机器学习在ENSO预测会商中的应用
2022-03-10李晨彤
李晨彤
(国家海洋环境预报中心,北京 100081)
1 引言
厄尔尼诺-南方涛动(ElNiño-Southern Oscillation,ENSO)预测模型目前大体可分为动力模式和统计模式两种[1-4]。动力模式(确定论)利用了物理规律,没有利用或没有充分利用已有的大量实况历史资料;统计模式(概率论)利用了积累的大量实况资料,却没有利用或没有充分利用我们掌握的物理规律。动力模式在短期预测上是成功的,但对长期预测而言,单纯的动力学方法难以奏效。统计模式基于历史资料进行统计分析,无法区分现有资料中哪些联系是本质的,哪些是偶然的。实践表明,动力方法和统计方法都有一定的准确率,两者都能反映大气运动的部分规律[5-7]。
目前,ENSO 预测模式的预测能力仍然表现出不稳定性[8-9]。研究显示,采用统计方法对模式预测结果进行集合订正,可以减小模式误差对预报的影响[10-11]。多模式集合订正是提升ENSO 预报技巧和预测能力的有效方法[12-17]。机器学习作为一项新的技术,它的优势之一是对机制尚未清楚的问题进行分析、联想、记忆、学习和推断[18]。机器学习方法的引入使得气象预报和气候预测的运算量减小、运算速度加快、运算精度提高,但也存在过拟合和泛化效果差等问题[19-25]。因此,需要寻找合适的机器学习方法对ENSO 多模式预测结果进行集合订正,提高ENSO 预测的准确率,更好地应对ENSO 事件产生的影响。
近年来,国内外研究人员基于各种机器学习方法开展海表面温度(Sea Surface Temperature,SST)、海表面温度异常(Sea Surface Temperature Anomaly,SSTA)和Niño3.4 指数的预测研究工作。Ham 等[26]使用卷积神经网络(Convolutional Neural Networks,CNN)进行了18 M 超前预报时效的SSTA 和Niño3.4指数预测。1984—2017年的预报结果表明,CNN 模型的Niño3.4 指数预报技巧远高于目前最先进的动力模式,同时,该模型也能更好地预测海面温度的详细区域分布,克服了动态预测模型的弱点。Zhang 等[27]使用长短时记忆模型(Long Short-Term Memory,LSTM)对渤海SST进行预测,较传统方法的预报准确度有所提升,均方根误差(Root Mean Squard Error,RMSE)减小。Aguilar-Martinez等[28-29]分别使用贝叶斯神经网络、支持向量回归和线性回归建立热带太平洋区域SSTA 预测模型对ENSO 进行预测,可信度较高,超前预报时效较传统模型可提升至12 M,且非线性预报模型优于线性预报模型。Nooteboom[30]等结合自回归整体滑动平均方 法(Autoregressive Integrated Moving Average Model,ARIMA)和人工神经网络(Artificial Neural Networks,ANN)建立了一种Niño3.4 指数预报模型,并根据Zebiak-Cane(ZC)模式的测试结果进行特征选择,针对不同超前预报时效选取不同输入因子。该模型在6 M以内超前时效上的技巧评估优于气候预测系统版本2(Climate Forecast System version 2,CF Sv2)集成。此外,2010 年1 月起报的预测结果优于CFSv2集合的所有成员。许柏宁等[31]使用序列到序列模型预测Niño3.4 指数,可以较好地预测出SSTA 变化趋势,但在峰值处表现较差。其结果与传统的动力学ENSO 预报模型相比,在中长期(提前7 M以上)预测上的RMSE表现更好。何丹丹等[32]搭建了基于Attention机制的序列到序列预报模型进行Niño3.4 区SST 预测,在短期预测上其预测结果与其他方法相当,长期预测中RMSE 比其他方法下降了0.3~0.4。蒋国荣等[33]使用后向传播(Back Propagation,BP)算法进行ENSO 预报,可以较好地预测ENSO 事件(关键区海温的变化趋势)。但预报技巧评估依赖于预报时效,当预报时效较短时,预报技巧评估较好,反之,则较差。结果还表明,增加隐含层神经元个数对预报技巧评估改进不大。以上研究说明,搭建机器学习模型进行ENSO预测,在短期预测和长期预测上预报技巧评估都相当或优于传统的动力模式和统计模式[34]。跟传统方法一样,也存在随着预报时效增加,预报技巧评估变差的现象。
本研究基于预测会商工作的思想,利用可解释机器学习方法——决策树算法建立了多模式ENSO预测结果智能会商系统,模拟会商工作的流程,并给出预测结论及预测依据。在建模过程的可解释方面,该智能会商系统给出了各模式预测结果的特征重要性。不同的决策树模型表现出较为一致的偏好,超前预报时效较短时偏重于动力模式,较长时偏重于统计模式。这与在不同超前预报时效上,动力模式和统计模式预报技巧的高低相吻合。黑盒模型无法给出该解释,只能给出预测结果。
2 数据与方法
2.1 数据获取及预处理
特征值:从美国哥伦比亚大学气候预测国际研究所(International Research Institute for Climate and Society, IRI)官网(网址:https://iri.columbia.edu/~forecast/ensofcst/Data/)下载多个模式的季节性(3 M滑动平均)Niño3.4指数预测结果。目前,IRI官网收录的模式数达十余个,基于特征数据集的连续性和完整性考虑,筛选出预测结果时间序列较长和缺失值较少的模型预测结果作为订正对象,输入智能会商系统。动力模式来自欧洲中期天气预报中心(European Centre for Medium-Range Weather Forecasts,ECMWF)、日本气象厅(Japan Meteorological Agency,JMA)、美国国家航空航天局(National Aeronautics and Space Administration,NASA)、美国国家环境预报中心(National Centers for Environmental Prediction,NCEP)、美国哥伦比亚大学拉蒙地球观测中心(Lamont-Doherty Earth Observatory,LDEO)、韩国气象局和首尔国立大学(Korean Meteorological Adminstration and Seoul National University,KMA SNU);统计模式有美国气候预测中心马尔可夫(Climate Prediction Center MRKOV),美国气候预测中心模拟构建(Climate Prediction Center Constructed Analog,CPC CA)、美国科罗拉多州立大学气候预测(Colorado State University CLImate PRediction,CSU CLIPR)。
标签值:从美国国家环境预报中心(网址:https://www.cpc.ncep.noaa.gov/data/indices/)下载ERSST v5 季节性(3M 滑动平均)Niño3.4 指数数据,作为监督学习的标签值。
缺失值处理:对各模式预测结果的缺失值进行插值处理。
2.2 数据集构造
依据训练集(2002—2017 年数据)和测试集(2018—2020 年数据)的划分,分别构造多模式超前1~9 个季节性滑动平均月(下文中分别简称超前1~9 M)预报时效预测结果的数据集。
2.3 预报技巧评估指标
皮尔逊相关系数(Pearson Correlation Coefficient,PCC)r:衡量预测值同观测值之间相关程度的量。
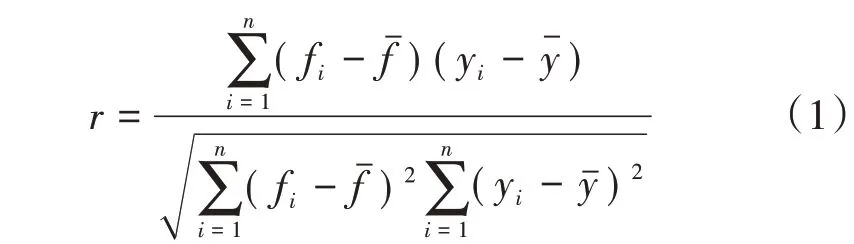
均方根误差(Root Mean-Square Error,RMSE):衡量预测值同观测值之间离散程度的量。
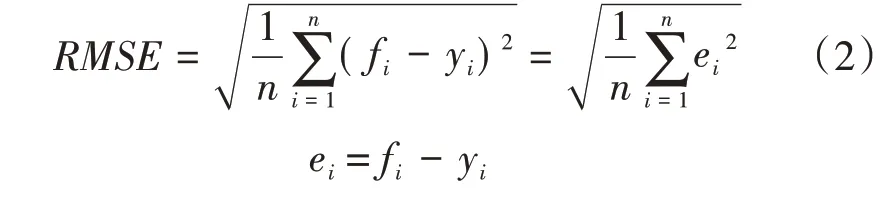
平均绝对误差(Mean Absolute Error,MAE):衡量预测值同观测值之间偏差大小的量。
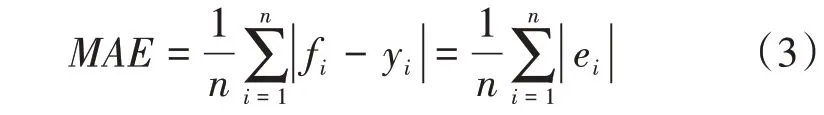
式中,fi为预测值;yi为观测值;ei为预测值与观测值之间的误差。
2.4 决策树算法
决策树(Decision Trees)是一种用来分类或者回归的监督学习方法[35-36],相较其他机器学习方法,决策树模型具有所需训练数据少、准确性高和可解释性等方面的优势。因此,本研究选用可解释的决策树模型进行机器学习建模。
单棵决策树容易出现过拟合的问题,泛化能力有限。通过某种集合策略将多颗决策树组合起来的决策树算法——集成学习(Ensemble Learning),能够构建并结合多个学习器来完成学习任务,泛化能力得到提升。根据个体学习器的生成方式,集成学习方法大致可以分为提升法(Boosting)和套袋法(Bagging)[37]。
Boosting 是一簇可将弱学习器提升为强学习器的算法。基于Boosting 的方法主要有:梯度提升决策树(Gradient Boosting Decision Tree,GBDT)[38]、极端梯度提升(eXtreme Gradient Boosting,XGBoost)[39]和轻量梯度提升机(light Gradient Boosting Machine,lightGBM)[40]。
Bagging 基于自助采样法(bootstrap sampling),也叫有放回重采样法。基于Bagging 的方法主要为随机森林(Random Forest,RF)[41]。
2.5 超参数调整方法
机器学习算法中的调优参数(Tuning Parameters)需要人为设定,称为超参数(Hyper Parameter)。在算法中,它们作为参数传递给估计器类的构造函数。用于搜索超参数最佳配置的策略包括:网格搜索交叉验证(Grid Search with Cross-Validation,Grid Search CV)和随机搜索交叉验证(Randomized Search with Cross-Validation,Randomized Search CV)等。本文结合两种方法的优势,扬长避短,先通过Grid Search CV 寻找出超参数最佳配置的大致范围,然后利用Randomized Search CV在该范围内搜索出超参数的最佳配置。
3 基于决策树模型的ENSO 多模式预测结果智能会商系统
在预报预测产品发布前,通常需要一个必不可少的会商过程来综合汇总各预报结果,博采众长,以有效降低或避免因主观性和经验性导致的空报、错报甚至漏报,提高预报准确率。会商通常包括收集整理、分析处理和可视化等步骤,并作出最终的预报结论及依据。在此过程中,存在着大量重复性工作。因此,本实验借鉴会商工作的思想,借助机器学习方法在快速完成繁琐工作方面的优势,模拟ENSO 预测会商过程,建立一个多模式的ENSO 预测结果智能会商系统,实现流程的智能化和智慧决策。该智能会商系统可以实现读取各模式预测结果、智能调参、给出Niño3.4 指数预测结论及预测依据和可视化预测结果等一系列流程的自动化。
3.1 基于GBDT 算法的ENSO 多模式预测结果订正模型
基于GBDT 的订正模型中各模式结果特征重要性方面(见表1),超前1~5 M 和超前7 M 的动力模式预测结果平均特征重要性高于统计模式,超前6 M和超前8~9 M的统计模式高于动力模式。
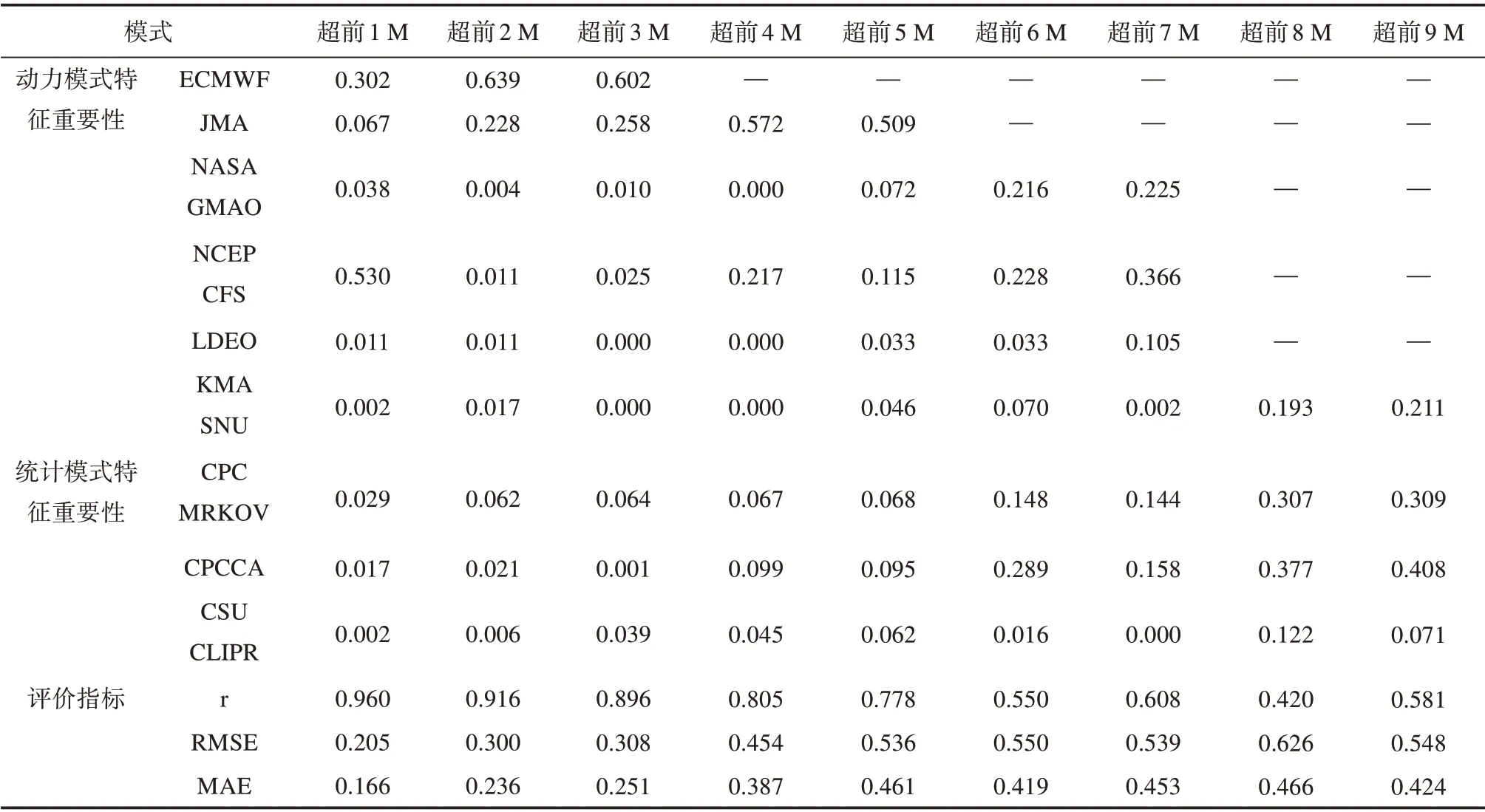
表1 GBDT订正模型的模式预测结果特征重要性及订正结果评估Tab.1 Feature importance of the prediction results of GBDT revised model and evaluation of the revised results of GBDTrevised model
从GBDT 模型的订正结果时间序列图可以看出(见图1),超前1~3 M 的相位和强度与标签值基本一致;超前4~5 M 的相位和强度与标签值偏差较小,存在过拟合问题;超前6~9 M的相位和强度与标签值偏差较大,较标签值幅度逐渐变小。总体而言,随着预报时效的增加,相位滞后程度逐渐加大,强度偏差也越来越大。
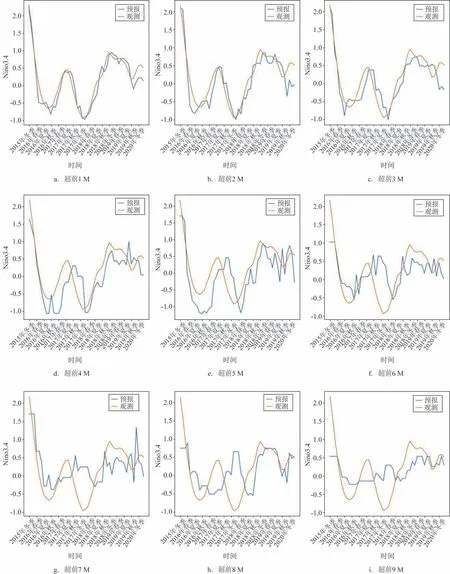
图1 基于GBDT算法的集合订正结果Fig.1 Correction results based on GBDT algorithm
GBDT 模型的订正结果评估如表1 所示。超前1~3 M的r在0.9 左右,超前4~5 M在0.8左右,超前6~7 和超前9 M 为0.550~0.581;超前1 M 的RMSE为0.205,超前2~3 M在0.3左右,超前4 M为0.454,超前5~9 M 为0.5~0.6;超前1~3 M 的MAE 在0.2左右,超前4~9 M在0.4左右。
3.2 基于XGBoost 算法的ENSO 多模式预测结果订正模型
基于XGBoost 的订正模型中各模式结果特征重要性方面(见表2):超前1~2 M 的动力模式预测结果平均特征重要性高于统计模式,超前3~9 M 的统计模式高于动力模式。
从XGBoost 模型的订正结果时间序列图可以看出(见图2),超前1~3 M 的相位和强度与标签值基本一致;超前4~5 M 的相位和强度与标签值偏差较小,存在过拟合问题;超前6~9 M 的相位和强度与标签值偏差较大,较标签值幅度逐渐变小。总体而言,随着预报时效的增加,相位滞后程度逐渐加大,强度的偏差也越来越大。
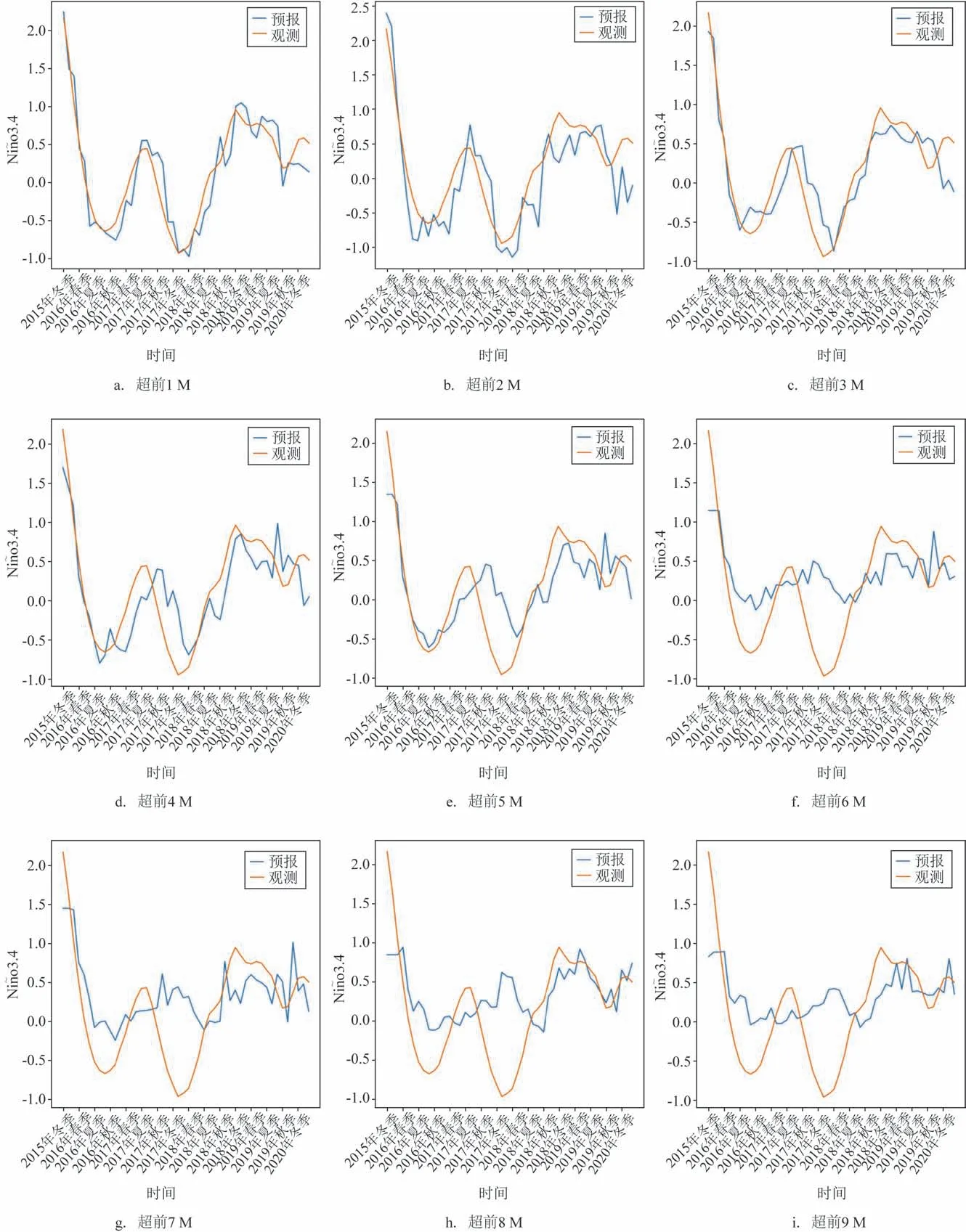
图2 基于XGBoost的集合订正结果Fig.2 Correction results based on XGBoost algorithm
XGBoost 模型的订正结果评估如表2 所示。超前1~3 M 的r在0.9 左右,超前4~5 M 在0.8 左右,超前6~7 M 达0.6 以上,超前8~9 M 在0.547 以上;超前1 M的RMSE为0.248,超前3~5 M为0.3~0.4,超前5~9 M为0.5~0.6;超前1~4 M的MAE在0.2~0.3,超前4 M为0.308,超前5~9 M为0.408~0.451。
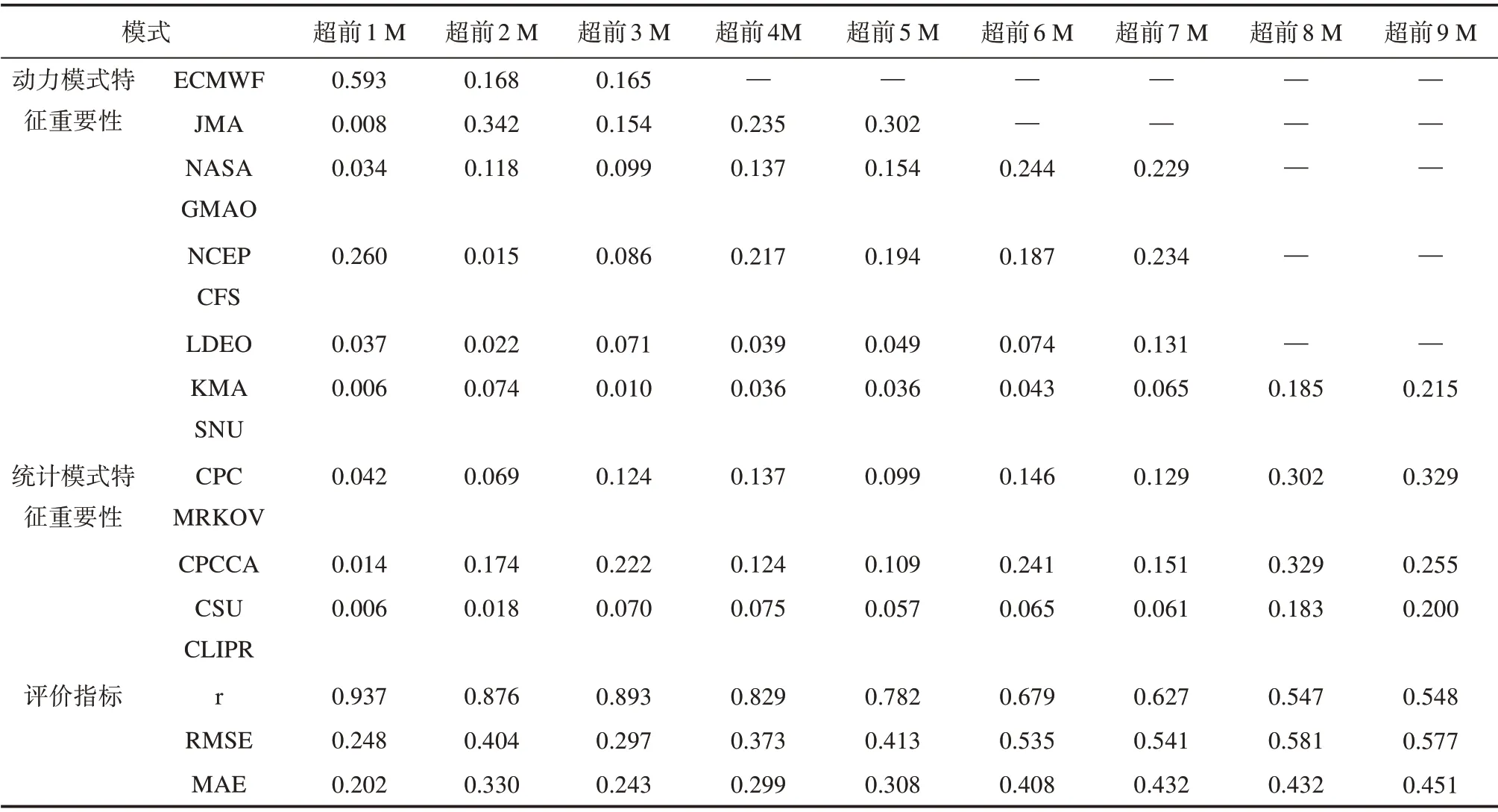
表2 XGBoost订正模型的模式预测结果特征重要性及订正结果评估Tab.2 Feature importance of the prediction results of XGBoost revised model and evaluation of the revised results of XGBoost revised model
3.3 基于lightGBM 算法的ENSO 多模式预测结果订正模型
基于lightGBM 的订正模型中各模式结果特征重要性方面(见表3):超前1~2 M 和超前6 M 的动力模式预测结果平均特征重要性高于统计模式,超前3~5 M和超前7~9 M的统计模式高于动力模式。
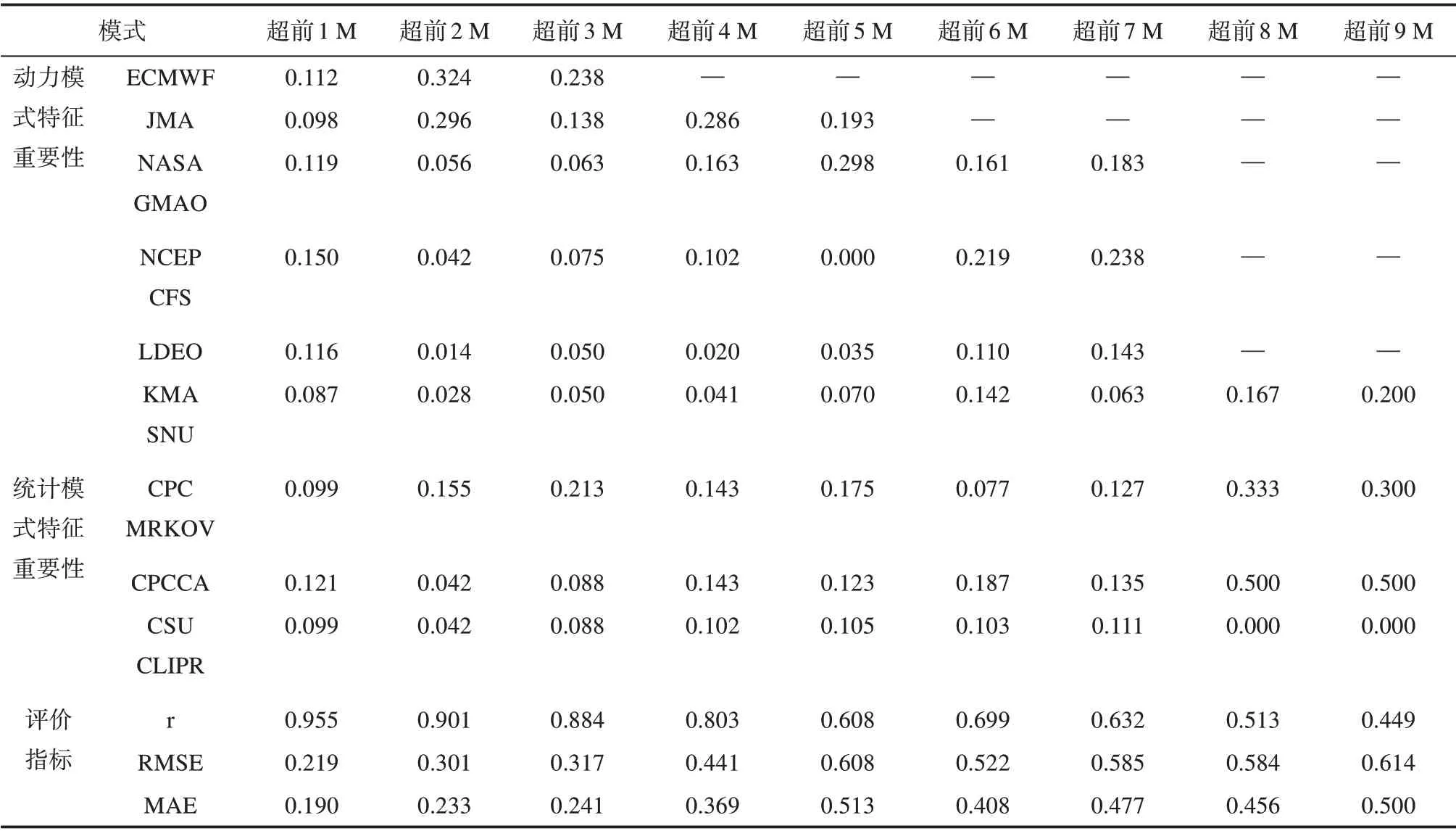
表3 lightGBM订正模型的模式预测结果特征重要性及订正结果评估Tab.3 Feature importance of the prediction model results of lightGBM revised model and evaluation of the revised results of lightGBM revised model
从lightGBM 模型的订正结果时间序列图可以看出(见图3),超前1~3 M 的相位和强度与标签值基本一致;超前4~7 M的相位和强度与标签值偏差较小,存在过拟合问题;超前8~9 M 的相位和强度与标签值偏差较大,较标签值幅度逐渐变小且趋平。总体而言,随着预报时效的增加,相位滞后程度逐渐加大,强度偏差也越来越大。
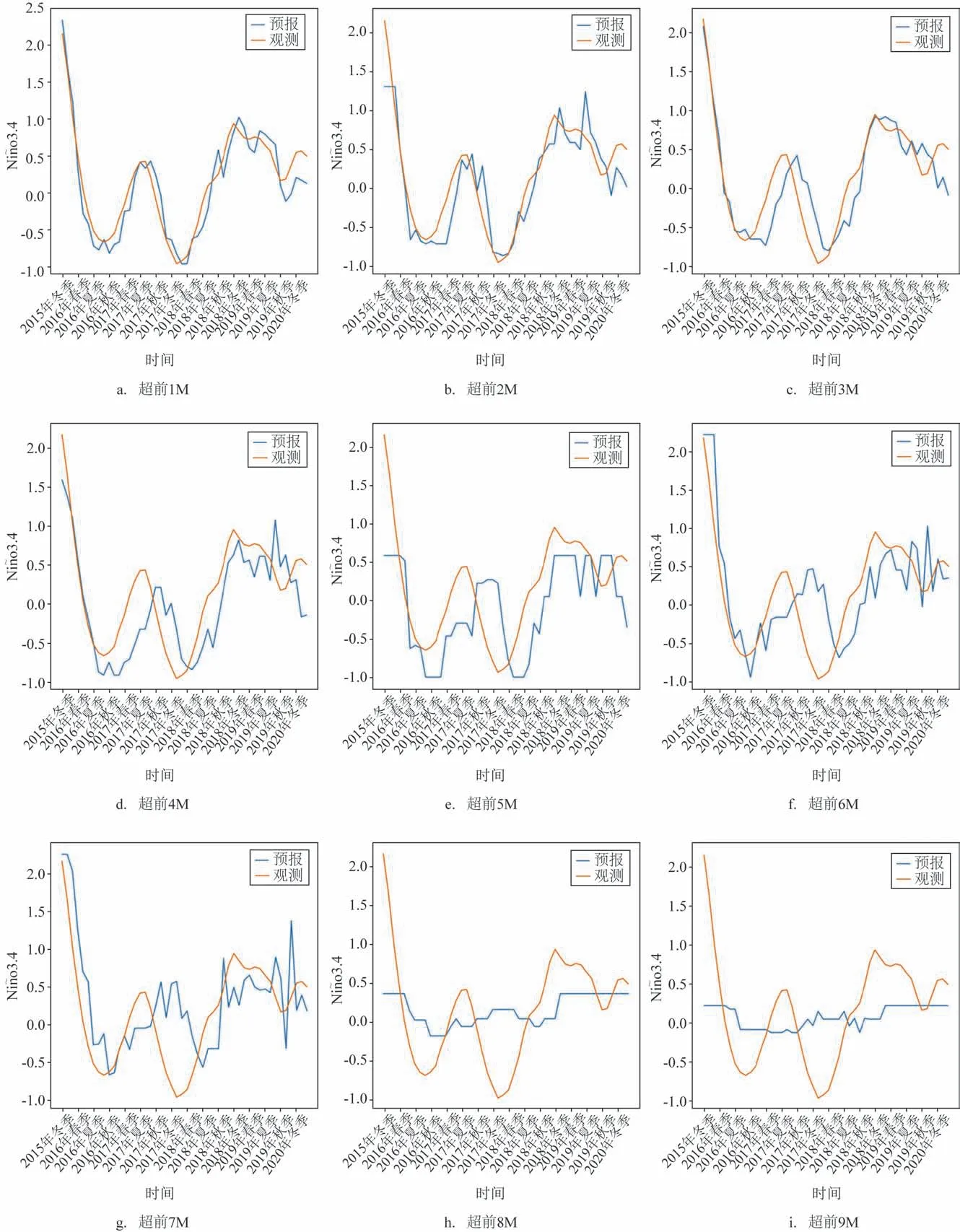
图3 基于lightGBM的集合订正结果Fig.3 Correction results based on lightGBM algorithm
lightGBM模型的订正结果评估如表3所示。超前1~3 M 的r在0.9 左右,超前4 M 达到0.8,超前5~7 M为0.6~0.7,超前8~9 M为0.5左右;超前1~3 M的RMSE的r在0.2~0.3,超前4 M为0.441,超前5~9 M为0.5~0.6;超前1~3 M的MAE 在0.2 左右,超前4 M为0.369,超前5~9 M为0.4~0.5。
3.4 基于RF算法的ENSO多模式预测结果订正模型
基于RF 的订正模型中各模式结果特征重要性方面:超前1~5 M 和超前7 M 的动力模式预测结果平均特征重要性高于统计模式,超前6 M和超前8~9 M的统计模式高于动力模式。具体而言,超前1~3 M 动力模式明显高于统计模式;超前4~7 M 动力模式和统计模式基本相当;超前8~9 M动力模式明显低于统计模式。
从RF 模型的订正结果时间序列图可以看出(见图4),超前1~3 M 的相位和强度与标签值基本一致;超前4~7 M 的相位和强度与标签值偏差较小,存在过拟合问题;超前8~9 M 的相位和强度与标签值偏差较大,相较标签值幅度逐渐变小。总体而言,随着预报时效的增加,相位滞后程度逐渐加大,强度的偏差也越来越大。
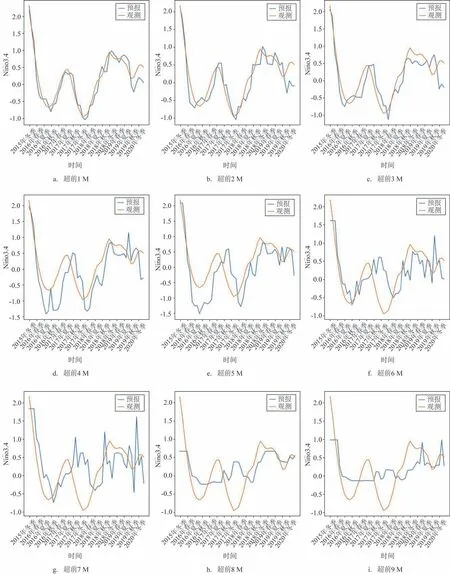
图4 基于RF的集合订正结果Fig.4 Correction results based on RF algorithm
RF 模型的订正结果评估如表4 所示。超前1~3 M 的r在0.9 左右,超前4~5 M 在0.8 左右,超前6 M 和超前8~9 M 基本达到或超过0.6;超前1~3 M的RMSE为0.2~0.3,超前4~6 M和超前8~9 M在0.55 以下;超前1~3 M 的MAE 在0.2 左右,超前4~6 M和超前8~9 M在0.46以下。
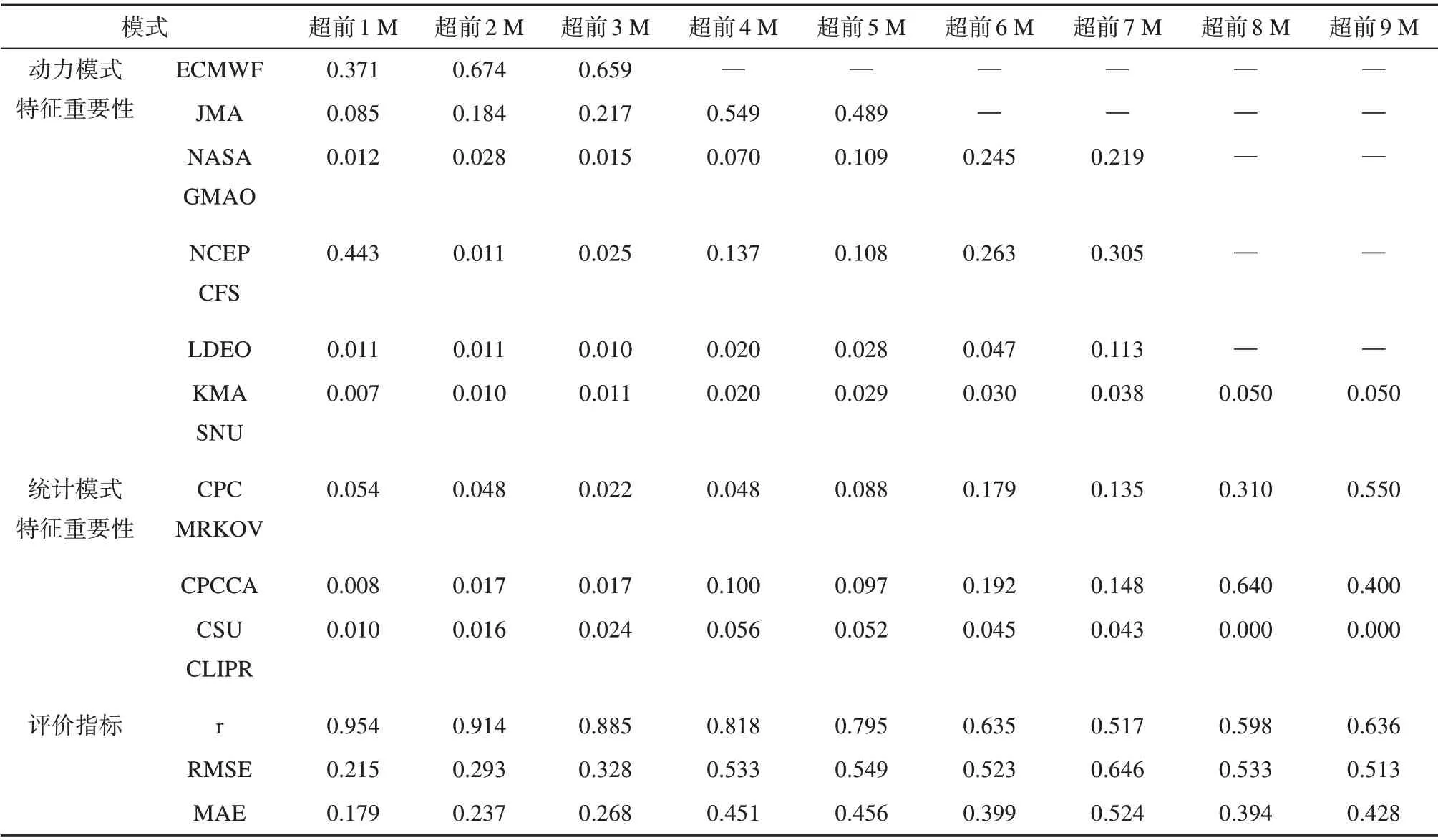
表4 RF订正模型的模式预测结果特征重要性及订正结果评估Tab.4 Feature importance of the prediction model results of RF revised model and evaluation of the revised results of RF revised model
3.5 智能会商系统结果分析
4 种决策树算法订正结果的时序趋势随着预报时效的增加而趋平,这与输入订正模型的模式预测结果有关。特别地,随着超前预报时效的增加,起报时间逐渐提前,输入特征的极值范围不断缩小。对于2015年冬季发生的超强厄尔尼诺事件,起始时段的订正结果时间序列呈直线状,且强度明显偏弱。这跟机器学习模型的预测效果依赖于训练集的丰富程度密切相关。
4 种决策树算法在不同超前预报时效上的预报技巧表现不一,这可能与4 种算法在数学方法上选用的目标函数和损失函数不同,以及在工程实现方面采用的技术手段不同有关。XGBoost对异常点敏感;GBDT精度更高且灵活性更强,但运算过程消耗内存过大;lightGBM所需内存更小且运算速度更快;RF综合表现良好,相对于其他算法有较大的优势。
随着超前预报时效的增加,预报技巧整体呈下降趋势。但是,4 种决策树模型在超前6~9 M 预报时效上的预报技巧存在着不同程度的起伏,并不严格随预报时效的增加而降低,这可能与决策树算法的不稳定性有关。
4 总结与展望
本研究主要得到以下结论:
(1)在建模特征重要性方面,不同的决策树模型表现出不同的偏好。整体而言,超前预报时效较短时,偏重于动力模式,较长时,偏重于统计模式。这与在不同超前预报时效上,动力模式和统计模式预报技巧的高低相吻合。
(2)决策树模型同传统的动力模式和统计模式一样,随着预报时效的增加,相位滞后程度逐渐加大,强度的偏差也越来越大,甚至有时间序列趋于平缓的趋势,同时还存在过拟合的问题。不同决策树模型在不同超前预报时效上的预报技巧表现不一,这与机器学习算法的特性有关。
(3)基于4 种可解释机器学习算法建立的多模式ENSO 预测结果智能会商系统,对多模式结果进行集合订正,预报技巧达到或优于传统的动力模式和统计模式水平。这说明使用机器学习算法进行多模式集合订正具有优势,同Ren 等[42]的调研结果相一致。
此外,由于机器学习算法本身存在一定的缺陷,机器学习回归预测模型的预报技巧依赖于训练数据的丰富程度,对于未经训练的极值,无法给出有效预测结果。例如,对于2015—2016 年发生的超强厄尔尼诺事件,该智能会商系统的预测能力有限。
