基于知网的词语语义相似度改进算法研究*
2022-03-17MariusPetrescu潘俊辉王浩畅
王 辉 Marius.Petrescu 潘俊辉 王浩畅 张 强
(1.东北石油大学计算机与信息技术学院 大庆 163318)(2.普洛耶什蒂石油天然气大学 普洛耶什蒂 100680)
1 引言
词语相似度计算在面向各领域的自动问答系统、词语语义排歧、信息检索等方面都有着广泛的应用[1]。目前,中文词语语义相似度计算方法大致可分为两类:一类是依赖大规模语料库统计词语相关性,如利用相关熵[2]或平均互信息[3]等计算词语相似度,计算过程复杂,计算结果受训练数据噪声和数据稀疏影响;另一类是根据世界知识(Ontology)或某种分类体系(Taxonomy),借助现有同义词词林[4]、WordNet[5]、知网[6]等,分析词语在树型结构中的语义信息进行词语相似度计算,计算方法简单有效,易受个体主观意识影响。然而,专家所划分的词语知识概念体系具有一定权威性,根据概念关系计算词语相似度计算也更合理。
与WordNet 和同义词词林不同,知网作为目前国内词语语义研究的主流工具,其是一部比较详尽的词语语义知识词典,采用多维知识表示形式描述一个词的语义。因此,基于知网的中文词语语义相似度的计算,可归结为义项各组合间的相似度计算,进而逐步归结为义原相似度的计算[7]。如,张硕望等考虑了词语与义原之间的包含关系[8],王小林等简化了义原分类[9],吴华等提取词语的上下文语境特征作为语义承载单元[10]。
在基于本体知识的相似度算法基础上,本文深入研究知网描述语言特征和结构,综合考虑义原距层次树根节点深度、义原所在区域密度及其主次关系对义原相似度的影响,提出一种义原相似度计算改进方法,进而得到了新的词语语义相似度算法。
2 基于知网的词语语义相似度计算
2.1 知网
1988 年,中科院计算机语言信息工程研究中心董振东提出,自然语言处理系统需要强大的知识库支持,应首先建立一种以中英文词语代表的概念为描述对象,以揭示概念间及其属性间的关系为基本内容的常识知识库[11]。数年后,此库被称为知识系统的常识性知识库,即知网(HowNet)。自1999年公布以来,知网作为一部详尽的语义知识词典,已被广泛应用于自然语言处理、机器翻译等方面的研究。
知网与其他树状词汇数据库有着本质不同,知网的哲学和根本特性决定了它独特的建设方法,其侧重利用中文词语意义结构特征来分析和提取义素,采用一套基于义原和关系的结构化标注语言——知识库描述语言(KDML)标注语义。
在知网中,主要包含“义项“和“义原”两个概念,每个汉语词语均由义项的集合语义来描述,义项由“知识表示语言”——义原来定义,义原则是描述概念的、不可再分的最小意义单位[12]。每个汉语词语的义项可分为虚词义项和实词义项,其中实词义项集合语义可由四类义原集合描述组成,即第一基本义原描述、其他基本义原描述、关系义原描述、关系符号描述[13]。
2.2 词语语义相似度计算
假设有两个中文词语w1和w2,若w1涉及n个义项:s11,s12,…,s1n,w2涉及m 个义项:s21,s22,…,s2m,词语w1和w2语义相似度sim(w1,w2)定义为涉及到的各个义项间相似度最大值[14],如式(1)所示。
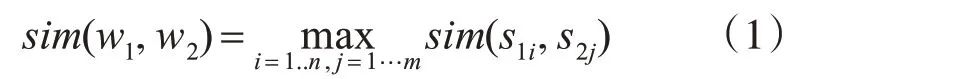
式中,sim(s1i,s2j)为义项s1i与s2j之间相似度。故,词语语义相似度计算归结为义项相似度的计算。
2.3 义项相似度计算
知网中,义项分为虚词义项与实词义项,因此,义项相似度计算分为虚词义项相似度计算和实词义项相似度计算。
2.3.1 虚词义项相似度计算
由于虚词本身没有词汇意义的特点,虚词与实词不可以互相替换,导致虚词义项与实词义项的相似度总是归为零[15]。虚词义项总是用句法义原或关系义原描述,故为得到虚词义项相似度,实际需要计算的是其对应的句法义原或关系义原之间相似度。
2.3.2 实词义项相似度计算
实词义项是用语义表达式来描述的,故为得到整体的实词义项相似度,应分别计算第一基本义原描述式、其他基本义原描述式、关系义原描述式及关系符号描述式四类义原集合的相似度。
1)第一基本义原描述式
指描述该实词最基本语义特征的义原,也是对最重要的一个描述式,相似度记为sim1(s1,s2)。
2)其他基本义原描述式
指除第一基本义原外,用基本义原(或具体词)描述的所有其他基本义原(或具体词),相似度记为sim2(s1,s2)。
3)关系义原描述式
指描述式中每个特征属性都是关系义原,如“关系义原=基本义原”或者“关系义原=(具体词)”,相似度记为sim3(s1,s2)。
4)关系符号描述式
指所有用符号义原描述的描述式,如“关系符号基本义原(具体词)”,相似度记为sim4(s1,s2)。
因此,可用虚词义项和实词义项的各部分相似度表示义项整体相似度,如式(2)所示。
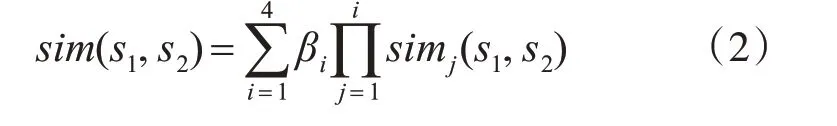
式中,βi(1 ≤i≤4)为可调节的参数,且有β1+β2+β3+β4=1,β1≥β2≥β3≥β4。后者不等式反映了sim1到sim4对义项相似度的影响依次减弱,由于第一基本义原描述式反映的是义项最贴切、最主要的特征,sim1影响最大,一般β1≥0.5。因此,义项相似度的计算可归结于义原相似度计算。
2.4 义原相似度计算
义原相似度是由义原的语义距离计算得到的,所有义原根据上下位关系均构成树状义原层次体系。然而,分属不同义项领域的多棵树状义原层次树并无交集,不同树的义原间没有任何可行路径,语义距离也不存在,这类义原相似度为零。属于同一棵树的不同义原之间存在可行路径,刘群等提出可利用义原节点在树状结构的距离关系来计算这类义原相似度[11],如式(3)所示。
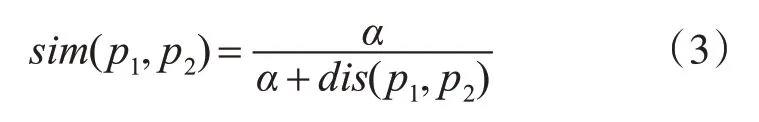
式中,p1和p2为两个义原;dis(p1,p2)为义原p1和p2处于同棵义原树的义原距离,当两义原分属不同树时,dis(p1,p2)取一个较大常数,一般取值为20[16];α为可调节的参数,取值为1.6。
3 改进的词语语义相似度计算方法
Rigau 在利用Wordnet 计算词语的语义相似度时,提出在义原树中,影响义原距离最主要的两个因素是义原深度与义原密度[11]。义原深度指义原距所在层次体系树根节点的路径长度,长度越短,其表达的概念(即义项)越抽象,反之,表达的概念越具体。义原深度相同的两个节点,若位于层次树的越底层,其语义距离较大。义原密度(即义原区域密度)指义原所在层次体系树的同层兄弟节点总数(含自身),总数越大,则说明分类越细致,其携带的语义信息越详细。路径长度相同的两个节点,若位于层次树中的高密度区域,其语义距离应大于位于低密度区域的相同路径长度的两个节点。
因知网中均采用单个义原描述第一基本义原,导致其距离义原树的根节点很近,义原深度与密度对第一基本义原影响不大,本节仅改进除第一基本义原之外的义原相似度算法。
本节参照张小川等利用距离约束最小层次义原深度因素,保证义原距离对相似度计算结果主导作用的方法[6],以及葛斌等提到的综合考虑义原层次树的深度、密度等因素对义原节点权重的影响[17],改进式(2)得到新的义原相似度计算方法,如式(4)所示。

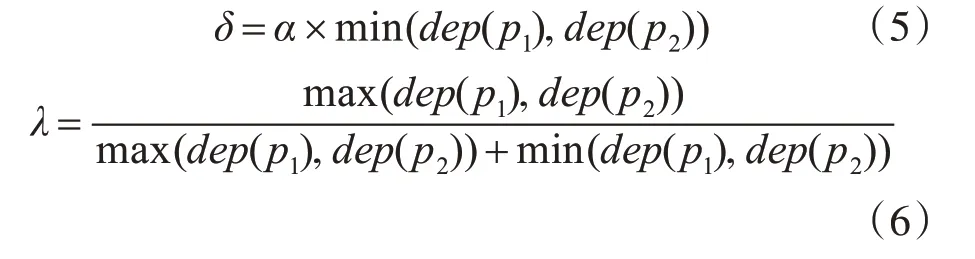
式中,sim(p1,p2) 为义原p1和p2的相似度;dis(p1,p2) 为义原距离;min(dep(p1),dep(p2)) 为义原最小深度;max(dep(p1),dep(p2))为义原最大深度;G是义原p1和p2的最小公共父节点;f(·)为当前义原的兄弟节点个数,能够反映其所在树中的密度信息;γ1+γ2=1,γ1和γ2为权重因子,分别取值为0.5;α和ε为调节参数,取值分别为0.5和2。
李蕾等认为义原深度越大,义原距离越小;义原密度越大,义原距离越小。综合考虑义原深度与义原密度,设置权重因子来限制义原深度与义原密度的影响[18],将dis(p1,p2)义原距离取为边权重之和,如式(7)所示。

式中,weight(ip,q)为层次树种每条边的权重,随层数递增而单调递减;ip,q为义原p与q之间的边;q是义原p的上一层父节点;depth为当前义原层次树树高;kp为义原p所在层编号;max 为义原p所在树中所有义原节点总数;c1+c2=1,c1和c2为权重因子,分别取值为0.7和0.3;θ为调节参数,取值为4。
4 实验结果与分析
本文的实验数据来自《知网》网站(http://www.keenage.com/)。根据文献[11]多次尝试中取得的经验,结合多次实验,设置了实验参数值,如表1 所示。
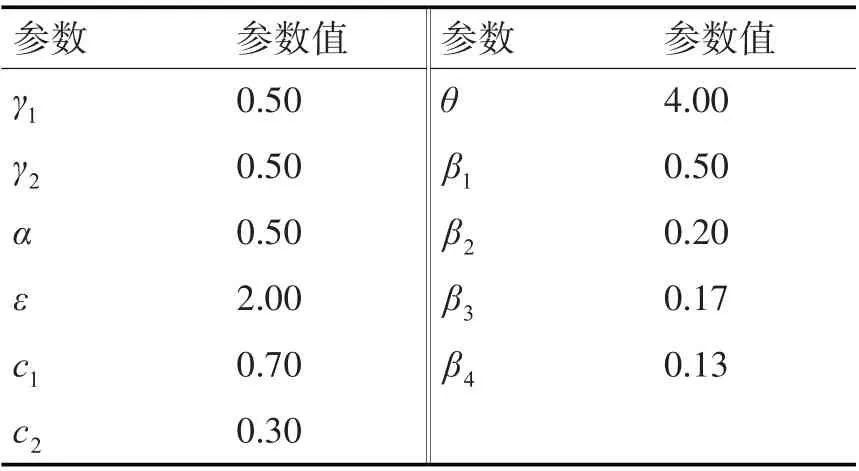
表1 实验参数设置
本文实验使用5 种不同方法来计算比较义原相似度,实验结果如表2 所示。方法1 为文献[11]算法;方法2 为文献[6]算法;方法3 为文献[17]算法;方法4为文献[18]算法;方法5为本文算法。
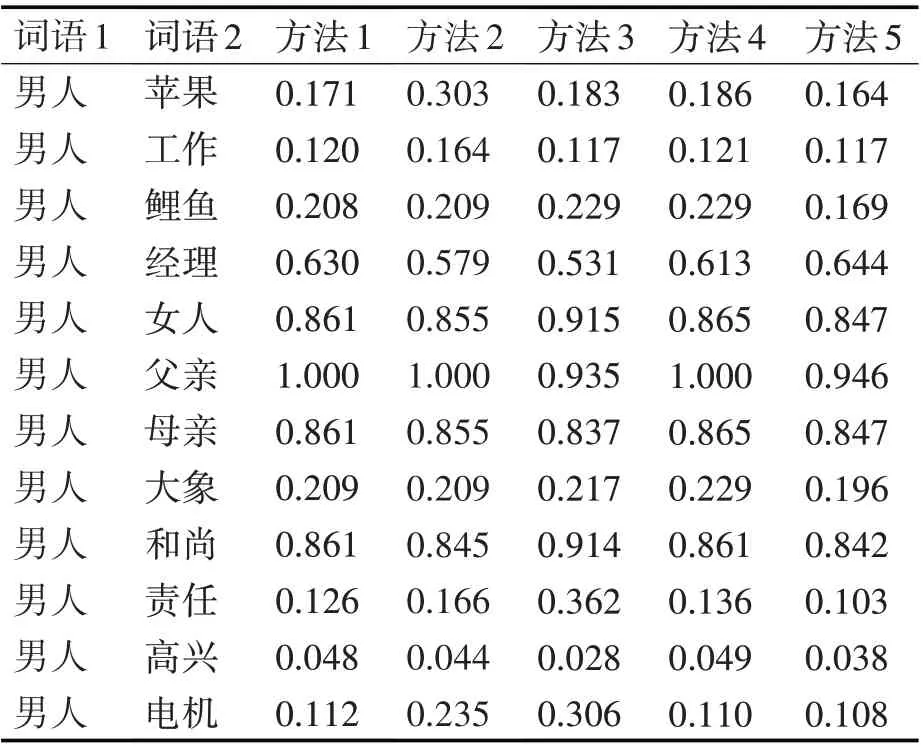
表2 实验结果对比
方法1 仅考虑了词语中义原距离因素,没有考虑义原层次树种节点深度与区域密度的影响,因而实验结果比较粗糙,如“男人-女人”、“男人-母亲”相似度相同,且接近于“男人-父亲”相似度。方法2 与1 比较,部分数据有所降低,主要是因为方法2在义原语义相似度计算中用集合的加权平均值代替了最大值,使得实验结果稍客观,效果不够明显。方法3与方法1、2比较,由于加入了层次权重,可以比较细腻地区别不同词汇,更符合人为认知判定标准,比如“男人-母亲”相似度明显降低;“男人-父亲”相似度在前两个方法中相同,但在方法3中有所降低,这是符合人为判定标准的。但也有不太合理的地方,比如“男人-女人”相似度在前三个方法中,均得到了大于或等于“男人-和尚”相似度的数值。方法4 与前三个方法比较,由于加入了调整义原深度与密度主次关系的权重因子,大部分相似度更加合理,只出现了个别相似度遗漏,比如“男人-父亲”相似度重新回到方法1的数值。方法5与前四个方法比较较为合理,在深入分析义原深度、义原区域密度及其主次关系之后,将词语语义相似度刻画较为细致,使得原本相似度高的词计算出的相似度更高,反之原本相似度低的词计算出的相似度更低;又因为参考了方法3 的层次权重,更好呈现出了符合人为认知判定的实验结果,比如“男人-父亲”相似度没有重新回到方法1的数值。
5 结语
不同于其他语义词典,知网采用了上千个义原,通过KDML描述每个义项。为了更好地计算两个词语语义表达式相似度,本文将其分解成多个部分语义表达式,在保证义原距离对最终相似度计算结果的主导作用前提下,综合考虑了义原距离、义原深度、义原密度对义原相似度的影响,构建出一种新的词语语义相似度计算方法,结合实验结果对比分析,验证了该算法更为合理和准确。但由于汉语词汇本身的复杂性、多义性等因素,词语语义相似度计算仍有很大的研究空间,今后将侧重从信息论的角度深入研究义原树中拥有的信息量对相似度的影响。
