活动模式的挖掘及其相关趋势分析
2022-04-15宋玲吕舜铭刘洪鑫吕强牛小飞刘新锋
宋玲,吕舜铭,刘洪鑫,吕强,牛小飞,刘新锋
1. 山东建筑大学 计算机科学与技术学院,山东 济南 250101
2. 国家电网公司信息通信分公司,北京 100031
3. 国网技术学院,山东 济南 250002
随着越来越多的传感器和移动设备的普及以及智能化,用户的活动行为及其活动轨迹等信息也越来越容易获取,逐渐积累了越来越丰富的人类活动数据集。借助于机器学习等方法来挖掘这些大数据,获取人群的活动模式及其发展趋势,并且挖掘其相关的社会人口学模式,可以有助于更好地理解人类行为,是个人信息需求分析的基础,同时也是提高各种智能系统的关键,可以为推荐系统、电子商务以及城市规划等应用提供数据和决策支持。
基于人群活动行为的模式理解是极其复杂的,涉及到活动的各种属性,包括活动的类型,发生的时间、地点,参与者以及活动轨迹。人类的活动行为的表现及其时间分配实质上又受社会人口学影响。因此对人群活动行为的模式挖掘具有较大的难度。模式挖掘的首要任务是计算人的活动行为之间的相似度,所以首先需要抽取出描述活动行为的属性。人类活动行为可以用不同的属性来描述。作为对活动行为的一种描述, Ying 等[1]提出活动行为相似度通过最大活动轨迹来计算。Zhang 等[2]使用活动序列的最长公共子序列(longest common sequence,LCS)来表示活动轨迹之间的相似性。时空信息作为对活动行为的另一种描述,在特征提取和表示中起着重要的作用。Banovic 等[3]将活动行为日志转换为活动上下文的事件序列,用于表示人的日常活动行为。为了更深入地掌握人的活动动态,Zhang 等[2]从活动和旅行事件中提取活动的空间和时间特征。You 等[4]通过同时考虑语义信息和地理信息来计算轨迹相似性。在Chakri 等[5]的工作中,知识发现用于从语义轨迹中提取空间和时间信息。
为了挖掘用户的时空活动模式,有些学者使用空间统计,如核密度估计、K 函数和空间自相关和可视化技术来分析活动在时空上的分布和密度,然后确定密集活动[6-8]。时空流分析和轨迹分析主要依靠时空上的距离来识别密集活动[9-11]。这类方法没有将单个轨迹作为一个整体来对待,无法挖掘出具有代表性的模式特征。有的学者使用机器学习模型进行模式挖掘,如Shen 等[12]从个体的角度基于个人活动之间的时空距离通过聚类进行活动类别的识别。Zhang 等[2]综合考虑了活动及其活动的空间相交性、时间相交性以及活动轨迹来计算个体之间的相似度,并进一步基于社会网络分析进行社区发现。Kwan 等[13]利用序列比对将人类活动描述为多维序列,并将活动模式相似性评估作为一个多目标优化问题,提出的多目标进化算法用于计算个体活动模式相似性,然后使用聚类方法进行模式挖掘。给定一个人的时间和地点,Benetka 等[14]提出了一个针对活动的推荐系统,Krishna 等[15]提出一个基于长短期记忆人工神经网络模型预测活动以及活动持续时间的方法。
LCS 是一个经典问题,其在很多领域有广泛应用,长期以来许多研究者对LCS 做出了优化。有研究已经证明LCS 问题算法的时间复杂度下界为Ω(mlogn)[16]。该问题最常用的算法是动态规划, Hirschberg[17]提出了时间复杂度为O(pn)的算法,Nakatsu 等[18]提出了时间复杂度为O(n(m-p))的算法。
在以往的相关研究中,研究者往往仅利用活动轨迹来描述用户的活动行为,忽略了时间对活动的影响。本文认为人的时序活动序列描述了从时间的先后顺序下的活动特征,反映了人的重要行为特征,因此本文基于时序活动序列挖掘人的活动模式。
1 时序活动序列相似度计算
在时序活动序列的相似度计算中,计算的关键是需要同时考虑活动序列以及序列中每个活动发生的时间。为此本文考虑了相似活动的合并,将时间相邻且活动相似的时间离散为一个时间段,将每一段看作一个加权的点,这样一个人的日常活动是关于时间和活动的二维表示,2 个人的时序活动序列的比较就成了三维的比较。为了降低三维比较的算法复杂度,鉴于活动的时间段离散化程度比较大的特点,使用线段树和贪心算法进行降维,在借鉴前人LCS 研究的基础上,提出了一个复杂度为O(p(m-p))的时序活动序列的相似度算法。
1.1 最长公共时序活动子序列问题
最长公共时序活动子序列问题可以描述为:设序列X和Y是定义在活动集C上的序列,给定2 个用户的活动的序列X和Y,找出X和Y的一个最长公共子序列Z。注意,在此活动集中的活动是是包含了时间信息的。定义X的前i个前驱为Xi,Y的前j个前驱为Yj。因为人的日常时序活动序列描述了其行为习惯,所以使用最长公共时序活动子序列的长度来衡量用户之间的行为相似度。
1.2 算法设计
对于给定活动序列X和Y,LHi[k]表示所有与子序列Xi有公共子序列长度为k的Yj中j的最小值,即:LHi[k]=min{j| LCS(Xi,Yj)=k}。由此可以得出:
1)对于 ∀i(0≤i≤n),如果LHi[k]和LHi[k+1]都存在,则LHi[k]<LHi[k+1];
2)对 于 ∀i(0≤i≤n-1),如 果LHi[k] 和LHi+1[k]都存在,则LHi[k]≥LHi+1[k];
3)对于 ∀i(0≤i≤n-1),如果LHi[k]和LHi+1[k+1]都存在,则LHi[k]<LHi+1[k+1];
4)对于 ∀i(0≤i≤n-1),如果LHi[k] 和LHi+1[k]都存在,如果xi+1=yi且j>LHi[k],LHi+1[k]=j;否则如果xi+1=yi且j≤LHi[k],LHi+1[k]=LHi[k]。
1.3 算法实现
根据上述分析及相关定理,算法存储设计如下所示:
1)用一维数组L存储xi=yj时的跳跃点,L的下标表示Xi和Yj的公共子序列的长度,L[k]表示Xi和Yj的公共子序列的长度为k的j的最小值,(L[k],k)表示c[i][j]的跳跃点,c[i][j]为Xi和Yj的最长公共子序列的长度。
2)线性扫描字符序列Y,为字符集中的每个字符ai建立一个列表charList[ai],表中升序记录序列Y中每个字符ai出现的位置。
3)使用一维数组charListLen[ai] 记录列表charList[ai]的长度,使用一维数组charListIndex[ai]记录扫描列表charList[ai]的指针位置。
1.4 算法分析
使用LHi[k] 计算LHi+1[k] 时,在LHi[k] 的基础上,对于xi+1=yi的所有j,将min{ LHi[k] | LHi[k]>j|}替换为在LHi[k] 中出现的j,如果min{ LHi[k]|LHi[k]>j|}不存在,则将j放到LHi(max{k|LHi[k]exist}+1),计算结束。
计算最长公共时序活动子序列的长度时,只需要基于L数组就地进行即可,因此空间复杂度为O(n)。L数组最多包含p个元素,由LHi[k]计算LHi[k+1]的方法可知,只需要对L数组遍历一次即可,该操作的时间复杂度为O(p),此操作共进行m次,其中,m1∈{0},m2∈{0,1},m3∈{0,1,2},……因此最坏情况下mp=p,故最坏情况下时间复杂度为O(1+2+…+p+(m-p)p),即:O((m-p)p)。构造最优解的过程中只需要对X序列线性遍历即可,时间复杂度为O(m),故整个算法的时间复杂度为
O((m-p)p)。
1.5 算法讨论
以上提出的最长公共时序活动子序列算法,不仅考虑了活动序列,同时考虑了活动所发生的时间,所以计算相似度矩阵的复杂度较高。以本文所用的数据集为例,描述了人日常一天1 440 min的所有活动,样本个数在10 000 左右,所以计算相似度矩阵的复杂度大约为O(1014)。为了降低算法的复杂度,我们将时间相邻且活动相似的时间离散为一个时间段,这种离散化的处理使得变量的分布比较集中,也就是说相同连续的类型比较多。因为处理的对象是活动及其时间,粒度是分钟,每个活动会持续多个分钟,所以比较集中。基于数据集的序列存在这种特殊性,所以最坏情况出现的概率几乎为0,极大提高了计算效率。而像DNA 序列,虽然只有4 种类型符号,但都是交错的,离散化效果并不理想,所以本算法对DNA 这种类型的计算效率不高。效率高低主要取决于离散化程度,其效率和离散化后的区间个数正相关。对于类型比较少的序列使用后缀数组等方法来提升计算速度。
2 模式挖掘
基于以上相似度矩阵,首先使用谱聚类算法将其划分成各不相交的簇。
2.1 谱聚类
相比K-means 和基于密度的聚类算法,谱聚类只需要用户的相似度矩阵,对于稀疏数据的聚类处理较有效。因为使用了降维,在处理高维数据时比传统聚类算法效果好,对数据分布的适应性也更强。谱聚类的主要思想是首先把所有的数据映射为空间中的点,然后用边的权值表示两点之间的相似度,最后进行切图,使切割后的子图内的权值和尽可能的高,并且子图间的权值和尽可能的低。
谱聚类算法描述如下:
1)构图。将每个样本都看作是顶点V,并将这些点V用边E连接起来,边的权重表示样本的相似度,从而得到顶点之间的相似性矩阵W;
2)通过相似性矩阵W计算得到顶点间的度矩阵D,即W的每一行元素和;
3)计算拉普拉斯矩阵L=D-W;
4)计算L的特征值,取最小的k个特征值和对应的特征向量;
5)使用K-means 算法对特征向量进行聚类。
2.2 聚类算法的评价指标
1)轮廓系数(silhouette coefficient,SC)结合了分离度和内聚度2 种影响因素,取值为[-1,1],结果越趋近于1 代表聚簇的分离度都相对较优。其轮廓系数的计算方法为

式中:ai为点i到其同一簇内其他点的距离的平均值,bi为点i到与点i最近的不同簇的点的距离的平均值。所以整体聚类的轮廓函数为

2)CH 分数通过计算簇中各点与簇的中心点的距离平方和来度量簇的内聚度,通过计算各簇中心点与数据集中心的点距离的平方和来评估数据集的离散度,CH 分数由内聚度与紧密度的比值得到。因此,CH 分数越大表示聚簇自身越紧密,簇与簇之间越分散。CH 分数的计算方法为式中:n为类的数目,k为当前的类, tr(Bk)为类间离差矩阵的迹,tr(Wk)为类内离差矩阵的迹,Bk为簇间分散平均值,Wk为簇内分散值,d( )为距离计算公式。

3)Davies-Bouldin 指 数(Davies-Bouldin index,DBI)为任意2 个簇的簇内距离的平均距离之和与两簇质心间距之比的最大值。设有m个时间序列,这些时间序列聚簇为n个簇。m个时间序列设为输入矩阵X,N为簇数,计算公式为

3 实验与结果
本文使用美国时间使用调查(American Time Use Survey,ATUS)连续6 a 的数据作为实验数据集,原因如下: 1)ATUS 是美国劳工统计局积累的多年的统计数据,真实度较高; 2)数据具有代表性,样本的数量、特征值以及类别信息都比较广泛和详细,不容易导致过拟合现象;3)记录了用户一天详细的活动、时间、地点、人物以及社会人口学属性,为活动的模式挖掘提供了详实丰富的数据;4)根据2013—2018 年的数据进行发展趋势研究。
3.1 数据集及其预处理
2013—2018 年的样本个数分别是11 385、11 592、10 905、10 493、10 223 和9 593 个。提取用户的活动特征以及社会人口学特征,然后对数据集进行去重处理,并对特征严重缺失的数据值进行删除处理,还有少量特征缺失的数据进行均值填充处理。最后针对特征的性质以及计算需要,进行了归一化和标准化处理。
3.2 模式挖掘系统结构
本文系统采用B/S 结构,核心计算部分集中到服务器上,可以在Web 浏览器界面进行可视化调参、远程添加计算任务、异步计算以及计算结果可视化等操作,简化了调参和计算过程。服务端主要由配置文件、数据文件、结果文件、线程池计算队列和计算模块构成,其中计算模块又分为相似矩阵计算模块、聚类计算模块、可视化计算模块和统计计算模块。各个组成部分的相互关系以及整体结构如图1 所示。

图1 模式挖掘系统的B/S 结构
3.3 模式挖掘
模式挖掘系统中存在较多的关键参数,面向不同的应用的时候,在数据处理和分析过程中存在参数调整的问题,因而模式挖掘系统实现了一个可视化操作界面,实现对数据集的监控、关键步骤的计算、参数的调整、数据的保存、异步计算以及数据结果分析等功能。
3.3.1 聚类

表1 聚类评价指标
3.3.2 模式的典型特征分析
下面对聚类结果进行分析和挖掘。图2 将2018 年k=7 的聚类结果通过活动序列图对一天的活动时间分布进行可视化。从凌晨的4:00 到第二天凌晨的3:59,将簇中每个人一天1 440 min的所有活动通过不同的颜色表示,这样通过观察该图的颜色分布,可以直观地发现簇7 呈现的颜色分布具有明显性的差异,具有较好的辨识度,说明该聚类较好地捕捉到典型的活动模式。

图2 2018 年k=7 时的活动时间序列
我们对2013—2018 年的聚簇结果通过活动序列图显示其典型特征,发现不同年份所聚类的7 个簇所呈现的活动序列图分布大体比较一致。如2013 年的簇7、2014 年的簇3、2015 年的簇7、2016 年的簇3、2017 年的簇2 和2018 年的簇7,它们的活动序列图呈现相似的特征。更进一步,我们计算一天中各时刻的各类活动的人群密度函数。图3 为某类簇在2013—2018 年所呈现的概率密度图,我们观察到该类簇在不同的年份呈现相似的概率分布,由此推论出它们属于同一类活动模式。
图4 是2013 年的簇7、2014 年的簇3、2015 年的簇7、2016 年的簇3、2017 年的簇2 和2018 年的簇7 的概率分布图,观察到该类簇在不同的年份呈现相似的概率分布,属于同一类活动模式。与图3 比较,发现它们呈现明显不同的概率密度分布,由此推论图3 和图4 呈现了2 种不同的模式的概率密度分布。
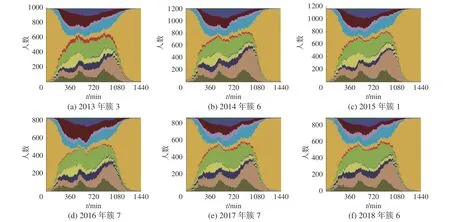
图3 k=7 时的概率密度分布(2013 年簇3、2014 年簇6、2015 年簇1、2016 年簇7、2017 年簇7 和2018 年簇6)

图4 k=7 时的概率密度分布(2013 年簇7、2014 年簇3、2015 年簇7、2016 年簇3、2017 年簇2 和2018 年簇7)
通过以上对活动时间序列图和概率密度分布图的可视化,我们对2013—2018 年的聚簇结果进行对比分析,得到同一模式在不同年份所对应的簇。
3.3.3 模式的主要特征分析
本节针对k=7 时的聚类结果,对簇内的样本进行统计分析,提取活动行为以及社会人口学的典型特征,得到以下7 种模式:
小白说,真是万幸,幸亏你摔到了绿化带的树苗堆里,再说,你还遇到了一位好心的老板,第一时间就把你送到了医院。
#1:个人护理时间最长,工作时间最少,年龄中年,收入较低,黑人比例较高,受教育程度较低;
#2:社交、休闲和娱乐时间最长,工作时间你较少,年龄最大,黑人比例较高,收入较低,受教育程度较低;
#3:工作时间主要分布在凌晨00:00 左右,年龄最低,收入低,男性较多,黑人比例较高,受教育程度较低;
#4:家务活动为主,中年,女性较多,白人比例较高,收入中等,受教育程度较高;
#5:与其他模式相比,花在工作上的时间最多,中年,收入高,和家人相处的时间较少;
#6:花在休闲、旅行、宗教、购物和购买服务的时间较多,参与的活动类型较多,老年,中等收入,白人比例较高,受教育程度较高;
#7:花在休闲、旅行、教育、宗教、锻炼、吃喝、购物和购买服务的时间最多, 参与的活动类型最多,中年,收入最高,白人比例较高,受教育程度较高,职业多为科技和管理类,家庭成员较多,工作时间较短,陪伴家人时间较多。
3.4 趋势分析
从以上分析可以看出,#1 和#7 是区别度较大的2 种模式,本节以这2 种模式为例,分别从活动行为和社会人口学角度进行趋势分析。活动行为包括参与的活动及其花费的时间,社会人口学因素包括年龄、家庭收入、种族、性别、职业、家庭人口数、工作时间、陪伴家庭的时间和休闲时间。我们画出这些特征在2013—2018 年的变化趋势图,分析结果如下。
3.4.1 模式#1 的发展趋势分析
活动:餐饮的时间在56~61 min,社交休闲的时间在255~300 min,体育锻炼娱乐的时间在11~18 min,宗教及其精神活动的时间在22~26 min,出行时间在35~40 min,个人护理时间在815~853 min,教 育 时 间 在9~23 min,购买 时间 在15~18 min。2013—2018 年,总体变化不大,个人护理与教育这2 种活动有增长的趋势。
年 龄:10~19、20~29、30~39、40~49、50~59、60~69 岁各年龄段人群比例大致均匀,70 岁以上人数比例有所减少。在2013—2018 年,60 岁以下的人数比例有降低的趋势,而60~79 岁的人数比例具有升高的趋势。
收入:收入主要分布在$15 000~149 999,在各子区间人群比例大致均匀。家庭收入低于$15 000的约占20%,而高于$100 000 的约占10%。在2013—2018 年,收入在$35 000 以下的人数比例有降低的趋势,高于$35 000 的人数比例整体略有升高的趋势。
各种族的人数比例:白人的比例在66.74%~70.45%,略有下降的趋势;黑人的比例在22.73%~25.90%,变化不大;亚洲人比例在3.20%~5.81%,略有增长的趋势。
职业:除了建筑工程、食品准备及其服务、建筑清洁维护、销售以及安装修理行业,其他职业的比例略有上升的趋势。
家庭人口数:整体曲线下降,说明人口数比例随着家庭人口数的增多而降低。家庭人口数在1 个的占比为28.91%~34.74%,人口数比例有增加的趋势;大于2 个的人口数比例均有所下降的趋势。家庭人口数在2 个的占比为23.86%~28.45%,家庭人口数在3 个的占比为16.09%~18.00%,家庭人口数在4 个的占比为12.71%~15.56%,家庭人口数在5 个的占比为6.41%~8.28%,家庭人口数大于5 个的人数比例明显减少。
工作时长: 大约10% 的人不工作;15.10%~17.47%的人工作时长是1~99 min,占比最高;在100~699 min 的每100 min 时间段上的人数分布较均匀,在每个时段的比例大概在10%左右。
陪伴家庭时长:不陪伴家人的人数比例在43.63%~48.36%,且有增长的趋势;陪伴家庭的时间在1~699min 的每100 min 时间段上比较均匀,在每个时间段上占比大约在5.93%~9.08%。
休闲时间:大约10% 的人没有休闲时间,休闲时间1~99 min 人数比例最高,大约在16%~18%,在100~699 min 每100 min 时间段人数比例平稳下降。
3.4.2 模式#7 的挖掘及其发展趋势分析
活动:餐饮的时间在85~94 min,社交休闲的时间在127~208 min,体育锻炼娱乐的时间在40~67 min,宗教及其精神活动的时间在53~75 min,出行的时间在158~185 min,教育的时间在61~106 min,购买的时间在45~55 min,这些活动花费的时间明显比#1 多;而个人护理在561~572 min,比#1 明显少。2013—2018 年,旅行、工作时间有增加的趋势,宗教及其精神活动有减少的趋势,其他基本持平。
年龄:20~29 岁和70 岁以上的人员数量较少,其他年龄的人员分布较均匀,50 岁以下比例具有减少的趋势,50 岁以上比例具有增加的趋势。
收入:收入曲线呈现上升趋势,收入越高,所占比例人数越多。收入在$15 000 以下的人数比例在10%以内,而且有减少的趋势;收入在$100 000以上的人数接近30%,而且有增加的趋势。
种族的人数比例: 白人的比例在78.48%~82.88%,比#1 模式的高出约12 个百分点;黑人的比例在9.2%~13.15%,比#1 模式的低约12 个百分点;亚洲人比例在4.99%~7.25%。
职业上:在管理、工商金融、计算机和数学、建筑和工程、生命物理和社会科学、法律、教育培新、艺术设计、医疗、保护性服务、销售、办公行政方面的职业的人数比例比#1 多;从事社区服务、健康支持、食物准备和服务、建筑、安装维护和修理、个人护理服务、生产和运输的比例比#1 少。从事商业和金融、计算机和数学、教育培训和图书馆的人数比例有升高的趋势,其他职业的人数比例有下降的趋势。
家庭人口数:家庭人口数在1 个的占比为18.44%~22.97%,比#1 低出10 个百分点,人数比例有增大的趋势;家庭人口数在2 个和3 个的占比和#1 基本持平,人数比例有增大的趋势;家庭人口个数在4 个的占比为19.15%~23.43%,比#1 高大约7 个百分点;家庭人口个数在5 个及其以上的比#1 大约高出3 个百分点。2013—2018 年家庭人口数大于2 个的人数比例趋势有所下降。
工作时长:大约10% 的人不工作,32.44%~39.08%的人工作时长是1~199 min,占比最高;之后的各时间段的人数占比越来越小。2013—2018 年,工作时长0~300 min 的人数有下降的趋势,而工作时长300 min 以上的有增长的趋势。
陪伴家庭时长:不陪伴家人的人数比例在28.91%~34.45%,比#1 低大约14 个百分点,有增长的趋势;陪伴家庭的时间在1~799 min 的每100 min时间段分布比较平稳,之后呈现长尾特征,略有下降趋势。
休闲时间:休闲时间为1~99 min 的人数比例最高,之后人数比例逐渐下降。在300 min 以内的时间段的比例人数有减少趋势,而在300 min以上的时间段的人数比例呈现增加趋势。
综上,#1 和#7 的活动行为和社会人口学模式及其发展趋势具有明显的不同。共同之处是2 种模式都存在着老龄化、收入增加的趋势,但是,在其他方面呈现马太效应的趋势。更进一步说明了人类的活动行为是由其社会人口学特征决定的。
4 结论
本文首先提出了一个基于时序活动序列相似度来计算用户相似度的方法,然后基于相似度矩阵进行聚簇,最后进行模式分析和挖掘,并基于连续多年的数据进行了模式趋势分析。因为模式挖掘中存在众多关键参数,因而本文提出的模式挖掘系统实现了对数据集的监控、关键步骤的计算、参数的调整、数据的保存、异步计算以及数据结果分析等功能。该界面可以简化研究操作,在提高研究效率的同时也降低了操作失误所带来的问题。
通过本文的研究,我们发现具有相似时间活动序列的人,他们之间可能具有相似的活动行为,同时具有相似的社会人口学特征。本文提出的方法不仅适用于时间使用调查表的模式挖掘,也适用于从移动终端设备收集的人群活动数据集的模式挖掘。在未来的工作中,我们首先将基于本体在相似度的计算中增加语义的理解;接下来,将提取簇群中最长的公共活动子序列,以进一步了解人类活动行为模式;最后,我们将该方法应用于从移动终端设备收集的数据集,并应用于推荐系统。
