全景视频数据的网络同步与合成技术研究
2022-03-24丘美玲晏细兰陈惠红
丘美玲,晏细兰,陈惠红
(广州番禺职业技术学院,广东 广州 511483)
1 全景视频浏览参数计算
在一般图像浏览软件中,图像是完整读入到内存,再通过驱动模块显示到显示器,其缩放和局部浏览的操作均由驱动模块后台完成。而对于超大尺寸的图像,其需要的储存空间往往超过一般电脑内存的承受能力,以上显示图像的方式就不再适用。对于超大图像,一般使用块存储格式存储,其格式中包含的不同分辨率下图像的缩略图和实际分辨率下按块划分的多个子图,在高分辨率浏览时按照感兴趣区域对各块分布抽样或读取,再组合成一个区域图像[1-2]。在一般的全景系统中,各个全景子图是单独存储在各运算子机中的,类似于超大图像格式中的按块存储,区别在于全景子图中各子图可能存在一定的重叠[3-5]。利用块存储提取原理,可以计算出各个子图中的需求内容。
对于单一图像的浏览是利用视窗(实际观察区域)和图像做重叠区域计算得到的,计算得到的参数包括视窗在图像中的偏移坐标(XS,YS)、视窗大小(WS,HS)、视窗缩放系数(αx,αy)。如图1 所示,偏移坐标(Xi,Yi)为视窗原点在图像中的坐标,视窗大小为视窗在图像分辨率下的大小,视窗缩放系数为视窗大小与显示窗口大小(WQ,HQ)的比值。那么,我们浏览区域图像Is 和原图I 的相对关系如式(1),其中T 代表对图像的最近邻域抽样或像素平均后双线性内插等操作。

图1 窗口关系
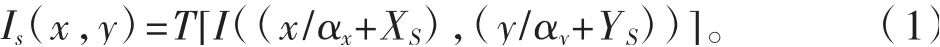
以上原理对于全景图像同样适用,利用该方法能计算出视窗与全景的对应关系,再利用各个子图与全景的坐标变换关系,可以算出各个子图与显示窗口的坐标变换关系。首先计算子图与视窗是否重叠与重叠范围,计算方法采用四点排序方法,方法步骤如下:
Step1:计算两个坐标方向上是否有重叠,假设x 方向上矩形1 的范围为X1=[x11,x12],矩形2 的范围为X2=[x21,x22],那么X 方向上是否重叠如式(2):

如果x 方向和y 方向均重叠,那么两个矩形区域存在重叠区域。
Step2:如果重叠,计算重叠范围,设X=[X1,X2],对X进行由小到大的排序,有x 方向上的重叠长度Lx为次大值和次小值的差:

同理求出Ly。
考虑到图像在融合过程中,为了达到公共区域的平稳过渡,同时考虑了多个重叠子图的信息。但是在特定情况下,视窗与子图的重叠区域只存在子图与其他子图的重叠区域中,即其他子图已经包含了该区域的所有信息。
图2 中,子图A 与子图B 与视窗S 均重叠,但是由于有(B-A)∩S=Ø,即子图B 与视窗S 的公共区域全部都在A 里面,那么子图A 就包含了该公共区域的所有信息,这样我们就不需要对A 和B 做融合后分别把其与视窗重叠区域发送至合成端,只需要把A 的完整重叠信息发送至合成端,对于子图B 中,B 与S 的重叠区域存在与B 唯一相交的区域,即(B-A)∩S≠Ø 时,必须把B 与S重叠的信息发送至合成端,全景图像中局部图像合成次数的多少会影响全景合成中与各个子图的控制复杂度。

图2 窗口与子图的重叠关系
2 网络数据的快速提取
网络数据的提取主要是根据子图与视窗的重叠区域参数来计算提取的,对于一个实时系统而言,点提取采用像素平均后做双线性内插值方法是非常耗费运算资源的,所以可以采用图像效果相对较差,但运算效率相对较高的最近邻抽样方法。采用该方法的另外一个好处是重叠参数一旦确定后,窗口子图与全景子图上的坐标成了一一对应的关系,利用这一特点,可以在重叠参数改变后生成一个坐标对应关系查找表,利用查找表可以把原来的数值运算变成赋值运算。直接计算和查表分别如式(4)和(5),其中K 为最近邻查找,Ic为输出图像,Iw为投影后的图像,Tx和Ty分别为x 和y 方向坐标的对应查找表。

可以看出直接计算,每个坐标点需要做2 次除法、2 次加法、2 次最近邻查找和1 次赋值运算,而查表法只需要做3 次赋值运算。在当今拥有多级缓存和高速内存的硬件环境下,赋值运算比数值运算速度快得多。表1 中,分别利用重叠参数直接计算和查表形式对一个图像做1 000 次数据提取计算,查表法大概要比直接计算快40%。

表1 裁剪速度对比
对于全景子图,除了坐标变换还需要对图像做融合,事先生成了一个融合系数模板Mask,利用模板切割的方法同样可以生成一个和显示子图对应的融合查找表TM,融合查找表返回的是一个浮点型数,而浮点型运算在计算机中相对是比较费时间的。实际观察中发现,RGB 图像点分量的等级为256,所以对于融合系数的精度要求只需要达到1/256。利用这一特点,可以考虑把融合查找表转换成uchar(0~255)型数,生成一个0 到255 各乘以1/256 到1 的系数查找表T256。一帧720 p 图像用直接计算来投影和裁剪需要约35 ms,采用查找表法后,投影和裁剪需要约25 ms,即使系统最终全景帧率是由多个并行环节中最慢的一部分决定的(实际测试该环节为网络传输),但这部分节约的功耗最终会分配到其他环节,从而提升了系统的最终效率。
3 全景视频的网络生成
网络数据在按照提取参数提取出来后,会统一发送到服务器进行组合,由于数据在计算节点就被投影,同时还乘上了融合系数,因此服务器只需要把各个数据按照其偏移坐标叠加到显示模板即可。但是在全景生成前,还要考虑数据的同步问题[6]。
3.1 合成数据的网络同步
由于全景视频是由多个有一定重叠区域图像组成的,对于运动目标而言,在时域上存在一定的空间差异性,当全景拼接采用了不同步的图片,且公共区域内出现了运动目标,即使背景拼接成功,融合拼接后运动目标会出现重影。对于一个监控系统,视频中运动物体才是人们感兴趣的,如果出现数据不同步将会大大影响监控质量。全景视频系统的同步要求包括两个方面,一方面是摄像机数据的采集同步,另外一方面是数据在网络数据计算过程中的同步。摄像机数据采集的不同步,主要是由于摄像机本身硬件差异产生的输出波动和启动时间不同而产生的。假设各个摄像机的帧率相同,那么它们同时间采集一帧会存在一定的物理误差,这个误差会在一帧时间以内,对于非高速运动的目标,该误差影响非常小,并且这个物理误差是不可避免的,所以一般把这个物理不同步忽略掉。
对于网络计算过程的不同步,主要是由于各个计算节点效率的不相同和同一计算节点在时域上计算效率的不稳定,到各个节点数据的输出频率在并行和串行上都不一致,还有就是网络传输效率的不一致。由于各个摄像机计算延时的不相同,有时候服务器同一时间在各个节点接收到的数据会存在1~2 帧甚至更多的差异。
如上所述情况不包括个别计算节点存在超负荷工作状态,指的是各个计算节点在总体输出效率相当,但个别时间点出现了输出水平的波动的情况。解决这一问题主要是采用缓存机制,利用缓存机制在服务器输入前端做帧对齐,能保证视频合成过程中连续稳定,但弊端是引入了一定的人为延时。计算延时是不可避免的,在系统流畅运行的情况下一般为300 ms,而人为延时可以通过缓存大小设定其上限值,这里设定为1 000 ms,在本系统即10 帧。
为了实现时域上帧对齐,必须利用各帧采集时间来标识。忽略掉物理不同步,摄像机数据返回到采集节点时数据为实时数据,该数据的时间标识即为当前计算机的系统时间。所以首先要实现各个计算节点和服务器的时间同步,步骤如下:
Step1:在网络底负荷的情况下,服务器给计算节点发送测试命令,计算节点收到命令后立马返回,服务器接到返回后计算返回时间差。
Step2:重复Step1 多次,计算平均时间差Tp。
Step3:服务器把系统时间发送到计算节点,计算节点计算其与服务器的系统时间误差Δt,如式(6):

Step4:重复Step3 多次,计算平均系统时间误差ΔT,更新当前时间,如式(7):

图像在采集时打上的时间戳不会因为各种处理有所改变,最终发送到服务器的子图像的时间标识仍然是该图像采集时的时间戳。在全景视频开始时,由于各个节点的启动时间不一致,必须对服务器上并行数据做首帧对齐,如图3 所示,步骤如下:

图3 首帧数据
Step1:计算帧差时间,如帧率为10 fps,帧差时间Δt为100 ms。
Step2:找出首帧中超前的1 帧,如图中T11,设定全景起点为t0=T11,生成全景播放序列tn=t0+n·Δt。
Step3:排序各路数据,如果该帧时间戳在tn到tn+1之间,该帧的播放时间被安排到tn,如果该段时间内没有数据或数据没到,即插入空白帧。
因为全景视频是由服务器主动合成的,所以其播放也必须由服务器主动触发,触发时间根据生成的全景视频播放时间序列而定。真正触发时间并不是由该序列的标识时间决定的,该时间仅仅用于缓存对齐和决定全景视频的起点,真正触发全景视频的是帧差时间。首帧对齐决定了全景视频播放序列的排序,但是在播放过程中仍然会出现以下不同步的问题:
(1)丢帧。对于某一时刻,采集端出现了短暂数据采集的丢失,这样的数据在时序上是不可恢复的。对于该情况,通过在丢失时序上插入空白帧,保证全景播放流畅,但是全景内容会出现缺失。
(2)帧滞后。该情况主要由于计算滞后和网络滞后产生的,即数据没有丢失,但是数据到达时间比其他节点慢。对于缓存机制的优点就是能允许数据出现滞后,但由于缓存大小有限,当滞后长度超过缓存长度滞后仍然没有回复,即新来滞后数据时间戳比当前播放序列标识超前,对于这样的数据服务器会直接丢弃,直到滞后恢复为止。采用本文的同步机制能使全景视频流畅播放,其播放帧率与视频采集帧率一致,缺点是全景视频播放在某个节点出现问题时全景数据会出现丢失。
3.2 全景视频数据的合成
全景视频数据的合成,只需要根据视频的偏移坐标,把子图像叠加到一个和显示窗口大小一致的空白图像模板中,如式(8)。图像在发送到服务器前就完成了偏移值的计算、裁剪缩放和融合的操作,所以在其叠加过程中不会出现子图超出模板范围或者个别坐标点超出值域的问题。

需要注意的是,当视窗改变后,合成参数被重新计算,计算节点会更新查找表,服务器接收的数据会改变。在这种情况下,缓存中的数据不再适用,这时必须清空缓存,重新进行数据的帧对齐和生成新的全景视频播放时间序列,在这个过程中全景视频会出现短暂的卡屏,卡屏的时长和各个节点切换速度有关,一般在500 ms 左右。
4 结束语
本文主要阐述了在分散式系统环境下的全景视频多分辨的局部浏览方法,通过本方法,可以把在监控过程中感兴趣的局部区域从运算节点的有效数据中提取出来。提取出来的数据量主要和屏幕大小有关系,这样可以限定各运算节点传输到服务器的数据量,防止造成网络堵塞,并且运算节点保存的是视频源投影前的数据,运算节点只需要把观察区域做投影和融合,减少了计算节点的计算开支,所以使得系统能用更少的计算节点来完成全景视频的生成。
