增强型DeepLab算法和自适应损失函数的高分辨率遥感影像分类
2022-03-09许泽宇沈占锋李杨赵丽芳柯映明李苓苓温奇
许泽宇,沈占锋,李杨,赵丽芳,柯映明,李苓苓,温奇
1.中国科学院空天信息创新研究院国家遥感应用工程技术研究中心,北京100101;
2.中国科学院大学电子电气与通信工程学院,北京100049;
3.中国科学院空天信息创新研究院遥感科学国家重点实验室,北京100101;
4.中国科学院大学资源与环境学院,北京100049;
5.应急管理部国家减灾中心,北京100124
1 引言
随着遥感影像分辨率的提高,高分辨率遥感影像呈现了大量的新特点,如几何、结构、纹理特征丰富,光谱精细化,地物目标多尺度化等等(李德仁等,2012)。传统遥感信息提取方法已不足以满足高分辨率影像地物信息提取的需求。深度学习方法可以提取地物更多更深层次的特征信息,近些年来广泛用于遥感图像的分类、识别、检索和提取(龚健雅和季顺平,2017),也给高分辨率遥感影像地物提取提供了新的思路。
计算资源和数据资源的结合,为人工神经网络的复兴和深度学习技术的发展提供了前所未有的契机(郭华东等,2016)。深度学习中语义分割网络可以同时提取物体的类型、位置和轮廓信息,适用于遥感地物的自动分类和提取。目前常见的语义分割神经网络在基础卷积神经网络如VGG(Simonya 和Zisserman,2015)、GoogLeNet(Szegedy等,2015)、ResNet(He 等,2016)的基础上发展而来,比较典型的有FCN(Shelhamer 等,2017)、SegNet(Badrinarayanan等,2017)、Deeplab(Chen等,2017a,2017b,2018b)等。
在高分辨率遥感影像信息提取中,建筑、道路提取是研究的热门课题(龚健雅和季顺平,2018)。李志强(2019)构建了一种多级特征参与决策的全卷积神经网络算法,在公开的Mnih 建筑物数据集(Mnih,2013)上得到了优于传统网络结构的提取结果。刘笑(2018)结合改进的道路形状特征指标以及深度学习结构,提高了网络抗干扰能力和建筑物提取的精度,且对道路中心线的定位更加准确。彭博(2018)改进了现有网络结构,提出了B-DLinkNetPlus 等模型以提高道路提取的视觉效果,提出了融合多尺度生成对抗网络GAN-Unet改进模型,以解决不同等级道路宽度不一致问题。
相比于形状比较规则的建筑、道路,低矮植被、树木等信息提取的加入,进一步增加了高分辨率影像信息提取和分类的复杂性,因此,高分辨率影像中多种地物的同时分类更具挑战性。在具体应用中,Kussul等(2017)提出了一种多级的深度学习模型,在土地利用分类中其算法相对于多层感知机和随机森林算法有明显优势。夏梦等(2017)结合深度学习和条件随机场,在输入图像中增加了纹理信息,得到了比SVM 分类器更好的提取效果,但其网络结果中,输出层地物位置信息没有得到足够的保留。在DeepLab v2 网络的基础上,Chen 等(2018a)提出了Naïve-SCNN 和Deeper-SCNN 网络,并提出增强视场的方法,使用ISPRS的高分辨率语义分割数据集,成功提高了训练精度。Audebert等(2018)在SegNet等卷积神经网络基础上改进得到V-FuseNet网络,以利用更多通道数据,得到了很高的精度,当通道数有较大变化时,这种融合网络结构也会发生变化,有一定的局限性。
本文以DeepLab v3+网络模型为基础,针对高分辨率影像地物提取问题,提出E-DeepLab 网络模型。通过改变编码器和解码器的结合方式、增强编码器和解码器的连接、加入自适应权重以及进行多通道训练的多方面改进,以提高地物分类精度。
2 研究方案
2.1 E-DeepLab网络
本文在DeepLab v3+网络模型的基础上进行改进,得到E-DeepLab(Enhanced DeepLab)网络。DeepLab v3+是对多种网络模型中优秀结构的综合运用,如编码器—解码器(Encoder-Decoder)、空洞卷积、金字塔池等多种结构,其在常用数据集中展现了非常高的精度(Chen等,2018b)。
DeepLab v3+模型主要分为卷积部分、空洞空间金字塔池化模块(Atrous Spatial Pyramid Pooling)和解码器模块3 部分。(1)卷积部分是Xception 结构(Chollet,2017),本文使用的Xception 采用深度可分离卷积(Depthwise Separable Convolution)将卷积操作分成两部分进行:第一部分是深度可分卷积,对影像的每个通道分别进行卷积运算,第二部分是逐点卷积,使用跨通道的卷积来进行。该方法把三维的卷积分为了二维卷积和一维卷积的结合,以更好的获取信息。(2)为空洞空间金字塔池化模块(Atrous Spatial Pyramid Pooling),通过并行多尺度空洞卷积,获取多个尺度的特征信息(图1)。(3)为解码器模块,通过上采样得到地物的形状信息。先进行4倍上采样,再与相同位置编码器输出数据拼接,以增强空间信息。拼接结果再进行4倍上采样,得到输入图大小的结果。

图1 空洞空间金字塔池化示意图Fig.1 Schematic diagram of atrous spatial pyramid pooling
E-DeepLab主要改进在以下3个方面:
(1)改进编码器和解码器的结合方式。卷积神经网络编码器部分在逐步下采样的过程中,地物的轮廓信息也在逐渐损失,在解码器上采样时,轮廓信息难以足够保留,通过编码器和解码器结合,可以在上采样过程中还原更多的轮廓信息,提高提取和分类精度。本文改进的结构中采用类似LinkNet 网络模型中直接相连的方法,记为“E-Link”连接方法(图2)。原始方法首先将编码器输入和对应上一层解码器的输出通过C1过程进行拼接(contact),再通过C2过程卷积(convolution),得到下一个解码器层(图2)。而改进后的方法将有相同通道数的编码器层和解码器层直接求和加成,以保留更完整的空间信息。由于解码器每一层共享编码层的信息,两层连接后通道数不变,从而节约了参数数量,直接加成的方法也使所提取地物的位置、轮廓信息更完整地保留。
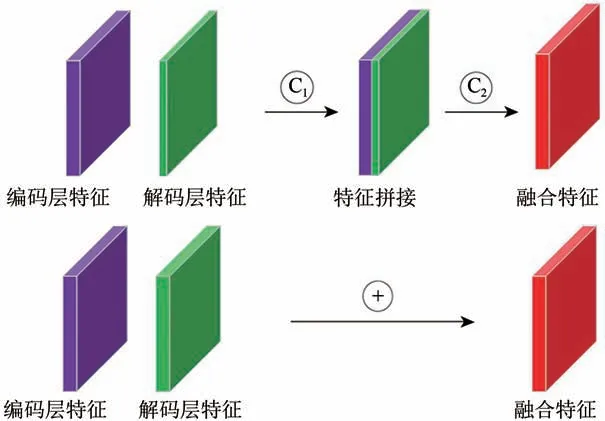
图2 编码器和解码器的结合方式示意图Fig.2 Schematic diagram of the combination of encoder and decoder
(2)缩小单次上采样倍数,增加上采样层,提高编码器与解码器连接的紧密性。与普通图片语义分割相比,遥感影像中地物分类对分类边界轮廓提取精度要求更高。原DeepLab v3+网络模型中,上采样2 次,编码器和解码器仅有1 次连接(图3(a)),虽然这种简单的解码器应用于日常图片有比较好的性能,但在应用于高分辨率遥感影像分类时,不能保留足够的地物地理位置信息以及轮廓信息。本文改进后每个编码器模块都与对应解码器相连,轮廓信息传递更密切。改进后的E-DeepLab 模型使用4 次2 倍上采样,同时编码器与解码器3 次连接(图3(b))。由于改用上文提到的“E-Link”连接方式,这里增强连接次数后,避免了使网络模型过于复杂。
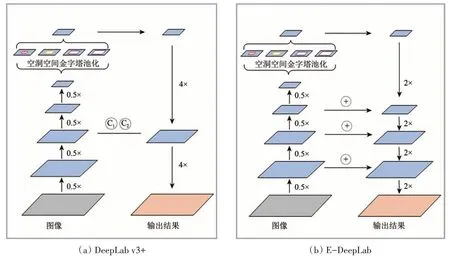
图3 网络结构对比图Fig.3 comparison of network structures
(3)自适应权重损失函数。研究以交叉熵损失函数为基础,结合改进的自适应权重算法,改善模型损失评估能力。交叉熵主要用于评估两个概率分布间的差异信息,可以理解为拟合时的信息熵与样本标注(真实值)的信息熵之间的差距,其表示为

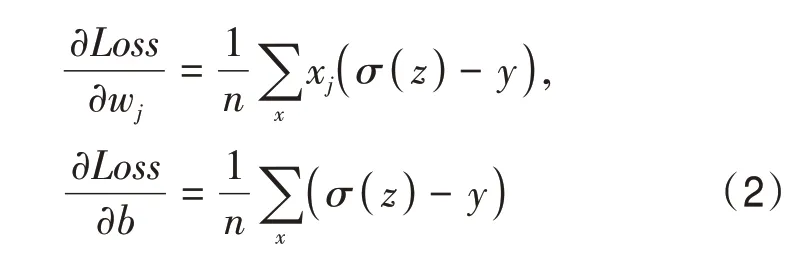
式中,

式中,Loss表示损失值,x表示样本,y表示实际值,即期望值,a表示输出值,n为样本数。则参数σ(z)-y表示输出的值和实际期望值之间的距离,当误差越大时,相应的梯度也就越大,参数w和b就调整得越快,由此可以使得训练速度加快。实际训练过程中,不断调整这些参数的大小以减少损失值,从而使网络得以优化。
由于地物尺度、数量等差异较大,因此使用相同权重损失函数时,由于类别的不平衡会影响网络对输出结果的判断。为解决类别不平衡的问题,ENet 中(Paszke 等,2016)使用了自适应权重的计算方法。本文对该方法加以改进,增加调节参数以使自适应权重函数更有灵活性。改进后类别权重函数定义:

式中,wclass表示不同类别的权重,Pclass表示该类样本所占的比例,α和β是两个超参数,用来调节权重参数函数的形状和值域。
综合以上3 方面改进,得到E-DeepLab 模型(图4)。“E-Block”表示“Encoder Block”,为编码器部分,“D-Block”表示“Decoder Block”,为解码器部分。
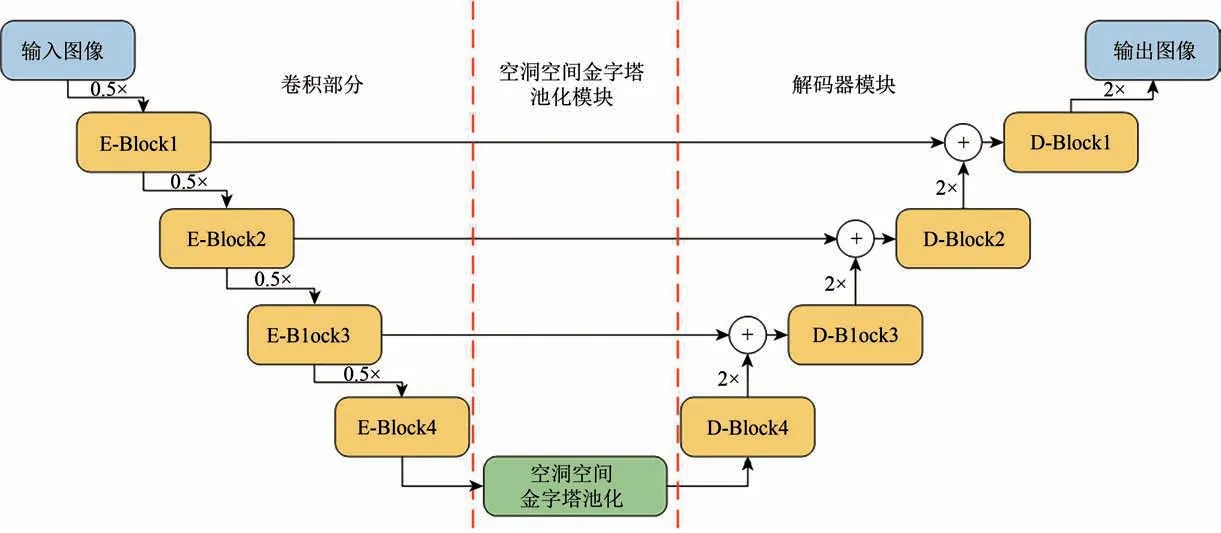
图4 E-DeepLab网络结构Fig.4 E-DeepLab network structure
2.2 多通道训练
为充分利用各波段数据,采用多通道训练的方法。区别于传统图片中的三通道,本研究区的数据中,包含近红外、红、绿、蓝波段的数据,以及标准化的DSM 数据。在此基础上,计算归一化植被指数NDVI,作为新的辅助通道,以更好地对植被进行识别和分类。

式中,RED 表示红波段值,NIR 表示近红外波段值,植被指数值越大则该位置像元是植被的概率越大。修改网络输入层,使其可以输入大于3个通道的数据,同时修改预训练模型,使其能够适应输入数据通道的变化。修改后的网络模型既可以满足多通道训练的需求,又可以利用预训练模型参数加速训练过程,提高训练精度。
3 实验与分析
3.1 研究数据集
研究数据采用ISPRS 影像分割挑战赛数据集,该数据集的影像是通过摄影测量得到的正射影像(http://www2.isprs.org/commissions.html[2019-06-18]),包含Potsdam 和Vaihingen 两个地区的数据(图5),Potsdam 数据所在区域位于德国东北部,有密集的街道和较大的建筑群,属于比较大型的城市,影像数据空间分辨率为0.05 m,包含近红外、红、绿、蓝波段和DSM 数据。而Vaihingen 数据集位于德国中部偏西南部,属于农村地区,有很多独立的小层建筑,影像数据空间分辨率为0.09 m,包含近红外、红、绿波段和DSM 数据。两个数据对应的地物复杂度、空间分辨率等方面存在较大差异,本文以这两个地区为研究对象,以验证模型在不同类型研究区域的适应性。数据集中包含遥感影像、DSM 数据及人工标记数据(图6),本文中将人工标记数据作为标准标记数据,认为是地表真实数据。

图5 研究区数据集示例Fig.5 Example of data set in the study area

图6 研究区数据集示例Fig.6 Example of data set in the study area
在该数据集的标注数据中,包含5 中常见地物:不透水地面、建筑、低矮植被、树、车辆。数据集中Potsdam 地区有24景带标记影像,Vaihingen 地区有16 景带标记影像,按6∶1 比例分为训练集和测试集,因此Potsdam地区20景影像用于训练,4 景影像用于测试,Vaihingen 地区13 景影像用于训练,3景影像用于测试。
3.2 深度学习环境搭建与数据预处理
本研究使用GPU(计算图形处理器)加速计算,显卡为NVIDIA GeForce TITAN X(Pascal),使用Windows10操作系统和Tensorflow深度学习框架。
对神经网络的样本数据首先进行标准化处理,再设置步长(待生成的训练样本尺寸)进行影像的规则分割。对于样本的标准数据,即地表真实值数据,其值在神经网络中直接作为标记数据,数据范围转为0—5,表示不同的地物类别,存储为单通道的灰度格式,作为输出期望输入到神经网络中。
3.3 精度评价指标
采用精确度(Precision)、召回率(Recall)和综合精度得分(F1)作为结果的评价指标,以样本标记为参考值,网络模型输出结果为预测值,实际和预测均为正类的像素记为TP,实际为负类,预测为正类的像素记为FP,实际为正类,预测为负类的像素记为FN。得到3个评价指标为

精确度表示提取正确的像素占所有预测结果的比值,召回率表示该地类提取正确的像素占所有标记像素的比值。综合精度得分F1 用来综合评估提取效果。根据数据提供者约定,本文精度评价使用去除边界3像素的方法。
3.4 结果与分析
实验设置初始学习率为0.01,考虑到两地区样本数量不同,Potsdam 地区样本迭代10万次,损失函数中α为1.05,β为0.4,Vaihingen 地物样本迭代5 万次,损失函数中α为1.01,β为0.4,分析两个不同类型地区主要地物分类结果。
为更好地对比模型,本文选择U-Net(Ronneberger 等,2015)和DABNet(Li 等,2019)两种网络模型对比参考。U-Net模型首先在医学领域提出,其网络结构简明,性能稳定,在遥感信息提取中也有着广泛应用。DABNet 模型是一个高效的语义分割网络模型,采用了空洞卷积、分解卷积等模型结构,有着很好的精度。对比模型时,E-DeepLab采用三通道模式和多通道模式。三通道默认为近红外、红、绿波段,Potsdam 地区六通道为近红外、红、绿、蓝、规范化DSM、NDVI 波段,Vaihingen 地区数据缺少蓝波段数据,因此为五通道,即近红外、红、绿、规范化DSM、NDVI波段。网络预训练模型使用在ImageNet 数据集(http://www.image-net.org[2019-06-18])上训练的模型,当通道数不等于3 时,读取部分预训练模型参数,当通道数等于3 时,读取全部预训练模型参数。
总体上,本文提出的E-DeepLab 模型体现了最高的分类精度,在两个地区具体精度体现略有不同(图7)。在Potsdam 地区,召回率略高于精确度和F1 分数,E-DeepLab 模型精度提升优势明显。其中,使用六通道数据的E-DeepLab 模型总体F1分数比原DeepLab v3+提高了5.4%,相比DABNet模型提高了5.9%(表1)。在Vaihingen 地区,各模型的3 个精度指标比较接近,E-DeepLab 模型也有着明显的优势,使用六通道数据的E-DeepLab模型总体分数比原DeepLab v3+提高了3.0%,比DABNet模型提高了2.7%(表2)。
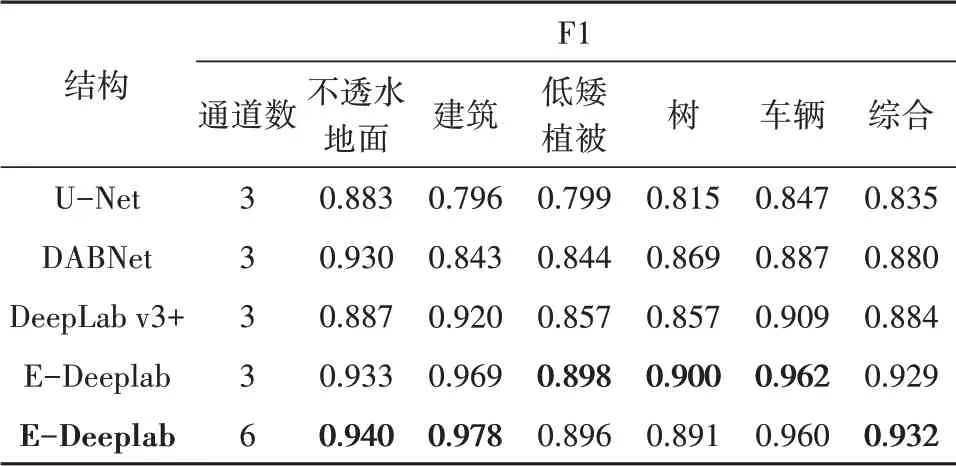
表1 Potsdam地区提取精度对比Table 1 Comparison of extraction accuracy in Potsdam area
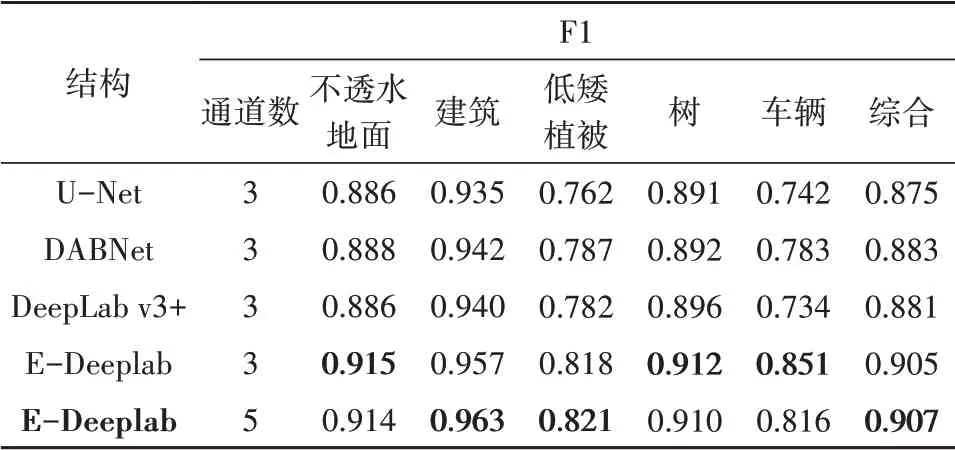
表2 Vaihingen地区提取精度对比Table 2 Comparison of extraction accuracy in Potsdam area
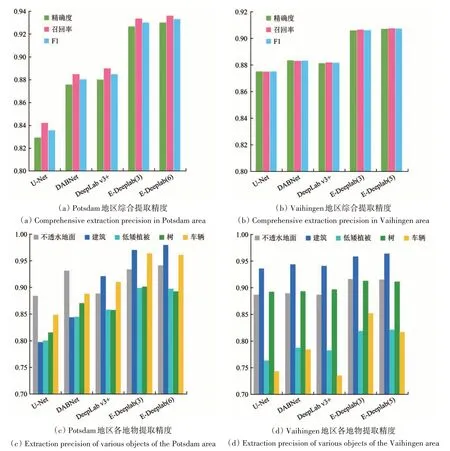
图7 两地区分类结果比较图Fig.7 Comparison of the classification results of the two regions
具体地物分类中,不同网络模型的效果也不相同。在Potsdam 地区,U-Net 和DABNet 模型不透水地面提取精度最高,其中DABNet 模型的不透水面提取精度已接近E-DeepLab 模型的精度,但其他地物提取精度较低。在DeepLab 网络的3 个模型中,建筑物提取精度最高,且E-DeepLab 模型中各地物提取精度均是最高的。但是,当通道数不同时,也体现出精度差异。其中,不透水地面和建筑使用六通道数据精度最高,而低矮植被、树、车辆等使用三通道数据精度最高。在Vaihingen 地区,由于样本量较少,不同地物分类精度差异较大。各模型均是建筑物提取精度最高。其中,建筑和低矮植被使用五通道数据精度最高,不透水地面、树、车辆等使用三通道数据精度最高。因此对于E-DeepLab 模型,三通道和更多通道对于不同地物互有优势,但从综合精度看,使用更多通道的方法精度更高。
对具体示例分析,在Potsdam 地区图8(a)中,右上角建筑物部分E-DeepLab 三通道方法更接近真实值,左下角不透水面部分E-DeepLab 六通道方法更接近真实值。图8(b)和图8(c)中,E-DeepLab 网络提取建筑物区域与标准图最接近,明显优于其他算法,且对于不透水面和树的提取,E-DeepLab 也体现了很好的分类结果。图8(d)中,建筑物凸起部分,E-DeepLab 三通道方法比六通道略好。在Potsdam 地区总体上E-DeepLab 网络体现了最好的分类性能。
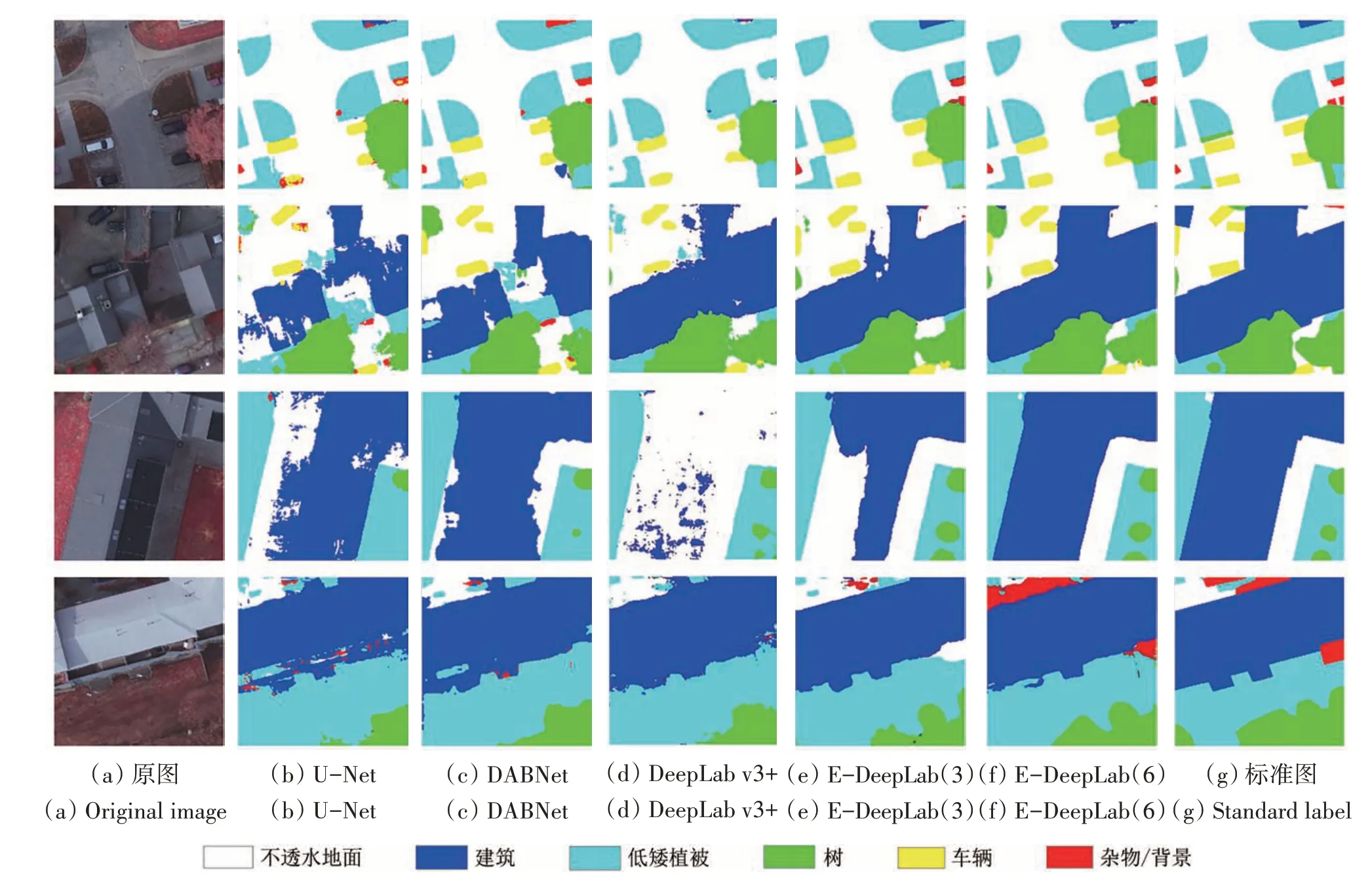
图8 Potsdam地区各地物提取结果Fig.8 Extraction results of various land cover types in the Potsdam
在Vaihingen 地区图9(a)中E-DeepLab 六通道方法在中部低矮植被和左下角建筑物的分类轮廓均优于其他方法。图9(b)中右下角部分影像地物复杂,E-DeepLab 六通道方法提取效果最好。右侧中部低矮植被和树的区分,E-DeepLab六通道方法也有更好的识别能力,其他模型无法识别出高大树木周围的低矮植被。图9(c)中右上部分建筑物的识别,E-DeepLab六通道方法最接近标准图,左侧中部低矮植被的识别也由于其他模型。图9(d)中E-DeepLab 六通道提取车辆中有两个车辆没有分开,三通道结果更好,但对于建筑物的分类,E-DeepLab六通道方法的结果最接近标准图。整体上,E-DeepLab 算法有最好的分类效果,其中六通道方法有比三通道方法更优的综合性能,分类结果与标准结果具有高度一致性。
4 结论
本研究以DeepLab v3+为基础,针对高分辨率影像地物提取问题,提出E-DeepLab 算法。通过(1)改变编码器和解码器的结合方式(2)增强编码器和解码器的连接(3)加入自适应权重损失函数(4)结合DSM 和NDVI 的多通道训练等多方面改进,在两个地区进行实验,有效提高高分辨率影像中地物分类精度。结果表明,本文提出的学习框架在高分辨率影像地物分类方面达到了较高的精度,在Potsdam 地区和Vaihingen 地区,相对于原始DeepLab v3+算法精度分别提高了5.4%和3.0%,总体提取精度分别为93.2%、90.7%,建筑物提取精度分别达到了97.8%、96.3%,体现了算法在不同研究区的适应性和健壮性。
