文本风格转换综述
2022-04-12贾熹滨刘思良胡长建
贾熹滨,刘思良,胡长建,李 让
(1.北京工业大学信息学部,北京 100124;2.联想集团北京研究院,北京 100085)
风格转换任务在人工智能许多子领域都有着广泛的研究,包括计算机视觉[1-2]领域和自然语言处理[3-15]领域.
风格转换最早的研究是在计算机视觉领域中,Gatys等[1]认为艺术画作是由画家在内容和风格中构成复杂的图像来创造独特的视觉体验,人工智能系统无法具备同样的能力.受到计算机视觉领域的其他任务的启发,深度神经网络的视觉模型在某些计算机视觉的任务中可以达到接近于人类的表现.借助深度神经网络对图片提取内容与风格信息,再通过内容重构和风格重构可实现在艺术画作与真实照片之间的图像风格转换.
在自然语言处理领域中,风格转换的研究起步较晚.文本风格相较图像风格定义更为宽泛,例如:文章和文章的摘要[16]、礼貌的表达和粗鲁的表达[17]、积极的表达和消极的表达[7]都可以视为2种不同的风格.实现方法可以大体分为解耦与基于一步映射两大类.早期的文本风格转换任务受图像风格转换任务相关研究的启发,将研究的重点放在如何解耦文本中的风格与内容.近几年也有一些研究者认为文本的内容和风格特征的解耦是非必须的,提出让模型直接学习不同文本风格间的映射关系,实现文本的风格转换,推动文本风格转换研究进一步发展.另外,随着表示学习突飞猛进的发展,预训练语言模型在各项自然语言处理的任务上取得了巨大的成功[18].基于预训练语言模型的文本风格转换方法[10]为文本风格转换任务提供了新的研究思路.
本文梳理了近几年文本风格转换算法的研究工作,首先,从文本风格转换任务的数据集入手,按照是否具有平行语料,介绍平行数据集和非平行数据集;然后,依次介绍平行和非平行数据集上的相关工作;最后,展望文本风格转换任务未来的发展,尝试为研究人员建立一个比较完整的研究领域视图,为相关领域的研究者提供帮助.
1 文本风格转换任务概述
自然语言生成作为人工智能领域一项重要的技术,已经广泛应用于各类实际场景中,包括机器翻译、对话生成等.以往的自然语言生成模型往往存在一些缺陷,无法根据实际需求生成文本,距离真正的人工智能还有着一定的差距.寻找可控自然语言生成方法成为近年来的研究重点.
可控自然语言生成是指模型能根据特定的风格和内容生成文本.风格可控包括控制句子的长度[19]、情感[20]、时态[20]等;内容可控包括基于对话中的角色信息[21]、维基百科中的常识信息[22]等控制文本的生成.文本风格转换任务作为可控自然语言生成的子任务,是一种在保留句子内容信息完整的基础上控制句子的风格,生成具有指定风格的句子的任务.通常指定的风格和句子原有风格是对立的.
文本风格转换在实际场景中有着广泛的应用.在智能客服场景中,根据用户的情绪生成具有相关联情感的回复能有效提高用户的体验.另外,在书面语言的修改及纠错的场景中,文本风格转换也发挥着重要作用.模型将书面语言和口语化语言作为2种相互转换的风格,通过学习二者间的不同,为用户提供书面语言的纠错或改写的服务.
然而,文本风格转换任务的发展过程是曲折的,仍存在着三大问题阻碍文本风格转换任务的发展.
其一,缺乏平行的数据集.传统的文本生成模型是在平行数据集上训练的,各类任务在有监督的训练中取得了巨大的成功[23-24].由于文本风格转换任务本身的复杂性,很难构建合适的平行数据集.以Yelp[3]数据集为例,它是文本风格转换最早的主流数据集.数据源于用户在Yelp平台上对饭店服务的评价.Yelp数据集将评价分为积极和消极2种.每一条评价对应用户一次消费体验,很难找到对立风格中与之相对应的句子构建平行语料.
其二,无法解决梯度回传问题.传统的风格转换任务的训练可分为2个阶段:先由生成器生成目标风格的样本,再由判别器对生成的样本计算风格损失,通过反向传播,回传判别损失,实现风格转换.该模式在图像风格转换中取得了巨大的成功[1-2].在文本风格转换任务中,文本的表示是离散化的.在文本生成的过程中,每一个时间步都需要选择当前时间步最大概率的词作为该时间步的输出,导致梯度消失难以微分,无法通过反向传播实现梯度回传,需要借助其他方法解决梯度回传问题.
其三,缺乏全面的自动评价指标.在文本风格转换任务中,评价指标包括风格转换的准确率、内容的保存程度及流利度3个方面.在衡量模型的优劣时,会将人工评价和自动评价的结果共同作为评价的依据.人工评价是指找一批以数据集中的语言作为母语或对该语言有一定能力的人,从3个方面为生成样本打分,能够准确地测试出模型各指标的表现差异.因为人工评价存在成本高、主观性强、难以复制的缺点,所以在衡量不同模型间的差异时,还是以自动评价标准作为主要参考.自动评价指的是借助统计模型或神经网络模型分别从单一维度评价生成结果,计算成本低,评估速度快,可信度高.当前的自动评价方法都是只对单一维度评价,在采用自动评价指标为模型打分时,每个指标只能反映单个维度模型的表现,无法全面地评价模型的表现.多维度的评价指标将有助于文本风格转换任务的进一步发展.
为了解决这些问题,研究者们寻找了许多解决办法.针对缺乏平行语料,采用无监督的自然语言生成方法在非平行语料下训练模型.另外,一些研究者还针对某些特定风格,开发平行语料的数据集,有效地缓解了缺乏平行数据的问题.针对文本的离散表示,通常的解决办法有3种:第1种采用Gumbel-Softmax[25],通过重参数化采用连续分布近似文本的离散分布,避免离散化数据导致的无法梯度回传问题;第2种,避开每个时间步的采样,将每个时间步生成的词表分布作为该时间步生成的词向量,该方法也是文本风格转换任务中最常用的处理离散化数据的方法;第3种,采用强化学习方法,解决不可微分问题,通过奖惩机制引导模型的生成.针对缺乏自动评价指标的问题,Zhang等[26]将Bert[18]作为自动评价模型,该模型能够综合文本内容与流利度这2个评价维度对样本打分,能够更全面地评价模型.
2 数据集
研究者根据不同的实际场景,选择一些风格特征明显的场景构建数据集,包括正面与负面、浪漫与人文、学术与新闻、男性与女性等.根据数据集中是否具有平行语料,将当前的数据集分为平行数据集和非平行数据集.
平行数据集的构成包括2种风格特征的文本数据,不同风格特征的文本数据具有一对一的映射关系,每一句话都可找到风格特征不同、内容特征相同的另一句,两句互为标签.在此类数据集中,模型可进行有监督训练.与之类似,非平行数据集包含2种不同风格特征的文本数据,但不同风格的文本数据之间没有对应关系.因此,在非平行数据集中的文本风格转换模型只能在无监督的条件下训练.本文在表1中列举了一些文本风格转换研究相关的数据集.
最早的平行数据集是由Xu等[30]在2012年提出的基于写作风格的平行数据集,将莎士比亚的写作风格和现代写作风格当作2种对立的风格特征,构建平行数据集.之后Carlson等[34]在2018年提出基于《圣经》语言风格与现代语言风格的数据集.在统计与比较多个版本的《圣经》后,总结不同版本《圣经》的语言风格,在《圣经》的语言风格与现代语言风格之间构建平行数据集.Rao等[31]在2018年提出基于书面表达的平行数据集.针对人们的书写习惯,将书面形式的表达和非书面形式的表达作为2种不同的风格,模型可以在该数据集上学习和训练,为非母语者提供写作帮助及为儿童教育提供帮助,具有广泛的应用前景.
非平行数据集中研究最多的是Yelp和Amazon数据集.Yelp数据集是2017年Yelp挑战赛上由官方提供,通过众包的方式选择数据集中风格比较明显的文本构建的积极与消极的数据集.Yelp是国外类似于大众点评的应用,顾客会在Yelp上对餐厅打分.Amazon数据集原本是在文本分类任务中应用的数据,在2018年,Li等[8]将该数据集率先应用在文本风格转换任务中.Amazon数据集是源自于亚马逊网购平台的产品评价,包括积极的评价和消极的评价.
从表1可以发现,平行数据集的数据量通常小于非平行数据集的数据量,规模基本小1个数量级.这是因为平行数据集的构建需要大量的人工标注.相对来说,非平行数据集更容易获取.

表1 文本风格转换数据集Table 1 Text style transfer datasets
在文本风格转换任务的研究中,缺乏平行数据集的问题一直阻碍着文本风格转换研究的发展.因此,当前文本风格转换的研究主要集中在非平行数据集.
3 基于平行数据集的文本风格转换方法
在文本风格转换任务的方法中,大多数基于平行数据集的研究都是将文本风格转换任务当作标准的序列到序列(Seq2Seq)的文本生成任务,具体做法是将2种不同风格特征、相同语义信息的数据集类比为机器翻译任务中成对的翻译语料,参照机器翻译生成方法实现文本的风格转换.
Jhamtani等[35]的工作是较早出现的基于平行数据集的文本风格转换研究.该工作在Xu等[30]提出的莎士比亚数据集上,参考生成式文本摘要的复制机制[36],提出在标准的序列到序列模型中增加指针网络[37],有效提升了文本风格转换效果.
在Rao等[31]提出基于书写正式的数据集后,大量基于平行数据集文本风格转换的研究都集中在该数据集.Niu等[38]在2018年将多语言引入文本风格转换任务中,提出借助书写形式敏感的机器翻译模型在英语与法语翻译的过程中加入风格控制.采用多任务的训练方式,一方面约束机器翻译模型的翻译能力,另一方面约束生成的文本具有指定的风格,通过学习不同语言中包含的共同的语言知识有效地提升文本风格转换的质量.这也是自然语言生成领域中常见的提升模型生成质量的方式.与Niu等[38]的研究工作相同,Xu等[39]同样采用了多任务的思想,通过多个损失函数训练模型在保留足够多语义内容的基础上,实现文本风格的转换.
随着GPT2[40]在自然语言生成任务中显示出的卓越性能,Wang等[41]将GPT2模型应用于文本风格转换任务,与以往的研究不同,该项工作主要关注的是非正式文本到正式文本的改写.首先采用基于规则的方式处理非正式的文本,得到基于规则的正式文本,再将非正式的文本和基于规则的结果作为GPT2模型的输入,通过解码器解码得到生成结果.Zhang等[42]认为书写正式数据集的规模较小,阻碍了书写纠错这一文本风格转换任务的发展,因此,在Wang等[41]的工作基础上,提出对现有数据集进行数据增强,通过多个现有的模型在数据增强数据集训练后在多个评价指标上的提升,证明了该数据增强手段的有效性,同时在该数据集上提出新的方法.
4 基于非平行数据集的文本风格转换方法
基于非平行数据集的文本风格转换方法,主要采用基于无监督文本生成方法.整体的研究思路可以分为两大类.
第1类研究思路认为句子应当包含语义内容和文本风格两部分,文本风格转换任务实质上就是二者分离、重组,即先分离语义内容和文本风格,保留句子中的语义内容,修改句子的文本风格,再重新组合.如何成功将两部分完整分离,实现语义内容与风格特征的解耦,就成为需要主要解决的问题.沿着语义内容与风格特征解耦的研究思路,一些研究人员认为可在提取文本特征时采取一些手段解耦,从而获取风格独立的语义内容.文本特征分布的空间称为隐空间,因此,这类方法称为基于隐空间解耦的方法.另外一些研究者认为可利用句子本身的构成特点及人的语言习惯,通过对句子中词的修改实现内容特征与风格特征的解耦.例如,在“这里做的菜很难吃”“这里做的菜很棒”这两句话中具有相同的语义内容,而表达的风格却是相反的.决定整个句子风格倾向的就是“难吃”和“棒”这2个词.将决定句子风格倾向的词汇与句子中剩余部分分离,就能实现内容特征与风格特征的分离.因为是通过分割句子实现的解耦,类比隐空间解耦的方法,所以此类方法称为显性解耦的方法.
第2类研究思路认为句子中的内容特征和风格特征是相互包含的,无法彻底分离.模型可以在不同风格的数据间学习映射关系,避免对语义与风格解耦,实现文本风格的转换.因此,这类文本风格转换方法称为基于一步映射的方法.
4.1 基于隐空间解耦的方法
在基于隐空间解耦的文本风格转换的工作中,主要解决2个问题:一是如何从文本特征中分离出与风格无关的内容特征,二是如何控制生成句子的风格.在这些工作中,第1个问题的解决方法包括对抗学习、基于机器翻译模型、隐空间分离等方法;第2个问题的解决方法可分为基于风格属性码和基于隐空间分裂的风格控制方法.下面根据风格控制方法的差异,依次介绍基于隐空间解耦的文本风格转换研究.
4.1.1 基于风格属性码的风格控制方法
此类方法的实现过程是采用额外的结构化的风格属性码控制生成文本的风格.在实现内容特征与风格特征解耦后,将风格独立的内容特征的隐空间特征与目标风格的风格属性码拼接作为解码器的输入,或者采用不同的解码器生成对应风格的句子.
Fu等[3]采用循环神经网络(recurrent neural network,RNN)提取文本特征,将序列到序列模型作为基本模型,引入多任务框架与对抗学习的思想实现风格与内容的解耦.模型结构如图1所示.在模型训练过程中,采用迭代的方式逐步实现解耦,增加多层感知机作为风格特征判别器,对文本特征进行分类.如果判别器能正确分类,说明文本特征仍然包含风格信息.为了进一步分离内容与风格,可将判别器和特征提取器进行对抗训练.首先,训练特征判别器,固定编码器参数,更新判别器参数;然后,使判别器能够准确判断文本特征中是否还包含着风格,再固定判别器参数,更新编码器,降低判别器分类的准确率,减少文本特征中包含的风格信息.通过重复这2步,文本特征中的风格信息不断减少,实现内容与风格的解耦.在风格的控制方法上,该工作提供了2种思路:方案一为多解码器模型,采用的是初始化状态的方法控制风格,为每个不同的风格都分配了对应的解码器;方案二为风格向量模型通过风格向量进行控制,将目标的风格向量s与内容特征组合作为解码器的输入,控制生成样本的风格.

图1 多解码器模型和风格向量模型[4]Fig.1 Multi-decoder model and style-embedding model[4]
Prabhumoye等[4]提出借助神经机器翻译模型得到与风格无关的内容向量,模型结构如图2所示.在模型训练前,先在具有中性风格的翻译语料中训练英译法和法译英神经机器翻译模型;将源风格的句子(英语)通过预训练的英译法模型翻译成法语的句子作为法译英的模型的输入,通过法译英模型提取文本特征作为风格独立的内容特征.作者认为2个翻译模型是在中性风格语料中训练的,可以减少2种风格语料对模型的影响,从而学习到与风格无关的内容特征.因此,通过法译英模型提取的文本特征就是风格独立的内容特征.在风格的控制上,采用了初始化状态的方法,通过对应风格的解码器控制目标风格样本的生成.

图2 基于机器翻译解耦的文本风格转换模型Fig.2 Text style transfer model based on machine translation disentangle
Dai等[6]的模型结构如图3所示.这项工作的思想源于图像风格转换Cycle-GAN[2],将转换风格后的样本重新转换为原来的风格,计算与原有样本的差异,从而保证转换过程中信息没有丢失.该模型的训练分为2步:1)对文本建模,学习提取文本特征.与一般的自编码器不同,将文本特征与随机初始化的风格向量拼接作为解码器的输入,计算重构损失Lself;2)控制风格实现风格转换.采用2个损失函数Lstyle、Lcycle控制句子风格的转换和转换过程中内容的保留.在训练中,将文本特征与目标风格向量拼接生成目标风格的句子,再利用判别器判断生成样本的风格,计算判别风格与实际的目标风格之间的差异Lstyle,引导生成文本的风格向目标风格靠近.为了保证转换过程中语义信息不丢失,将生成的文本与原有的风格向量结合重新生成原有的句子,计算重新生成的句子与输入句子的差异Lcycle.另外,还采用Transformer代替原有的RNN作为编解码器,有效地提升了文本风格转换的生成质量.

图3 Style Transformer模型Fig.3 Style Transformer model
4.1.2 基于隐空间分裂的风格控制方法
此类方法认为同一风格的数据集具有相同的风格特征,可对相同风格的句子提取统一风格特征,将文本特征的隐空间表示分裂,一部分代表风格独立的内容特征,另一部分代表风格特征.然后,再通过对风格特征的替换和文本特征的重组,控制文本生成的风格.
John等[7]对隐空间解耦做了进一步的改进和提升,提出了Disentangled模型.将内容特征与风格特征视为2个独立的隐空间分布,并将文本特征投影到2个隐空间,分别代表内容特征和风格特征.模型结构如图4所示.

图4 Disentangled模型Fig.4 Disentangled model
在训练阶段,将文本特征分别投影到不同的隐空间中,得到风格特征s和内容特征c.然后,为了保证2个隐空间相互独立,设计2个判别器用于计算某个隐空间特征中包含的风格信息和内容信息.针对内容隐空间特征,最小化内容损失Jmul(c),最大化风格损失Jdis(s).针对风格隐空间,最小化风格损失Jdis(c),最大化内容损失Jmul(s),促使风格空间中包含更多的风格信息和更少的内容信息.另外,计算隐空间内容损失采用的是词袋损失[43]的方法.将输入句子去除停用词和风格词,得到词袋特征,将词袋特征当作标签,再基于隐空间特征预测词袋特征.如果隐空间包含的内容信息足够多,就能完整地预测出文本的词袋特征,同时去除输入文本的停用词和情感词也保证了得到的词袋特征没有包含风格信息.计算隐空间内容损失的方法与Fu等[3]的工作类似,在此就不做赘述.
在推理阶段,需要用目标风格的特征代替原有风格的特征,模型采用对大量相同风格句子的风格特征求和取平均的方法,作为该种风格的特征表示,替换原有风格特征,控制生成句子的风格.
4.2 基于显性解耦的方法
在基于显性解耦的研究工作中研究者将决定句子整体风格的词汇称作风格标记,通过改变句子中的风格标记实现句子的风格转换.
显性解耦的方法可以分为3步:第1步,删除风格标记,对数据进行预处理,通过删除句子中原有风格的标记获取风格独立语义内容的文本表示.第2步,检索目标风格的风格标记,用于替换原有风格标记.第3步,生成目标风格句子,将第2步检索到的目标风格标记填入原有风格标记的位置.
4.2.1 删除原有风格标记
Li等[8]提出一种简单易行的方法以找到句子中的风格标记.在数据集中,计算每个词在2种风格数据集中出现的次数,其中风格标记与剩余词在不同数据集中出现的频率存在显著的差异,再根据这一差异区分出风格标记与剩余词.具体公式为
(1)
式中:Count()代表词u在数据集Dv中出现的次数;λ代表平滑稀疏,保证数据集Dv中没有出现的词也能分配一定的权重;s(u,v)代表词u在数据集Dv中对于风格v的贡献度,当s(u,v)大于某个阈值时,将词u作为风格v的风格标记.
采用自注意力机制的风格分类器,为文本中的每个词分配权重,权重越高的词对句子的风格贡献度越大,将文本风格贡献度高的词作为风格标记,公式为
a=Softmax(w·tanh(WHT))
(2)
r=a·H
(3)
y=Softmax(W′·r)
(4)
先为句子中的每个词分配权重a,由每一时间步的隐状态通过全连接和Softmax得到;再将权重与每一时间步的隐状态相乘,得到加权后的隐状态c;最后,通过Softmax得到句子每个词汇的贡献度,即句子的风格概率分布.将所有权重大于阈值的词作为风格标记,其中将阈值设定为平均权重.Xu等[9]还将上述的2种方法融合,将词频与自注意力词权重相乘,更精确地找到句子中的风格标记.另外,Wu等[10]认为长短期记忆(long short-term memory,LSTM)网络模型不够鲁棒,提取特征效果有待提高,并用实验证明删除风格标记过程中会删掉一些重要的上下文或遗漏一些风格标记.因此,提出采用Transformer[44]选择删除对象,结果显示能够更准确地识别句子中风格标记.
Sudhakar等[11]提出一个判断方法,公式为
px=pθc(s|x)
(5)
px,ti=pθc(s|x,ti)
(6)
(7)
先通过预训练好的风格分类器(基于自注意力机制的分类器)计算句子x的风格s的概率px.再计算去掉词ti后文本的风格概率px,ti,将2个风格概率的差Sti作为删除词ti的风格重要性.之后按照重要性从大到小的顺序依次删除k个词汇得到剩余文本的风格概率pxk,ti,计算k个词对句子风格的影响,直到整个文本的风格概率小于阈值α.最后,将删除的k个词作为该文本的句子.为了避免无法完整删除风格标记情况的出现,设定了删除的风格标记应当大于阈值β,并详细论证了2个阈值的大小对删除风格标记的影响.
4.2.2 寻找目标风格标记
在删除输入文本中原有风格标记后,需要在另一种风格的数据集中寻找能够与之相对应的目标风格标记.在此处将去除原有风格标记的剩余部分称为模板,一种常用的寻找目标风格标记的方法是用原有的风格数据集中的模板匹配目标风格数据集中的模板.如果目标风格数据集中有一些模板与处理后的模板的语义相似度高,二者对应风格标记也应是相互对应的.为了将模板与目标风格数据集中其相似的模板匹配,一般都是通过句子向量的余弦相似度来寻找.常用的计算句子向量的方式包括基于词频的TF-IDF,以及采用预训练词向量的GloVe[45],通过对句子中所有词的词向量求和取平均后,得到句子向量.
4.2.3 生成目标风格句子
生成目标风格句子的方法大致可以分为2类:一类是直接将检索到的目标风格模板对应的风格标记填入原有目标风格的位置;另一类是采用编解码器作为生成模型,以原有模板和检索到的目标风格标记作为输入,生成目标风格句子.
Li等[8]提出4种策略生成目标风格句,按照生成方式的不同可以分为 “基于模板”“仅检索”“仅删除”“删除与检索”,如图5所示.前2种方法属于第1类生成方法,其中“基于模板”方法是将目标风格标记c(xt,vt)替换输入文本中的原有风格标记vs;“仅检索”方法是将对立风格数据集中模板间相似度最高的句子xt直接作为输出结果.后2种方法属于第2类生成方法.“仅删除”方法是直接将原有模板c(x,vs)作为编解码器的输入,生成目标风格句子;“删除与检索”方法是在目标风格数据集中找到模板间相似度最高的模板,将匹配到模板的目标风格标记c(xt,vt)与原有模板c(x,vs)组合作为编解码输入,生成目标风格句子.
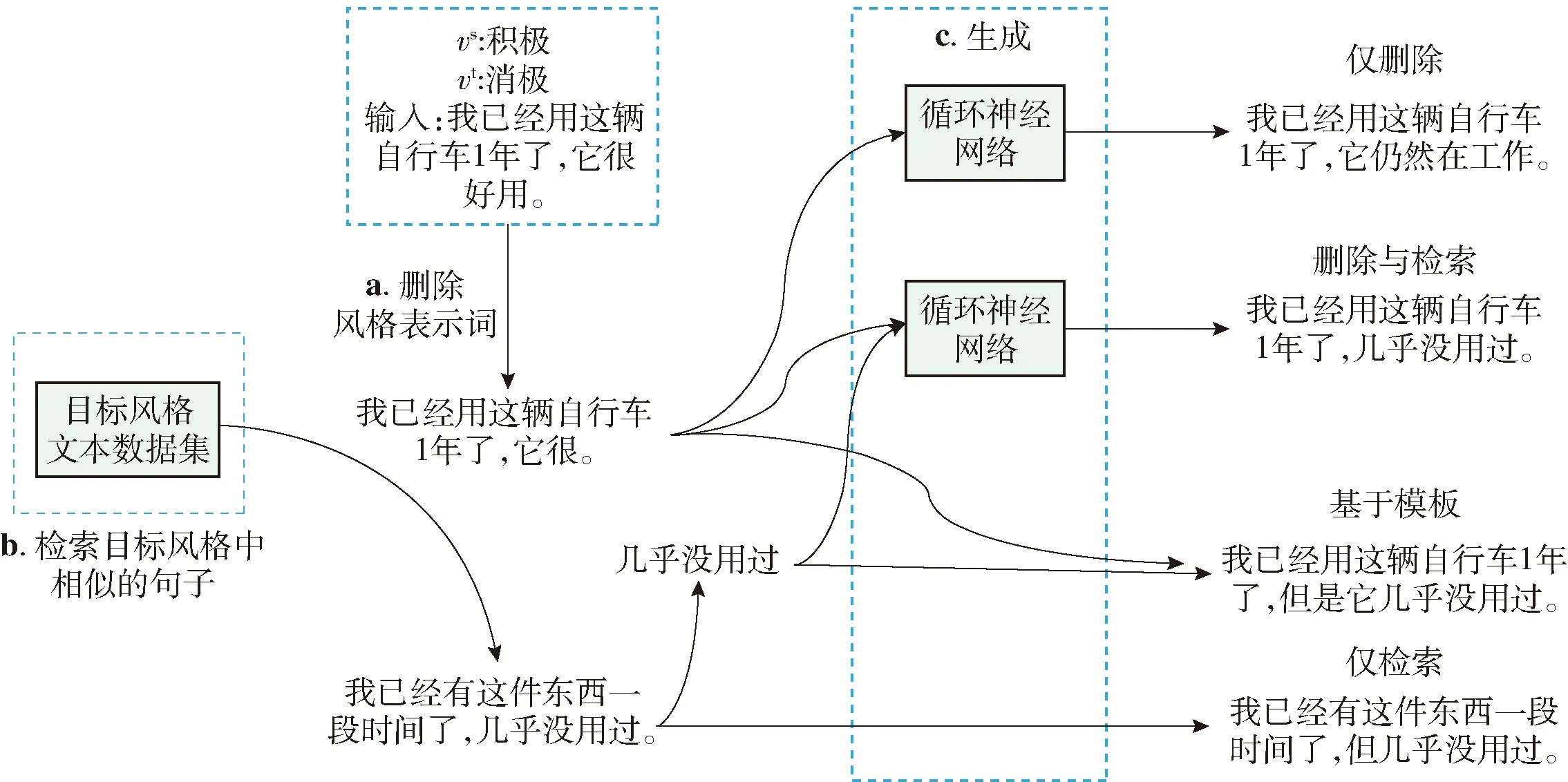
图5 4种文本风格转换方法[8]Fig.5 Four methods in text style transfer[8]
Wu等[10]借助预训练语言模型Bert,结合Bert的预训练任务掩盖式语言模型(mask language model,MLM),将原有风格标记视为需要掩盖的词,目标风格标记视为需要预测的词.以Bert作为基础模型,借助预训练语言模型中的知识,将检索与填充融合成一步,提升了文本风格转换的质量.
4.3 基于一步映射的方法
基于一步映射的方法指的是采用端到端的生成方法,将文本特征视为一个整体,避免对文本中风格与内容特征的分离.通过学习不同风格句子之间存在的映射关系,实现风格转换.具体实现可以分为3种方式:基于机器翻译、基于强化学习和基于隐空间编辑的生成方法.
4.3.1 基于机器翻译的方法
Zhang等[12]受到无监督机器翻译研究的启发,将基于非平行语料数据集的文本风格转换任务视为无监督的机器翻译.采用迭代回译的方式提升翻译质量,先构建伪平行语料,作为迭代回译的初始输入.通过计算词向量的余弦相似度学习不同风格词之间的对应关系,建立对应词表.按照词表替换原文本中的词,得到伪平行语料.构建完成的伪平行语料作为平行语料,由模型再生成另一种风格的句子,再将回译生成的结果作为第2轮模型的输入.在回译过程中通过语言模型与分类器引导迭代回译,在迭代中不断提升风格转换质量.
Jin等[13]同样采用迭代回译的方法,区别在于该模型通过检索构建伪平行语料.在计算不同风格数据集间文本的语义相似度后,将超过某个预先设定阈值的句子与原有文本构成伪平行语料对.在迭代回译的过程中,比较该轮生成的结果与检索结果和源句之间的词移距离(word mover’s distance,WWD)[46],将距离更近的句子作为下一轮的伪平行语料,避免在迭代回译过程中出现模型崩溃的情况.
4.3.2 基于强化学习的方法
Luo等[14]认为在没有并行数据的情况下解耦很难分离句子的内容与风格,并提出了一个双向强化学习框架(如图6所示),将2种风格间文本相互转换的过程视为一种双向映射的学习任务.针对文本的风格转换和文本内容保持设计2个奖励函数,由得分引导模型学习风格间的映射.同时,参考迭代回译的思想,提出伪退火教师教学算法,每次将上一轮的生成结果作为伪平行语料,再借助伪平行语料进行下一轮的训练,迭代提升模型的生成质量.在2个基准数据集的实验模型中取得了很好的效果.

图6 基于双向强化学习约束的文本风格转换模型训练流程[14]Fig.6 Training process of text style transfer model based on two-way reinforcement learning constraints[14]
4.3.3 基于隐空间编辑的方法
Liu等[15]认为可以在隐空间中直接学习不同风格文本隐空间特征存在的映射关系,编辑隐空间特征,实现风格转换.其创新点在于可以直接利用分类器的梯度回传影响隐空间特征.通过迭代的方式不断修改隐空间特征,直到分类器能将转换后的特征识别成目标风格,从而学习到隐空间中不同风格的分布间的映射.为了限制隐空间编辑的迭代过程中的参数的更新幅度,在损失函数中增加正则项,避免由于更新幅度过大导致的信息丢失.
4.4 各类研究工作的比较与分析
在表2中列举了各类风格转换的研究工作在Yelp数据集上的实验结果,其中参考-BLEU指的是计算生成结果与预设的参考结果的相似度(BLEU是一种衡量生成样本质量的评价标准,会在5.1.2节详细介绍),输入-BLEU指的是计算生成样本与输入数据间的相似度,这2项指标用于衡量生成样本中内容的保留度.准确率指的是生成样本中具有指定风格的比例,由训练好的分类器对生成样本打分,衡量风格转换的成功率.
由表2可得到一些结论:第一,对实验结果分析后可推断模型的准确率与原文-BLEU值存在负相关,即包含原有内容越多越容易被判断为原风格.这意味着这些模型在训练时可能会采取牺牲一个指标来换取另一个指标的提升的策略,需要在模型训练的时候加以平衡.第二,无论是按照哪一种研究思路的工作,当前最优的实验结果差别不大,但不同的研究思路在各个指标上的表现有所不同.隐空间解耦在训练过程中会采用重构损失来减少风格转换过程中内容的损失,此类生成方式可比较自然地完成文本风格转换,在参考-BLEU指标上表现出较大优势.显性解耦中的一些风格转换方法是通过修改或添加风格词汇实现的,在风格的转换上能表现出较高成功率,如果原文与参考结果差异过大,可能会导致参考-BLEU得分较低.基于一步映射的风格转换方法是通过迭代训练实现的,在保证语义内容不丢失的情况下不断向目标风格靠近,因此,此类工作在2个指标上表现比较均衡.第三,Transformer模型的加入能够有效地提升生成样本的质量,尤其是在Wu等[10]中引入了基于Transformer的预训练语言模型,借助丰富的语言知识,在不同指标上都有所提升.

表2 文本风格转换在Yelp数据集上的实验结果Table 2 Experimental results of text style transfer on Yelp dataset
在模型的可解释性上,基于隐空间解耦和基于一步映射的方法模型存在可解释性较差、不易训练、训练过程不可控制等问题,而基于显性解耦的方法模型具有可解释性好,容易调优、调试和改进的优点.
在模型时空复杂度的比较上,3种方法如果采用同种编解码器,空间复杂度是一样的.在时间复杂度的比较中,因为基于一步映射的方法需要大量的迭代训练,所以该方法的时间复杂度高于基于隐空间解耦的方法.基于显性解耦的方法需要对数据进行预处理,该方法的时间复杂度高于基于隐空间解耦的方法.另外,决定模型的时空复杂度的另一个重要因素是编解码器采用何种模型.采用Transformer模型会带来更大的参数量,同时,会大幅增加模型的训练时间.
在文本风格转换任务中存在各种类型的数据集,一些句子的风格可能是由句子整体决定的.此类数据集难以分离句子中的内容特征与风格特征,可以采用基于一步映射的方法.对于一些句子结构比较简单的数据集,基于隐空间解耦和基于显性解耦的方法都可以应用在这些数据集中.
5 评价指标
评价文本风格转换生成质量的方法通常分为人工评价和自动评价2种,均是从生成文本的风格转换准确率、内容的保留度以及文本的流利度3个方面进行评价.这一观点得到了广泛的认可[47-48].
5.1 自动评价指标
5.1.1 风格转换准确率
风格转换准确率是评价风格转换模型的一个重要指标,它是指在所有的生成文本中,风格转换成功的句子所占的比例.准确率越高代表模型的风格转换效果越好.一般采用的方法是用预训练的文本分类器对生成的句子进行分类.在实际应用中,研究者则会采用不同的模型作为分类器.Shen等[5]使用TextCNN[49]模型作为分类器,测试表明,在数据集中进行预训练可以获得90%以上的分类精度.
5.1.2 内容的保留度
随着对生成句子进一步分析,研究者发现即使生成的句子在风格转换准确率这一指标上得分较高,转移风格后的句子内容与输入句子的内容并不相关,文本风格转换也是失败的.对于保存程度的测量,研究者们提出了很多方法,其中BLEU[50]是使用最广泛的方法.BLEU是评估输出句子与参考句子之间字或词重叠程度的指标,代表了2个句子的相似程度,BLEU分数越高,表示2条文本越相似,代表模型内容保存得越好.此外,还有一种基于词嵌入的度量方式,通过Word2Vector[51]或GloVe[45]获得风格转换前后句子的向量表示,将向量表示之间的余弦相似度作为内容保留度的评价标准.在Bert[18]模型被提出后,一些研究者提出可以采用语境化的词嵌入代替静态的词嵌入,并采用Bert模型对内容的保留度打分,可以获得更准确的评价标准,即BertScore[26].
5.1.3 流利度
仅从风格转换准确度和内容给出的保留度评价,仍然无法保证生成的句子足够好.如果生成的句子完全不符合人类的阅读习惯,风格转换模型还是失败的.因此,判断句子是否流畅也很有必要.Mir等[47]在真实句子和风格转换句子样本上训练了一个基于单字的神经逻辑回归分类器,判断生成的句子是真实的还是模型生成的.最后,计算通过分类器的句子数占所有转换生成句子的比例,并给出流畅度分数.另外,采用困惑度来衡量生成句子的流利度也是一种评价流利度的方法.一般采用预训练的语言模型对句子打分,越符合人类阅读习惯的困惑度越低.
5.1.4 自动评价指标存在的缺点与改进
上述3种方法均在单个维度评价模型的生成质量,无法从多个维度反映整体模型的质量,因此,可以联合多种评价方法来评价模型.比如:计算准确率和BLEU的几何平均值和谐波平均值,对模型的综合能力打分.
除此之外,在以困惑度作为评价流利度的指标时,可能会遇到生成样本中存在一些比较罕见的单词,导致作为评价指标的困惑度升高,错误地评价模型.除了采用人工评价作为补充,目前没有更好的解决办法.
5.2 人工评价
自动评价的结果可以快速地提供模型的评价指标,但是自动评价无法提供模型进一步训练的修正意见,无法直观地反映风格转换过程中出现的问题.人工评价可以弥补这一缺陷,人工分析生成样本可为模型训练提供更多意见.关于人工评价,研究人员需要先找到一些具有语言背景的工作人员评价模型.一般来说,研究人员会找到3~6个人对每个句子进行打分.使用Stent等[52]提出的1~5利克特量表对句子的3个指标进行打分.评估过程需要对样本充分打乱顺序,从中取出足够的样本,同时,保证每个评估者无法知道句子的来源.
6 展望
风格转换的任务实质上是改写句子的风格.从狭义上讲,风格转换的任务是二值属性间的风格转换,比如:积极到消极、书面语言与非书面语言.从广义上讲,风格转换可以包括多个风格之间的转换[53],以及文章与文章主题间的转换[54],或者细粒度上的风格转换[55].除此之外,目前大多数的工作都是基于单句的文本风格转换.在实际应用中,句子通常还有上下文,转换单句的时候需要考虑上下文才能实现更自然的风格转换样本.Cheng等[33]提出基于上下文内容一致性的文本风格转换任务.
随着大规模预训练语言模型的发展,预训练模型在许多下游任务中显示出优越性[18],将预训练语言模型应用到风格转换任务中,可能会推动风格转换任务的发展.
本文基于当前文本风格转换任务的发展现状总结出以下3个方面的挑战.
6.1 更复杂的风格转换任务
在自然语言处理的实际应用中,二元属性的风格转换不能满足所有实际应用场景的需要.因此,研究者提出一些更复杂的文本风格转换任务.第1类,多风格间的转换任务.Helbig等[53]将句子中的情感属性作为一种风格,提出一种端到端的基于词典替换的六分类情感转换模型.模型分为2部分:一部分负责找到需要替换的词,另一部分负责填词,保证新的句子包含目标情感.另外,增加了打分模块,对多个生成结果从情感风格、内容保留以及流利度这三方面打分,将得分最高的句子作为最后的结果.从模型的实验结果上看,只能处理一些简单的句子,主要目的是将二元的文本风格转换任务扩展到多元.第2类,将不同的文体作为风格.Yang等[54]提出在摘要和文章这2种文体之间实现风格转换.与一般的文本风格转换任务不同,文本风格是由整段文字决定的.为了弥补不同风格间数据的差异,补充上下文信息,该研究还引入了一个外部数据库,实现了在摘要和正文间的转换.第3类,Luo等[55]提出一种细粒度的风格转换模型,在传统粗粒度(正向或负向风格)的基础上,增加细粒度的控制,可以控制风格表达的程度,表达更细腻的风格.
6.2 基于上下文一致性的文本风格转换
以前风格转换任务的工作主要研究对象是单句之间的风格转换,没有考虑句子在风格转换后对上下文的影响.因此,Cheng等[33]提出一个新的文本风格转换任务,即基于上下文的文本风格转换任务.将上下文也作为控制样本生成的条件,在单句风格转换的基础上,保持上下文的一致性.在该研究中,模型将上下文与原句信息共同作为编解码器的输入,另外,增加了判断生成样本是否与上下文一致的分类器,引导模型生成样本.
6.3 预训练语言模型
预训练语言模型已经证明了它们在各种自然语言处理任务中的能力,包括机器翻译、文本分类、命名实体识别.特别是GPT2[40]在自然语言生成方面取得了显著的成功.如果将预训练模型所学知识应用于语体迁移任务中,能有效地提高迁移句子的质量,同时保证风格转换句子的流畅性.
