基于改进YOLOv5的道路车辆跟踪算法
2022-03-25张文龙南新元
张文龙, 南新元
(新疆大学 电气工程学院,新疆 乌鲁木齐 830047)
道路场景中最重要的组成部分是汽车,随着自动驾驶汽车出现,道路场景下汽车跟踪技术的研究日益重要,作为自动驾驶技术环境感知的一个重要组成部分,其对多目标跟踪算法的准确度和实时性要求较高。
目前,多目标跟踪算法主要分为传统方法和基于深度学习方法。传统方法主要有光流法[1]、核相关滤波[2-4]等,其跟踪速度快,但缺乏对尺度变化目标的处理,导致跟踪效果不佳。基于深度学习的跟踪算法在行人重识别(ReID)技术[5-6]推动下获得了前所未有的发展,实现了速度与精度的双重提升。基于ReID的目标跟踪算法主要分为2类:one-shot和two-stage,这2类模型都是基于检测的跟踪(tracking-by-detection)方法。其中,two-stage算法将跟踪流程分为检测和匹配2个独立的过程,使用2个不同的网络分别提取特征,虽然这样可以提高算法准确度,但是使用2个网络模型计算成本过高,不适合自动驾驶这种实时性要求较高的场景。典型的two-stage算法有DeepSORT[7]、HOGM[8]等。随着多目标跟踪算法发展,为解决two-stage算法速度过慢问题,one-shot算法被提出,这类算法通过将ReID嵌入到检测器中,将2个独立的任务作为一个多任务学习模型,通过共享权值,同时输出目标检测框和ReID表观特征,达到近似实时的速度。如Wang等[9]提出JDE(joint detection and embedding)算法,通过使用YOLOv3[10]作为检测器,将ReID嵌入到检测器中,共同学习特征表示,获得了速度与精度的双重提升;Zhang等[11]通过分析JDE的不足,提出了FairMOT算法,使用DLA(deep layer aggregation)[12]模型和anchor-free算法[13],提高了算法的准确度;晏康等[14]通过组合空间和通道注意力,一定程度上改善了JDE跟踪算法的性能;薛俊韬等[15]利用MobileNet[16]替换YOLOv3检测器的骨干特征提取网络,显著提高了跟踪算法的实时性,但减少了跟踪算法的跟踪精度;马永杰等[17]通过在YOLOv3算法上增加一个检测头,并与DeepSORT算法结合,提高了算法对汽车的检测精度。
虽然这些文献对轻量级网络进行了初步研究,但在非常有限的计算预算中追求最好的精度-速度折中仍然是视觉领域的难点。本文的目的是把这个权衡作为一个整体,考虑精度和实时性,通过将改进的YOLOv5检测算法与JDE跟踪算法结合,同时设计关联融合网络来缓解JDE算法多任务学习中不同任务之间的竞争问题,提出一种有效的道路车辆多目标跟踪算法,该算法能有效减少模型复杂度,提高JDE算法实时跟踪速度,且不降低算法跟踪性能。
1 相关工作
1.1 注意力机制
注意力机制在计算机视觉领域取得了巨大成功,它仅包含少量参数,可以带给模型性能提升,通过关注感兴趣信息,对提取特征进行过滤,提高特征重要性。注意力机制主要分为通道注意力机制、空间注意力机制和混合注意力机制。通道注意力机制通过按通道对特征图进行提取,使用提取到的权值来表示特征重要性。SENet[18]网络通过使用全局平均池化获得每个特征通道上的平均值,然后使用2个全连接层学习非线性特征,最后将获得的权重与原输入特征加权。ECANet[19]使用一维卷积学习通道之间的交互信息,避免特征完全独立,从而学习更有效的特征表示。FCANet[20]从频域的角度思考通道注意力,获得了较好的效果。混合注意力机制结合空间注意力和通道注意力同时提取目标的空间信息和通道信息。如Woo等[21]将空间注意力与通道注意力串联,提出了CBAM注意力机制,在多个计算机视觉任务中获得了优秀的性能。
1.2 JDE模型
JDE算法通过扩展YOLOv3网络,将ReID和检测器集成到一个网络模型中,共享低级特征,能有效避免重复计算,JDE基本结构如图1所示。
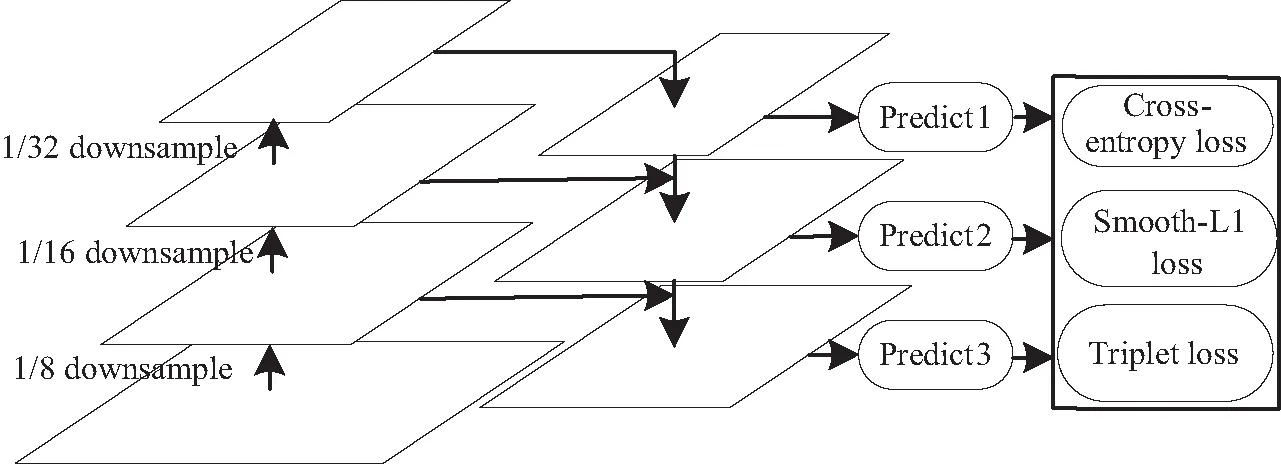
图1 JDE结构Fig. 1 Structure of JDE
从图1中可以看出,JDE采用特征金字塔网络(feature pyramid networks, FPN)[22]结构提取多个不同尺度的特征图进行预测,从而提高了目标检测中尺度变化目标的检测能力。输入的视频帧首先通过主干网络向前传递,获得3个不同尺度的特征图,即分别具有1/32、1/16和1/8下采样率的特征图。接着,将下采样率为1/32的特征图进行上采样,并通过跳过连接与下采样率为1/16的特征图进行融合,下采样率为1/8的特征图同理。然后,在这3个不同尺度的融合特征图上添加YOLO检测头,每个YOLO检测头由几个卷积层堆叠组成,并输出一个大小为H×W×(6A+D)的预测特征图,式中:A表示anchor的数量;D是ReID中embedding的维数;H表示特征图的高;W表示特征图的宽。最后,将得到的特征图用于后续的卡尔曼滤波和匈牙利算法进行轨迹匹配。
2 基于YOLOv5的多目标跟踪算法
2.1 改进的YOLOv5检测网络
与YOLOv3检测算法相比,YOLOv5作为最新的一阶段目标检测算法,获得了速度与精度的双重提升。但对于资源较少的设备,YOLOv5模型仍然较大,不适合部署到资源较少的设备上。模型参数量计算如式(1),
J=d×Cin×k×k×Cout。
(1)
式中:Cin、Cout分别表示输入、输出通道数;k表示卷积核大小;d表示卷积模块的数量。从式(1)中可以看出,当模型的输入和输出通道由C变为nC时,模型参数量将扩大n2倍;当卷积核大小由k变为nk时,同理,模型参数量也将扩大n2倍;若将模型的深度由d变为nd时,参数量将扩大n倍。
YOLOv5特征提取网络通道数C被设置较大,通过式(1)可知,其模型复杂度过高。为了减少模型复杂度,提高模型的实时检测速度,使算法更适合自动驾驶任务,本文采用EfficientNetV2[23]替换YOLOv5的特征提取网络。EfficientNetV2通过缩减通道宽度C,扩增深度d,实现了模型复杂度和准确度的折中。EfficientNetV2主干网络由Fused-MBConv和MBConv模型结构组成,其结构如图2所示。
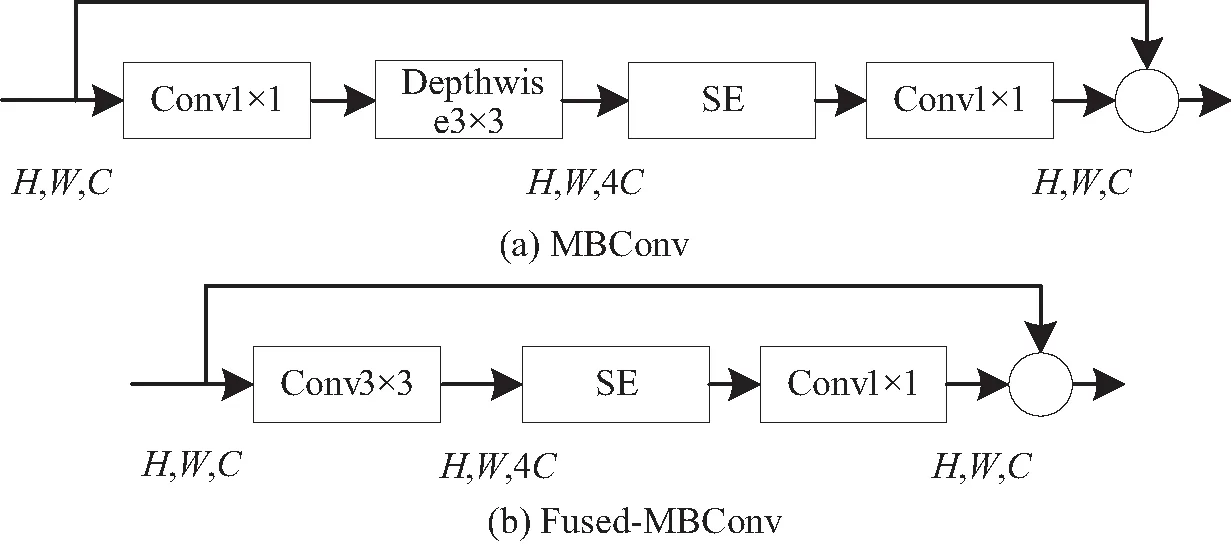
图2 MBConv、Fused-MBConv结构Fig. 2 Structure of MBConv and Fused-MBConv
MBConv核心模块采用深度可分离卷积[16],相比传统卷积,它具有更少的参数量,深度可分离卷积与传统卷积参数量下降比为
(2)
EfficientNetV2使用SENet提高模型准确率,SENet通过全局平均池化提取特征图的全局信息,利用得到的1×1×C矩阵来表示特征,但仍然存在不足。从频域的角度分析,全局平均池化提取特征将会造成信息丢失,通过二维离散余弦变换(2D-DCT)分析,2D-DCT变换可以描述为
(3)
式中:f2d表示2D-DCT频谱;x2d表示输入特征。2D-DCT逆变换可以被描述为
(4)
令式(3)中h和w为0,式(3)变为
(5)
式中gap表示全局平均池化。从式(5)可以看出,全局平均池化只是2D-DCT的特殊形式,与低频分量成比例关系。因此EfficientNetV2中SENet使用全局平均池化会造成信息丢失,且SENet中通过使用2个全连接层对通道进行挤压和扩张,获取更多非线性变换,但2个全连接层的使用会带来较多参数量。为了进一步提高模型实时检测速度,降低模型复杂度,本文受FCANet启发,结合DCT与ECANet提出D-ECA通道注意力,替换EfficientNetV2中的SENet,提出的注意力模块如图3所示。
将输入特征按通道分为N组,每组通道数C/N,利用式(3)计算每组离散余弦变换权值,如式(6)所示。
(6)
式中D(X)表示2D-DCT变换。由式(3)、(5)可知,相比使用全局平均池化,DCT能够获取更多的频率信息。然后使用核大小为k的一维卷积学习相邻通道之间的信息,为了避免通过交叉验证手动调整k,设计了一种自适应确定k的方法,核大小k自适应描述如式(7)所示。
(7)
式中:|t|odd表示最近的奇数t;a和b设置为2和1,并在本文所有实验中保持一致。最后使用Sigmoid激活函数输出注意力权值,与输入特征加权融合。
对于电视上经常播放的“细胞助长灵”“增高鞋”“增高药”之类的广告,对我有难以言喻的吸引力,我总是按捺不住想要去尝试一下,说到这儿,我想你已经明白了,没错,我就是人们说的“矮个儿”。你无法想象我有多讨厌这个词语。“矮”给我带来了许多的苦恼。
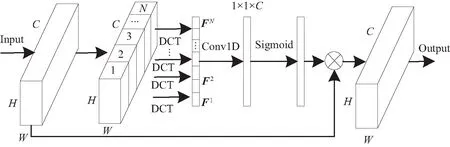
图3 通道注意力Fig. 3 Channel attention
2.2 关联融合网络
相比传统的多目标跟踪算法,JDE虽然获得了精度与速度的双重提升,但通常低于两阶段跟踪算法。文献[11]指出,诸如JDE这种单阶段多目标跟踪算法,由于多任务学习中不同任务之间的竞争,使学习到的ReID特征不是最优的,这将导致大量的ID切换。为了解决这个问题,参考DANet[24]和PADNet[25],通过设计关联融合网络(associative fusion network, AFN)来提高JDE跟踪算法中检测器与ReID的协作学习,提出的关联融合网络如图4所示。
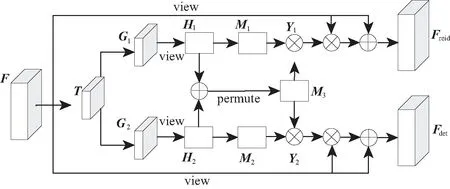
图4 AFN结构Fig. 4 Structure of AFN
图4中F∈RC×H×W表示来自检测头的输出,首先使用一个自适应平均池化层获取特征信息T∈RC×H′×W′,然后使用2个卷积核大小为3的卷积层分别学习ReID的嵌入信息G1和用于检测的特征信息G2,然后将输出的2个用于不同任务的特征信息通过view操作变换为尺寸H∈RC×P,其中P=H′×W′,然后对H1和H2分别使用Softmax激活函数学习2个任务的自关联矩阵M1和M2,其计算公式如式(8)。
(8)
式中:hi表示矩阵H中的第i个元素;mi表示自关联矩阵M中的第i个元素。同样,将H1和H2特征进行融合,然后使用Softmax激活函数以学习不同任务之间的共性。将Softmax的输出通过permute操作变换为尺寸RP×C,将自关联矩阵与互关联矩阵执行矩阵乘法,输出关联融合特征Y∈RC×C,然后将原输入特征F重新排列为RC×N尺寸,其中N=H×W。最后将重新排列后的输入特征与学习到的融合特征执行矩阵乘法重新构造特征图,以增强每个任务的特征表达能力。通过残差连接,将输入特征F与融合特征融合,以防止信息丢失。
2.3 多目标跟踪模型总体结构
本文提出改进YOLOv5的多目标跟踪模型总体结构如图5所示。从图5中可以看出,由于模型需要5次下采样,输入图片尺度需要为32的整数倍,为了适应视频数据集的尺寸,本文输入图片分辨率设置为1 280×384。通过主干特征提取网络,输入的视频帧向前传递,获得5个不同尺度的特征图,本文提取160×48、80×24、40×12等3个尺度的特征图,然后使用路径融合网络(path aggregation network, PAN)[26]完成多尺度融合,提取更加丰富的特征,加强对小尺度目标的检测和跟踪能力。然后在每个PAN层的输出路径上接入AFN模块,促使模型学习与任务相关的特征,提高检测和ReID这2个任务的协作学习能力,缓解由于2个任务之间竞争导致的性能退化。接着将提取到的表观特征和检测框,利用卡尔曼滤波和匈牙利算法完成关联和匹配。具体地说,oi为用表观特征表示的一个轨迹,mi=(x,y,r,h,x′,y′,r′,h′)表示目标运动状态,这里:x、y表示边界框的中心;r表示宽高比;h表示边界框的高;x′、y′、r′、h′表示沿各自方向的速度。对于第一帧,首先通过第一帧的检测结果初始化为新的轨迹。对于后续视频帧,计算所有卡尔曼滤波观测值和轨迹池的成对运动关联矩阵Am和外观关联矩阵Ao。余弦相似度计算外观关联矩阵,马氏距离计算运动关联矩阵,然后利用匈牙利算法求解线性分配问题,其损失函数为
L=αAo+(1-α)Am。
(9)
最后利用卡尔曼滤波算法更新所有匹配轨迹的运动状态,计算如式(10)所示。

图5 本文跟踪算法总体结构Fig. 5 Overall structure of the tracking algorithm in this article
(10)
式中:fit表示当前匹配观察值的embedding;λ=0.9表示一个动量因子。如果连续2帧内有未匹配到的检测结果,则将这个检测结果初始化为新的轨迹。如果某条轨迹连续30帧内没有被分配新的目标,则删除这个轨迹。
3 实验结果与分析
3.1 实验参数设置
(11)
(12)
式中:Tt表示第t帧真实边界框的数量;Et表示第t帧误检样本的数量;St表示第t帧漏检样本的数量;It表示第t帧目标身份切换次数;Nt表示第t帧目标成功匹配的数量;Bt,j表示第j个检测结果与真实边界框的重叠率。
3.2 跟踪算法实验对比
本文选取KITTI-tracking基准数据集,数据集中视频以10 frame/s速度拍摄,并包含较大的帧间运动,是当前最全面的自动驾驶数据集,其主要包括城市、乡村和十字路口等交通场景。本文选取数据集中的Car、Van和Truck 3个类别,然后将这3个类别都划分为Car类。为了增加数据多样性,减少模型过拟合,提高汽车跟踪算法的准确率,本文采用实时数据扩充处理数据样本,例如水平翻转、颜色空间变换、Mosaic数据增强等。本文训练参数设置为:embedding维度为512;batch size为4;最大迭代次数为50;优化策略采用SGD函数;动量因子0.95;初始学习率为0.005,学习率在第30代和40代分别下降10倍;权重衰减设置为0.000 5。本文在JDE算法的基础上添加和修改各个模块的消融实验,如表1所示。
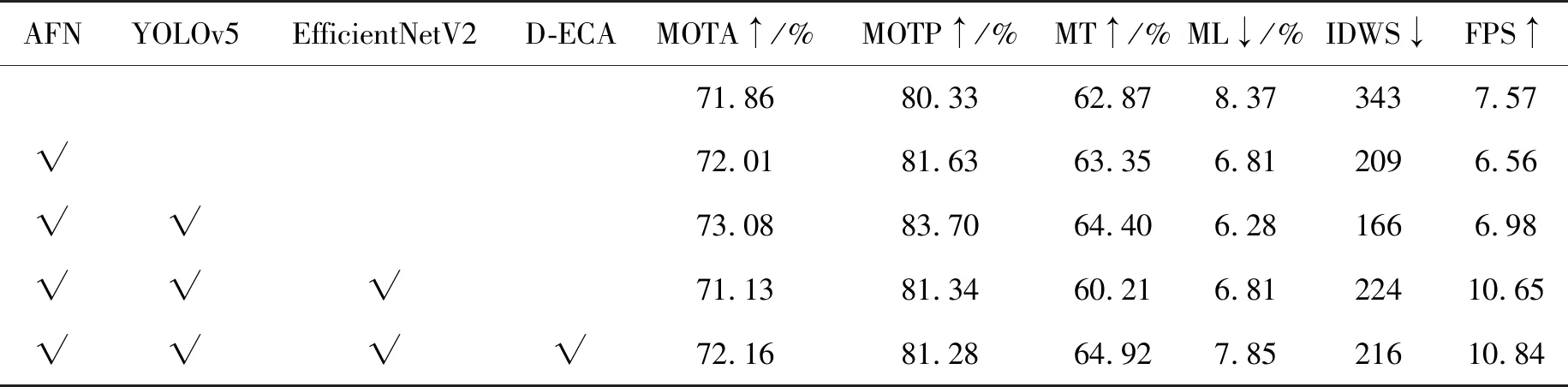
表1 消融实验
从表1中可以看出,在原JDE算法上添加AFN模块后,MOTA、MOTP都有一定的提升,并且显著减少了IDWS。使用YOLOv5替换YOLOv3后,跟踪算法的整体性能均得到了有效提升,表明检测器对跟踪算法的整体性能有很大影响。当再次使用EfficientNetV2替换YOLOv5的特征提取网络,由于特征提取能力不足,导致跟踪算法的整体性能下降,但算法的FPS提高约52.6%,在此基础上引入D-ECA注意力模块,使MOTA提高1.03个百分点,且一定程度上减少IDWS。最终本文算法相比原JDE算法FPS提高约43.2%,MOTA提高0.3个百分点,IDWS减少37%,能有效取得精度与速度折中,具有一定的实际意义。表2展示了本文算法与其他主流算法的性能对比,从表2中可以看出,本文算法大部分评价指标均优于对比算法,具有一定竞争力。
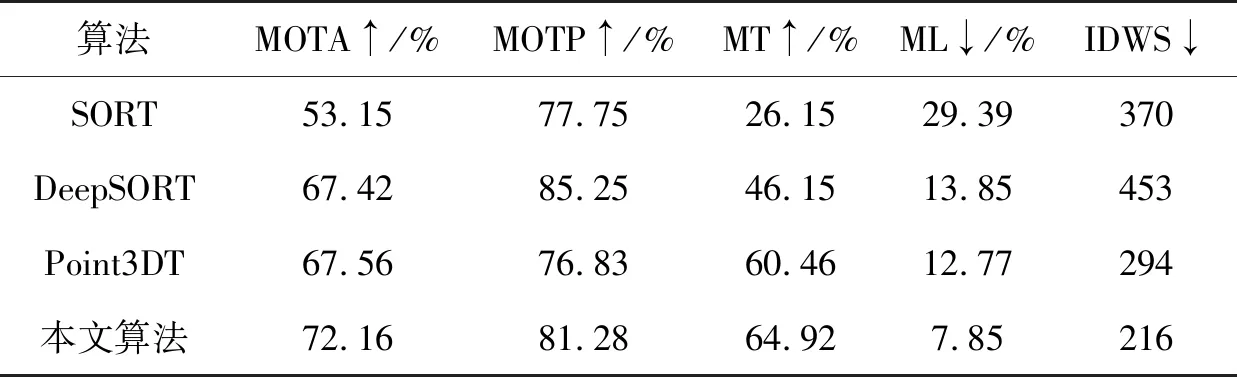
表2 不同方法对比
选取KITTI基准数据集中视频序列对本文算法跟踪结果可视化。图6(a)为视频序列0010可视化结果,这段视频道路交通情况较为复杂,ID为155的车辆需要左转,ID为124、125的车辆遮挡较为严重,且多条轨迹相交。可以看出ID为135的车辆在第31帧期间被遮挡后,在第35帧被重新检测到,且ID没有发生变化,其他车辆跟踪效果良好均没有发生ID切换。图6(b)为视频序列0000的可视化结果,从中可以看出,本文算法对拥挤的停车环境仍然有很好的跟踪效果。

图6 本文算法跟踪结果Fig. 6 Tracking results of the algorithm in this paper
4 结语
本文通过改进JDE跟踪算法,提出了一个有效的车辆跟踪算法。首先在JDE算法的基础上添加AFN模块,减少身份切换次数,其次使用EfficientNetV2替换YOLOv5的特征提取网络,提高模型的实时检测速度,同时减少模型复杂度,使跟踪算法更适合自动驾驶任务,同时为了解决EfficientNetV2特征提取能力不足的问题,通过引入D-ECA模块,提高模型对车辆的检测和跟踪能力。实验结果表明,本文算法有效地对JDE网络进行了压缩,提高了算法实时跟踪速度和检测能力。但本文算法对严重遮挡和密集车辆的跟踪效果仍然有待提高。未来工作将研究在保证不降低实时性的情况下,提高对密集目标和遮挡目标的跟踪能力。
