SPSS在进口铁矿产地品牌识别中的应用
2022-03-25陈永欣李慈进吴国境何龙凉
陈永欣 周 山 李慈进 吴国境 何龙凉
SPSS在进口铁矿产地品牌识别中的应用
陈永欣1周山2李慈进1吴国境1何龙凉1
(1.中华人民共和国防城海关,广西 防城港 536000;2.广西柳州钢铁集团有限公司,广西 防城港 538001)
文章介绍了建立进口铁矿产地品牌识别模型的方法。利用X射线荧光光谱法、红外吸收法、发射光谱法等常规方法测定所收集的进口铁矿样品中的主次元素含量,选择其中Al2O3、SiO2、Fe、K2O、Cr、CaO、MgO、V2O5、TiO2、MnO、Na2O、P、As、S、Ni、Zn、Pb共17种元素进行含量分析。在大量检测数据的基础上,分别采用SPSS软件中4种算法对元素和产地品牌的关联程度进行计算,建立不同进口铁矿产地品牌识别模型,并利用测试样本评估不同模型的准确性和可靠性。测试结果显示,判别分析和多层感知器神经网络能实现对铁矿石产地与品牌的识别。所建立的模型可应用于常见进口铁矿的产地品牌识别,对于维护贸易公平、保障矿石质量安全将起到积极的作用。
铁矿石;神经网络;判别分析;产地;品牌
引言
铁矿石是钢铁生产的重要原材料,是重要的国际大宗商品,由于受地质、环境等因素影响,不同产地铁矿石的主次元素含量存在某些区域特征。中国是世界上最大的铁矿石需求国,2020年中国累计进口铁矿石11.7亿吨,同比增加9.5%。虽然进口量不断增加,但品质却难以得到保障。少部分铁矿供应商采取了降低品质、以次充好的做法,甚至出现原产地造假,以扩大出口规模,骗取最惠国关税,谋求更大的经济利益。由于不同产地的铁矿品质、应用范围不尽相同,国内铁矿使用企业在冶炼时就需要制定不同的混料配比。伪冒铁矿原产地不仅直接损害了钢铁企业的利益,同时也严重扰乱了我国进口铁矿的市场秩序和进口货物海关监管,因此对于识别进口铁矿产地品牌就变得极为重要。
以已知国别铁矿石样本X 射线荧光光谱无标样分析数据为基础,武素茹、张博等[1,2]采用逐步判别法、逐步判别-Fisher判别分析法等建立进口国别的判别模型,识别进口铁矿石产地及品牌,准确率为74.6%以上。刘倩[3]应用波长色散-X射线荧光光谱无标样分析法,选择 O、Al、Mg、 Si、S、P、K、Ca、Cu、Fe、Ti、Ag、As、Pb、Mo、Zn和Mn 共17种元素含量作为变量,结合 F-score 筛选变量用于 BP 神经网络模式识别可以实现对铜精矿的国别识别。较多方法是应用无标样半定量方法确定元素含量,但不同仪器、不同实验室之间所得到的成分含量不尽相同,甚至相差较大,会影响到方法适用性[4-6]。
大数据应用为量化管理提供便利的同时,也需要全面掌握数据统计分析技术与方法。SPSS 是世界上最早采用图形菜单驱动界面的统计软件[7],由于其操作简单,已经在各个领域发挥了巨大作用。本文对798份防城口岸进口铁矿进行准确成分分析,并应用SPSS对所获得监测数据进行统计分析,分析出进口铁矿中各元素含量与产地品牌间的关系,利用不同统计方法建立矿石组分含量—产地品牌的“大数据”识别模型。该模型直接应用于进口铁矿的产地鉴别,不仅有利于保护我国进口铁矿贸易相关方的经济利益和保障进口铁矿的质量安全,而且对于维护国家外贸秩序稳定也将起到一定作用。
1 实验部分
1.1 样品收集
根据GB/T 10322.1-2014《铁矿石取样和制样方法》从防城口岸采集并制备来自8个国家21个品牌的进口铁矿化学分析样品,共798批次样品。采集的样品分布地域广,容量大,具有一定的独立性和代表性,包含了我国进口铁矿的主要来源国。
1.2 方法
所收集的样品采用以下方法对其中17种主次含量进行分析:SN/T 0832-1999 《进出口铁矿中铁、硅、锰、钙、钛、磷、铝和镁的测定——波长色散X射线荧光光谱法》、GB/T 6730.61-2005《铁矿石碳和硫含量的测定高频燃烧红外吸收法》、GB/T 6730.76-2017《铁矿石钾、钠、钒、铜、锌、铅、铬、镍、钴含量的测定电感耦合等离子体发射光谱法》。
通过采集来自全国主要铜精矿进出口口岸的澳大利亚、巴西、秘鲁、南非、乌克兰、毛里塔尼亚、伊朗、智利8个国家798批进口铁矿代表性样品,选择17种元素含量用于判别分析与神经网络建模,对比了一般判别、逐步判别、多层感知器神经网络、径向基函数神经网络对铁矿石产地品牌识别的适用性,讨论不同方法的差异,通过建模样品验证、交叉验证以及预测样品验证,可确保不同模型的准确性和适用性。
1.3 数据处理
1.3.1 判别分析
在分类确定的条件下,根据某一研究对象的各种特征值,判别其归属类型问题的一种多变量统计分析方法,称为判别分析,又称“分辨法”。其基本原理是根据一定的判别准则,建立相关判别函数,用研究对象的相关数值确定判别函数中的待定系数,并计算判别指标。据此即可确定某一样本属于何类。判别方法可分为参数法和非参数法,也可以分为定性资料的判别分析和定量资料的判别分析。常用方法有最大似然法、距离判别、Bayes判别和Fisher判别等4种。SPSS软件具有其中一般判别和逐步判别两种判别分析的算法。一般判别分析是根据已知变量数据来判别某些样本未知类别的方法。逐步判别分析则是筛选出跟要判别的类别相关性较强的变量指标来判别类别,而与类别相关性不强的指标,则给予剔除。
应用SPSS软件,采取两种不同方式对全部个案进行分析,分析个案处理摘要如表1所示,共有7.6%的个案排除在外,一般判别通过变量共提取了17个函数;而逐步判别通过变量共提取了16个函数,在每个步骤中,将输入可以使总体威尔克Lambda最小化的变量,最大步骤数为34,要输入的最小偏F为3.84,要除去的最大偏 F为2.71。

表1 分析个案处理摘要表
1.3.2 神经网络
近年来兴起的人工神经网络学科(ANN- artificialneuralnetworks)是集数学、计算机科学、神经学等学科为一体的综合性交叉学科。神经网络是由大量的称为神经处理单元的自律要素及这些要素相互作用形成的网络。神经网络分为一个输入层、若干个中间隐含层和一个输出层三个部分。神经网络分析法能够从未知模式的大量复杂数据中发现其规律。神经网络分析过程是一种自然的非线性建模过程,无需分清样本数据间存在的何种线性、非线性关系,克服了传统数据分析过程的复杂性及选择适当模型函数形式的困难,极大方便了样本数据建模与分析。目前应用的神经网络包括BP神经网络、RBF(径向基)神经网络、感知器神经网络、线性神经网络、自组织神经网络、反馈神经网络等。SPSS软件中具备两种神经网络算法:多层感知器神经网络和径向基函数(RBF)神经网络。
多层感知器神经网络是一个具有单层计算神经元的神经网络,网络的传递函数是线性阈值单元;主要用来模拟人脑的感知特征,采取阈值单元作为传递函数,适合简单的模式分类问题。径向基函数(RBF-Radial Basis Function)神经网络具有单隐层的三层前馈网络。模拟了人脑中局部调整、相互覆盖接收域的神经网络结构,是一种局部逼近网络,它能够以任意精度逼近任意连续函数,特别适合于解决分类问题。
应用SPSS软件中多层感知器和径向基函数两种方法,均使用样品798个,其中多层感知器训练数561(70.3%),检验数237(29.7%);径向基函数训练数546个(68.4%),检验数252(31.6%)。两种算法的输入层是一致的(17个),隐藏层同为1个,隐藏层中单元数和激活函数不一样,输出层中因变量和单元数一致,但激活函数和误差函数不一致。具体如表2所示。
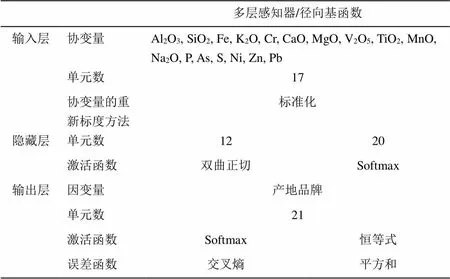
表2 神经网络算法网络信息
2 结果与讨论
2.1 判别方式
2.1.1一般判别
算法共提取的17个函数,可以解释100%的方差,其中函数1~7累计方差已经达到98.8%的方差,如表3所示,函数1~5的典型相关性在0.9以上,而函数8骤降到0.656,可以看出函数1~7尤为重要。如表4所示,显著性小于0.05时,具有统计意义,提取的函数有效,可以使用。同时可以看出函数15~17的显著性0.102~0.810之间,远大于0.05,证明这三个函数并非十分必要。从一般判别函数分类合并图(图1)也可以明显看出,不同产地的类别质心分散性较好,同一产地的质心较为接近,说明不同国家的品质能相互区别开;“澳大利亚中信精粉”与其它1~6种类相对分散,“巴西英美资源精粉”与其它8~11种类相对分散,说明这两种精粉与其它矿种区别较大;“伊朗精粉”和“智利CMP Atacama精粉”同一分类个案与质心重叠性不佳,说明这两个矿种的品质波动性较大。
一般判别算法的典则判别函数(1~7):
Y1=0.834X1+1.349X2+2.925X3-17.913X4+31.749X5-47.571X6-112.321X7-0.477X8-0.378X9-1.031 X10+6.907 X11+8.652 X12-20.157X13+85.507X14+49.007X15+54.327X16+36.478X17-92.686
Y2=-2.598X1-1.184X2+3.123X3-13.273X4-74.445X5+25.191X6-256.347X7+1.141X8+2.230X9-1.186 X10+6.396 X11+3.731X12+145.100X13+53.416X14+20.687X15+20.157 X16+16.861X17+85.437
Y3=0.346X1+0.445X2+5.171X3+5.014X4-180.998X5-40.140X6+102.434X7-0.626X8+12.007 X9+5.409X10+4.626X11+5.189X12+136.779X13-111.468 X14-35.050X15-60.722X16+18.044 X17-29.018
Y4=1.110X1-0.014X2+7.043X3+26.716X4+74.267X5+65.584X6-411.206X7+1.188X8+3.897X9+5.016X10+1.363X11+1.922X12-65.319X13+218.019X14-6.783X15-2.949X16+22.142 X17-9.514
Y5=0.963X1+0.517X2-7.653X3+35.977X4-61.525X5-151.645X6+346.439X7+1.878X8+1.114X9+2.561X10+2.609X11+4.908X12+17.352X13-183.264X14+10.463X15+15.537 X16-41.913 X17-44.150
Y6=1.405X1+2.308X2+0.366X3+49.243X4+273.704X5-41.850X6-266.263X7+4.322X8-5.095X9-3.836X10+0.961X11+0.746X12-72.016X13-2.415X14-9.586X15-21.251X16+51.709X17-160.526
Y7=0.842X1+2.112X2+3.389X3-35.118X4-235.823X5+100.148X6+4.097X7+4.948X8+7.367X9+7.270X10-1.019X11-0.886X12+98.242X13-3.557X14-18.662X15-4.440X16-42.033X17-142.793
为达到更高的识别准确率,笔者选择使用全部17个函数来建立判别模型,所建立的模型具有很好的识别效果,可准确地对94.4%个原始已分组个案进行分类,正确地对93.9%个进行了交叉验证的已分组个案进行了分类。

表3 一般判别函数特征值
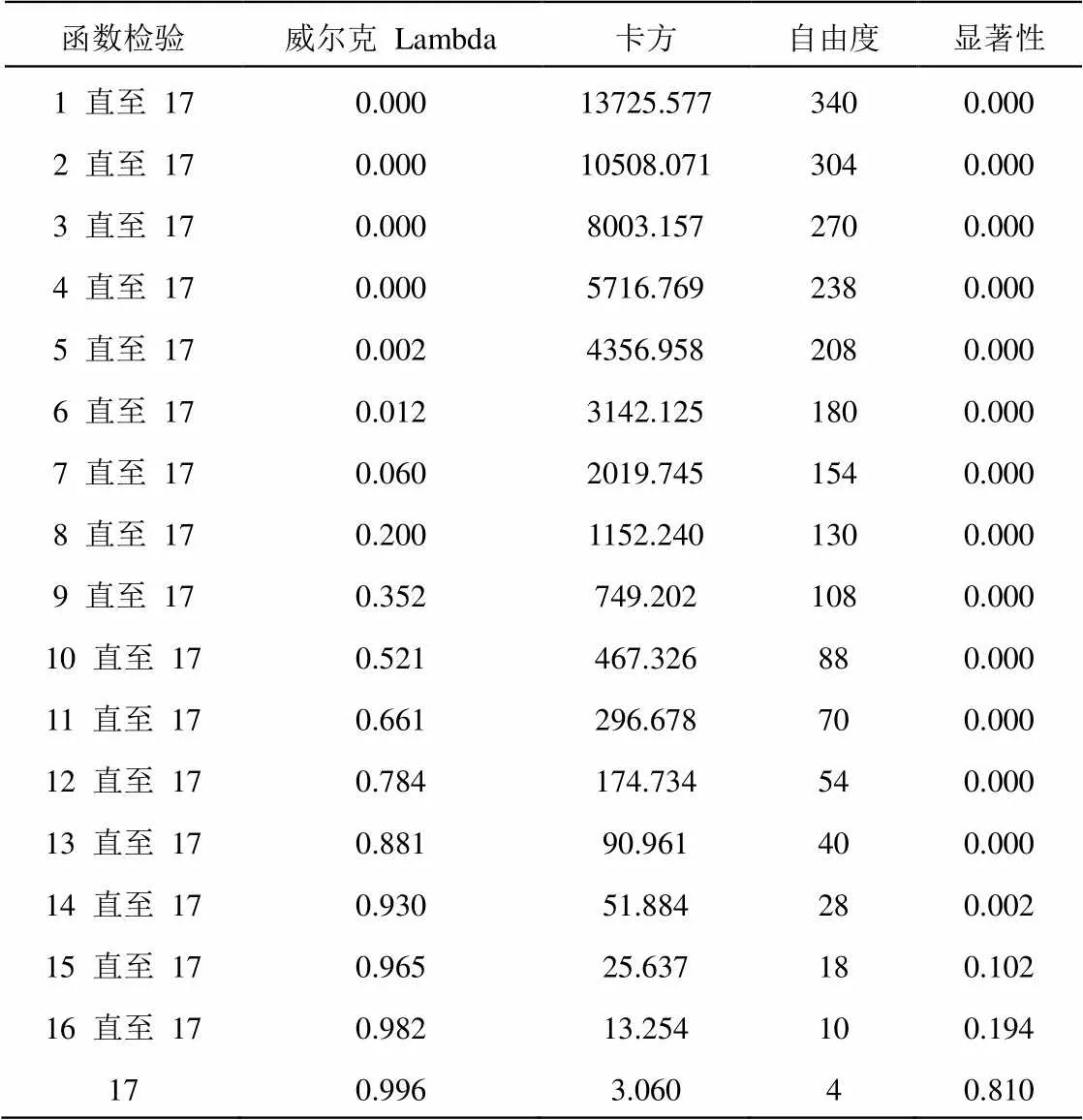
表4 一般判别函数威尔克 Lambda
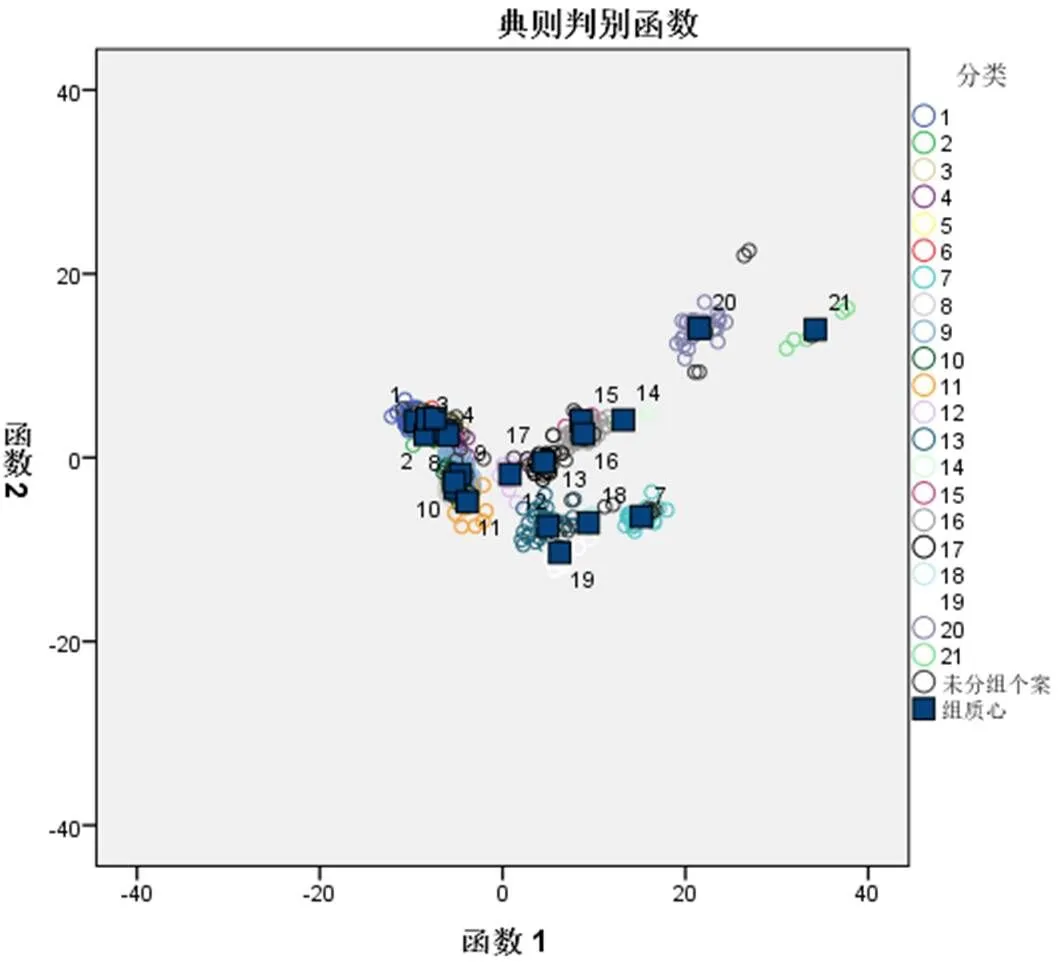
(1-澳大利亚BHP金布巴粉,2-澳大利亚必和必拓麦克粉,3-澳大利亚必和必拓纽曼粉,4-澳大利亚必和必拓纽曼混合块,5-澳大利亚力拓PB粉,6-澳大利亚力拓PB块,7-澳大利亚中信精粉,8-巴西CSNIOC6粉,9-巴西淡水河谷BRBF混合粉,10-巴西淡水河谷SSFG粉,11-巴西托克SSFS粉,12-巴西英美资源精粉,13-毛里塔尼亚SNIM TZFC粉,14-秘鲁精粉,15-南非阿斯芒粉,16-南非库博标准粉,17-南非库博块,18-乌克兰INGGOK 精粉,19-乌克兰KRIVOY ROG 精粉,20-伊朗精粉,21-智利CMP Atacama精粉)
2.1.2 逐步判别
算法所提取的16个函数可以解释100%的方差,函数1~7累计方差已经达到98.9%的方差。函数特征值(表5)显示函数1~5的典型相关性在0.9以上,而函数8骤降到0.644,可以看出函数1~7尤为重要。威尔克 Lambda表(表6)可以看出函数16的显著性0.077,证明这个函数重要性可以忽略。从逐步判别函数分类合并图(图2)也可以明显看出,与2.1.1一般判别图1的情况一致。
逐步判别算法的典则判别函数(1~7):
Y1=0.833X1+1.349X2+2.928X3-17.919X4-44.595X5-84.204X6-0.478X7-0.370X8-1.025X9+6.907X10+8.653X11-19.222X12+ 85.571X13+48.969X14+54.268X15+36.426 X16-92.706
Y2=-2.597X1-1.186X2+3.105X3-13.263X4+18.345X5-322.260X6+1.146X7+2.185X8-1.212X9+6.387X10+3.718X11+142.654X12+53.521X13+20.851X14+20.423X15+16.962X16+85.591
Y3=0.341X1+0.439X2+5.174X3+5.044X4-57.163X5-59.228X6-0.614X7+11.990X8+5.380X9+4.659X10+5.205X11+132.183X12- 111.851X13-34.839X14-60.458X15+18.509X16-28.619
Y4=1.107X1-0.016X2+7.036X3+26.597X4+72.658X5-345.183X6+1.179X7+3.920X8+5.039X9+1.353X10+1.918X11-63.116X12+218.292X13-6.813X14-2.925X15+21.706X16-9.328
Y5=0.970X1+0.528X2-7.664X3+36.293X4-157.876X5+292.529X6+1.902X7+1.066X8+2.520X9+2.622X10+4.917X11+ 15.293X12-183.992X13+10.479X14+15.454X15-41.379 X16-44.947
Y6=1.410X1+2.332X2+0.476X3+48.994X4-13.373X5-29.268X6+4.348X7-5.035X8-3.785X9+0.912X10+0.688X11-64.542X12+ 1.769X13-10.087X14-21.673X15+51.007X16-162.053
Y7=0.828X1+2.083X2+3.361X3-35.848X4+76.913X5-202.548X6+4.920X7+7.409X8+7.328X9-1.012X10-0.872X11+92.772X12-6.651X13+18.287X14-3.973X15-41.739 X16-140.838
为追求更高的识别准确率,还是选择使用全部16个函数来建立判别模型,该模型正确地对94.2%个原始已分组个案进行了分类,正确地对93.4%个进行了交叉验证的已分组个案进行了分类。

表5 逐步判别函数特征值

表6 逐步判别函数威尔克 Lambda

(1-澳大利亚BHP金布巴粉,2-澳大利亚必和必拓麦克粉,3-澳大利亚必和必拓纽曼粉,4-澳大利亚必和必拓纽曼混合块,5-澳大利亚力拓PB粉,6-澳大利亚力拓PB块,7-澳大利亚中信精粉,8-巴西CSNIOC6粉,9-巴西淡水河谷BRBF混合粉,10-巴西淡水河谷SSFG粉,11-巴西托克SSFS粉,12-巴西英美资源精粉,13-毛里塔尼亚SNIM TZFC粉,14-秘鲁精粉,15-南非阿斯芒粉,16-南非库博标准粉,17-南非库博块,18-乌克兰INGGOK 精粉,19-乌克兰KRIVOY ROG 精粉,20-伊朗精粉,21-智利CMP Atacama精粉)
2.1.3 两种判别方式的比较
从上述2.1.1和2.1.2可知,虽然算法不一样,激活函数、误差函数不尽相同,逐步判别所提取的函数比一般判别少1个,但从两个模型的参数评估来说,在铁矿石产地和品牌模型的建立上,一般判别与逐步判别没有明显差异,函数1~7的累计方差达到了98%以上,函数1-13的显著性为0.000,重要的是两者准确性都较为理想,超过93%。
2.2 神经网络
2.2.1 敏感性
敏感性分析,主要是通过对神经网络各个参数的敏感性进行分析,比较出对网络模型的输出决策几乎不起作用或无影响的连接或输入结点,然后进行网络裁剪,从而达到网络结构简化的目的。从曲线下方的区域数值(表7)可以看出,多层的敏感性比径向基的要好,曲线下方的区域,多层感知器的数值大于0.998,而径向基的为0.873~0.998之间。
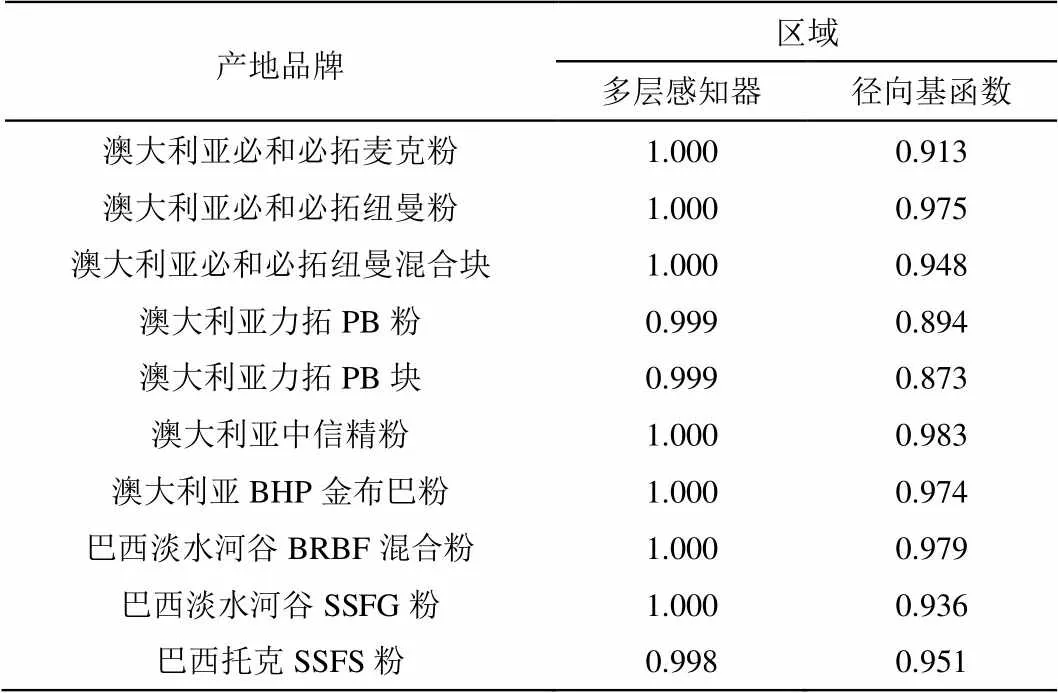
表7 不同特异性-敏感性曲线下方的区域
续表7

巴西英美资源精粉1.0000.996 巴西CSNIOC6粉(分类12)0.9990.974 毛里塔尼亚SNIM TZFC粉1.0000.992 秘鲁精粉1.0000.986 南非阿斯芒粉1.0000.967 南非库博标准粉1.0000.996 南非库博块1.0000.939 乌克兰INGGOK 精粉0.9990.976 乌克兰KRIVOY ROG 精粉1.0000.985 伊朗精粉1.0000.998 智利CMP Atacama精粉1.0000.998
2.2.2 增益及效益
两种方法在增益和效益指标方面差异较大,具体见图3至图6。(1)多层感知器:当使用10%样本量计算时,增益就在60%以上,大部分产地品牌的增益接近100%;当使用20%样本量计算时,全部增益接近100%。也就是说,只用到10%左右的样本就可以筛选出来自同一产地品牌的样本。这也从效益图中也得到印证。(2)径向基函数:相比于多层感知器,增益就没有那么明显,当使用20%样本量计算时,尚有不少产地品牌增益尚未达到90%;当使用70%样本量计算时,“澳大利亚力拓PB块”增益才90%。

图3 多层感知器增益图
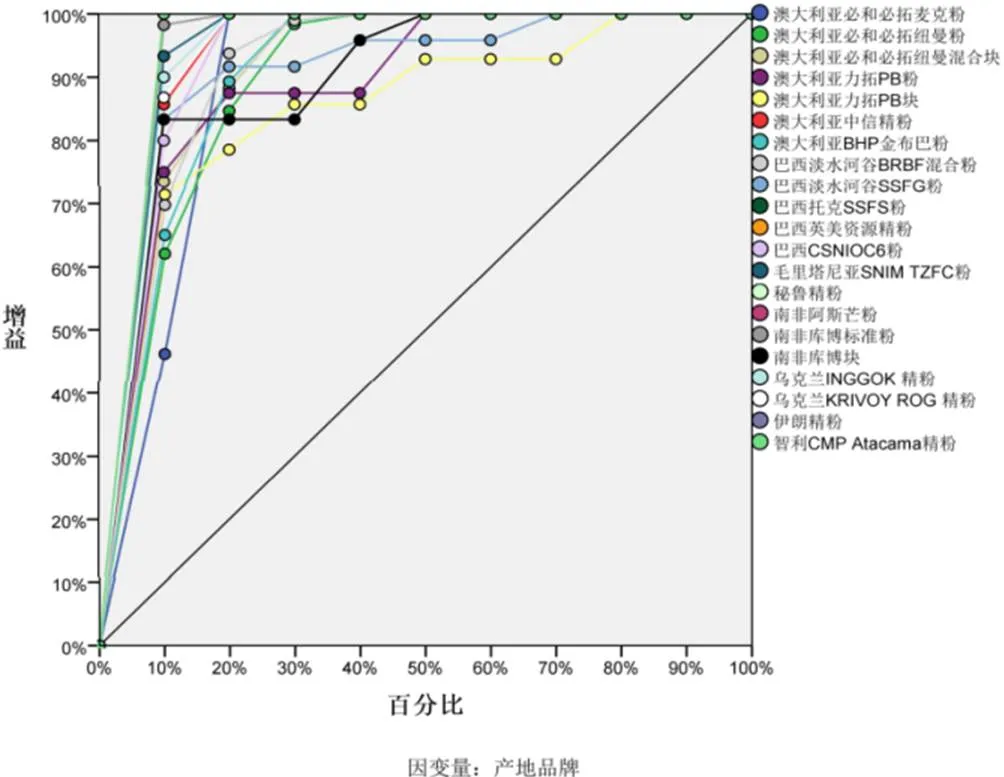
图4 径向基函数增益图
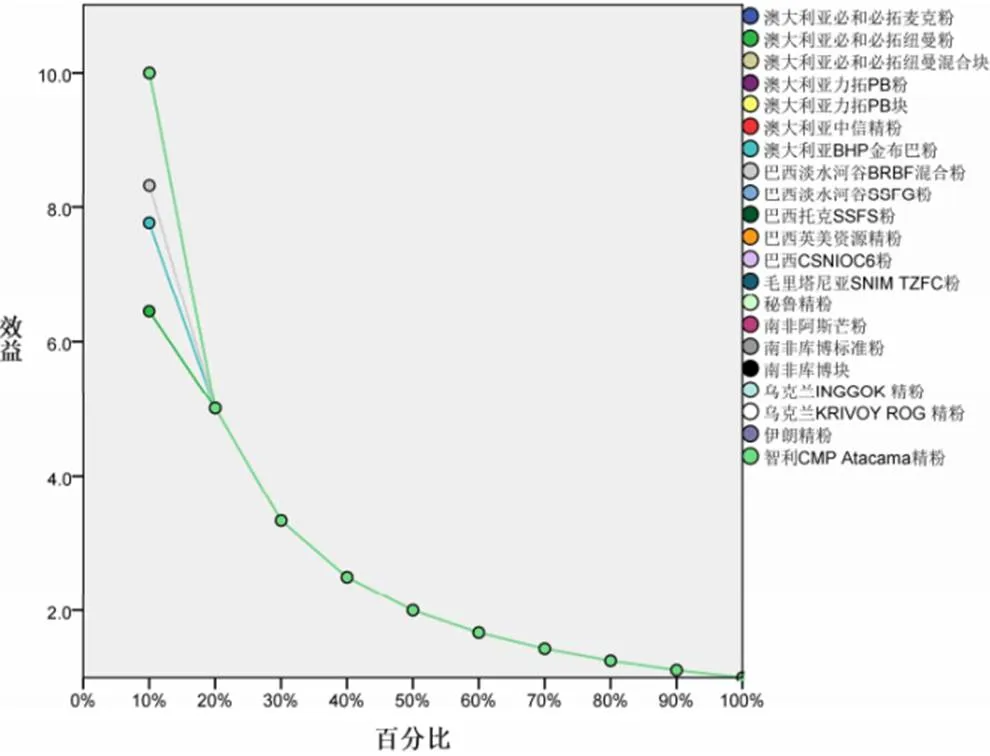
图5 多层感知器效益图
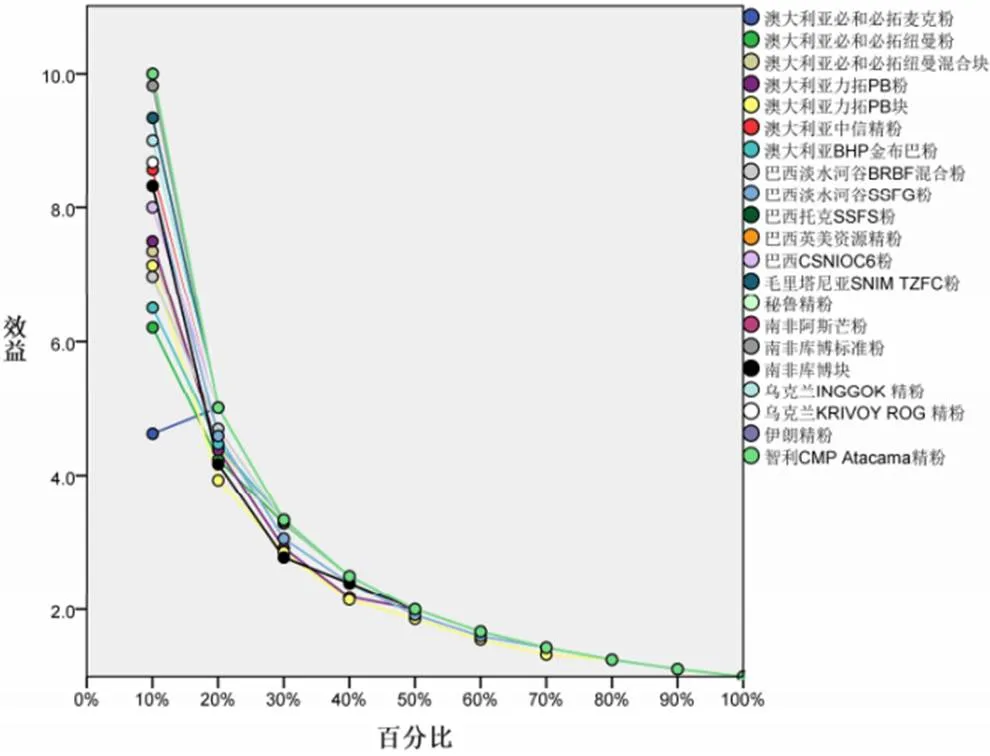
图6 径向基函数效益图
2.2.3 自变量正态化重要性
对17个自变量正态化重要性进行分析,多层感知器模型中各变量重要性在0.020~0.099之间,前五的因变量分别为SiO2(100%)、Al2O3(84.0%)、K2O(69.8%)、Na2O(66.6%)、TiO2(65.2%);径向基模型中各变量重要性在0.038~0.076之间,前五的因变量分别为MgO(100%)、V2O5(89.2%)、S(89.0%)、Na2O(87.7%)、MnO(85.6%)。两者前五因变量中只有Na2O一个相同,从另一方面证明两个算法有较大区别,模型的权重完全不一样。具体数值如表8所示。
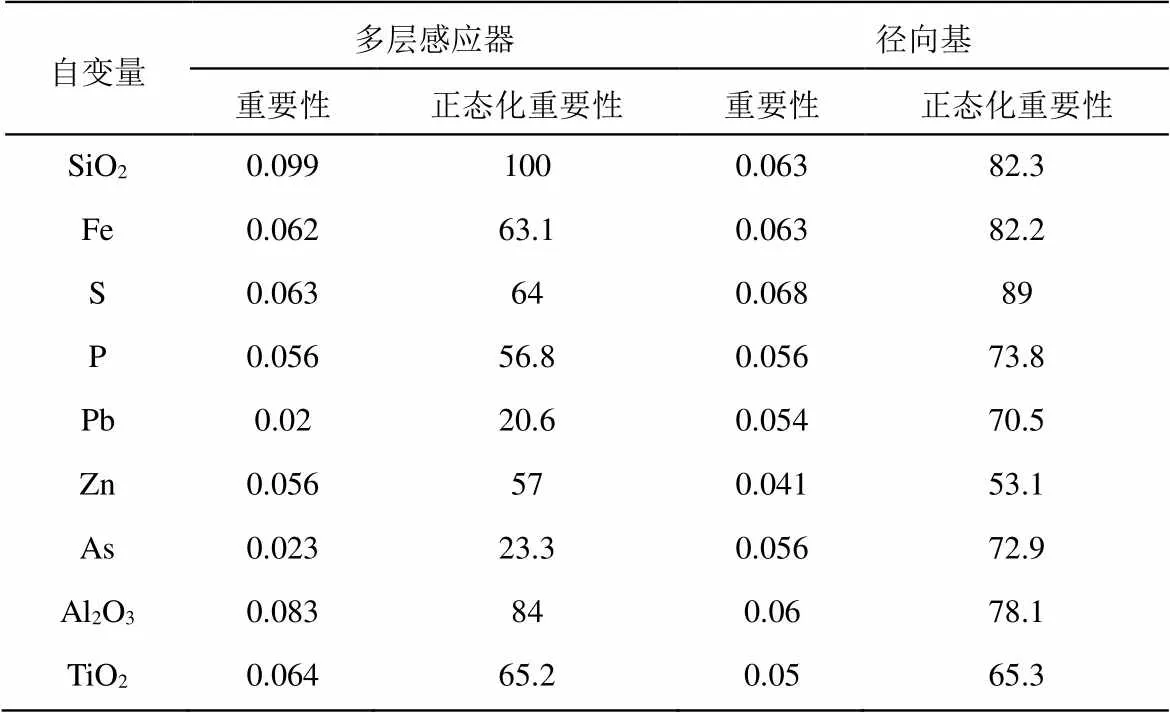
表8 自变量重要性
续表8

MnO0.05555.30.06585.6 CaO0.05555.90.05977.3 MgO0.06610.076100 Ni0.05656.90.03849.2 Cr0.05353.80.05268.2 V2O50.0661.20.06889.2 K2O0.06969.80.06483.7 Na2O0.06666.60.06787.7
2.2.4 准确性
(1)多层感知器:训练中使用的中止规则为“误差在1个连续步骤中没有减少”,交叉熵误差为34.068,不正确预测百分比为1.6%;在检验计算时,交叉熵误差为31.641,不正确预测百分比为4.2%。多层感知器分类结果,训练集中3个澳大利亚样品、4个巴西粉矿样品、1个乌克兰精粉被识别为同一国家别的品牌,1个毛里塔尼亚SNIM TZFC粉被识别为乌克兰INGGOK 精粉。训练集中“乌克兰INGGOK 精粉”的准确性最低为80%,高达14个品牌的准确性达100%;检验集中,共有13个品牌的准确性达100%,“南非阿斯芒粉”和“智利CMP Atacama精粉”准确性仅为50%,总体准确性为95.8%。经过训练之后可以达到很好的精度和较高的学习效率。收敛速度很快,可以在一定情况下逼近给定的任意精度。
(2)径向基函数:训练中平方和误差103.893,不正确预测百分比为27.7%;在检验计算时,平方和误差56.179,不正确预测百分比为34.5%。径向基函数分类结果较为不理想,训练集中,共有8个产地品牌样本准确性为0,准确性最高的为澳大利亚BHP金布巴粉,总体准确性仅为72.3%;检验集中,同样共有8个产地品牌样本准确性为0(品牌与训练集一致),总体准确性仅为65.5%。
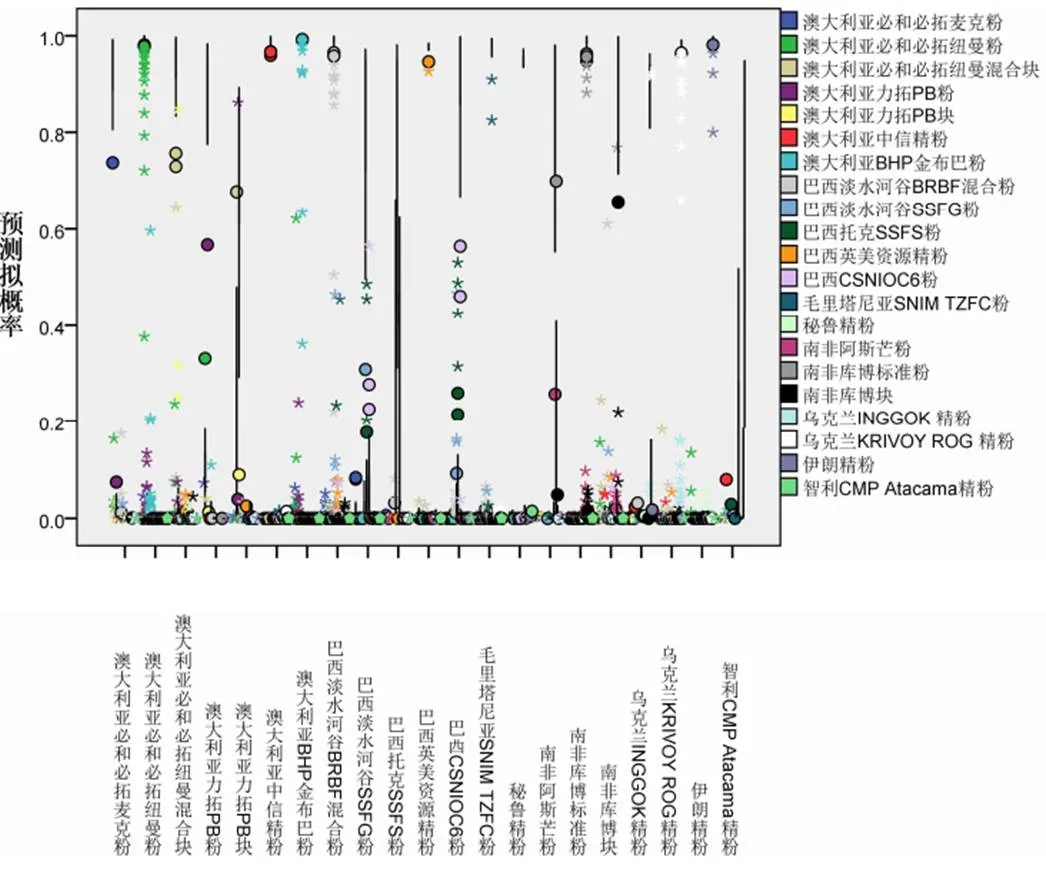
图7 多层感知器预测拟概率

图8 径向基函数预测拟概率
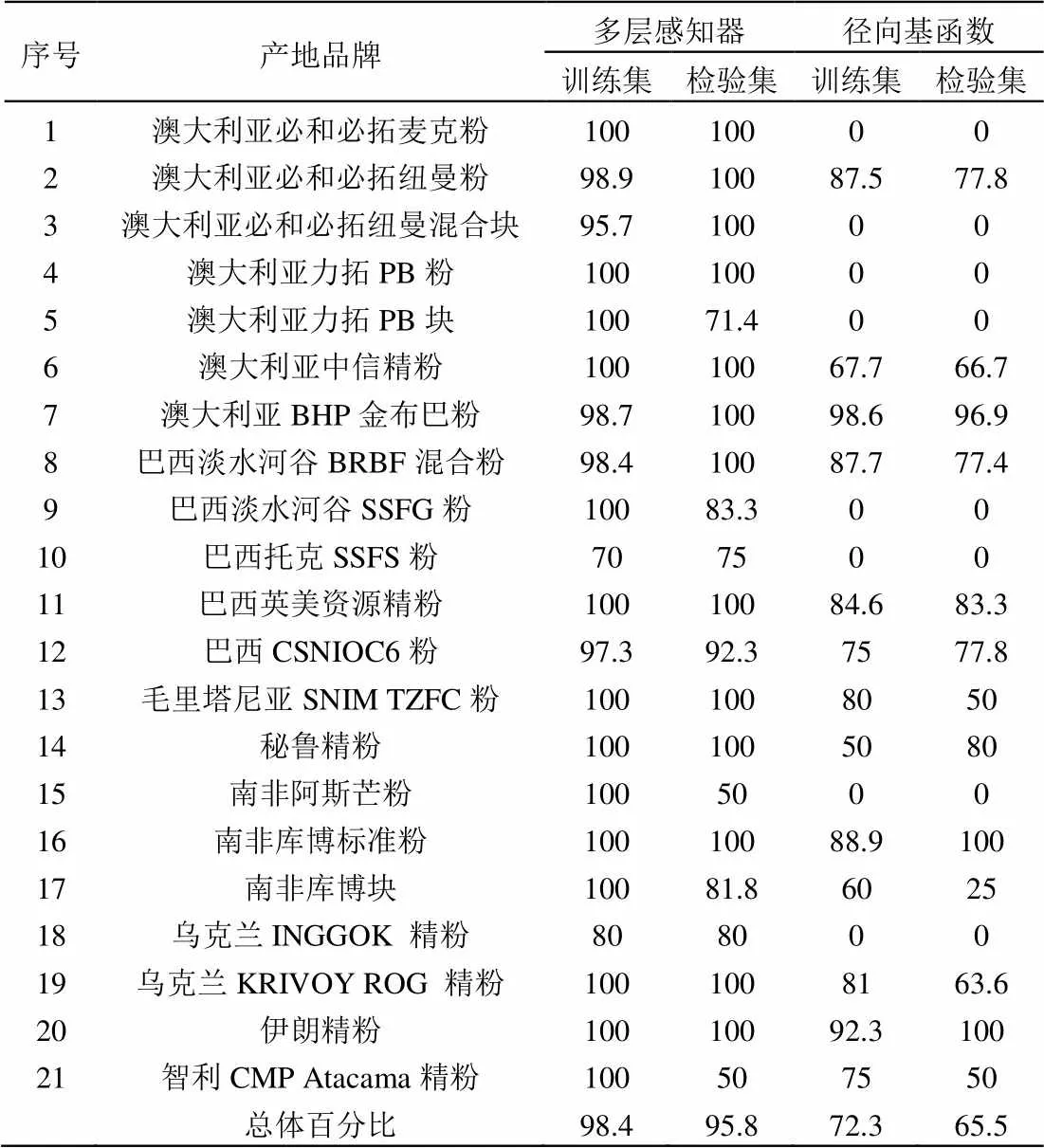
表9 两种方法的正确百分比
3 结论
比较4种模型的结果,径向基函数神经网络模型中多个产品品牌无法正确识别,总体准确性仅为65.5%,无法在实际中获得应用;一般判别、逐步判别、多层感知器神经网络模型识别结果很好,三者的总体准确性高于90%,可以进行很好的预测和分类,在综合信息成矿信息预测中具有特征提取的作用和好的泛化能力(推广性),即有效逼近样本蕴含的内在规律。模型样品原产地及建模样品数量与模型识别的准确率存在很大关系,随着后续样品收集数量增加,该模型数据库还可继续丰富,模型的稳定性将得到进一步的提升。
[1]武素茹,谷松海,宋义,等. 进口铁矿产地鉴别模型的建立[J]. 计算机与应用化学,2014,31(12): 1543-1546.
[2]张博,闵红,刘曙,等. X 射线荧光光谱结合判别分析识别进口铁矿石产地及品牌[J]. 光谱学与光谱分析,2020,40(8): 2640-2646.
[3]刘倩,秦晔琼,刘曙,等. X 射线荧光光谱结合 BP 神经网络识别进口铜精矿产地[J]. 光谱学与光谱分析,2020,40(9): 2884-2890.
[4]纪雷,林雨霏,孙健,等. 我国进口铁矿石有害元素含量代表值估计及整体特征分析[J]. 分析试验室,2007,26(6): 58-61.
[5]孟海东,殷跃,孙家驹,等. BP神经网络在矿产资源分类识别中的应用[J]. 西部探矿工程,2012,24(8): 137- 139,145.
[6]阴江宁,克炎,李楠,等. BP神经网络在化探数据分类中的应用[J]. 地质通报,2010,29(10): 1564-1567.
[7]吴占福,马旭平,李亚奎. 统计分析软件SPSS介绍[J].河北北方学院学报(自然科学版),2006,56(6): 23-25.
Application of SPSS in Brand Recognition of Imported Iron Ore Origin
This paper introduces the method of establishing the brand recognition model of imported iron ore origin. The contents of primary and secondary elements in the collected imported iron ore samples were determined by conventional methods such as X-ray fluorescence spectrometry, infrared absorption spectrometry and emission spectrometry. A total of 17 elements including Al2O3, SiO2, Fe, K2O, Cr, CaO, MgO, V2O5, TiO2, MnO, Na2O, P, As, S, Ni, Zn, Pb were selected for content analysis. Based on a large number of test data, four algorithms in SPSS software are used to calculate the correlation degree between elements and origin brand, establish brand recognition models of different imported iron ore origin, and use test samples to evaluate the accuracy and reliability of different models. The test results show that discriminant analysis and multilayer perceptron neural network can recognize the origin and brand of iron ore. The established model can be applied to the origin brand identification of common imported iron ore, and will play a positive role in maintaining trade equity and ensuring ore quality and safety.
iron ore; neural network; discriminant analysis; origin; brand
TF52
A
1008-1151(2022)01-0005-07
2021-11-15
2020年防城港市技术研究与开发财政补助项目(防科AD20014029)。
陈永欣(1981-),男,中华人民共和国防城海关工程师,从事进口矿产品监管工作。
