Sentiment Lexicon Construction Based on Improved Left-Right Entropy Algorithm
2022-03-08YUShoujian于守健WANGBaoying王保英LUTing
YU Shoujian(于守健), WANG Baoying(王保英), LU Ting (卢 婷)
College of Computer Science and Technology, Donghua University, Shanghai 201620, China
Abstract: A novel method of constructing sentiment lexicon of new words (SLNW) is proposed to realize effective Weibo sentiment analysis by integrating existing lexicons of sentiments, lexicons of degree, negation and network. Based on left-right entropy and mutual information (MI) neologism discovery algorithms, this new algorithm divides N-gram to obtain strings dynamically instead of relying on fixed sliding window when using Trie as data structure. The sentiment-oriented point mutual information (SO-PMI) algorithm with Laplacian smoothing is used to distinguish sentiment tendency of new words found in the data set to form SLNW by putting new words to basic sentiment lexicon. Experiments show that the sentiment analysis based on SLNW performs better than others. Precision, recall and F-measure are improved in both topic and non-topic Weibo data sets.
Key words: sentiment lexicon; new word discovery; left-right entropy; sentiment analysis; point mutual information (PMI)
Introduction
The sentiment analysis is defined as the computational treatment of opinions, sentiments and subjectivity in a text, which is often used in recommendation[1-2]and stock price prediction[3]. The increasing popularity of Weibo has brought new challenges to sentiment analysis. Massive data has generated new words that have spread from user to user, such as “宅经济(stay at home economic)”, which refers to the economy that occurs at home specifically, including consumption and work. Internet popular words may be expressed in traditional characters, but they have different meanings, such as “肿么办(how to do it)” and “康康(look)”, which make sentiment analysis more difficult.
The methods of sentiment analysis are divided into rule-based, machine learning-based and deep learning-based. The sentiment analysis based on machine learning mostly adopts a supervised framework[4-5], in which a large number of sentences with labels to train the model. However, labels are difficult to obtain, which brings great limitations to relevant research. For studies on weak supervision[6-7]or remote supervision, they rely on external resources (synonym sets[8]and syntactic structures) heavily. Zhuangetal.[9]proposed the development of sentence-level sentiment analysis guided by a minimum of users and captured aspect specific sentiment words by combining the autoencoder and the lexicon. However, this method was far inferior to the performance shown by the sentiment lexicon in terms of sentiment analysis of Weibo. Zhaoetal.[10]integrated features into deep convolutional neural network based on contextual semantic features and co-occurrence statistical features of the words in Twitter, and usedN-gram to train and predict sentiment classification tags, which required a higher quality of corpus tags. This paper mainly conducts sentiment analysis on content of Weibo. In order to better identify new words, sentiment lexicon is used for sentiment analysis. However, the main language of Weibo is Chinese that has multiple meanings in terms of grammatical structure and syntactic rules. Sentiment lexicon of Twitter cannot be applied to Weibo directly. Therefore, it’s necessary to have a more comprehensive method to build a sentiment lexicon.
This paper is organized as follows. Section 1 summarizes current research work of sentiment lexicon. Section 2 describes the method of constructing sentiment lexicon and the improvement of left-right entropy algorithm. Section 3 elaborates the experimental results on two different data sets. Finally, section 4 shows conclusions and future work.
1 Related Work
Researches have contributed two main methods for creating sentiment lexicons, namely manual creation and automatic creation[11]. The manual method is the most reliable and straightforward because each sentiment value of a term is determined by experts, but they drain on manpower. Automatic method can save human cost, but there are some problems such as the low word coverage and the poor stability. This paper aims to automatically acquire new words and integrate them with the basic sentiment lexicon constructed manually to generate a more comprehensive sentiment lexicon of new words.
More mature English lexicons include General Inquirer created by Harvard University, SentiWordNet,etc. Esuli and Sebastiani[12]constructed a new sentiment lexicon SentiWordNet based on synset of WordNet, but the coverage of its lexicon varied in different fields and its recognition was relatively low. Alharbi and Alhalabi[13]introduced a problem that used stock market as reference domain to extract polarity lexicon automatically in a completely automated way without interference from context, scale and threshold. However, this paper didn’t include other part of speech labels. Zerroukietal.[14]introduced application of k-nearest neighbor (KNN), Bayes and decision tree in social network sentiment analysis in detail, but it didn’t clarify its effectiveness in Weibo.
The main resources that can be applied are HowNet, national Taiwan University sentiment dictionary (NTUSD) in China, and sentiment lexicon compiled by LI Jun of Tsinghua University(TSING)[15]. Yangetal.[16]segmented words into multiple semantic elements, calculated the intensity of their sentiment inclination, and constructed a sentiment lexicon based on HowNet and SentiWordNet. Wangetal.[17]integrated HowNet with point mutual information (PMI) similarity, but its word coverage was not suitable for Weibo. Liuetal.[18]proposed a method of extracting new sentiment words from Weibo based on multi-character mutual information (MI) and sentiment similarity between words. In addition, lexicons rely on the variety and accuracy of new words, and researches often find new words by method of machine learning-based in texts. Lietal.[19]proposed an algorithm of new words discovery based on internal solidification and frequency of multiple characters aboutN-gram. This method used Trie as the data structure, but there was still the problem of fixed sliding window dependency.
The accuracy of sentiment analysis based on machine learning is high, but it depends on the quality of training set which has been labeled with positive and negative sentiment tendency, which affects stability of correctly identifying sentiment tendency. Lexicon-based sentiment analysis has high stability, but incomplete lexicons tend to lead to low accuracy because they are highly dependent on external resources. Therefore, the sentiment lexicon of new words (SLNW) is constructed by combining the above two methods in this work. The left-right entropy algorithm is changed to improve dependency of fixed sliding window. New words are found from data sets, and the sentiment-oriented point mutual information (SO-PMI) algorithm with Laplacian smoothing is used to classify sentiment tendency of new words. Comparative experiment indicates the superiority of SLNW.
2 Construction of SLNW
Constructing a high-quality sentiment lexicon is the key of textual sentiment analysis. The existing sentiment lexicons such as HowNet and NTUSD are formal and not comprehensive enough to correctly analyze new words, which leads to declining in the accuracy of text sentiment analysis. In order to construct a sentiment lexicon with a wider coverage, SLNW is established by utilizing a basic sentiment lexicon and using the improved left-right entropy new word discovery algorithm to find new words.
2.1 Construction of basic sentiment lexicon
As mentioned above, this paper incorporates some sentiment lexicons. Duplicate words are removed and the basic sentiment lexicon is obtained with the weight set to 1. The basic sentiment lexicon is shown in Table 1.

Table 1 Basic sentiment lexicon
2.2 Lexicons of adverbs and internet terms
This paper summarizes the used negative words commonly and sets the weight as -1. Among the grammatical rules, polarity and position of degree adverbs have a great influence on semantic meaning of sentences. There are 219 degree-level words in HowNet which are given different weights according to the intensity of part of speech. In addition, internet buzzwords emerge in an endless stream every year. Therefore, network sentiment lexicon established in this paper is derived from the popular word set of the same year provided by Sogou input method. This work marks sentiment polarity of network sentiment lexicon that contains 30 positive words and 67 negative words respectively, and puts them in basic sentiment lexicon constructed in section 2.1. For neutral network terms, this paper puts them in user lexicon to optimize accuracy of word segmentation.
2.3 MI and left-right entropy
MI algorithm belongs to information theory, also known as internal cohesion. Binary MI represents degree of correlation between two things. For random variablesxandy, MI represents the amount of information shared between two variables denoted asIM(x,y), shown as
(1)
wherep(x)p(y) represents the probability of two words appearing in training corpus respectively, andp(x,y) represents the probability of wordsxandyappearing in training corpus at the same time. In sentiment analysis, the most common use of MI is PMI which mainly represents correlation degree between two independent words. The definition of PMI between points is shown as
(2)
whereIPM(x,y) represents the value of PMI; the greater the value ofIPM(x,y), the greater the probability that two wordsxandyappear together. The algorithm can also be derived to calculate sentiment tendency of candidate words. In sentiment analysis research, there arenpositive sentiment seed wordsPD={p1,p2,…,pn}, andmnegative sentiment seed wordsND={n1,n2,…,nm}. In order to determine sentiment tendency of sentiment candidate wordCi(i=1,2,…), Eq. (2) can be used for calculation to obtain the algorithm of SO-PMI.
Entropy is an indicator representing the amount of information. Higher entropy means larger information content and higher uncertainty[20]. The entropy of random variableXcan be expressed as
(3)
wherep(x) represents probability thatXis denoted asx.
Because the entropy contains information, the values of left-right entropy are often calculated in the study of new word discovery to know whether the word has rich collocation. When two words reach a certain threshold, they can be considered as a new word to expand word quantity. Therefore, left-right entropy is often referred to as external degree of freedom. The calculation formulas of left entropy and right entropy are shown as
(4)
(5)
whereWrepresents word string ofN-gram.Arepresents the set of all words that appear on the left side of the word string, andarepresents a certain word that appears on the left. Similarly,Bandbrepresent the set of words and a certain word on the right respectively.P(aW|W) represents conditional probability that the left adjacency isawhen the candidate wordWappears. If the number ofELandERin the string is higher, that is, the more words around the wordW, the more likelyWis to be a complete multi-word expression. A threshold is specified in the process of finding new words in this paper. In Eqs. (4)-(5), ifEL(W) is greater than the threshold, the left boundary is determined; ifER(W) is greater than the threshold, the right boundary is determined.
Among two words “辈子(lifetime)” and “被子(quilt)” with large MI values, “quilt” commonly used “盖被子(cover with quilt)”, “叠被子(make the bed)”, “新被子(new quilt)” and so on, and the left word has many different words. As the value of left entropy increases, the ability to form independent words becomes stronger. For “lifetime”, the general usage has “一辈子(a one’s life)”, “这辈子(this lifetime)”, “上辈子(previous life)” and so on. The possibility of the left side is small, the ability of the word to be independently formed is weak, and it is true that “辈子(lifetime)” is used as a separate word rarely in ordinary times. Combining MI between words and left-right entropy, accuracy of word-formation will be improved significantly because it not only ensures the cohesion between two words, but also verifies the possibility of external word formation.
2.4 Improvements of left-right entropy algorithm
The reason why a word becomes a word comes from its rich external context and intensity of internal cohesion. In the study of new word discovery algorithm in this paper, PMI algorithm adopts probability calculation method to solve the correlation degree greatly when two mutually independent transactions appear at the same time. However, traditional left-right entropy segmentation algorithm is based on the hash algorithm in general. When obtaining the prefix of word segmentation, a large number of word segmentation texts will bring pressure to the algorithm. However, for the algorithm using Trie as data structure, different values will be used to limit length of candidate words inN-gram calculation, which results in frequent manual changes and poor applicability.
In order to solve the problems mentioned above, this paper improves the left-right entropy new word discovery algorithm based on Trie. Trie stores key-value pair types and the value is string usually. String obtained after word segmentation is denoted ass, the set of left-neighbor string isL={l1,l2,…,ln}, and the set of right adjacency string isR={r1,r2, …,rm}.FL(li,s)(i=1, 2, …,n) is the number of occurrences of the left stringSli,s(i=1, 2, …,n) in the texts. Similarly, right string is denoted asFR(s,rj)(j=1, 2, …,m). In order to better associate left and right strings during subsequent synthesis of new words to perform recursive operations, this paper writesLs, rj(s,rj) as the stringSs,rj(j=1, 2, …,m) left-neighbor string set, andRli,s(li,s) is the set of stringSli,s(i=1, 2, …,n) right adjacent to the string. According to Eqs. (4)-(5), the left information entropy of stringscan be changed to
(6)
The right information entropy of stringsis
(7)
And
(8)
2.5 Classification of neologism tendency
SO-PMI algorithm (shown in Eq. (9)) with Laplacian smoothing is adopted to identify sentiment tendency of new words obtained in the above operations. When selecting seed benchmark words used by the SO-PMI algorithm, words with the higher term frequency (TF) value are preferred as candidate benchmark words. Traversing cyclically in the positive and negative words of sentiment lexicon, benchmark words in the existing sentiment lexicon are used as seed words first. Combined with SO-PMI, this work divides new words into positive, neutral, and negative tendencies, and adds them to the comprehensive sentiment lexicon constructed in section 2.1.
(9)
whereISOPM(ci) represents the value of SO-PMI on candidate wordci.c(ci,pj) andc(ci,rj) represent the number of simultaneous occurrences with positive and negative sentiment seed words, respectively.
3 Experiments and Analyses
3.1 Data set preprocessing and experimental environment
Weibo topic and non-topic data sets from Chinese software developer network are used in this work. Weibo topic data set mainly include five themes of Mengniu, mobile phone, basketball, football game and genetic modification. There are 40 000 comments in total with 4 000 positive and negative comments on each topic. For non-topic data sets, there are 30 000 non-topic positive and negative sentiment comments on Weibo, totaling 60 000. Two data sets are preprocessed separately, including removing numbers, emoticons, and stop words.
Hardware experimental environment of this paper is as follows. The process is Intel (R) Core (TM) i7-7700 CPU @ 3.60 GHz. The memory size is 32 GB and the hard disk capacity is 1 T. Software experiment environment is Python 3.6 version and code is run in Python language.
To evaluate performance of SLNW on two data sets separately, this paper adopts the idea of Duetal.[21]to construct a sentiment lexicon on data sets of Weibo topic and non-topic as a comparative experiment respectively. Traditional domain sentiment lexicons refer to those constructed under specific themes, such as news data set and movies data set. Based on the topic data set of Weibo, this paper constructs a domain sentiment lexicon. In order to explore effectiveness of SLNW compared with sentiment analysis based on machine learning methods, this paper adopts KNN and Bayes[14]as methods about sentiment classification of text to carry out comparative experiments.
3.2 Evaluation index
The confusion matrix between predicted category and actual category is denoted in Table 2.
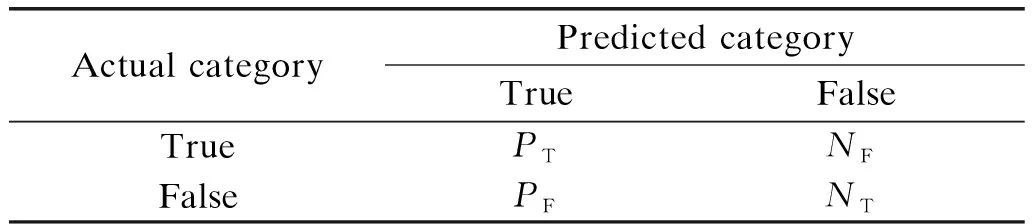
Table 2 Confusion matrix of sentiment classification
This analysis of Weibo belongs to text classification, which in turn belongs to the field of natural language processing (NLP). Therefore, evaluation indexes in this paper are still precision (P), recall (R) and comprehensive measurement (F-measure,F1) in NLP. Relevant formulas are
(10)
In order to distinguish performance of positive and negative tendency, evaluation indexes are refined. For texts in positive,PP,RP, andF1Pare used to representP,R, andF1. Similarly,PN,RNandF1Nare used to representP,R, andF1of negative texts.
The performance of SLNW will be verified on data sets obtained from Weibo topic and non-topic comments.
3.3 Experimental results and discussion
SLNW performance evaluation is conducted on topic and non-topic Weibo data set respectively. In particular, the improved left-right entropy algorithm is used to find new words on topic and non-topic data set respectively, and new words are integrated into basic sentiment lexicon according to the data set separately, so that each data set has a specific and distinctive lexicon named SLNW.
3.3.1Weibotopicdataset
Based on sentiment lexicon classification method, 40 000 Weibo data are preprocessed according to the operations in section 3.1, and 3 786 new words are obtained under the specific threshold filtering. Combined with the SO-PMI algorithm, SLNW corresponding to the data set is expanded. Experiments of sentiment lexicon are carried out with 4 000 positive and negative comments respectively, and the lexicon adopts chi-square feature selection to realize sentiment polarity analysis. In the contrast experiment based on KNN (k=1, 3, 5, 7, 9, 11, 13) and based on Bayes, the ratio between positive and negative about test set and training set is guaranteed to be 4∶1, that is, 16 000 training comments and 4 000 test comments are tested for positive and negative texts respectively. The comparison results are shown in Table 3.

Table 3 Results of sentiment tendency classification on topic texts
It can be seen from Table 3 that SLNW can improve precision, recall andF-measure of positive and negative comments, and is better than sentiment lexicon constructed by SO-PMI. This comparative experiment reduces the influence of SO-PMI algorithm on dividing sentiment tendency of new words, and shows the effectiveness of the improved left-right entropy algorithm. It can be seen that performance of SLNW is improved by 0.33%-2.04% compared with lexicon constructed by SO-PMI. The Bayes algorithm with good scalability is simple and efficient. In this experiment, performance of Bayes is the best in terms of positive recall which is 0.63% higher than SLNW, but it determines classification through the priori and the data to determine the posterior probability, so there is a certain error in the classification decision. KNN has the worst performance in comparison experiments. The large amount of Weibo comments and unbalanced samples result in decrease of prediction speed and precision on KNN.
3.3.2Weibonon-topicdataset
Considering the widespread use of Weibo platform, the above experiment has unbalanced corpus on Weibo topics and limitations in analyzing sentiment polarity of Weibo non-topic comments. Therefore, this experiment adopts statements marked polarity of Weibo non-topic review 60 000 data, and the same operation on the data set in section 3.3.1 is performed to obtain 2 651 new words which are expanded to obtain SLNW. In the experiments based on sentiment lexicon, the test data set has 6 000 positive comments and negative comments respectively, and the ratio between training set and test set based on KNN and Bayes is 4∶1. Results of the comparative experiment are shown in Table 4.

Table 4 Results of sentiment tendency classification on non-topic texts
It can be seen from Table 4 that precision, recall andF-measure of the four experimental methods are reduced compared with the topic-based Weibo comments in both chaotic and irregular Weibo non-topic comments, but SLNW still performs better than others, and indexes are improved by 0.33%-0.65%. The lexicon constructed based on SO-PMI algorithm is partial to the domain, and performance is poor in non-topic comments. KNN algorithm still shows poor performance under large number of Weibo texts, and Bayes-based algorithm is more stable.
In order to verify performance of SLNW in different numbers of Weibo comment texts, this paper conducts experiments on test data with the number of 2 000, 3 000, 4 000 and 5 000 respectively, and keeps the ratio of training set to test set with 4∶1. Combined with experimental results of the above 6 000 items, changes of recall for the four methods under non-topic data sets are shown in Fig. 1.

Fig. 1 Recall under non-topic texts changes with the number of test set
As can be seen from Fig. 1, recall of the four methods increases accordingly with the number of Weibo comment texts. Recall based on SLNW is always higher than that of Bayes, with a difference of 0.03%-0.12%. Recall of lexicon constructed by SO-PMI algorithm is inferior to that of Bayes algorithm because it lacks a domain lexicon, but at the same time it is always higher than KNN for sentiment classification. With the support of a large number of texts, performance of KNN has gradually become weak, and recall is at a stable level.
Based on the above experiments, the performance of sentiment analysis based on SLNW is better than the other three comparative experiments, which proves that sentiment lexicon incorporating new words can improve precision of sentiment analysis, and further proves effectiveness of the improved left-right entropy algorithm.
4 Conclusions
This article integrates authoritative sentiment lexicons, adds lexicons of negative words and degree adverbs in combination with Chinese grammar rules to construct a basic sentiment lexicon. Based on left-right entropy and MI neologism discovery algorithm, this new algorithm dividesN-gram to obtain strings dynamically instead of relying on fixed sliding window when using Trie as the data structure, which expands the diversity of words. For text preprocessing, improved left-right entropy algorithm is used for new word extraction. Combined with SO-PMI algorithm, the novel algorithm expands basic sentiment lexicon to form SLNW. Experiments have testified the validity of SLNW.
Despite the improved algorithm for finding new words is proposed, with the increase of massive data, the coverage of SLNW for Weibo content is gradually decreasing. In addition, SLNW has low generality in other data sets because it is built on the Weibo data set. Further research work will focus on applying sentiment analysis technology to recommendation systems by analyzing sentiment tendency of users’ comment.
杂志排行

Journal of Donghua University(English Edition)的其它文章
- Diradical Character and Controllable Magnetic Properties in Chitin Through Radical Modification
- Recombinant Pyriform Spider Silk Expression and Wet-Spinning
- Experimental Study on Grinding Force of Electrostatic Coated Grinding Wheel
- Influence of Three Sizes of Sliding Windows on Principle Component Analysis Fault Detection of Air Conditioning Systems
- Consensus for High-Order Linear Multi-Agent Systems with Unknown but Bounded Measurement Noises
- Preparation of Polyaniline/Cellulose Nanofiber Aerogel for Efficient Removal of Cr(VI) from Aqueous Solution