三维视觉下的目标识别与位姿估计方法
2022-03-17贾秀海叶明露王启宇盛晓超
王 青,贾秀海,叶明露,王启宇,盛晓超
(西安工程大学 机电工程学院,陕西 西安 710048)
0 引 言
基于深度相机采集的三维点云数据不仅包括物体表面的几何特征、颜色信息,而且还包括深度信息[1],即采集的信息更接近现实场景,因此基于三维点云数据的物体识别与位姿估计技术是目前机器视觉领域研究的热点之一,被广泛用于机器人环境感知和导航、无人汽车自动驾驶、自动装配及虚拟现实等领域[2]。文献[3]使用快速点特征直方图计算局部特征,相比点特征直方图[4],极大地提高了点云的计算速度,并提出了一种基于样本一致性的初始对齐算法,解决了点云配准效率低的问题,但对噪声点云数据的鲁棒性较差。文献[5]利用视点特征直方图(viewpoint feature histogrcm,VFH)获取待配准点云特征,采用KNN算法和ICP算法估计物体位姿,具有较强的稳健性。文献[6]利用CVFH识别物体,可有效识别遮挡的点云以及包含噪声的点云。文献[7]通过使用点对特征对在散乱堆放场景中的物体进行点云匹配和位姿估计,采用投票策略进行模板匹配,在仿真环境下抓取准确率达到了97.1%,但该算法没有涉及对复杂场景中多物体的识别。文献[8]为了识别复杂场景中的多个目标,提出一种基于改进法矢的C-SHOT特征识别目标,使用LM-ICP实现目标点云的位姿估计,对颜色鲜明、区别性强的物体识别率达到了99%,但对表面光滑、颜色相近的物体识别率较低。
针对在复杂场景下点云目标被遮挡和含有噪声时目标识别率低的问题,本文结合CVFH与SHOT描述子[9],提出一种改进的CV-SHOT识别算法,并使用霍夫投票算法优化ICP算法[10-11],对复杂场景中目标进行识别和位姿估计。
1 点云数据处理
由于环境光线、相机本身误差等原因,深度相机采集的点云数据会包含数据噪点[12],并且除了物体点云信息外,还存在多余的背景信息、载物台平面信息等。为了得到有效的分割聚类以及提高后续的识别效率,需要去除多余点云。
1.1 数据预处理
针对深度相机采集的原始点云数据,为了快速找到感兴趣区域,采用点云直通滤波算法[13]去除冗余的背景信息,可以极大地减少点云数量,完整地保留目标特征的信息。待识别的目标点云与相机的距离保持不变,故可以截取空间坐标轴方向一定范围内的点云数据作为感兴趣区域,然后进行目标点云的识别。空间坐标轴各个方向上的距离阈值设置:
(1)
式中:(Xmin,Xmax) 、(Ymin,Ymax)、(Zmin,Zmax)阈值可通过计算获得。点云数据直通滤波效果如图1所示。

(a)原始数据点云 (b)直通滤波后的效果图 1 直通滤波Fig.1 Through filtering
图1(a)为原始数据点云,其冗余的点云信息主要是背景信息。取Z方向(-1,0)范围内的点云数据,直通滤波后的效果如图1(b)所示。滤波前后感兴趣区域的点云数量、形状、位置未发生变化,原始点云的点数量为223 778,直通滤波后的点数量为72 103,极大地减少了点的数量,节约了计算资源。在使用直通滤波的过程中,可以根据实际情况合理设置方向阈值,在减少点云数量和保留感兴趣区域之间达到平衡。
深度相机获取的点云数据比较稠密,为了提高后续点云处理的速度,在保留物体特征信息的基础上,采用体素滤波算法[14]对点云进行下采样。
体素滤波算法:根据点云数据的特点建立三维体素栅格,组成多个微小立方体,采用小立方体的重心替代该立方体内的点,对点云数据进行稀疏化。该方法简单高效,不需要建立复杂的拓扑结构,满足三维点云曲面快速重构的需求。每个小立方体重心(xc,yc,zc)的计算公式为
(2)
式中:n为小立方体中的点云数量;(xi,yi,zi)为小立方体中的第i个点。体素内的点用小立方体重心表示,以完成点云数据的下采样。体素滤波如图2所示。

图 2 体素滤波Fig.2 Voxel filtering
从图2可以看出,体素滤波中小立方体边长为5 mm,滤波前后点云的位置、形状保持不变,滤波前的数量为5 713,滤波后的数量为1 168,点云数量减少极大,提高了后续点云局部特征的计算速度。小立方体边长可根据场景情况适当调节,在减少点云数量与保持点云轮廓信息之间达到平衡。
1.2 载物台平面去除
采用随机抽样一致(random sample consensus,RANSAC)算法[15]去除载物台平面。RANSAC算法通过迭代方式在含有外部点的点云数据中估计并优化数学模型,将数学模型设置为平面模型,将载物台平面与场景物体分离。根据实验室场景的复杂度,设置最大迭代次数为50,距离阈值为0.01,对场景进行多次平面滤除,去除载物台平面效果如图3所示。

图 3 去除载物台平面Fig.3 The stage plane removal
图3中,相比左图,右图载物台主平面几乎被完全滤除,只有零散的几处小平面点云以及离群点未被滤除,平面上的物体点云形状、轮廓保持不变。
1.3 离群点滤除
为了去除因深度相机采集产生的稀疏离群点、点云边缘噪声以及分割载物台平面留下的离群点,并同时降低相互遮挡物体的连接性,采用统计离群点算法[16]进行点云数据处理,邻域平均距离的概率密度函数,即
(3)
式中:li为任意点的邻域平均距离。该算法对每个点的k近邻点进行分析,k设置为50。如果当前点距离k近邻点的平均距离超过整个点云数据点之间平均距离的一个标准差以上,则视该点为离群点,离群点滤波效果如图4所示。

图 4 统计离群点滤波Fig.4 Statistical outlier filtering
图4中,经过统计离群点滤波后,相比左图,右图中的离群点被滤除,相互接触的物体也被有效区别,得到了比较规则、光滑的多个物体点云聚类,可使后续的点云得到有效分割。
1.4 点云场景分割
点云分割通常依据点云的法线、几何特征、颜色等信息将点云分割为互不相交的多个子集。当场景物体经过点云预处理后,点云数据量急剧降低,各物体的连接性明显降低,此时采用欧式聚类[17]分割算法,相比于区域生长分割[18]、超体聚类分割[19-20]、最小分割[21]算法,可有效快速分割场景,分割实时性满足目标识别的需要。
在点云维度空间建立数据索引树形结构(KDTree),利用KDTree的最近邻查询算法加速欧式聚类的过程。欧式聚类是基于欧式距离判断是否进行聚类的算法,点云三维空间中,点(x1,y1,z1)与点(x2,y2,z2)的欧氏距离,即

(4)
首先在搜索空间中选取一点p,然后利用KDTree在搜索范围内找到k个离p点最近的点,当搜索点的欧式距离小于设定阈值时,则被聚类到集合A中。当集合A中的点数不再增加,则完成欧式聚类,否则选取集合A中除p点以外的点,重复上述过程,直到A中的点数不再增加,即完成聚类分割。图5为采用欧式聚类算法分割后的效果图。

图 5 场景分割Fig.5 Scene segmentation
从图5可以看出,当场景中的物体不相互粘连时,场景中的牛奶盒、茶叶罐、布仔、可乐罐被有效聚类。能够满足点云目标识别的要求。
2 目标识别与位姿估计
在点云目标识别过程中,最重要的是三维描述子的设计,一个目标能否被有效识别,很大程度上取决于三维描述子获取目标特征信息的准确性与完整性,三维描述子具有分辨率不变性、强鲁棒性和旋转不变性[22-23]等特点。三维特征按照空间搜索范围分为局部特征和全局特征[24]。局部特征描述子是对点云数据局部特征的描述,不需要对场景点云进行分割,直接计算场景物体局部特征,并与模型库完成匹配,识别速度快、具有旋转尺度不变性,但对点云噪声比较敏感;全局特征是对整个点云数据特征的描述,容易忽略细节信息,为了提高识别率,需要对场景点云进行适当分割。面对复杂环境,特别是物体相互遮挡、存在相似目标的场景中,本文提出一种复合描述子CV-SHOT,将全局特征的CVFH与局部特征的SHOT描述子结合起来,通过粗识别-精匹配两步法识别目标,并估计目标在场景中的位姿。
2.1 霍夫投票算法
3D霍夫变换用于检测平面、圆柱、球体以及不规则几何体[8]。以霍夫投票的票数为判断依据,实现目标点云的识别,并利用关键点局部坐标系的唯一性,获取识别目标的初始位姿。本文通过计算模型、场景关键点的局部参考系,利用SHOT描述子得到的模型-场景对应点集作为投票的特征点,提高霍夫投票的准确性。
相机拍摄角度或场景物体的移动,使场景中的待识别物体模型发生旋转平移,因此在霍夫投票之前,需要将模型参考向量坐标和场景坐标转换到同一个三维空间中,参考向量空间坐标转换如图6所示。
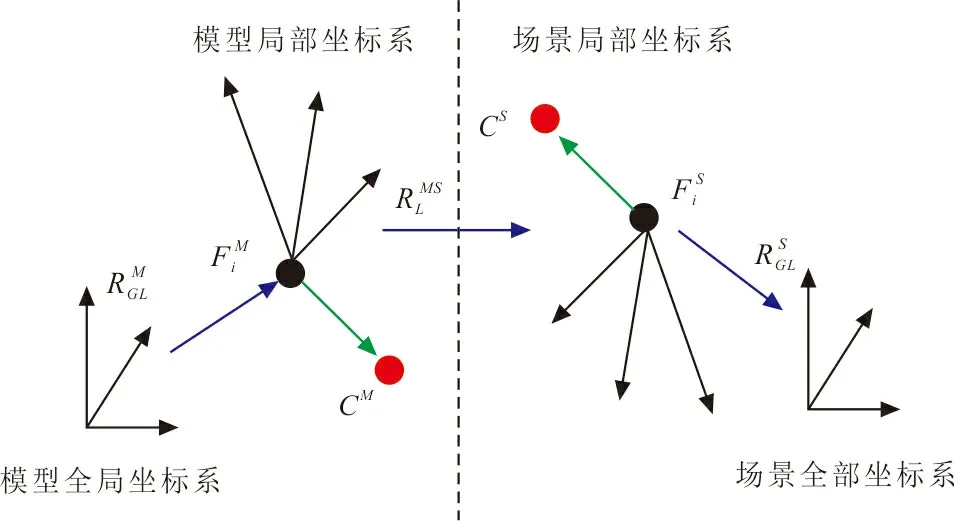
图 6 空间坐标转换Fig.6 Space coordinate conversion
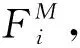
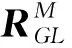
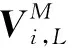
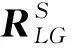
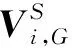
2.2 目标识别
CVFH是VFH的扩展,可有效获取复杂场景下遮挡目标的特征,CVFH将待识别的目标点云表面划分为多个平滑且连续的区域,在每个区域中生成VFH。因此,一个目标的识别可以由多个平滑且连续区域的CVFH特征表示。
SHOT描述子将签名法和直方图法组合描述点云局部特征,具有旋转及尺度不变性、对点云密度不敏感等特性。在特征点处建立半径为R的邻域空间,将邻域空间沿纵向划分为8份,沿半径划分为2份,沿高度划分为2份,邻域空间划分为32份,计算每份中特征点法线ni与特征点法线np的夹角余弦值cosθ,将每份空间中的余弦值划分为11个单元用直方图统计,则每个特征点的维数为32×11=352维,其中两法线夹角余弦值cosθ,即
cosθ=ni·np
(5)
将CVFH和SHOT描述子结合进行目标识别。首先对场景点云使用CVFH特征进行快速初步识别,得到相似的k个目标,极大地缩小了目标搜索空间,提高了识别速度;使用SHOT描述子进行进一步识别,获得模型-目标的初始对应点集;计算关键点的局部参考系,采用霍夫投票算法使匹配的点集生成投票向量;最后通过霍夫投票数滤除匹配的伪对应点,实现目标识别。
2.3 位姿估计
完成场景中目标识别后,需要进行点云配准,获得目标物体的精确位姿。点云配准是不断迭代优化的过程,经典的ICP算法通过迭代最近点实现点云配准,但是当匹配的点云间位姿相差较大时,容易陷入局部最大值,因此选取霍夫投票高的目标位姿作为配准的初始位姿,实现粗配准,再采用ICP算法进行精确配准,得到模型库目标到场景目标的旋转矩阵R与平移向量t。
ICP算法通过在匹配点集中不断迭代搜索最近点间的距离平方和获得最优的刚性变换,欧式距离平方和计算公式:
(6)
式中:Np为匹配点数;xi、pi分别为模型、场景点。
ICP算法通过不断迭代,使最近点距离平方和不断收敛,直到达到设定的距离阈值或者迭代次数,并输出最优的旋转矩阵R和平移向量t。设α、β、γ分别为坐标轴的旋转角度,tx、ty、tz分别为坐标轴的平移向量,则六自由度参数为
ψ=(α,β,γ,tx,ty,tz)
3 结果与分析
3.1 算法框架
目标识别算法分为离线训练与在线识别2个阶段,CV-SHOT算法流程如图7所示。
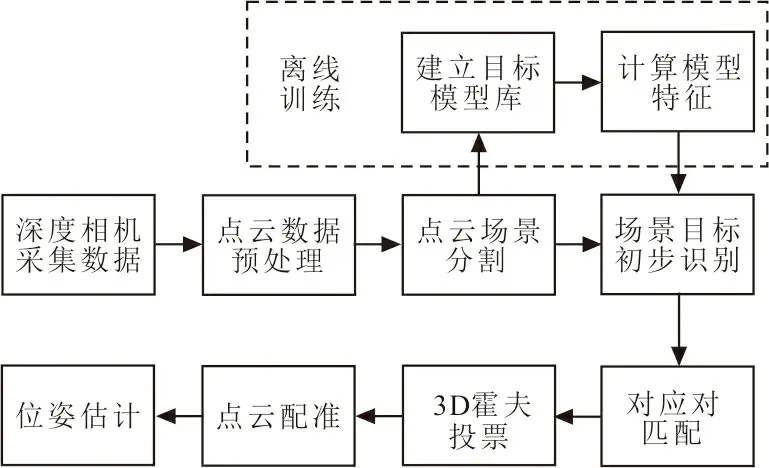
图 7 CV-SHOT算法流程Fig.7 CV-SHOT algorithm flow
3.1.1 离线训练。
1) 建立目标点云数据集模型库。在实验室真实场景下,使用深度相机采集单个目标物体各个方向的几何、颜色信息,利用Intel RealSense SDK生成目标点云,采集100个目标点云数据构成模型库。
2) 在目标点云空间中建立KDTree结构,计算模型库中各个点云的CVFH描述子,建立物体类别数据文件。
3.1.2 在线识别。
1) 将原始场景点云进行点云预处理,采用欧式聚类分割算法分割场景物体,得到有效的多个聚类,组成点云集Q。
2) 设置初步识别时匹配的目标模型数量为k,取k=3,卡方检测阈值为D,计算点云集Q中第i个聚类的CVFH特征(i=1,2,3,…),对模型库进行k近邻搜索,利用训练建立的KDTree结构进行近似查找,搜索得到k个小于卡方检测阈值D的相似点云集合q,完成初步的识别。
3) 将包含k个点云聚类的相似点云集q按卡方距离从小到大排序,采用体素滤波算法提取点云关键点,对点云数据稀疏化处理。
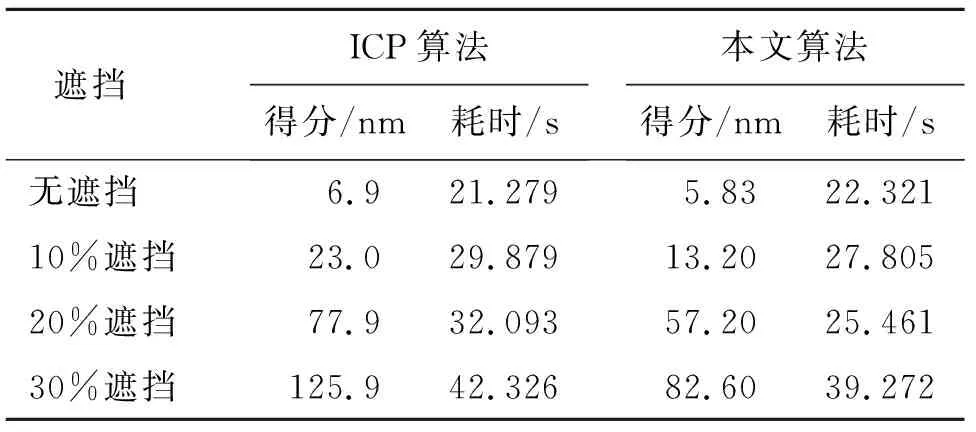
4) 分别计算SHOT描述子,使用KDTree FLANN方法匹配,通过最近邻搜索得到相似点,当相似点对的平方距离S<0.25时,则为模型-场景的对应点,遍历整个点云聚类qm(0 5) 计算关键点局部参考坐标系,采用3D霍夫投票算法去除伪匹配点对,精确识别目标,并获得初始位姿。 6) 根据获得的初始位姿,采用经典的ICP算法进行点云目标的精确配准,得到场景中目标的最终位姿估计。转到步骤2,进行识别点云集合Q中下一个候选点云聚类。 7) 在场景中被识别到的目标用绿色标识,并输出其六自由度位姿;迭代下一帧场景点云。 以识别真实场景中布仔为例,运行本文算法,有效地识别目标并计算布仔位姿。识别效果如图8所示。 图 8 识别效果图Fig.8 Recognition effect diagram 旋转平移矩阵: M=t(tx,ty,tz)·R(α,β,γ)= 转化为六自由度位姿: ψ=(α,β,γ,tx,ty,tz)= (-0.015 0.008 0.005 0.005 0.010 -0.001)3.2实验平台搭建 计算机操作系统为windows 10,硬件配置为Intel(R) Core(TM) i3-4005U CPU@ 1.70 GHz,运行内存为8 GiB,结合PCL 1.9.1 点云库,在 Visual Studio 2019中编译运行程序。真实场景中的点云采集设备使用英特尔公司的RealSense D435i深度相机,采集实验室场景制作数据集。 以识别布仔为例,在布仔场景中分别采用C-SHOT算法[8]、CSHOT-VFH算法[25]、本文三维视觉识别算法进行测试。使用深度相机RealSense D435i采集200个真实环境中的单物体点云图作为数据来源,单物体识别结果见表1。 表 1 单物体识别结果 从表1可以看出,本文算法识别率比C-SHOT算法提高了约3%,相比C-SHOT、CSHOT-VFH算法,修正了目标与模型点云位置、形状相似下目标分割不准确造成的误匹配,使目标识别率进一步提高。 考虑实际生产环境的复杂性,对多物体(除布仔,多个相似物品)以及对布仔进行部分遮挡的复杂场景进行识别。同样,采集200个真实环境中的复杂场景点云图作为数据来源,多物体识别结果见表2。 表 2 多物体识别结果 从表2可以看出,现有识别算法在复杂环境下的识别率明显降低,本文算法通过两步法识别,利用SHOT特征修正识别,降低了相似目标的误识别率,识别率显著提高,高达93.5%,验证了本文算法对复杂环境有一定的鲁棒性。 在位姿估计阶段,为了检验目标位姿的准确性与稳定性,以估计场景中布仔为例,首先对场景中布仔添加不同程度的遮挡,即占原始布仔点云数据量的百分比,遮挡强度为无遮挡、10%、20%、30%,不同遮挡程度下的布仔遮挡场景如图9所示。 (a) 无遮挡 (b) 10%遮挡 (c) 20%遮挡 (d) 30%遮挡图 9 不同遮挡程度下的布仔Fig.9 The fabric objects in under different degrees of occlusion 通过采集布仔不同程度遮挡的场景,测试位姿估计算法以及ICP算法[10],计算并统计布仔的配准耗时与配准得分,不同遮挡程度下布仔配准性能见表3。 其中配准得分为配准过程完成后对应点集之间距离平方和的平均值,得分越低,表明配准效果越好。配准得分计算公式: (7) 式中:pj为模型中的点;qj为模型点pj在场景中所对应的点;n为对应点的数量。 表 3 不同遮挡程度下布仔配准性能 从表3可以看出,随着布仔遮挡程度的增加,相比ICP算法,本文算法的配准得分与配准耗时增加幅度较小,配准得分均小于ICP算法,且得分保持在10 μm级别,配准时间也有所下降,因此,本文提出的位姿估计算法在存在目标部分遮挡情况下仍能保持较好的配准效果,对复杂场景具有一定的鲁棒性。 1) 面对复杂场景下的三维目标识别,本文改进了传统的CVFH识别算法,提出了一种将CVFH算法与SHOT算法相结合的特征融合识别算法,并将3D霍夫变换与ICP算法结合,实现了复杂环境下的目标识别与位姿估计。 2) 在单物体场景、部分遮挡的多物体场景中,验证了本文算法比传统识别算法识别率有效提高,达到了90%以上。 3) 对相同位置、不同复杂场景中的目标进行位姿估计,本文位姿估计算法准确度较高,可满足对三维目标有效识别与定位的需求。

3.3 数据集



4 结 论
