的误差得到的。MIrAD-US是由美国地质调查局地球资源观测与科学中心开发的与美国农业普查数据同步更新的美国灌溉农业数据集。该数据集是利用统计数据空间化的方法建模得到,以统计数据作为总量约束,以年NDVI峰值作为分配依据,将灌溉面积统计数据分配到空间格网上得到的。该数据集包含2002、2007、2012和2017年空间分辨率为250和1 000 m的灌溉耕地数据。内布拉斯加州灌溉设施分布图由内布拉斯加大学林肯分校先进土地管理信息技术中心提供。该数据图层以面状矢量文件的形式提供了根据2005年多时相的Landsat 5卫星影像和农业服务局的正射影像确定的内布拉斯加州2005年生长季的中心枢纽灌溉系统和其他灌溉系统分布图。内布拉斯加州已注册灌溉水井来源于内布拉斯加州自然资源部网站提供的注册地下水井数据。该数据以矢量点的形式存储,利用其属性表筛选出用途为灌溉且状态为活跃的水井构成已注册活跃灌溉水井数据。
4)辅助数据包括农作物图层、作物物候和研究区矢量。农作物图层是由美国农业部的美国国家农业统计局提供的农作物数据图层,空间分辨率为30 m。作物物候数据来源于美国农业部的美国国家农业统计局于2010年10月发布的农作物播种和收获日期。该数据主要被用来根据内布拉斯加州主要农作物的播种和收获时间确定研究中待分析数据的候选时间:4—10月。研究区内布拉斯加州的矢量边界数据来源于GADM (Database of Global Administrative Areas)。GADM提供所有国家以及地区的行政边界图,其下载网址为http://www.gadm.org/。
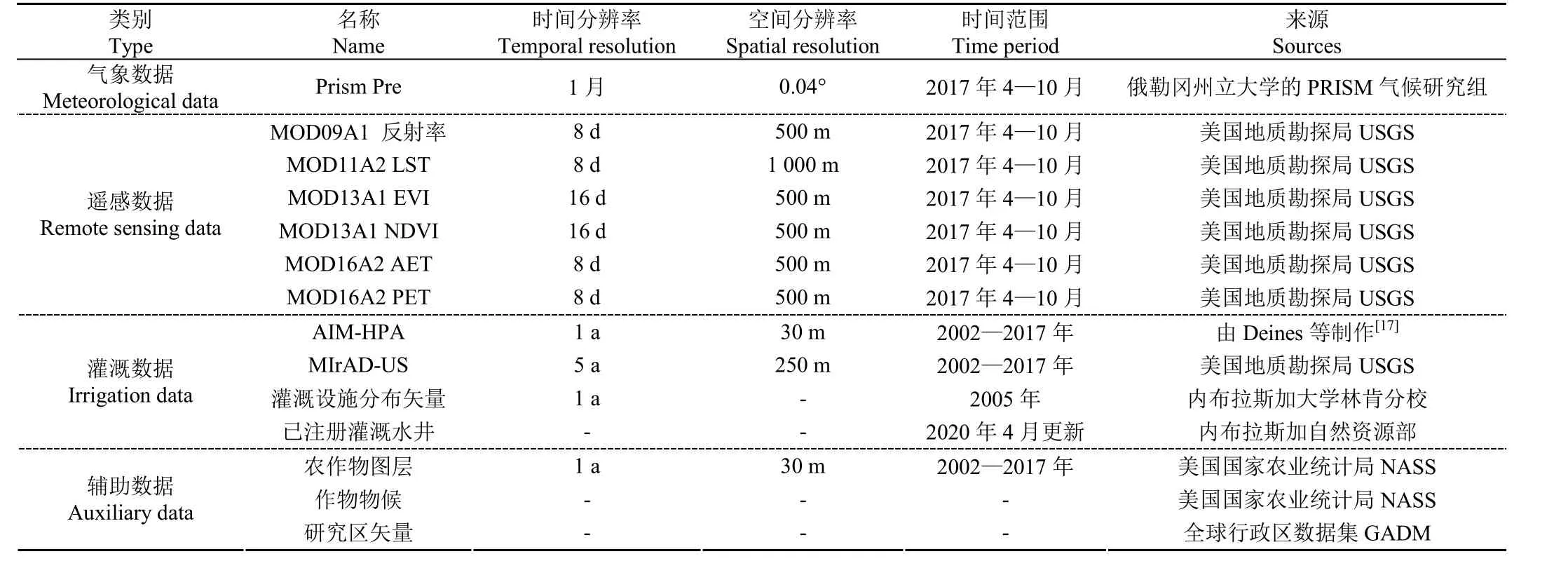
表1 数据说明Table 1 Data description
将所有气象数据和遥感数据的空间分辨率统一到500 m,时间分辨率统一到月尺度,空间参考统一为Albers Conic Equal Area。将其他数据的空间参考统一为Albers Conic Equal Area。
2.2 随机森林特征变量评价原理
随机森林由Breiman于2001年提出,它是一个包含多个决策树的集成分类器,其中的每棵决策树之间都是没有关联的。对于每个输入样本,每棵决策树都会给出一个分类结果,最后取所有决策树中分类结果最多的类别作为这个输入样本的最终分类结果。随机森林算法分类精度高、处理速度快、可处理高维数据和多重共线性数据且对过度拟合不敏感,是遥感分类的常用算法之一,也曾被成功应用于灌溉耕地制图的研究当中。
随机森林算法还可以对特征变量的重要程度和贡献进行分析评价,以保证使用最少的特征数量达到最佳的分类精度,通过特征变量的筛选,可以减少分类数据的冗余、降低不可靠变量对分类效果的影响、提高遥感分类的工作效率,并为后续相关研究进行特征变量的选择提供依据。在随机森林算法中主要有两个指标可以对特征进行重要性评估:一种是基于袋外误差的平均准确度降低值(Mean Decrease Accuracy, MDA);另一种是基于基尼不纯度的平均不纯度降低值(Mean Decrease Gini, MDG)。本文选择与分类精度关系更加密切的MDA进行特征重要性的评估。随机森林每棵决策树的生成过程中都有接近三分之一的样本没有被使用,这些样本被称为袋外样本。MDA主要是利用这些袋外样本来对变量的重要性进行评估,其计算过程大致分为以下3个步骤:1)对于每棵决策树,袋外样本数据的预测错误率都会被记录下来;2)将袋外样本数据的特征变量的值随机打乱(这个步骤相当于依次将待评估的特征变量替换成噪声),再次记录下来袋外样本数据的预测错误率;3)对于每棵决策树,计算这两次袋外样本预测错误率的差值,将所有决策树上的差值求均值。其表达公式如下:
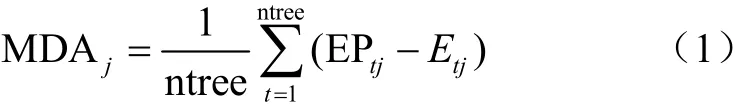
式中ntree代表这个森林中树的数量,E代表第棵树在对X特征变量的值随机打乱之前的袋外样本错误率,EP代表第棵树在对X特征变量的值随机打乱之后的袋外样本错误率。MDA的值越大,表示当前特征被替换成噪声后对模型预测精度的改变程度越大,也就是这个特征的重要性越高。
2.3 研究方法
2.3.1 样本点选择
结合作物图层CDL、已有的灌溉耕地分布图AIM-HPA和MIrAD、内布拉斯加州灌溉设施分布图和已注册灌溉水井分布图,按照下述规则在研究区内选取灌溉耕地样本点和雨养耕地样本点。
灌溉耕地样本点的选取规则分为两类:第一类适用于AIM-HPA灌溉耕地分布图有覆盖的区域;第二类适用于AIM-HPA没有覆盖的内布拉斯加州东部区域(图2)。第一类选取规则需要同时满足以下条件:1)AIM-HPA在2002-2017年均为灌溉耕地;2)MIrAD在2002、2007、2012和2017年均为灌溉耕地;3)2005年具有灌溉设备的区域。由于AIM-HPA没有覆盖的内布拉斯加州东部区域属于湿润地区,该地区的水分供给比较充足,对于灌溉的需求较少,经过叠加分析发现该部分地区MIrAD在2002、2007、2012和2017年四年均为灌溉耕地的像元也比较少,因此第二类选取更改为需要同时满足以下条件:1)MIrAD在2017年为灌溉耕地;2)2005年具有灌溉设备的区域;3)靠近已注册活跃灌溉水井点。

图2 高平原含水层年度灌溉图(AIM-HPA)及在研究区中的覆盖情况Fig.2 Annual Irrigation Maps-High Plains Aquifer (AIM-HPA)and its coverage in the study area
由于AIM-HPA和MIrAD灌溉作物分布图只包含灌溉作物像元,因此需要结合作物图层CDL对雨养耕地样本进行提取。对于30 m空间分辨率的AIM-HPA,采用重新编码后的30 m分辨率的作物图层进行雨养耕地的提取:将AIM-HPA为非灌溉耕地像元且CDL为作物的像元识别为雨养耕地。对于250 m空间分辨率的MIrAD,采用重新编码且进行众数聚合后的250 m分辨率的作物图层进行雨养耕地的提取:将MIrAD为非灌溉耕地像元且CDL为作物的像元识别为雨养耕地。雨养耕地样本点的选取规则也按照AIM-HPA有无覆盖分为两类。在AIM-HPA有覆盖的区域需要同时满足以下条件:1)AIM-HPA在2002-2017年均为雨养耕地;2)MIrAD在2002、2007、2012和2017年均为雨养耕地;3)2005年不具有灌溉设备的区域。在AIM-HPA没有覆盖的区域需要同时满足以下条件:1)MIrAD在2017年为雨养耕地;2)2005年不具有灌溉设备的区域;3)远离已注册活跃灌溉水井点。
依据以上规则选择了440个灌溉耕地样本点和343个雨养耕地样本点。
2.3.2 特征变量计算
本研究选取一些常用于表征耕地受灌溉可能性的特征变量作为遥感分类中的候选特征变量,包括气象特征变量、植被特征变量、土壤特征变量以及一些经过多个特征运算得到的综合特征变量,其中一些变量包含了生长季内每个月份以及整个生长季内的值,总计共82个特征变量,每个特征变量的计算方法以及其他信息如表2所示。
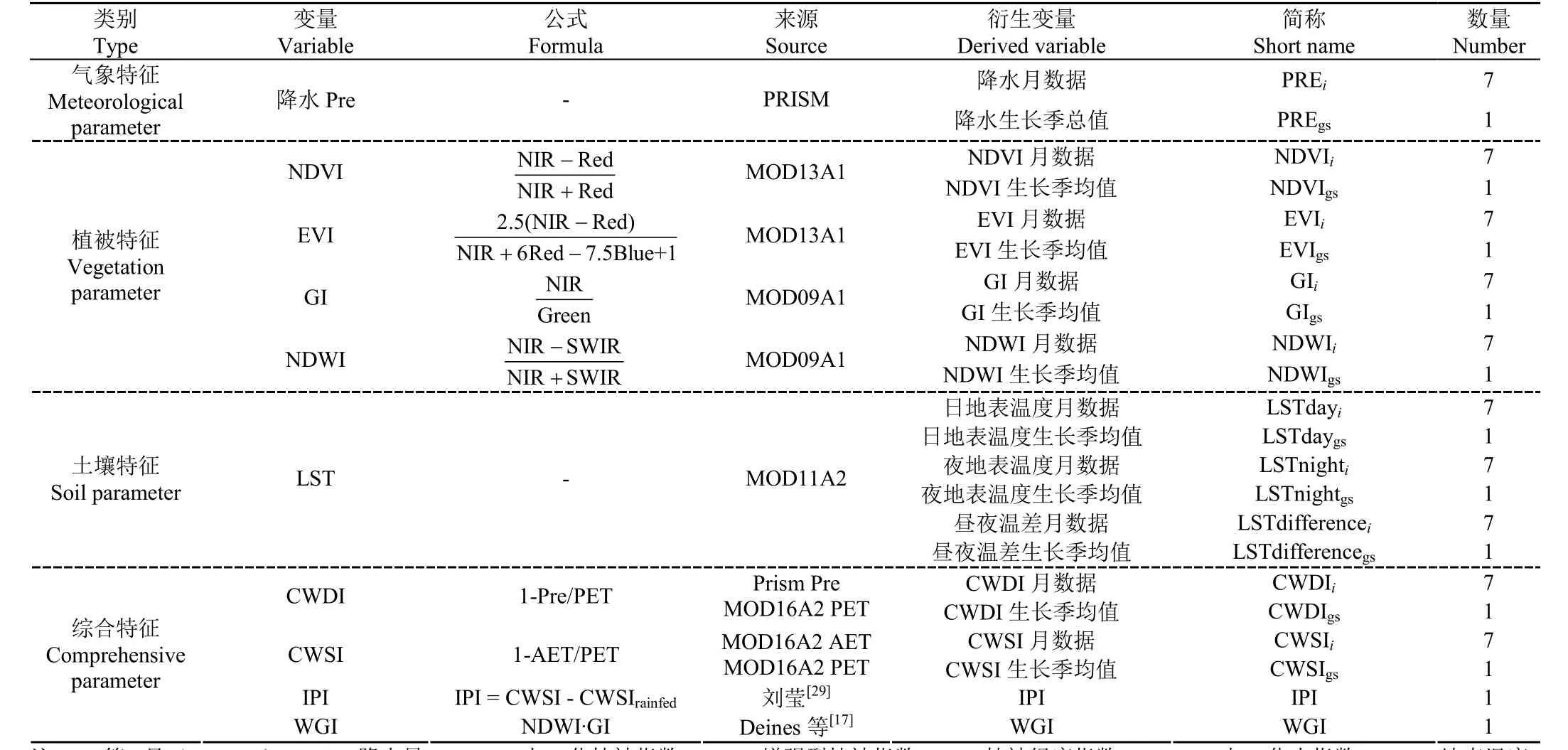
表2 待分析的特征变量Table 2 Feature variables to be analyzed
气象特征变量包括能对作物可用水分产生直接影响的降水量(Precipitation, Pre)数据。气象条件是决定农作物生长状态的基础条件,也是决定是否需要进行灌溉的先决条件。
植被特征变量主要包含植被的生产力水平以及植被的含水量情况。其中,生产力水平是利用植被指数来表示的。植被指数是监测作物长势以及生产力水平的有效手段,也是作物所处的气候条件以及是否受到灌溉等人为管理措施的间接体现。当气候条件适宜时,灌溉是增加作物可用水分、提高植被生产力的有效方式;当作物受到干旱等极端气候条件的胁迫时,灌溉可以通过改变作物产量波动的阈值或者使得作物产量与气候条件解耦来保持作物生产力水平的稳定性。因此,可以通过植被指数反映的作物生长状况来间接反映作物的生长过程中是否有灌溉的参与。本研究共选取了三种植被指数作为候选的植被特征变量:归一化植被指数(NDVI)、增强型植被指数和植被绿度指数(Greenness Index, GI)。植被的含水率情况是用归一化水指数(Normalized Difference Water Index, NDWI)表示的,该指数可以反映植被冠层的液态水含量。
土壤特征变量利用地表温度(Land Surface Temperature,LST)表示。研究表明,灌溉可以提高土壤湿度,增加农田的蒸散量,改变地表属性,这些生物物理影响也会进一步影响到地表能量的分割,反馈到局部气候上使得地表温度降低。因此,地表温度也可以作为间接反映作物是否被灌溉的特征变量。本研究中选取了日地表温度(LSTday)、夜地表温度(LSTnight)以及昼夜温差(LSTdifference)作为分类过程中候选的土壤特征变量。
除了单一元素的特征变量外,本研究还加入了四个结合多个特征运算得到的综合特征变量,包括灌溉概率指数(Irrigation Probability Index, IPI)、作物水分亏缺指数(Crop Water Deficit Index, CWDI)、作物水分胁迫指数(Crop Water Stress Index, CWSI)和水分调整绿度指数(Water-adjusted green index, WGI)。
2.3.3 特征变量评价和优选
随机森林算法需要进行两个重要参数的设置:决策树的数量(ntree)和树木生长时为达到最佳分割效果选择的分裂属性个数(mtry)。理论以及经验上的研究表明:分类精度对于决策树数量的敏感程度低于分裂属性个数,由于随机森林分类器的计算效率较高而且不会过拟合,决策树的数量可以设置的尽可能大。通常,选择一个使得分类误差达到稳定的决策树数量即可。分裂属性个数通常会被设置为输入变量数的平方根。
本研究利用R语言的randomforest程序包实现随机森林分类算法。首先,将决策树数量设置为一个较大的数值(设置ntree=1 000),保证在这个数量下的分类误差已经达到稳定,依次设置分裂属性mtry=1,2,3,…,81(变量总个数为82)进行试验,得到模型的袋外样本误判率均值随着mtry的变化情况,找出模型袋外样本误判率均值达到最低时的mtry取值作为mtry最优值。固定mtry值为最优值,绘制ntree=1,10,20,50,100,200,300,400,500,600,700,800,900,1 000时,决策树数量与袋外样本误判率均值的关系图,选择袋外样本误判率均值的变化低于0.1%的临界值,将其作为ntree的最优取值。
依据确定的适用于特征选择过程的最佳mtry和ntree参数,利用MDA对备选的82个特征变量进行了重要性评估。将此82个变量按照MDA重要性降序排列,从重要性最高的变量开始,依次添加变量进行随机森林分类(由于该步骤中变量数在随时变化,因此将mtry设置为变量数的平方根,ntree仍然设置为特征选择过程中得到的最佳ntree值),利用袋外样本的总体分类精度对分类效果进行评价,找出分类精度最高时对应的特征变量,作为优选出的特征变量集合。
3 结果与分析
3.1 随机森林特征评价最优参数的取值
当决策树数量固定为1 000时,模型的袋外样本误判率均值随着mtry的变化情况结果如图3所示。mtry的取值对模型误判率的影响整体波动不超过4%,当mtry=11时,模型袋外样本误判率均值达到最低,为11.33%,当mtry=9,与输入变量数的平方根接近时,模型袋外样本误判率均值次低,为11.36%。因此,分裂属性个数mtry的最优取值为11。
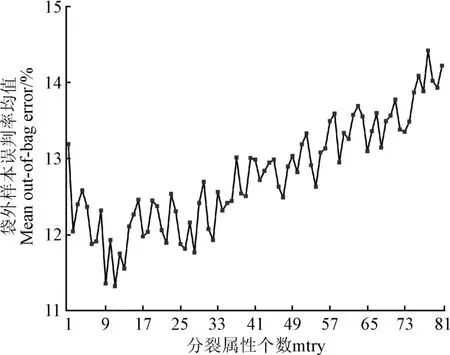
图3 分裂属性个数(mtry)与袋外样本误判率均值的关系Fig.3 The relationship between the number of split attributes(mtry) and the mean out-of-bag error
mtry参数固定为11,ntree为1、10、20、50、100、200、300、400、500、600、700、800、900、1 000时绘制得到的决策树数量与袋外样本误判率均值的关系图如图4所示。当决策树数量低于300时,决策树数量的变化会对模型的分类效果产生比较显著的影响;决策树数量达到300后,袋外样本误判率均值逐渐趋于稳定;当决策树数量达到500后,决策树数量每增加100,袋外样本误判率均值的变化低于0.1个百分点。因此,决策树数量ntree的最优取值为500。

图4 决策树数量(ntree)与袋外样本误判率均值的关系Fig.4 The relationship between the number of decision trees(ntree) and the mean out-of-bag error
3.2 分类特征优选结果
设定mtry=11,ntree=500,利用MDA对备选的82个特征变量进行了重要性评估,按特征重要性排序依次加入特征进行分类,利用袋外样本进行精度评价得到的结果如图5所示。由图可知,重要性前4的特征变量(CWSI,EVI,CWSI和IPI)对提升整体分类精度的影响比较大,重要性5~16的特征变量会提高模型的分类精度,但是单个变量的加入对提升模型分类精度的影响比前几个变量有所降低,在加入重要性前16的特征变量后分类结果基本达到稳定,总体分类精度达到88.44%。分类的特征变量数增加到16以后,随机森林模型的分类精度呈现小幅度上下波动,表示重要性程度排在16位以后的特征变量对提升模型的分类效果影响不大。因此本研究选取重要性程度前16位的特征变量为最优特征变量集合。具体每个变量的重要性程度及加入变量后的总体分类精度如表3所示。
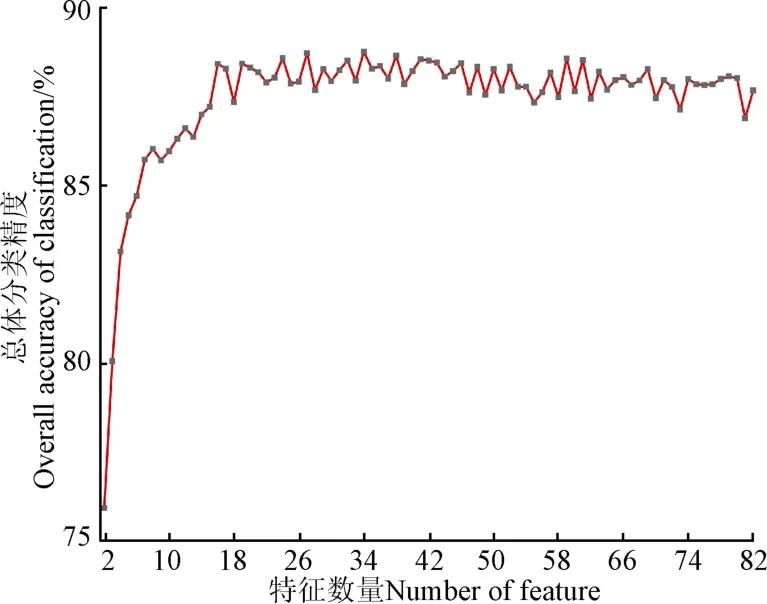
图5 特征数量与分类精度的关系Fig.5 Relationship between the number of features and classification accuracy
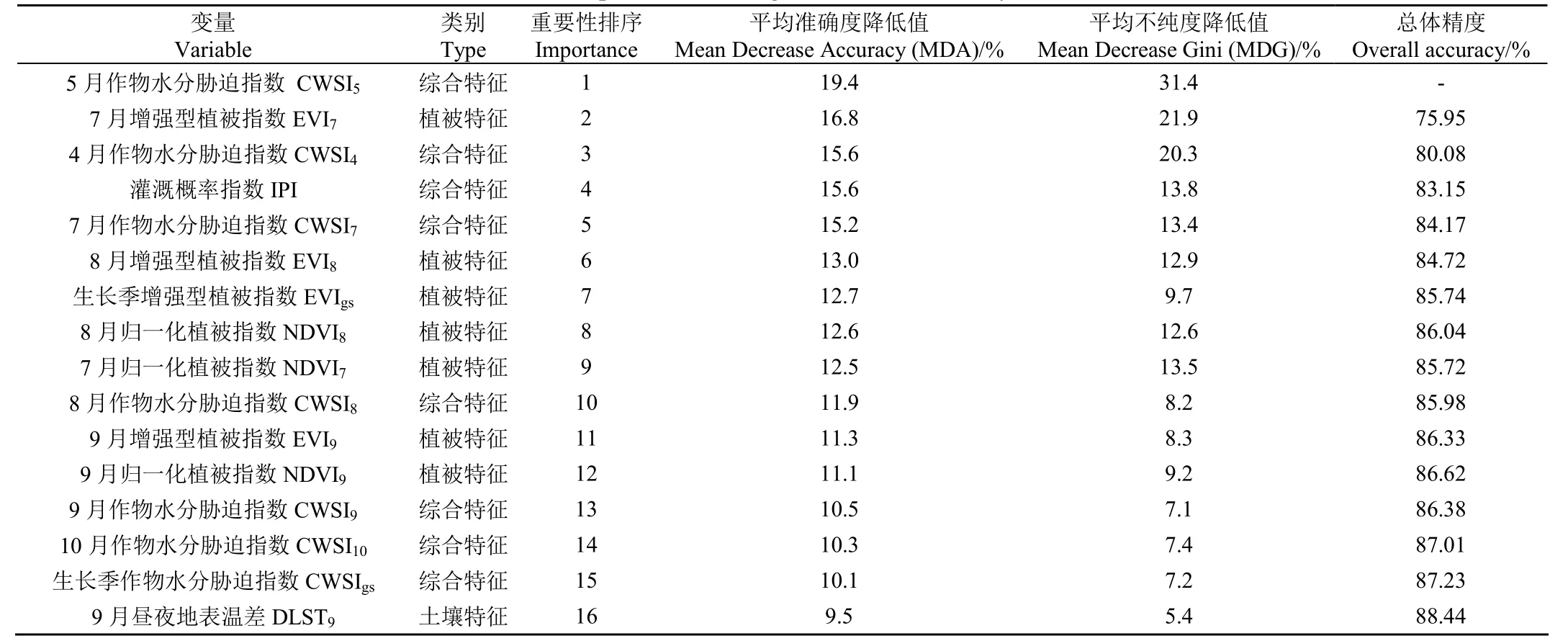
表3 特征重要性排序及分类总体精度Table 3 Feature importance ranking and overall accuracy of classification
在选取出的16个最佳特征变量中,包含8个综合特征变量、7个植被特征变量以及1个土壤特征变量,气象特征变量没有入选。农业干旱指数(作物水分胁迫指数)、灌溉概率指数、植被指数以及昼夜温差是区分灌溉农田和雨养农田的敏感特征变量。除了灌溉概率指数不是具备多个时相的特征变量外,其他特征变量的不同时相对于灌溉农田和雨养农田的区分也具有不同的敏感性。对于作物水分胁迫指数来说,几乎生长季内各个月份以及整个生长季的作物水分胁迫指数(CWSI、CWSI、CWSI、CWSI、CWSI、CWSI和CWSI)都具有较高的敏感性;对于植被指数(EVI、EVI、EVI、EVI、NDVI、NDVI和NDVI)来说,对灌溉农田和雨养农田的区分较为敏感的时相集中在生长季的后期;对于昼夜温差来说,9月份是区分灌溉农田和雨养农田的最敏感时相。
4 讨 论
本研究的结果进一步证实了遥感分类特征对于待分类目标的识别精度具有很大的影响,从表3可以看出,使用重要性排在前16的变量进行灌溉农田制图时比仅使用重要性排在前2位的变量进行灌溉农田制图的精度提高了12.49个百分点,加入更多的重要性排序靠后的特征对分类精度的提升没有作用,甚至起到负作用。因此,在进行灌溉制图之前有必要进行特征选择工作。
由特征选择的结果可以看出,综合特征变量对灌溉农田的识别最有帮助,而气象特征变量对灌溉农田制图的帮助最小。灌溉可以缓解作物水分胁迫,减缓或者抑制农业干旱的发生,进而促进作物生长,相比雨养作物同类的灌溉作物的植被生产力更高,灌溉也会影响地表参数,例如使地表温度降低、蒸散增强、土壤湿度增加。缺少降水只能决定灌溉需求,但不能决定是否真的发生了灌溉,因此降水特征变量在本研究中表现出最低的重要性。而能反映灌溉效果或灌溉可能性的指标,如作物水分胁迫指数CWSI,灌溉概率指数IPI和植被指数更有助于判断是否发生了灌溉。简单来说从灌溉结果出发比从灌溉的诱因出发去选择特征变量能更有效地判定是否发生了灌溉。
研究结果还显示同一特征变量在不同时间对于灌溉的识别能力不同,整体来说,各个月份的作物水分胁迫指数CWSI对于灌溉的识别都很有帮助,这也是容易理解的,因为灌溉最直接的作用就是缓解农业干旱。CWSI由1-AET/PET计算得到,目前MODIS数据提供了AET和PET产品,该数据在某些地区存在缺失,提高该数据产品的质量有益于推动基于该数据产品的灌溉耕地产品的生产。
本研究针对灌溉农田制图的特征变量选择问题进行了有益的探索,相关结果可以为其他研究者筛选灌溉农田制图的特征变量提供参考。但本研究也存在一些不足之处:
1)本研究的研究区为美国的内布拉斯加州,其主要的种植作物为玉米和大豆,尚未在其他种植结构不同的地区进行分析。中国是农业大国,其灌溉用水量和灌溉面积均位居全球前列。本文所提出的方法在中国有很大的应用潜力,然而中国的耕地地块相比美国更加破碎,种植结构更加复杂,且南北方差异大,在干旱和半干旱区为了节约用水,往往以补给灌溉为主,相比充分灌溉,补给灌溉的信号更弱,可能会影响识别的效果。未来还需要选择南北方种植结构不同的典型灌区,进一步的验证本文所提出的方法。
2)特征选择方法大致分为过滤式(Filter)和封装式(Wrapper)两种。前者在数据预处理步骤中对特征排序,设定阈值选择最优特征子集,排序准则有相关系数、互信息等。后者将分类特征与学习算法相结合,根据准确率评价每个特征子集,从而选择最优特征子集。本文所用的随机森林就是封装式特征选择方法的一种。与过滤式特征选择方法相比,随机森林对噪声数据和存在缺失值的数据具有较好的鲁棒性,其预测能力不受多重共线性影响。但是一些具体多重共线性的特征(如NDVI和EVI)的重要性会被相互抵消,从而影响对特征变量的解释性。对于高度相关的特征变量会存在信息冗余。未来考虑综合使用过滤式和封装式的特征选择方法,以减少特征变量的信息冗余和提高特征变量的可解释能力,找到普适性的灌溉耕地制图特征变量,服务于大范围灌溉耕地制图产品的生产。
5 结 论
本文选择有良好灌溉信息数据基础的美国内布拉斯加州为研究区,基于已有耕地空间分布图和灌溉信息数据,提取灌溉耕地样本和雨养耕地样本,计算了样本的82个特征变量,利用随机森林对比分析了82个特征变量对灌溉耕地识别的重要性,得到如下主要结论:
1)5月作物水分胁迫指数,7月增强型植被指数,4月作物水分胁迫指数和灌溉概率指数是重要性前4的特征变量,对提升灌溉耕地制图精度的影响最为明显。利用重要性前16的特征变量分类得到的总体分类精度最高,为88.44%。
2)四类特征变量中,对灌溉耕地识别的贡献程度由大到小为综合特征变量、植被特征变量、土壤特征变量、气象特征变量。
3)不同特征变量识别灌溉农田的最佳时相也存在差异。生长季后期的植被指数和9月的昼夜温差相比其他月份的植被指数和昼夜温差更有利于灌溉耕地识别。而对于农业干旱指数来说,几乎生长季内所有的月份都有助于灌溉耕地的识别。
