基于人体姿态估计与聚类的特定运动帧获取方法
2022-03-21蔡敏敏黄继风周小平
蔡敏敏,黄继风,林 晓,周小平
基于人体姿态估计与聚类的特定运动帧获取方法
蔡敏敏,黄继风,林 晓,周小平
(上海师范大学信息与机电工程学院,上海 200234)
运动视频中特定运动帧的获取是运动智能化教学实现的重要环节,为了得到视频中的特定运动帧以便进一步地对视频进行分析,并利用姿态估计和聚类的相关知识,提出了一种对运动视频提取特定运动帧的方法。首先选用HRNet姿态估计模型作为基础,该模型精度高但模型规模过大,为了实际运用的需求,对该模型进行轻量化处理并与DARK数据编码相结合,提出了Small-HRNet网络模型,在基本保持精度不变的情况下参数量减少了82.0%。然后利用Small-HRNet模型从视频中提取人体关节点,将每一视频帧中的人体骨架特征作为聚类的样本点,最终以标准运动帧的骨架特征为聚类中心,对整个视频进行聚类得到视频的特定运动帧,在武术运动数据集上进行实验。该方法对武术动作帧的提取准确率为87.5%,能够有效地提取武术动作帧。
特定运动帧;姿态估计;数据编解码;运动特征;聚类
随着人们生活水平的不断提高,参与体育运动的从业者和爱好者数量不断增加,使得体育运动发展迅猛,与此同时传统运动的学习方式存在的弊端也逐渐显现。对于业余爱好者只能通过教学视频来进行模仿学习,其缺乏互动性,不能正确且详细地了解自己的学习情况。即使是职业的运动者,如何及时并准确地知晓自己每个动作的规范程度,目前只能依赖教练的评价和指导。但这种一对一的方式,导致了教练资源的紧张和稀缺,且对教练的培养需要花费大量时间、人力和物力。这些问题在很大程度上的阻碍了体育运动的进一步发展,以及每个运动者在运动项目上的进步。
当前运动智能化指导主要以运动视频的自动评价来实现,运动视频的自动评价主要有2种方法。一种是直接研究2个视频之间整体的相似程度,如文献[1-3]中将视频数据视为一类特殊的多维时间序列,利用动态时间规整(dynamic time warping,DTW)进行整体时间序列相似度的计算从而得到评价结果,该方法只能得到总体的情况,并不关注动作本身,不仅缺失了对动作的进一步研究,也导致了在实际应用时,其作用范围十分受限。
另一种是将视频中得到的特定运动帧与标准帧之间进行相似度比较,能够得到每个动作的详细分析。该方法在一些简单运动上已经实现,如文献[4]中先获取视频的关键动作帧,做帧对比完成自动评价,但获取运动帧的方法太过依赖于高尔夫球的运动特性。对于复杂运动不能依靠该方法获得想要的运动帧,其难点在获取视频特定运动帧上,因此本文的关注点落在视频的特定运动帧获取上。
在获取视频特定运动帧的同时,也需要考虑视频运动特征的提取。运动视频中人体运动的位置不固定且具有多变的背景和光照条件,这些因素导致了传统特征提取效果不理想。随着人体姿态估计的不断发展,为视频运动特征提供了新思路,利用骨架信息作为人体的动作特征,将一系列的动作特征组合成视频的运动特征来进行表示[5]。
目前人体姿态估计技术分为2种,一种是采用自上而下的方法,先将所有的人体部分从图片中截取出来,再对单人图片进行关节点检测。WEI等[6]提出了一种卷积姿态机,运用卷积神经网络(convolutional neural networks,CNN)得到人体的关键点;CHEN等[7]将人体的关节点按照检测的难度进行划分;SUN等[8]利用HRNet模型将高分辨率子网络作为网络的第一阶段,逐步增加从高分辨率到低分辨率的子网形成多阶段并行网络,达到丰富高分辨率表征的目的。
另一种自下而上的方法是先检测图像中所有人的关节点部位,再利用关节点连接器进行处理,得到每个人的关节点信息。XIA等[9]提出了将人体关节点放置在分割区域的一定位置,并在部位分割和关节点之间建模;CAO等[10]在卷积姿态机的基础上提出了openpose模型,使用部位亲和力场来模拟人体结构,解决了使用中间点判断连接关系所造成的错连情况。
综上,本文提出了一种基于姿态估计与聚类的特定运动帧获取方法,如图1所示。整体流程分为:①利用轻量化网络对视频流进行姿态估计,以获得人体的姿态序列;②利用得到的姿态信息完成动作特征提取,将得到的运动特征与标准帧的运动特征进行聚类,完成视频特定运动帧的获取任务。
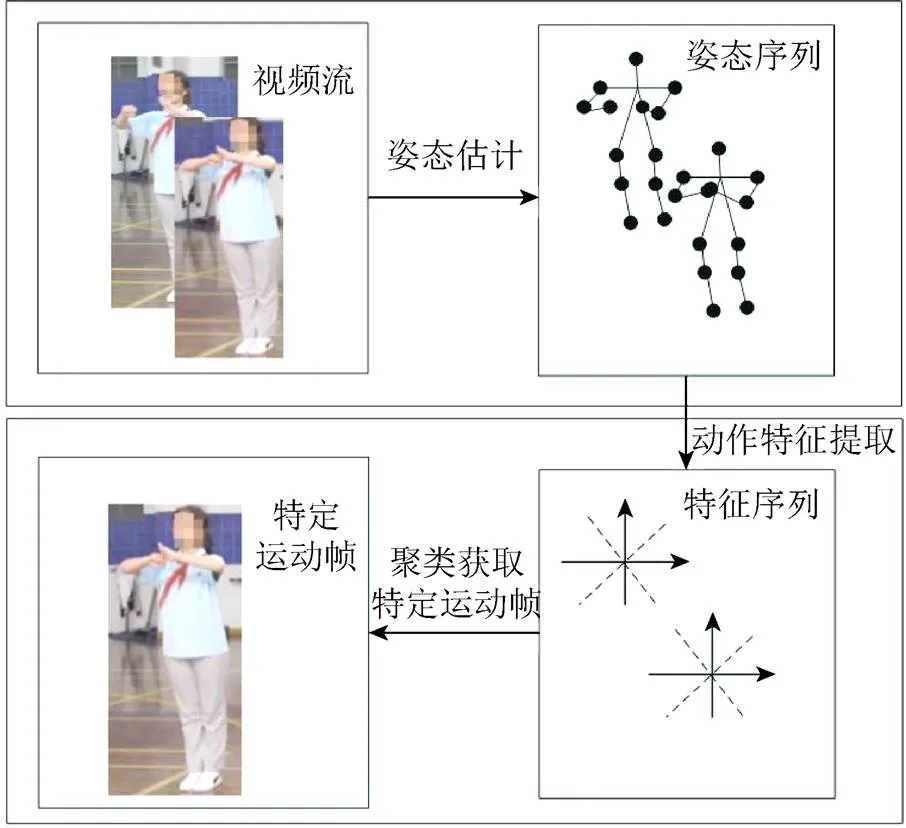
图1 特定运动帧获取方法流程图
1 人体姿态估计
姿态估计旨对无约束图像或视频中的人体关节进行位置检测。对现有模型通常采用热图定位的方式进行研究,对每一个关节点生成一张热图,将关节位置的概率作为热图的响应值,用响应值的大小来表示关节点所在的坐标,整个姿态估计的流程如图2所示[11]。先将任意大分辨率的边界框图像缩小为预先规定的小分辨率图像;然后送入人体姿态估计模型中进行热图预测,为了得到原始图像中的关节位置坐标,需要对预测热图进行相应的分辨率恢复,将其转换回原始坐标空间;最后将预测的位置称为最大激活的位置。
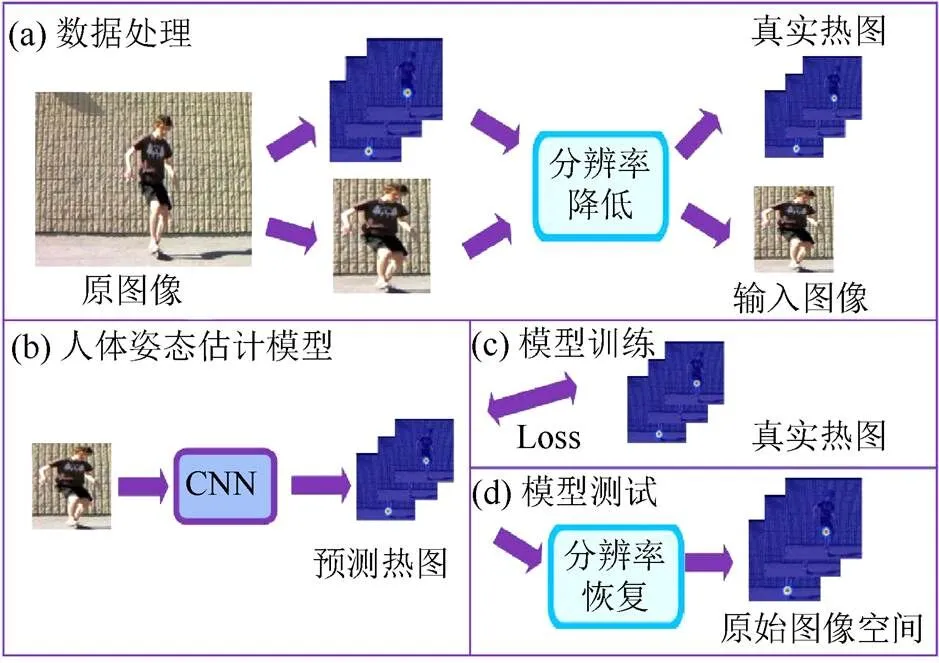
图2 姿态估计完整过程流程图((a)数据处理;(b)人体姿态估计模型;(c)模型训练;(d)模型测试)
本文在人体姿态估计模型HRNet的基础上,对模型进行轻量化处理,同时使用DARK数据编解码技术[11],完成Small-HRNet模型的构建,在保持检测精度基本不变的情况下,模型参数量减少了82%。
1.1 Small-HRNet模型结构
Small-HRNet网络是以HRNet模型为基础完成的结构设计,如图3所示。其改进思路是在保持精度的基础上最大可能地对原有模型进行简化。简化模型包括:①利用可分离卷积的思想设计了Smallblock模块,将3×3的卷积核替换为3×3的组卷积和1×1卷积的组合运算;②减少了原有模型并行子网数,以减少参数量。
Small-HRNet网络结构主要包含3个阶段,stage1,stage2和stage3,由并行连接的子网构成,每一个子网由上而下,每一级的分辨率均为上一级的1/2,同时通道数增加2倍。stage1是由分辨率最高的一条Bottleneck模块构成的子网组成,如图3(c)所示;stage2由2条并行的Basicblock模块子网组成,如图3(d)所示;stage3则是由3条Smallblock模块的子网组成,如图3(e)所示。图3(b)是不同分辨率特征之间的融合方式示意图,上述3个阶段相互连接融合使得网络的整体呈现出3条子网并行的结构,正是这种结构使整个网络在保持高分辨率的同时增强了多尺度的信息融合。
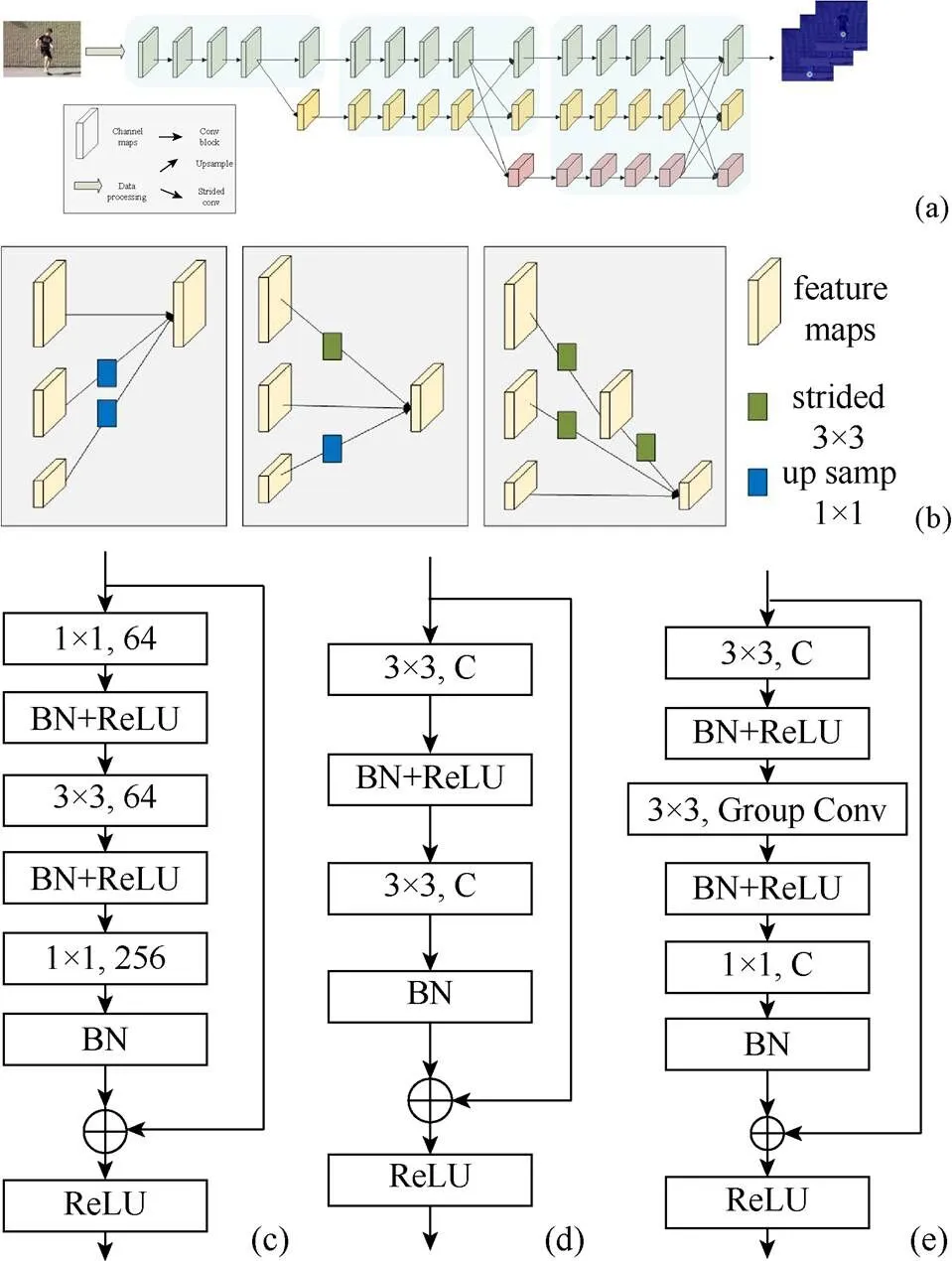
图3 Small-HRNet模型示意图((a)网络结构;(b)不同分辨率特征融合方式;(c) Bottleneck模块;(d) Basicblock模块;(e) Smallblock模块)
1.2 关节点的编码和解码
通常在训练姿态估计网络时,会从训练代价的角度出发,将图像做降采样处理以缩小图像分辨率。同时为了使网络能够利用热图为标签进行训练,需将基于原图的坐标转换成降采样后的坐标,再通过高斯模糊变成热图形式,本文将该过程称为坐标编码。反之为了得到关节点在原图中的坐标,在网络进行热图预测后,需先进行对应的分辨率恢复,再转换成坐标表示,这种从热图到坐标的转换过程称为坐标解码。
在人体姿态估计的研究中,大多关注网络的构建和改进,很少研究关节点的编码和解码过程。然而在分辨率变化时可能引入量化误差,会对整个的预测结果产生比想象中更大的影响,所以本文在关节点的编码和解码的研究中选用了DARK的编解码方法[11]。
1.2.1 原有的编码和解码方法
在对原有的坐标进行编码之前,需要将原图降采样到模型输入的大小,所以在生成热图之前,需要依据分辨率的变换对坐标进行相应的变换。
降采样后的坐标为
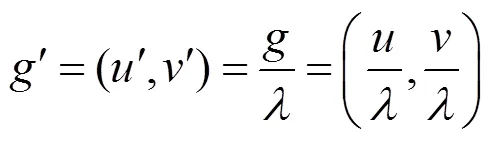
对ʹ进行量化处理后,得
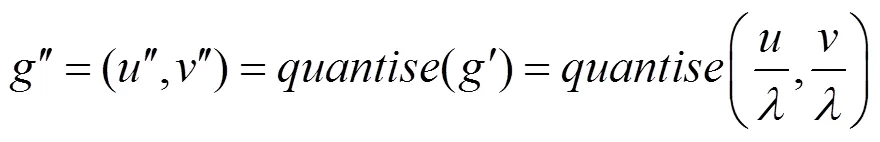
其中,(,)为关节点在原图中的真实坐标;为降采样率;函数为量化函数,常用的选项可以为向下、向上取整函数和四舍五入函数。
以量化坐标″为中心的热图,即
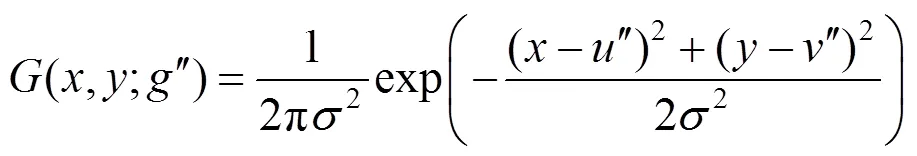
其中,(,)为热图中的像素位置;为固定的空间方差。
原有的坐标解码方法是由文献[12]依据其当时研究的模型性能按照经验设计的,由热图转换而来的坐标位置为
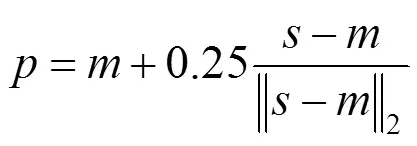
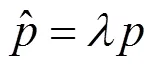
1.2.2 DARK的编码和解码方法
DARK的坐标编码和解码方法研究了预测热图的分布结构,和原有的几乎没有设计依据的编解码方法有很大的不同。
DARK的坐标编码方法:用非量化之前的ʹ代表量化中心,将式(3)中的″用ʹ替代。
DARK的坐标解码方法:为了获得亚像素级的准确坐标,假设预测热图和真实热图一样服从二维高斯分布。因此,可将预测热图表示为
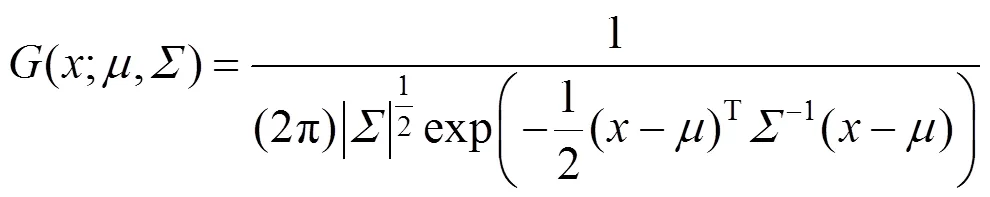
对式(6)进行对数变换可得
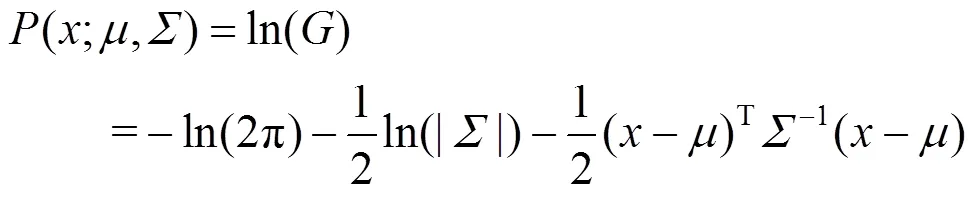
本文的目标只为了估算,高斯分布的一个极值点,该点的一阶导数满足
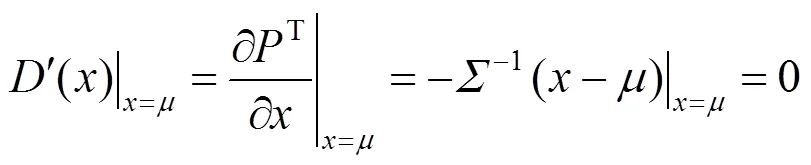
为了探索该条件,采用了泰勒定理,选用二次项泰勒级数在预测热图的最大激活处进行近似化
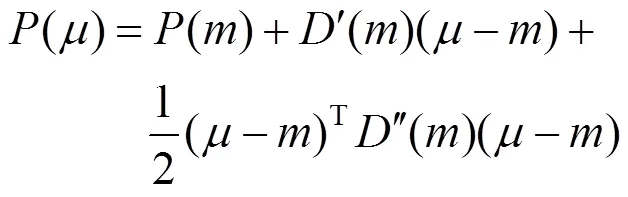
其中,″()为在处的二阶导数,可定义为
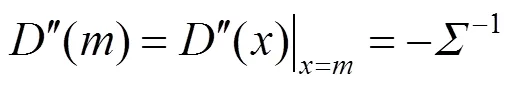
由式(9)~(11)可得

2 特定运动帧获取
运动视频中特定运动帧的获取是一项具有挑战的任务,因视频数据的维度高且复杂。视频具有时间特性,因可将运动视频看作时序数据,但每个时序点并不是一维数据而是图像,这种复杂的数据形式给处理方法的选择造成了很大的困难。
本文选用聚类的思想对视频数据进行处理,以解决上述问题。先基于人体骨架信息进行特征提取,在固定了聚类中心和簇数之后让数据根据彼此的相似性进行自动分类,聚类完成后,选取与聚类中心最相似的运动帧作为该特定运动帧。在武术运动数据集上进行实验准确率达87.5%。
2.1 运动特征提取
将运动视频的每一帧图像送入Small-HRNet网络中进行人体姿态估计,得到人体关节点的坐标信息,利用坐标信息对运动特征进行提取。每3个相邻的人体关节点会形成一个夹角,利用关节点的坐标通过余弦定理可计算夹角,将一系列的夹角角度作为运动特征。但是仅仅利用角度大小作为特征信息会有信息缺失。如图4所示,左图中左肩、左肘和左腕3个相邻关节点(⑤-⑦-⑨)形成的夹角角度与右图中相同部位形成的大小相等,但是可以清楚地看出,二者显示的并不是同一动作,因此仅用夹角大小作为特征信息并不合适。
为了解决仅用角度大小存在的信息缺失问题,在运动特征中增加了方向信息,实际增加了2个向量之间的相对位置信息,不再直接利用余弦定理完成角度计算,而是定义了关节点的旋转角,将一系列的旋转角作为运动特征。以左肩、左肘和左腕为例,从左肘到左肩的矢量为,从左肘到左腕的矢量为,且和均为单位矢量,矢量逆时针旋转到矢量的角度定义为的旋转角。
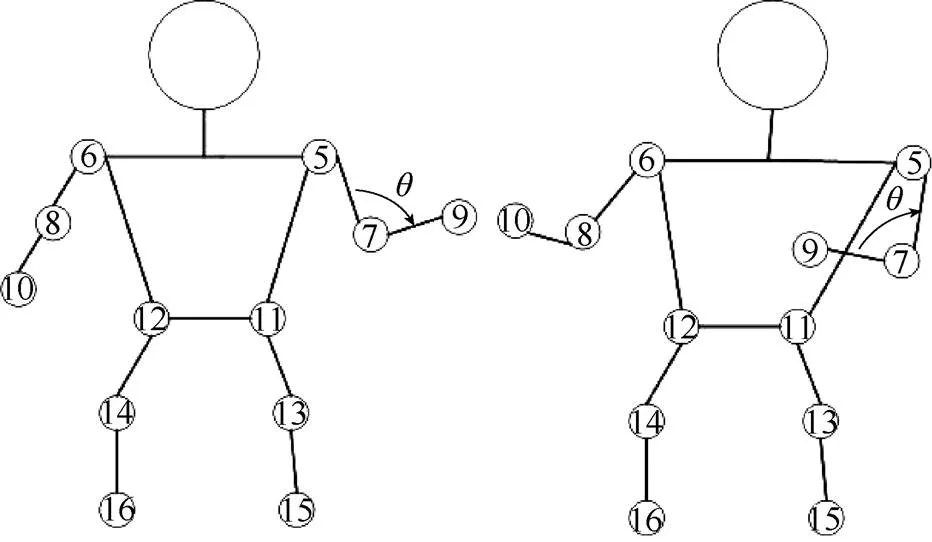
图4 不同动作具有相同角度示意图
根据运动时人体关节点的重要程度,选取了11个关节点的旋转角作为运动特征,见表1。
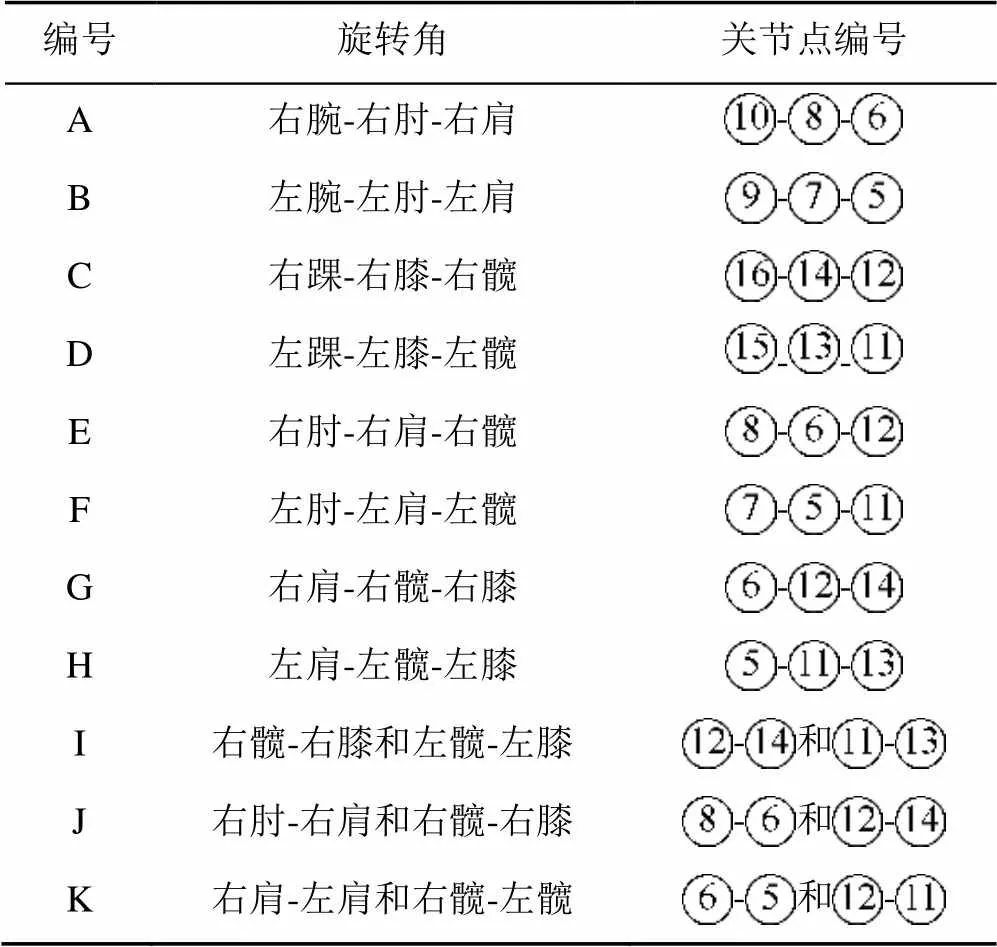
表1 运动特征所含旋转角信息
2.2 运动特征聚类
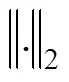
本文将每一帧的运动特征作为一个样本点,对完整视频形成的所有样本点进行固定聚类中心和簇数的聚类操作。固定的聚类中心选用的是一系列标准动作帧的运动特征,簇数与需要获取的特定运动帧数量相等,样本点和聚类中心的距离可表示为对应关节点旋转角之间的欧式距离之和加一个偏移量,即
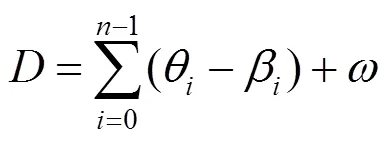
其中,为运动特征中关节点旋转角的个数;为当前样本点的关节点旋转角;为和当前样本点第个旋转角相对应的标准帧的关节点旋转角;为偏移量。研究中发现,对于2个不同的动作会出现镜像的情况,即所有的旋转角都一致,但一个动作人脸是正面而另一个是反面,所以即便使用旋转角还是会造成错误。为了解决该问题,本文采用了一个简单而有效的方法,判断左脚和右脚的相对位置。若右脚的水平坐标值比左脚的值小,则说明人脸是正面,反之是背面。所以用偏移量来表示样本点是否与该聚类中心的动作同方向,若相同,为零,否则为无穷大。
将带有运动特征的所有视频帧进行聚类,完成后将距每个聚类中心最近的视频帧作为所求的特定运动帧,并完成其获取任务。
从实验样本中随机抽取5个视频,按式(13)计算其8个正确运动帧与每个标准帧的距离,并得到平均值绘制热力图,如图5所示。从图中可以看出,正确帧与其相对应的标准帧的距离是最小的,表明旋转角和运动帧之间有一定的相关性,可以利用旋转角之间的距离计算完成运动特征的聚类。
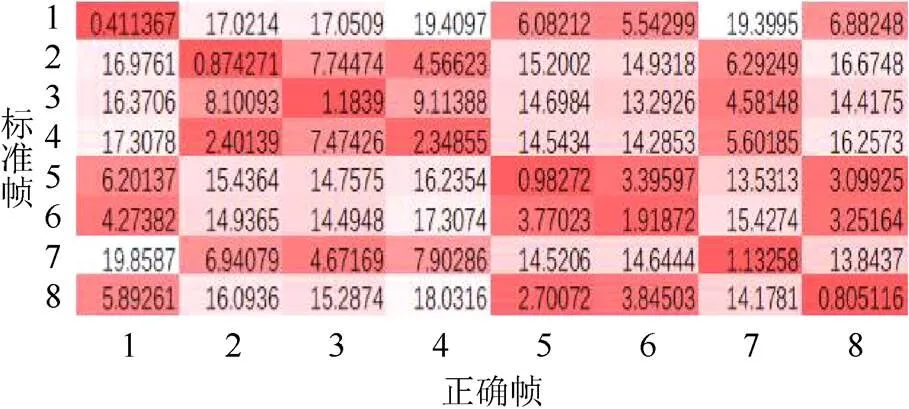
图5 标准帧与正确帧之间距离均值的热力图
3 实验结果与分析
3.1 实验平台
本文实验所用处理器为英特尔i7-9750H,内存为16 G,显卡为8 G的RTX2070,系统使用的是Ubuntu20.04版本。实验基于pytorch深度学习框架对人体姿态估计模型进行搭建,并使用GPU加速训练和识别过程。
3.2 人体姿态估计实验结果与分析
3.2.1 数据集
本文选择在人体姿态估计最常用的MPII和COCO2个基准数据集上进行实验。MPII数据集[13]总共包括25 000张带有标注信息的图片,其中单人的姿态标注有40 000多个,人体被标注为16个骨骼关节点。COCO数据集[14]总共包括200 000张带有标注信息的图片,其中单人标注有250 000个,人体被标注为17个关节点,并对每个关节点的坐标和可见性均进行了记录。
实验1.选用MPII数据集中的训练集样本22 246个作为训练样本,选用其验证集作为测试样本,验证集中包含2 958个样本MPII的骨骼关节点信息,如图6所示。

图6 MPII数据集的骨骼点信息图
实验2.选用COCO数据集中的训练集149 813个样本作为训练样本,选用其验证集的6 352个样本作为测试样本。COCO的骨骼关节点信息如图7所示。
3.2.2 评价指标
本文在实验1即MPII数据集中使用PCKh评价指标作为模型评估的度量。PCK定义为模型检测出的关节点与正确标注的关节点之间归一化的距离,小于事先设定阈值的一定比例,可称为PCK@评价方法[15]。在MPII数据集中归一化距离以头部长度作为归一化参考,即为PCKh。常用的PCKh评价有PCKh@0.2和PCKh@0.5。实验选用PCKh@0.5作为模型的准确率评价标准。即若模型检测的关节点与正确标注关节点之间的像素坐标距离小于人体头部长度比例的0.5时,表示该关节点检测正确[15]。其准确率为

图7 COCO数据集的骨骼点信息图
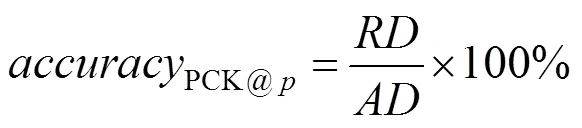
其中,为检测正确的个数;为总的检测个数。
本文在实验2即COCO数据集中使用评价指标[14]作为模型评估的度量,即
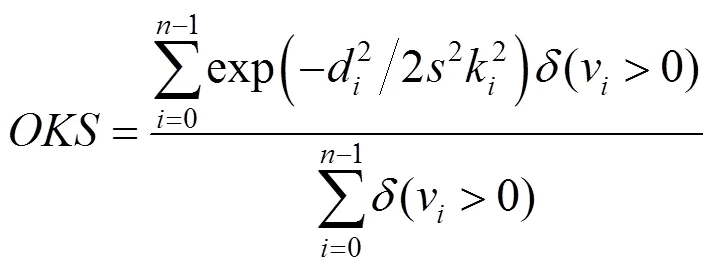
其中,d为预测的关节点与正确标注的关节点之间的欧式距离;为关节点的个数;v为该关节点是否可见,大于零为可见;为目标尺度;k为关节点的控制衰减常数。50表示为0.50时的检测准确度,本文在实验中选择平均准确率来进行模型评估,为分别等于0.50,0.55,0.60,···,0.90,0.95时准确度的均值。
3.2.3 训练策略
实验在模型训练时采用部分HRNet的预训练权重对网络进行初始化,因为对模型的网络结构和基础块进行了修改,所以并不能使用全部的预训练权重,当初始化模型检测效果不理想时,损失函数值会变大,且极易造成梯度分散并影响准确率,因此需选用部分预训练权重进行初始化。本实验模型的训练参数见表2,在训练中小于170时,学习率定为初始学习率0.100,之后的迭代则将学习率设置为最终的0.001。
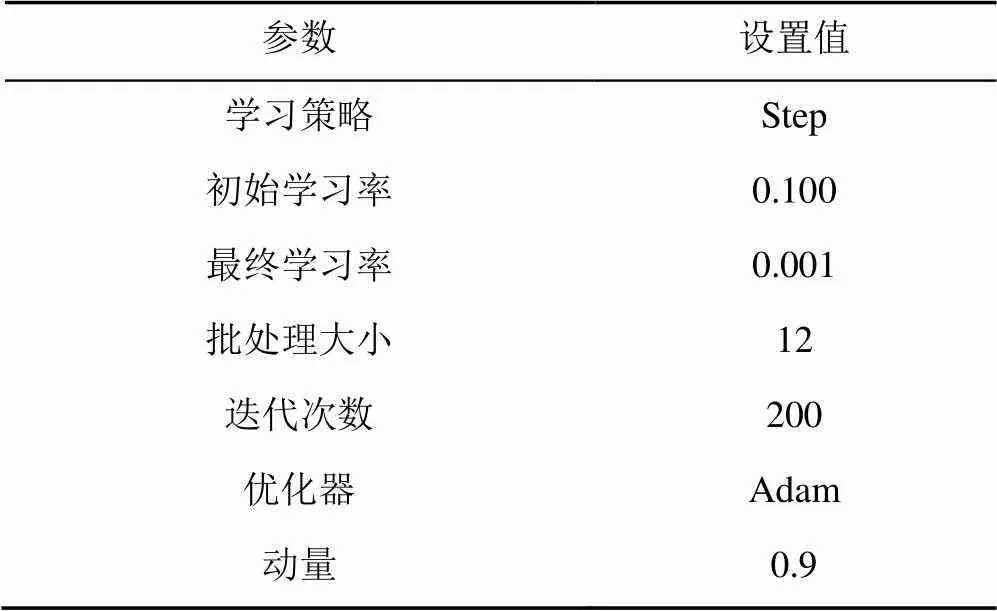
表2 模型训练参数
3.2.4 结果与分析
本文在对HRNet网络进行改进和轻量化后,在MPII数据集和COCO验证集上分别进行了对比实验。实验1的结果见表3,结果表明本文方法相比HRNet-32和HRNet-32+DARK方法,在保持精确度不变时参数量和GFLOPs大幅度下降,参数量减少了82.1%,GFLOPs降低了53.2%,相较于HRNet-32方法精确度仅下降了0.1%。
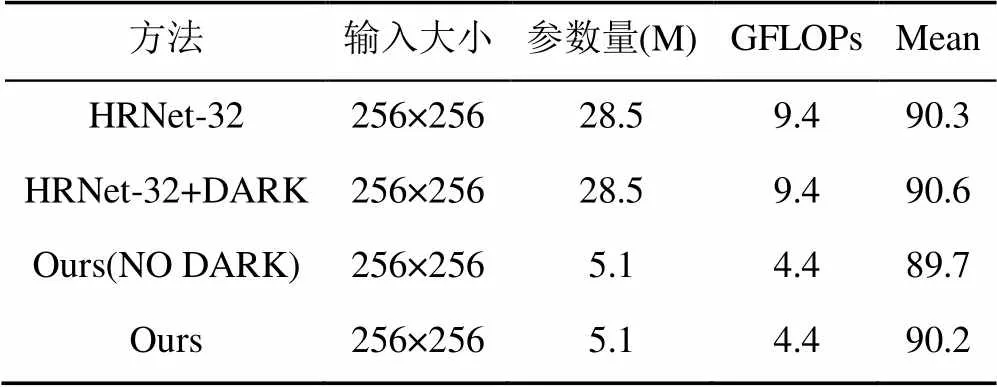
表3 不同方法在MPII验证集上的对比
实验2的结果见表4,结果表明本文方法相比HRNet-32和HRNet-32+DARK方法参数量减少了82.1%,GFLOPs降低了53.7%,相较于HRNet-32方法精确度下降了1.0%。
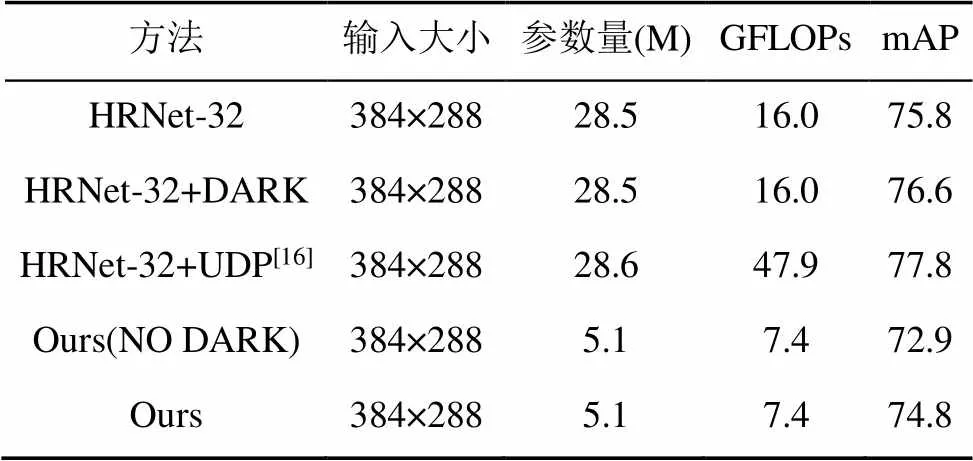
表4 不同方法在COCO验证集上的对比
通过实验结果可以看出,本文使用的Small- HRNet模型同时采用DARK数据编解码方法,可以大幅度地缩小模型规模并保持精度基本不变。
图8为本文实验的测试结果可视化示意图。图中本文方法具有一定的鲁棒性,即使在人体有遮挡的情况下,也能够准确检测出人体的关节点,并得到坐标信息进行后续研究。

图8 可视化结果示意图((a) MPII中无遮挡结果;(b) MPII中部分遮挡结果;(c) COCO中无遮挡结果;(d) COCO中部分遮挡结果)
3.3 关键动作帧获取实验结果与分析
3.3.1 数据集
本文实验选用了2个中学关于武术运动的20个视频作为实验测试集,选取理由:①武术动作复杂程度高且动作幅度大,相比一般的运动研究难度更大,可以突出本文实验方法在复杂运动中的有效性;②选用专业化程度不高的中学生的武术视频,可以验证在出错率较高的实际场景下本文方法的鲁棒性。本文实验选取了8个武术典型动作作为实验动作,分别为并步抱拳、冲拳弹踢、马步冲拳、弓步冲拳、正马步冲拳、弓步双冲拳、马步架打和回身弓步冲拳,如图9所示。
图10为利用Small-HRNet模型对武术数据集进行姿态估计的可视化结果图,可以看出本文方法在武术数据集上也有良好的效果。因为运动特征中利用了旋转角,为了方便分析,在数据集的可视化中添加了躯干可视化结果。

图9 武术动作示意图((a)并步抱拳;(b)冲拳弹踢;(c)马步抱拳;(d)弓步冲拳;(e)正马步冲拳;(f)弓步双冲拳;(g)马步架打;(h)回身弓步冲拳)

图10 武术数据集可视化结果图
3.3.2 评价指标
本文实验选用准确率作为评价指标,用预测正确的帧数占整个实验帧数的比例进行评价,但预测正确的定义与通常意义的并不相同,实验中的每帧按每秒30帧进行获取。实验前将得到每一个武术动作帧的最优帧,实验后得到预测帧,若实验的预测帧出现在最优帧的前后3帧之内,将认定该动作帧预测正确,反之认为预测错误。
3.3.3 结果与分析
本实验采用COCO数据集对人体关节点的标注形式完成运动特征的提取,并利用本文提出的欧式距离加偏移量的方法作为距离度量进行聚类操作,实验结果见表5。本文提出的方法在武术数据集上的准确率达87.5%,比单纯利用欧式距离做度量的方法提高了12.5%。实验表明本文方法能够较好地提取8种典型武术动作帧。

表5 不同距离度量在武术数据集上的对比(%)
3.4 局限性分析
图11(a)为弓步冲拳的教练标准帧,图11(b)为某一实验样本中该动作的预测帧,该学生的左手并未伸直,所以不在所要寻找的正确帧范围内。由于人体相对于摄像机的位置不同,视角产生差异从而导致了错误。可以看出本文方法对视角十分敏感。

图11 错误样例示意图((a)教练标准帧;(b)对应预测帧)
对视角敏感的根本原因是本文通过二维姿态估计为基础提出特定运动帧的获取方法,而二维关键点信息天然具有姿态的不确定性。在复杂情况下难以反映完整的三维姿态信息,使得本文的方法在更加复杂的数据集中扩展有一定困难。
4 结束语
本文提出了一种轻量化人体姿态估计模型和一种视频特定动作帧的获取方法。通过对网络结构和基础块的改进,完成对现有姿态估计模型的轻量化操作,并通过该轻量化网络对视频进行人体姿态估计,利用骨骼信息从中提取运动特征同时结合聚类的知识,完成对视频特定运动帧的获取。实验结果表明,本文的轻量化网络在基本保持精度不变的情况下大幅度减少了模型参数。本文的视频特定动作帧获取方法可以有效地提取出8种典型武术动作帧,均具有很好的实用性。现阶段只选取了部分的武术动作进行研究,且没有重复动作,后续将对拥有重复动作和更多种类的视频进行特定动作帧的获取研究。
[1] CHAARAOUI A A, CLIMENT-PÉREZ P, FLÓREZ- REVUELTA F. An efficient approach for multi-view human action recognition based on bag-of-key-poses[C]//The 3rd International Conference on Human Behavior Understanding. Heidelberg: Springer, 2012: 29-40.
[2] CHAARAOUI A A, PADILLA-L PEZ J R, CLIMENT- PÉREZ P, et al. Evolutionary joint selection to improve human action recognition with RGB-D devices[J]. Expert Systems With Applications, 2014, 41: 786-794.
[3] CHANDRASEKARAN B, CHITRAKALA S. Robust and adaptive approach for human action recognition based on weighted enhanced dynamic time warping[C]//The 3rd International Symposium on Women in Computing and Informatics. New York: ACM Press, 2015: 412-418.
[4] 季月鹏. 基于视频人体姿态估计的高尔夫挥杆动作比对分析研究[D]. 南京: 南京邮电大学, 2019.
JI Y P. The research on golf swing action comparison based on video human body pose estimation[D]. Nanjing: Nanjing University of Posts and Telecommunications, 2019 (in Chinese).
[5] 郭天晓, 胡庆锐, 李建伟, 等. 基于人体骨架特征编码的健身动作识别方法[J]. 计算机应用, 2021, 41(5): 1458-1464.
GUO T X, HU Q R, LI J W, et al. Fitness action recognition method based on human skeleton feature encoding[J]. Journal of Computer Applications, 2021, 41(5): 1458-1464 (in Chinese).
[6] WEI S E, RAMAKRISHNA V, KANADE T, et al. Convolutional pose machines[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2016: 4724-4732.
[7] CHEN Y L, WANG Z C, PENG Y X, et al. Cascaded pyramid network for multi-person pose estimation[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 7103-7112.
[8] SUN K, XIAO B, LIU D, et al. Deep high-resolution representation learning for human pose estimation[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2019: 5686-5696.
[9] XIA F T, WANG P, CHEN X J, et al. Joint multi-person pose estimation and semantic part segmentation[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2017: 6080-6089.
[10] CAO Z, SIMON T, WEI S E, et al. Realtime multi-person 2D pose estimation using part affinity fields[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2017: 1302-1310.
[11] ZHANG F, ZHU X T, DAI H B, et al. Distribution-aware coordinate representation for human pose estimation[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2020: 7091-7100.
[12] NEWELL A, YANG K Y, DAI J. Stacked hourglass networks for human pose estimation[C]//2016 European Conference on Computer Vision. Cham: Springer Intemational Publising, 2016: 483-499.
[13] ANDRIUKA M,PISHCHULIN L,GEHLERM A P, et al. Human pose estimation: new benchmark and state of the art analysis[C]//2014 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2014: 3686-3693.
[14] LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context[C]//2014 European Conference on Computer Vision. Cham: Springer Intemational Publising, 2014: 740-755.
[15] 张世豪. 基于深度学习的人体骨骼关键点检测方法研究[D]. 桂林: 桂林电子科技大学, 2019.
ZHANG S H. Research on key point detection method of human skeleton based on deep learning[D]. Guilin: Guilin University of Electronic Technology 2019 (in Chinese).
[16] HUANG J J, ZHU Z, GUO F, et al. The devil is in the details: delving into unbiased data processing for human pose estimation[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2020: 5699-5708.
Acquisition method of specific motion frame based on human attitude estimation and clustering
CAI Min-min, HUANG Ji-feng, LIN Xiao, ZHOU Xiao-ping
(School of Information and Electromechanical Engineering, Shanghai Normal University, Shanghai 200234, China)
The acquisition of specific motion frames in motion video was an important part of intelligent teaching. In order to obtain specific motion frames in video for further analysis, a method of extracting specific motion frames from motion video was proposed using the knowledge of pose estimation and clustering. Firstly, the HRNet attitude estimation model was adopted as the basis, which was of high precision but large scale. To meet the needs of practical application, this paper proposed a Small-HRNet network model by combining it with the data encoding of DARK. The parameters were reduced by 82.0% while the precision was kept unchanged. Then, the Small-HRNet model was employed to extract human joint points from the video. The human skeleton feature in each video frame served as the sample point of clustering, and finally the whole video was clustered by the skeleton feature of the standard motion frame as the clustering center to produce the specific motion frame of the video. The experiment was carried out on the martial arts data set, and the accuracy rate of the martial arts action frame extraction was 87.5%, which can effectively extract the martial arts action frame.
specific motion frame; attitude estimation; data encoding and decoding; movement characteristics; clustering
23 June,2021;
TP 391
10.11996/JG.j.2095-302X.2022010044
A
2095-302X(2022)01-0044-09
2021-06-23;
2021-08-15
15 August,2021
国家自然科学基金项目(61775139);上海市地方能力建设项目(19070502900)
National Natural Science Foundation of China (61775139);Shanghai Local Capacity Building Project (19070502900)
蔡敏敏(1997–),女,硕士研究生。主要研究方向为机器学习与计算机视觉。E-mail:caiminminw@163.com
CAI Min-min (1997–), master student. Her main research interests cover machine learning and computer vision. E-mail:caiminminw@163.com
黄继风(1963–),男,教授,博士。主要研究方向为机器学习与机器视觉等。E-mail:jfhuang@shnu.edu.cn
HUANG Ji-feng (1963–), professor, Ph.D. His main research interests cover machine learning, machine vision, etc. E-mail:jfhuang@shnu.edu.cn
