搜索引擎在信息搜集过程中的信息伦理问题研究
2022-04-02谭哲李诣斐
谭哲 李诣斐
关键词 信息伦理 搜索引擎 研究
1引言
在搜索引擎企业高速发展、搜索引擎企业对社会影响越来越大的同时,搜索引擎企业所爆发出来的信息伦理问题也越来越多[1] ,与社会的矛盾也越来越尖锐。搜索引擎的信息行为主要包括信息搜集、信息加工、信息提供、信息使用四个流程。其中,信息搜索是第一步。2013 年,在百度与360 之间展开的3B 大战中具有信息伦理内核和行业伦理准则性质的Robots协议成为判决的关键。这对我们解决搜索引擎在信息搜集中的伦理问题起到了启示作用。
2搜索引擎在信息搜索过程中的信息伦理问题案例
2.1案例选择———3B 大战案中对Robots 协议的使用
在搜索引擎的信息搜集中,尽管搜索引擎可以开发其他的产品,通过各种形式搜集信息,但采集网页却是搜索引擎的基础和重点———哪些网页应该采集、哪些网页不应该采集、万一有网页不愿意被采集。Robots 协议是行业内的软协议,不具备法律效力,只具备伦理约束效力。Robots 协议到底存在怎样的信息伦理内涵? 我们一探究竟。
3B 大战是搜索引擎行业的著名案例,360 违背百度设置的Robots 协议、不遵守行业规范也是案件判决的依据,下文将通过这个案例进行分析。
2.2案例回顾
2012 年年初,百度宣传360 通过360 浏览器故意窜改、仿照百度搜索结果,进行恶意、不良竞争。同年8 月,360 宣布推出“360 综合搜索”,正式进入搜索引擎市场,整个互联网行业为之震惊,百度的市场垄断地位或有望遭到动摇。360 将其浏览器的内置搜索引擎改为自主的360 搜索,替换了原来的Google 内核。
2012 年8 月28 日,百度又公开宣称360 侵犯了其Robots 协议,违背行业道德伦理规范,除对百度数据库进行了未被允许的抓取外,还对包括百度百科、百度知道在内的多项产品内容进行了抓取。360 的行为侵犯了百度的用户隐私和知识产权,百度单方面宣布用重置盗链的方式对360 进行反制:百度实行搜索结果中的跳转URL 动态加密,在使用一些浏览器时,用户搜索诸如关键词等行为也不会被记录。这样的强制手段旨在对网站和用户的信息进行保护,阻止搜索引擎的爬虫违背Robots 协议抓取本站数据,很多网站都曾采取这种方式,并非百度首创。
尽管这样的方式能阻止360 违背Robots 协议抓取信息[2] ,但360 见招拆招,采用了网页快照的方式进行反击。通过360 浏览器会被直接跳转至载有提示用户该页面系360 储存及具体储存时间的网页快照页面。
2012 年9 月,双方的恶意斗争终于引起了相关部门的关注。相关部门为避免再次发生3Q 大战中伤及用户的“二选一”现象,要求双方停止恶意斗争,不要再炒作。然而,事件并没有因此而平息,百度启用钓鱼策略,用“鬼节捉鬼”的手段证实了360 浏览器不仅抄袭其他浏览器的搜索结果,而且还用其360 浏览器记录用户的信息,严重侵犯用户隐私,造成用户的信息安全隐患。此外,百度还搜集证据,试图通过法律途径解决问题,同时呼吁用户对360 软件进行卸载。
2013 年4 月,法院判决百度诉360 不正当竞争和商标侵权案中360 不正当竞争行为成立。360 当即上诉。2013 年11 月法院驳回了360 的上诉。2014 年8月,北京市中级人民法院就此案做出一审判决,认为360 违反不正当竞争法,判决360 赔偿百度70 万元,同时驳回了关于百度申请禁止360 抓取其网页数据的行为。
法院认为,Robots 协议是搜索引擎业内的公认规则,属于伦理道德的范畴,行业企业需要遵守,360 搜索引擎没有遵守百度设置的Robots 协议,构成了不正当竞争。同时,法院也认为设置Robots 协议时要有充分的理由,百度对360 的针对性设置并不公平,因此驳回了百度的其他请求。
3案例分析———信息存取权问题
3.1 Robots 协议对搜索引擎信息存取权的影响
(1) 结果论分析:以上文案例为例,上述违反Robots 的情况将会导致搜索引擎企业为了获取更大的商业利益和赢得竞争而抓取网站保护数据以优化搜结果、抄袭同行对手的数据库及产品[3] 、滥用Robots 協议排挤竞争者等现象日益增多。搜索引擎可以为了降低成本而抄袭其他搜索引擎的搜索结果,搜索引擎也可能会为了获取更多的信息而侵犯一些网站不想被抓取的信息,这些信息可能对信息隐私和信息产权、信息安全有着极大的影响。
这样的行为会侵害网站、用户权益和公共利益。
最终打破搜索行业利益平衡,打乱行业秩序。从结果来说,违反Robots 协议是不利于结果论所追求“人类最大福祉”的。
(2)义务论分析:康德把义务理解为对普遍法则的尊重,就像网球俱乐部的会员需要遵守网球俱乐部的规则,而Robots 协议则可以看作是搜索引擎行业的普遍法则。Robots 协议是互联网网站的站长和搜索引擎服务商两者的共同协商之下于1994 年诞生的,其以Robots.txt 的形式实现,它可以引导搜索引擎的爬虫如何抓取本网站的信息,也可以告诉爬虫哪些信息可以抓取,哪些信息不能抓取,还能指定哪些搜索引擎可以抓取,哪些搜索引擎不可抓取。
Robots 协议的意义非凡,它的主要目的是保护网站中的敏感数据和信息,也可以保护网站用户的隐私,同时对网站的服务器也有保护作用,因为过高频率的抓取会给服务器带来巨大的压力。因此,Robots协议一经发布便被大部分的搜索引擎遵守。
在国内,《互联网搜索引擎服务自律公约》便有明文规定行业内成员要自觉遵守Robots 协议[4] ,在搜索引擎企业签署这一协议后,Robots 协议已上升为搜索引擎行业的信息伦理层面,应当普遍遵守。因此,违反Robots 协议是不符合义务论伦理的。gzslib202204022344(3)美德论分析:Robots 协议并非命令,它是网站为防止被别人肆意抓取站内数据信息的警告,依赖搜索引擎自觉遵守。尊重是传统美德,同时中国儒家传统美德中也有“ 己所不欲勿施于人” 一说。违反Robots 协议也会违反公平、平等、诚实信用等美德。从美德论的角度来说,作为搜索引擎企业也需遵守Robots 协议。
3.2前移动互联网时代搜索引擎对信息的掌控
在国内,曾经很多人打开浏览器后的第一个步骤便是进入百度页面,以获取网络信息。
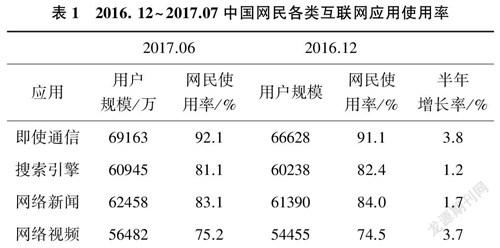
CNNIC 基于《2016.12~2017.06 中国网民各类互联网应用使用率》报告认为搜索引擎位列中国网民互联网应用使用率的第二位(表一)。在一般人都是用电脑使用浏览器浏览互联网信息的时候,搜索引擎对于网络中的信息有着极大的控制权。这时搜索引擎就成为网络世界的把关者,其可以决定让用户优先看到哪些网站,对信息的获取起到关键性影响。搜索引擎由此可以对信息资源进行掌控,用户想接触网络信息需要经由搜索引擎这道门,网站想让用户被看到也要通过搜索引擎这道门。
百度一下和Google it 两个搜索引擎的企业名直接成为搜索的代名词,也成为获得信息的代名词。
3.3移动互联网时代搜索引擎信息存取遭遇挑战
在这个移动互联网时代,更多的人选择通过手机上网。第40 次《中国互联网络发展状况统计报告》就指出搜索引擎的营收遭到挑战。
随着互联网的发展,越来越多的网站并不希望通过搜索引擎让用户找到,它们开始拒绝被搜索引擎抓取,搜索引擎也越来越难以存取、获得所有信息[5] 。
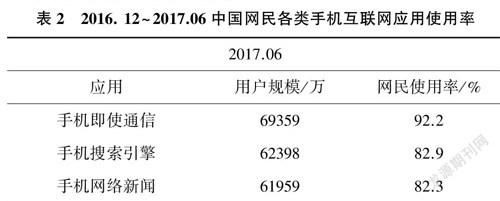
虽然搜索引擎应用在手机互联网应用中排名前三(表2),但搜索引擎这一产品似乎渐渐从底层瓦解,同时搜索引擎这门生意渐渐被分散,不再是一门集中网络资源的好生意。
