面向数据安全治理的联邦学习模型投毒DCR防御机制
2022-04-11黄湘洲彭长根谭伟杰
黄湘洲 彭长根,3 谭伟杰,3 李 震
1(公共大数据国家重点实验室(贵州大学) 贵阳 550025)2(贵州大学计算机科学与技术学院 贵阳 550025)3(贵州大学贵州省大数据产业发展应用研究院 贵阳 550025)4(贵州大学大数据与信息工程学院 贵阳 550025)(729375115@qq.com)
数字经济时代的核心生产要素是数据,海量数据带来巨大价值的同时也蕴藏着风险,尤其是大数据和人工智能的深度应用,使得数据安全形势日益复杂且充满挑战.针对模型、算法和数据的攻击日益剧增,风险威胁不断增强,危害范围急速扩大,影响程度日益加深,防护难度显著提升.安全风险不仅包括外部数据安全威胁,例如通过网络爬虫大量抓取数据、使用勒索病毒加密数据敲诈赎金、植入木马病毒来窃取数据、分析泄露数据进行撞库攻击等;还包括内部数据安全风险,例如运维人员因个人原因恶意破坏数据、内部人员窃取机密数据、研发人员在系统中设置后门等,数字经济时代的数据安全形势呈现出新特点、新模式.数据安全是数字经济发展的保障,也是数据价值实现的前提,数据安全不仅关系到数据本身,还与信息安全、网络安全、国家安全息息相关.因此加强数据安全治理与健全和完善数据安全治理体系已刻不容缓,同时也能够有效促进数字经济的平稳快速发展.
数据安全治理体系包括技术体系、标准和法规等多维度组织体系.其中数据安全技术体系建设包括数据资产梳理、数据分类分级、数据访问控制、数据加密、数据备份保护、隐私数据保护、数据水印和溯源、数据安全销毁、数据安全计算等.联邦学习作为人工智能安全的新技术模式,能够在各个节点的数据在不出本地的情况下进行联合模型训练,通过不共享本地数据而共享模型参数,实现数据的可用不可见功能,同时在保障数据隐私安全的前提下实现数据共享与应用,破解“数据孤岛”问题,以新的技术模式促进数据安全治理技术的实现.
联邦学习在大规模实际应用中面临着各种安全攻击的挑战,较为典型的是数据投毒攻击和模型投毒攻击[1-2].数据投毒攻击向节点添加恶意样本或错误样本,而模型投毒攻击则通过控制少数节点,向服务器更新错误或者恶意的参数,即可以达到影响全局模型性能与收敛的效果.联邦学习中的模型投毒问题在2018年由Bagdasaryan等人[3]首先提出,同时提出了一种新的模型替换方法来进行攻击,验证了该攻击方法在标准的联邦学习任务(如图像分类和单词预测)中的有效性.2019年Fang等人[4]对模型投毒拜占庭联邦学习进行了系统研究,该攻击方法能够操纵受损节点上的本地模型参数,使得全局模型具有较大的测试错误率.2021年Zhou等人[5]提出了一种基于联邦学习的深度模型投毒攻击方法.利用目标函数中的正则项,将恶意神经元注入神经网络的冗余空间中,该方法在实现较高攻击成功率的同时能够保持一定的隐身性.
针对联邦学习面临的模型投毒攻击威胁形势,越来越多的人开始关注模型投毒防御、保护模型参数安全的研究.2018年Bhagoji等人[6]提出了基于损失的模型投毒检测方法.中心节点将来自某个节点的更新添加到全局模型的当前状态,如果得到的模型验证精度远远低于聚合所有其他更新得到的模型验证精度,则服务器可以将更新标记为异常.2018年Fung等人[7]率先评估了联邦学习在面对模型投毒攻击时的脆弱性,随后提出了一种新的防御检测方法.该方法并不限制攻击者的预期数量,对客户端和数据的假设也更少.2020年Sun等人[8]提出了局部差分隐私聚合机制.该机制能够减少模型通信轮次,达到较高的全局模型训练效果.同年Naseri等人[9]提出了局部和中央差异隐私机制.该机制对敌手的攻击具有较好的防御效果,能够有效降低攻击精度.2020年Song等人[10]提出了一种无监督域自适应联邦算法.该算法能够保证半诚实的中心服务器和恶意第三方环境下的安全性.
目前的一些防御方法通常能做到检测攻击行为并进行防御,但无法解决攻击行为已对全局模型造成的损害与影响.针对该问题,本文提出一种动态缓冲可回调(dynamic cacheable revocable, DCR)模型投毒防御机制.该机制通过设置动态阈值,中心节点在每轮聚合参数之前先计算该轮次的阈值,包括各个节点在测试集上准确率的阈值和邻近节点距离的阈值,同时使用缓冲期机制和回调机制,相较于传统的防御方法特别是基于损失的模型投毒检测方法,在达到防御效果的同时可减少模型遭受的损害.
1 基础知识
数据安全治理技术体系中的一个重要内容就是数据安全计算技术.数据安全计算技术能够使得数据在隐私得到保护的情况下参与计算,发挥数据效用,这类数据安全计算技术在保障了数据计算安全性的同时满足了数据应用和安全合规的需求.联邦学习是数据安全计算中的关键技术,能够在多个节点协作使用数据的过程中避免各节点本地数据产生泄露的风险.充分发挥各节点本地数据的价值,保护数据安全,实现数据安全治理.
联邦学习在具体的模型训练过程中,各个参与方节点并不需要将各自的本地数据上传至中心节点,而是上传共享模型参数,最终训练出一个全局模型,这样既保护了本地数据隐私与安全,也发挥了本地数据的效用,达到了数据安全治理的效果.联邦学习能够保证最终的全局模型GFed的性能VFed和集中式机器学习训练出的模型GSum的性能VSum之间的差距足够小,即:
|VFed-VSum|<ε,
(1)
其中ε为任意小的正量值[11-12].


图1 联邦学习的训练过程
第1步:各节点上传参数至中心节点:
(2)
第2步:中心节点进行参数聚合,得到当前状态的全局模型[17]:
(3)
(4)
第3步:中心节点将经过聚合的参数(即全局参数)发送给各节点,各节点使用该参数在本地进行该轮次的本地模型训练,其中ηt为t轮次时的学习率,λ为防止过拟合的正则化参数,∇l为损失函数的梯度[18]:
(5)
(6)
第4步:循环以上3步,直到全局模型收敛或者达到最大训练次数,此时中心节点得到一个最终的全局模型:
Pc→GFed.
(7)
第5步:中心节点将最终的全局模型发送给各个节点[19-20]:
(8)
2 DCR防御机制
联邦学习在数据安全治理体系下扮演着重要角色,是数据安全治理技术体系中的数据安全计算核心技术.关于联邦学习中的模型投毒攻击问题,目前的一些防御方法无法解决攻击者的攻击行为,已经对全局模型造成一定损害与影响.针对该问题,本文提出了DCR防御机制,下面介绍攻击者的基本假设以及防御机制的具体运行算法.
2.1 基本假设
1) 攻击者的目标.假定攻击者的目标是尽可能阻止全局模型收敛,或者使得全局模型收敛在一个坏的局部最小值[21].
2) 攻击者的能力.假定攻击者控制了联邦学习系统中的某个节点,可以上传恶意参数更新进行模型投毒攻击,但攻击者对中心节点的聚合算法并不了解,对其他节点的情况也不了解,攻击者控制的节点不与其他节点串通,也没有其他合作伙伴交换信息[22].
2.2 DCR防御机制算法
基于以上条件,DCR防御机制总体算法如算法1所示:
算法1.DCR防御机制.
① 中心节点Pc初始化模型参数ω0,并将ω0广播给各个参与训练的节点;
② FOR 全局模型迭代更新轮次t= 1,2…
DO
③Pc存储当前轮次的全局模型参数;
④Pc随机选取节点总数N的一个子集Ct
(Ct≤N);
⑤ FOR 所有节点Pi(i∈Ct)并行地 DO

⑦Pi将更新后的模型参数上传至Pc;
⑧ END FOR
⑨Pc计算当前轮次阈值s;
⑩Pc对所有Pi上传的本地参数进行计算与比较;
中心节点在每一轮次的迭代中会存储当前轮次的全局模型参数,在对接收到的各个节点的本地模型参数更新进行聚合之前先计算当前轮次的动态阈值,动态阈值s的计算公式如下:
(9)
(10)
(11)
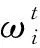
该防御机制主要有3个特点:
1) 动态阈值s.由于s是每一轮在对所有本地模型参数进行聚合之前计算出来的,敌手无法先验地了解防御机制,提高了敌手的攻击难度;
2) 缓冲期k.传统的基于损失的模型投毒防御方法为了达到较好的防御效果,通常在某个节点的本地更新出现1次异常那么该节点就会被抛弃,然而由于机器学习尤其是深度学习的黑盒以及不可解释的性质,某个节点可能仅仅这一轮次表现不好,但以后可能一直表现良好.传统的方法可能会将并不是模型投毒节点,而仅仅是某轮次表现不好的节点抛弃.设置一个k轮的缓冲期能够有效降低良性节点被“误杀”的风险,同时模型投毒攻击通常是持续进行的,恶意节点攻击行为的识别率也能保证.
3) 回调机制,通常意义上的模型投毒防御方法所能做到的一般在检测或者删除恶意节点,但这通常是模型投毒攻击已经发生,全局模型已经受到影响之后,对于恶意节点攻击行为对全局模型所造成的“污染”与损失并没有太多办法.回调机制的设置能够减少全局模型所遭受的负面影响,能够在联邦学习全局模型遭受攻击的情形下仍能保证模型有一个较好的性能.
3 仿真分析
实验仿真所采用的联邦学习开源框架是TensorFlowFederated(TFF);实验仿真环境是18.04.1-Ubuntu,Intel®Xeon®CPU E5-2678 v3@2.50 GH,2.50 GHz RAM 64.0 GB;数据集采用MNIST.本文分别使用DCR机制和基于损失的模型投毒防御方法来防御模型投毒攻击,对比模型在测试集上随着迭代轮次变化的损失函数(loss function)和准确率(accuracy)变化.实验参数设置为N=10,k=5,实验结果如图2和图3所示.

图2 损失函数对比
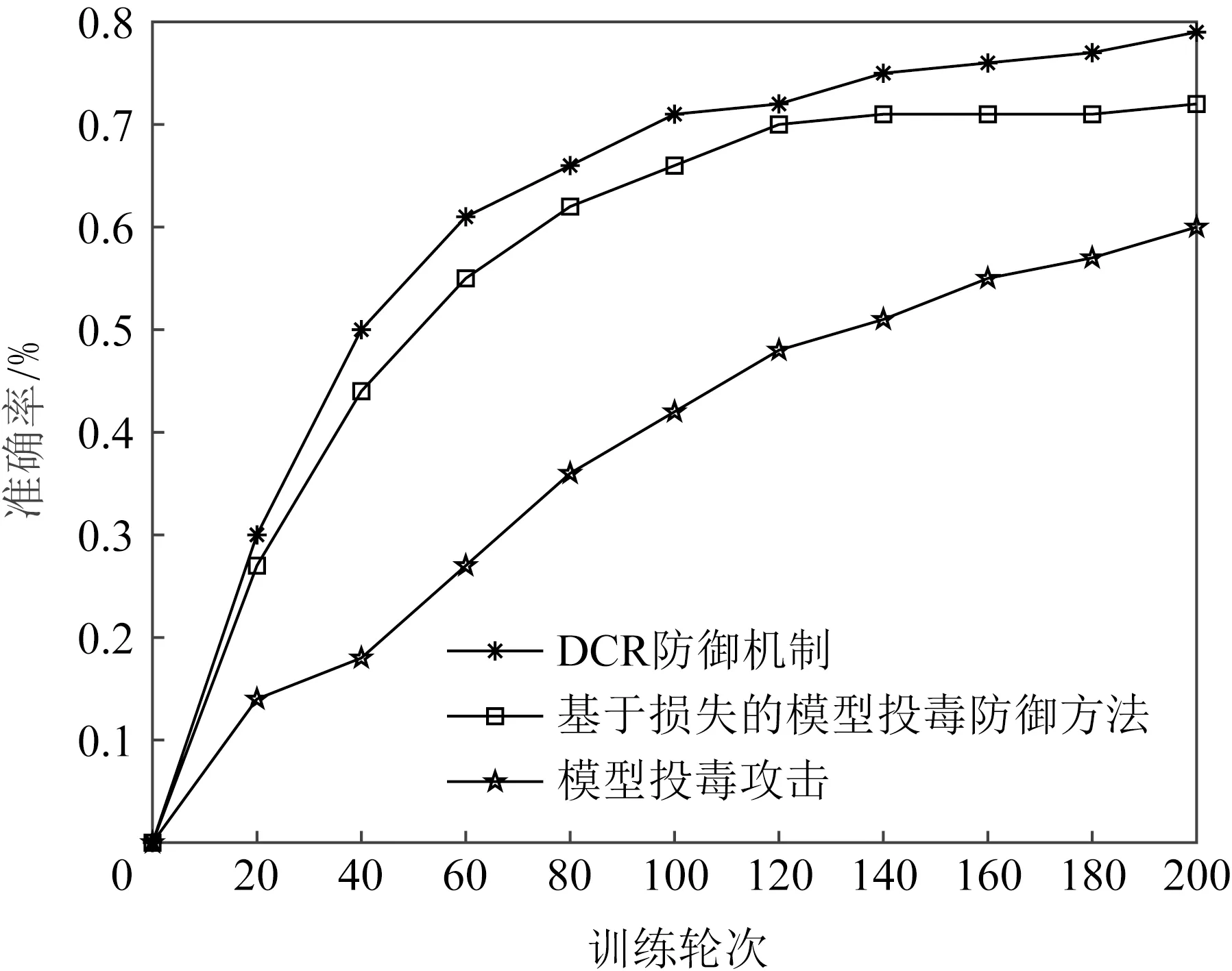
图3 准确率对比
攻击者的模型投毒攻击行为显著损害了全局模型的性能,而基于损失的模型投毒防御方法虽然有一定的防御效果,但是攻击者的模型投毒攻击行为对全局模型所造成的损害已经存在,最终全局模型的收敛效果不太理想.采用DCR模型投毒防御机制后,模型的损失函数与在测试集上的准确率相较于基于损失的模型投毒防御方法均表现更好,全局模型的损失函数更小,模型的准确率更高.DCR机制在实现防御效果的同时,能够较好地降低攻击行为造成的损害,有效保障联邦学习全局模型的安全与性能,实现数据安全治理技术体系下的数据安全计算.
4 结束语
数据投毒防御是数据安全治理的一个重要技术,本文针对联邦学习中模型投毒攻击对全局模型的影响,提出了一种DCR模型投毒防御机制.该机制主要有3个特点:动态阈值、缓冲期、可回调,提高了敌手的攻击难度,降低了良性节点被“误杀”的风险,减少了全局模型所遭受的模型投毒攻击负面影响,有效提升了联邦学习系统的安全性,保护了模型的性能与数据安全.实验仿真验证了该机制的效果,为数据安全治理下的数据安全计算提供了一种思路.未来的研究方向是综合考虑数据安全治理体系下联邦学习面临的数据安全威胁与挑战,能有效应对多种攻击与风险行为,同时保障防御性能与数据安全,充分发挥数据效用,实现数据安全计算,达到良好的数据安全治理效果.下一步将继续拓展人工智能中数据安全治理技术研究,包括训练数据的验证和决策结果评估等,以及提升虚假数据伪造与合成和对抗样本攻击的防御技术能力等研究,建立机器学习等数据安全治理技术保障体系.
