基于大数据分析的电网多数据源实时在线诊断方法
2022-03-15王书领邵其专滕伟业
王书领,邵其专,滕伟业
(云南电力调度控制中心,云南昆明 650000)
电力设备故障对智能电网的安全运行起着重要作用,电力系统中的设备运行时间越长,设备出现故障的可能性越大[1]。为了保证电力设备的安全运行,降低损失,必须对电力设备进行状态监测与故障诊断,以便及早发现设备出现的各种故障,避免灾害、事故的发生[2]。传统的数据降维方法主要通过主成分分析(PCA)实现,但在智能电网环境下,可靠性和实时性较差。在极端恶劣的环境下,电力设备经常由于监测值超标而向监测中心发送报警数据,造成监测中心在极端恶劣的情况下,出现井喷现象;使用基于混合神经网络的电网故障诊断算法,不能满足实际数据实时接收和处理的需求,造成数据丢失和覆盖。因此,提出了基于大数据分析的实时在线诊断方法,在大数据平台上部署电网数据,以实现电网特征数据的并行故障诊断。
1 电网多数据源特征
当电力系统运行时,电力特征量随系统运行状态而变化。在有故障源的情况下,通过特征参数显示故障信息[3]。将此信息作为故障测度,可以对系统状态进行诊断。电网多数据源的信息通过系统特征和状态来传递,若信息来源只发出一种状态,即为确定量信息,则信息的特征不带任何资讯,所以信息必然包含未知和不确定性[4-6]。电网多数据来源的不确定性与电网每一状态发生的概率有关[7]。
设电网出现故障的数据集为x(x1,x2,…,xn),每种故障状态出现的概率为P(xi),则一个数据源可以用一个概率空间描述,即:
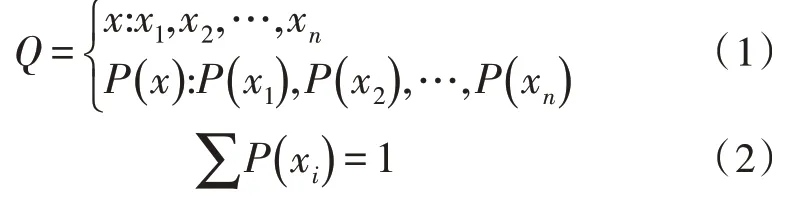
在上述公式中,各个状态空间相互独立,因此,可得到电网多数据源特征为:
1)不确定度是指数据源的状态数和其在概率空间的概率分布;
2)在数据源的概率空间为等概率分布时,不确定度较大;
3)当分布相等时,不确定度与可能状态数或相应概率有关。随着状态数的增加,不确定度增大,相应概率减小;
4)通过数据源概率倒数的对数度量表示数据源不确定度,即:

式(3)中,k表示度量数据量。该公式用来衡量数据量,数据量与接收数据前后不确定度关系有关,数据量降低,说明电网接收信息前后,概率空间概率分布发生变化[8-10]。为此,假定以y表示收到的信息,则不确定度可表示为:
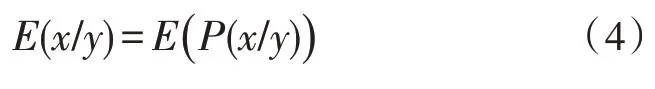
式(4)中,P(x/y)表示接收到的电网信息后验分布概率;E(x/y)表示异常信息熵,表示电网故障状态处于不确定的程度,由此得到的信息量为:
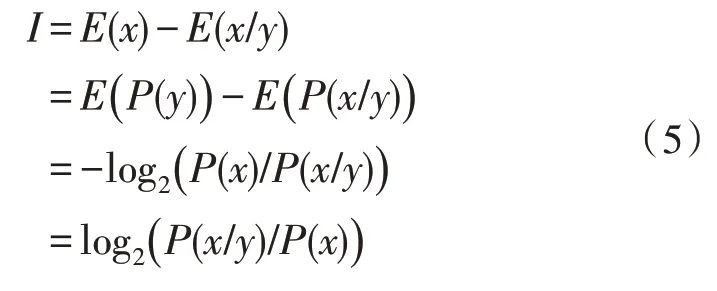
2 实时在线诊断方案设计
诊断方案的拓扑实现包含两部分,首先是模型构建,然后匹配相关数据,结合数据流处理过程和聚类过程,设计在线诊断流程。诊断方案的拓扑实现过程如图1 所示。
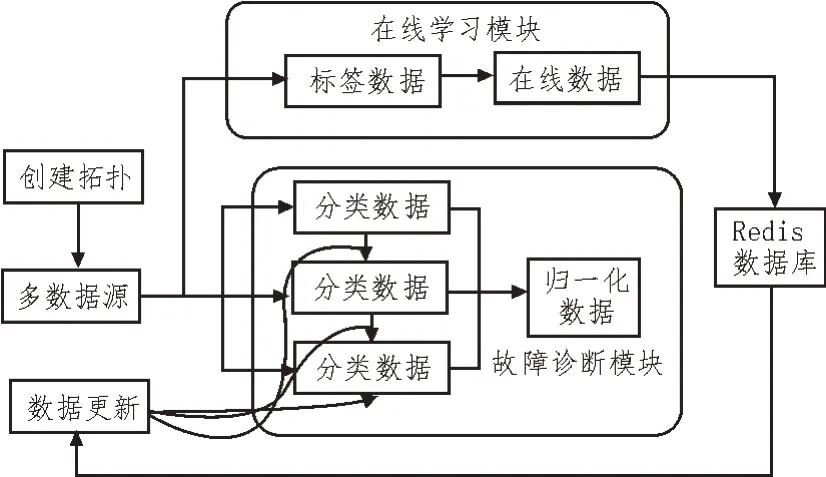
图1 诊断方案的拓扑实现过程
采用历史数据模拟在线数据,实时监测数据源,以便实现电网多数据源的在线学习与诊断[11-13]。
2.1 电网多数据源多维诊断模型构建
结合电网多数据源特征,构建了电网多数据源诊断的大数据多维模型,如图2 所示。
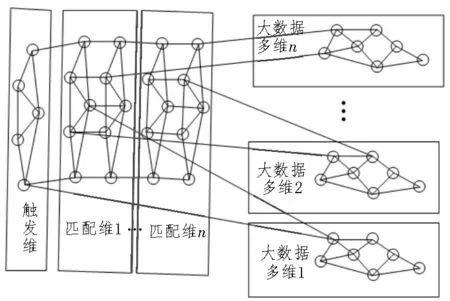
图2 大数据多维诊断模型
由图2 可知,电网故障诊断采用多维存储节点数据,通过大数据关联将相同数据维度的节点连接起来。对于多维大网络,当一个数据节点被成功触发时,对应的电力系统诊断数据会被激活,从而得到相应的诊断结果[14]。
2.2 匹配维
匹配维是触发维和大数据多维之间的桥梁,匹配维大数据节点的设计至关重要。基于触发器大小数据,匹配相同大小的大数据节点,具有相同的故障类别、电压等级和接线方式[15]。与维度匹配的大数据节点主要生成大数据多维共有部分,如图3 所示。
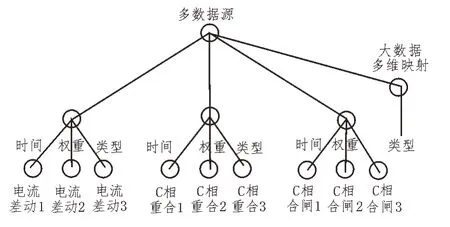
图3 触发多维大数据节点
由图3 可知,大数据节点代表线路电流差动保护及重合动作,而与大数据节点相同的部分,则是触发维度节点成功匹配时激活的匹配维度。与数据多维相同,每个匹配维度都有一个匹配维度的大数据与之关联,能够提高节点匹配效率。
2.3 数据处理
电网特征向量数据为无间隔数据流,通过向匹配维连续发送数据,构成待处理数据流。为便于对诊断结果的后续处理,保证元组处理顺序一致,每个发送的元组对每个元组中相应的数据集进行唯一标识,并将电网多维数据源多维诊断模型,按ID 排序相关计算结果进行汇总[16]。
为使元组样本数据规范化,采用了电网设备特征向量数据,每一个数据都有多维性特征。通过迭代更新聚类中心,计算每个聚类中心所有样本点的向量均值,聚类过程为:
步骤1:随机选择n个样本数据中的k个不同样本作为初始聚类中心。
步骤2:对样本集和各聚类中心之间的矢量距进行计算,选择矢量距最小的样本进行分类。K-均值算法一般是用欧氏距离来划分样本,公式为:
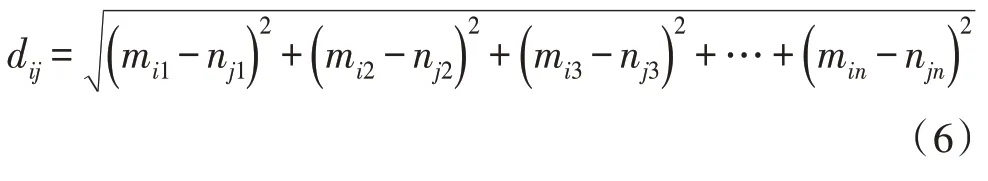
式(6)中,dij表示大数据多维节点m和n之间的欧式距离,其中mi多维节点坐标为(mi1,mi2,mi3,…min),nj多维节点坐标为(nj1,nj2,nj3,…njn)。
步骤3:更新簇中心,计算每一个类中所有样本数据的平均数,并以这些平均数为新的簇中心。
步骤4:重复步骤2 和步骤3,直到新的聚类中心不再改变,聚类停止,由此完成数据处理。
2.4 实时诊断流程设计
依据数据处理结果,对电网多数据源异常情况进行诊断,流程如下:
步骤1:在大数据多维节点中,通过大数据分析方法,获取电网多数据源处理队列,并对节点进行聚类。
步骤2:实时检测数据,得到的各个参量处理队列,依据该队列及时判断不同时间节点数据是否属于同一聚类中心。
步骤3:判断电网多数据源处理队列中是否存在异常数据,如果存在,则各个数据流中的节点数据属于正常数据。
步骤4:判断电网多数据源处理队列中是否存在少数异常数据,如果存在,则各个数据流中的节点数据既存在正常数据,也存在异常数据。
步骤5:判断电网多数据源处理队列中异常数据是否超过数据总量的1/2,如果是,则各个数据流中的节点异常数据比正常数据多。
通过上述内容,可实现基于大数据分析的电网多数据源实时在线诊断,这样可以使计算量达到最小,缩短诊断时间。
3 实验分析
为了验证基于大数据分析的电网多数据源实时在线诊断的实时性和有效性,进行了实验验证分析。
3.1 实验环境
实验室建立了一个Storm 云平台,包括一个主节点和8 个从节点,使用了5 台服务器形成物理集群,伺服器通过千兆开关连接,虚拟软件XenServer 安装在每个服务器上。9 个节点被虚拟化,每个节点分配两个CPU 内核。Storm 系统被配置为9 个虚拟机。虚拟机①为主要控制节点,其余8 个虚拟机②为工作节点,表1 为平台配置信息。

表1 Storm云平台信息
部署与系统相关的外部环境,在每个工作节点中分配4 个工作点,每个节点最多运行4 个进程,通过不同交换机连接实现节点间通信,由此构造一个内部网段。
3.2 诊断性能测试
3.2.1 吞吐量测试
吞吐量指在单位时间内电网处理的数据量,通过测试集群工作节点,分析吞吐量变化情况。保持集群节点数不变,改变组件并发数,设进程数为5个,不同组件并发数下的吞吐量如表2 所示。
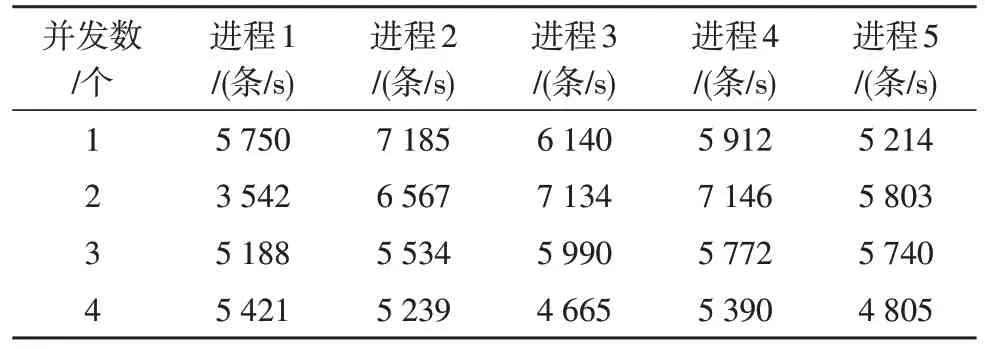
表2 不同组件并发数下的吞吐量
基于此,分别使用主成分分析法、混合神经网络算法和基于大数据分析方法,分析不同组件并发数下的吞吐量,对比结果如图4 所示。
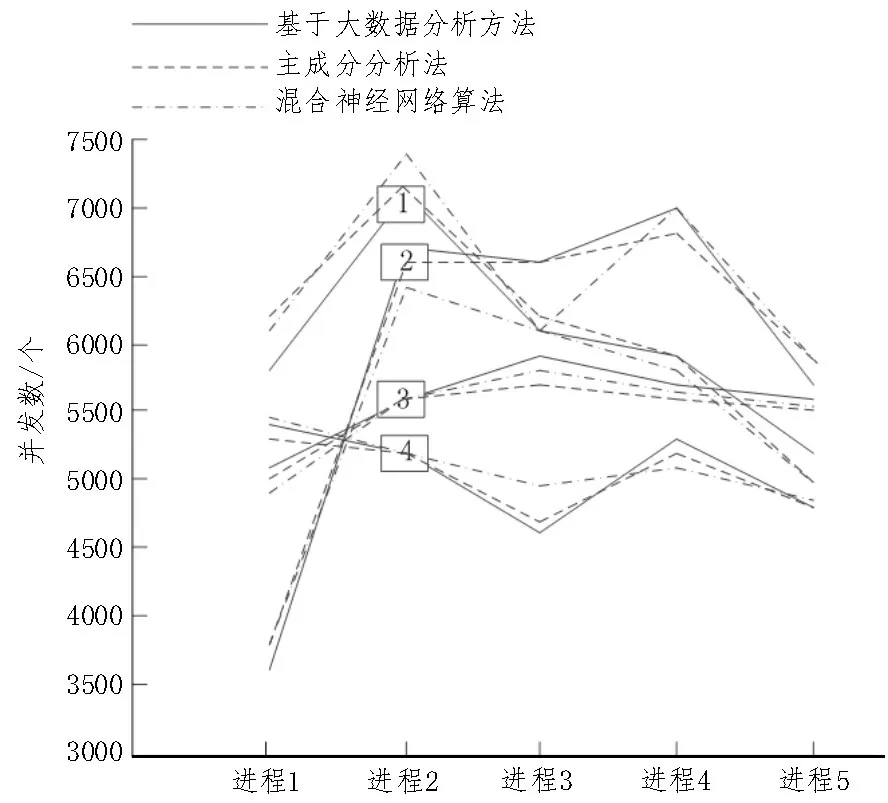
图4 不同方法吞吐量诊断结果对比分析
由图4 可知,使用主成分分析法、混合神经网络算法在不同进程下,与实际值存在一定偏差。其中,使用主成分分析法在进程4 下,与实际值偏差最大,相差200 个并发数。使用混合神经网络算法在进程1 下,与实际值偏差最大,相差300 个并发数。而使用基于大数据分析方法与实际值一致,误差为0。
3.2.2 数据延迟测试
数据延迟指在Storm 架构中,数据被发送到其被完全处理的时间,不同元数据序号下,预期延迟处理时间如表3 所示。
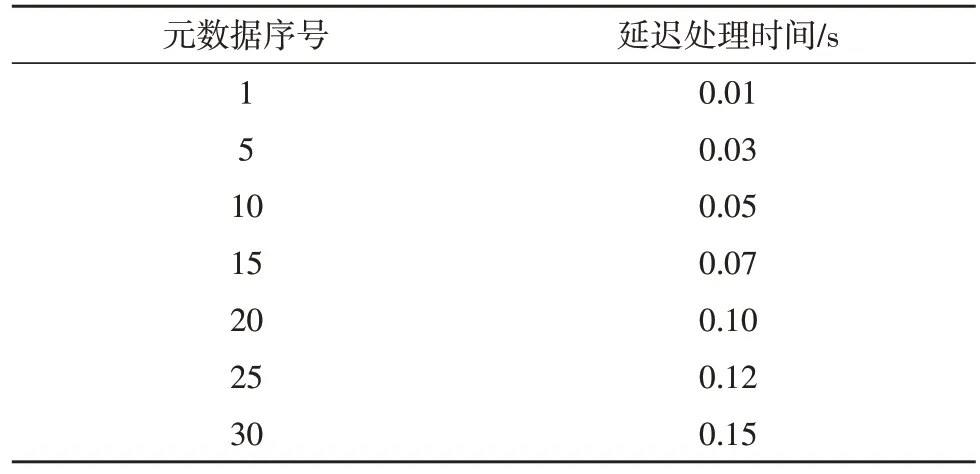
表3 不同元数据序号下预期延迟处理时间
基于此,分别使用主成分分析法、混合神经网络算法和基于大数据分析方法,分析不同元数据序号下预期延迟处理时间,对比结果如图5 所示。
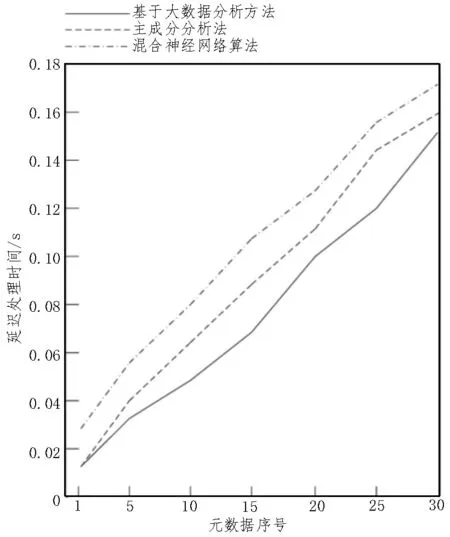
图5 不同方法延迟处理时间诊断结果对比
由图5 可知,使用主成分分析法、混合神经网络算法延迟处理时间比实际时间要长,而使用基于大数据分析方法与实际时间一致。
4 结束语
针对传统诊断方法实时性不足的问题,研究了基于大数据分析的电网多数据源实时在线诊断方法。实验表明,基于大数据分析的电网多数据源实时在线诊断方法能够满足电网快速诊断数据需求。然而,由于实验环境的限制,只能并行诊断电网数据,实践中应考虑多种不同因素,引入复杂事件,采用面向服务的思想,对多源信息实时处理。
