基于混合分布时间序列的K-GRU建模
2022-03-07吴维芝施三支
吴维芝,施三支
(长春理工大学 数学与统计学院,长春 130022)
在实际生活中,无时无刻不在产生具有混合分布的时间序列数据。这些数据通常具有复杂的特性,如非平稳性和周期性等,还包含大量的隐含信息和一定的变化规律。因此,挖掘和分析混合分布时间序列中的有效信息,对日常生活和生产活动等具有十分重大的意义。
处理该类时间序列数据问题的方法多种多样,如Zhangyulai等人[1]提出了一种新的非平稳时间序列建模优化算法,该算法采用移动窗口和指数衰减权值来消除历史梯度的影响,能够保证算法的收敛性。杨楠等人[2]采用混合高斯分布对时间序列数据进行建模,得到的模型具有较高的精度和泛化性能。Grunwald等人[3]使用马尔科夫链建立和估计混合分布变量时间序列。Guo等人[4]提出了一种低维中期混沌时间序列预测的延迟参数化方法,具有较高的预测效果。阚子良等人[5]基于优化机器学习使用遗传算法优化参数,对股价时间序列数据进行预测,该方法预测精度高且泛化能力好、鲁棒性强。Shao等人[6]提出了LSTM神经网络对具有非平稳性的街边停车位占用率数据进行预测,该方法优于现有的预测方法。谷丽琼等人[7]提出了基于Attention机制的GRU神经网络并应用于非线性波动的股票数据,结果表明该方法的预测优化是可行和有效的。上述方法尽管都能较为准确的对未来时刻的行为作出预测,但无法克服数据波动对预测效果带来的负面影响。本文提出了一种K-均值聚类与GRU神经网络相结合的模型——K-GRU模型,通过K-均值聚类处理能够降低据波动导致的时间序列内部差异,有利于GRU神经网络更好地作出预测。
本文对不同分布下构造的时间序列进行了仿真实验。通过不同场景中的仿真实验得到预测误差,再与多项式模型、傅里叶序列、LSTM模型和GRU模型进行比较,仿真结果表明本文所提的K-GRU混合模型具有较高的预测精度,最后将K-GRU混合模型应用于街边停车位占用率预测。
1 K-GRU混合模型
本节介绍了K-GRU混合模型相关的理论知识,并给出了算法步骤。
1.1 GRU神经网络
GRU是LSTM网络的一种效果很好的变体。它和LSTM一样具有门控循环单元,而GRU神经网络仅需要两个门控循环单元即可解决梯度消失和梯度爆炸的问题。因此,它比LSTM网络的结构更加简单,而且训练速度也更快。具体结构如图1所示。
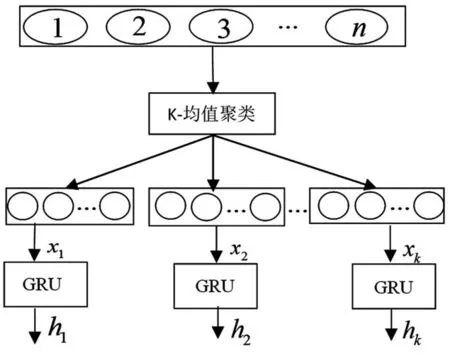
图1 GRU模型结构图
在GRU模型中只有两个门,分别是重置门rt和更新门zt。重置门控制前一时刻状态有多少信息被写入到当前的候选集上,重置门越小,前一状态的信息被写入的越少。更新门由LSTM中的遗忘门和输入门结合而成,更新门的作用是控制前一时刻的隐藏状态信息被转移到当前状态中的程度,更新门的值越大说明前一时刻的状态信息转入越多,相反,更新门越小,前一状态的信息被转入得越少。


其中,w、u、wr、ur、wz、uz为神经网络权值;t为时间步长;xt为输入值;ℎt为输出值;⊙为不同矩阵的Hadamard积;yt为当前时刻输出值。
1.2 基于聚类的K-GRU混合模型
聚类是数据挖掘和分析的主要研究领域之一。常用的聚类方法有K-均值聚类[8-9]、层次聚类[10-11]、SOM 聚类[12-13]等。
K-均值聚类算法由于在处理大量数据方面的简单性和速度而在以前的研究中被认为是一种广泛使用的聚类算法[14],因此本文采用K-均值对混合分布的时间序列数据进行聚类。通过K-均值聚类可以把较长的时间序列按K个初始聚类中心进行聚类,将原本单个的时间序列聚为K个序列,达到降低序列内部差异的效果。K-均值算法需要计算各个样本点到中心点的距离,常用的距离为欧氏距离,计算公式如下:

基于聚类的GRU混合模型的结构图,如图2所示。

图2 基于聚类的K-GRU混合模型
具体步骤如下:
(1)数据采集和数据预处理。可通过计算机语言生成模拟实验数据或数据网站下载相关数据。然后进行数据清洗、删除或补齐缺失值、归一化等。
(2)K-均值聚类。使用K-均值对步骤(1)中得到的数据进行聚类。
(3)划分样本。对每个类都进行训练集与测试集的划分,划分比例为8∶2。
(4)GRU神经网络训练。使用划分好的训练集进行神经网络的训练。
①第一层为GRU层,设置输入维度、输出维度和 return_sequences、return_sequences为 False,返回单个时间步长的隐藏状态的值,若为True,则返回全部的隐藏状态值。
②设置Dropout即随机失活率,Dropout是在训练过程中随机地忽略一些神经元,它会删除一些节点,以及网络与被删除节点之间的连接。
③第二层为GRU层,输入维度即为上一层的输出维度,设置return_sequences以及Dropout的取值。
④第三层是全连接层Dense层,网络训练的损失函数选择均方误差,选择优化器rmsprop。
(5)输入测试样本进行测试。
(6)计算并输出预测误差。通过对神经网络参数的调整,以达到误差最小。
本文的算法流程如图3所示。
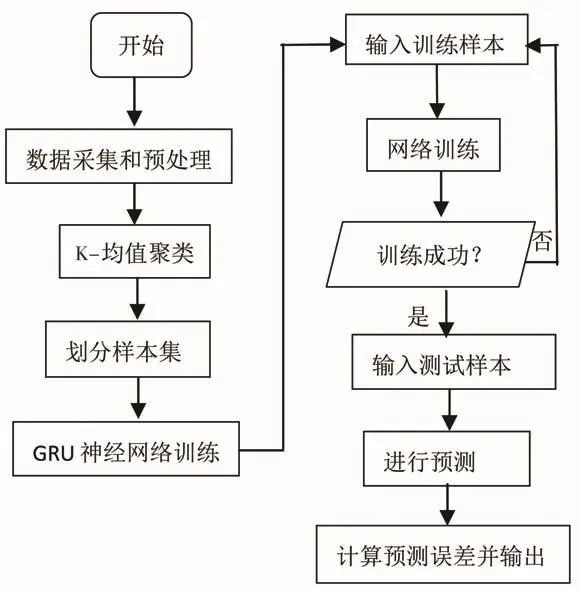
图3 算法流程图
2 仿真实验
为评价模型的性能,利用随机生成的数据进行了一系列的模拟实验。在python3.7环境下使用tensorflow2.0训练预测模型,实验计算机的物理核心为8核,逻辑核心为4核,显存大小为2 G,内存为32 G,储存空间为1 T。
2.1 评价标准
为了便于比较不同方法在占用率预测实验中的表现,使用平均绝对误差(Mean absolute error,MAE)和均方误差(Mean squared error,MSE)来描述实验误差。
平均绝对误差(Mean absolute error,MAE):

均方误差(Mean squared error,MSE):


2.2 仿真实验及分析
本节分别在三个场景中比较了多项式模型、傅里叶变换、LSTM模型、GRU模型与GRU混合模型的预测效果。设置样本量为n=5 369,其中场景A表示由数据量为5∶2的两个时间序列数据构成,分布分别为N~(0.3,0.1)和N~(0.2,0.09);场景B表示由数据量为5∶2的两个时间序列数据构成,分布分别为 N~(0.3,0.1)和 Be~(0.19,0.66);场景C表示生成均值为0.25,标准差分别为0.1~0.5的正态分布。模拟实验数据均使用R语言生成。
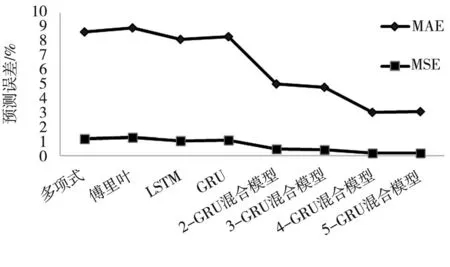
图4 场景A各方法预测误差比较
表1为场景A中各方法预测误差的具体数值,可以看出多项式模型、傅里叶序列、LSTM模型和GRU模型的预测效果几乎一致,K-GRU混合模型预测效果明显优于前面四种方法。KGRU混合模型在聚类数为4时,MAE和MSE都降到最低,分别为3.008%和0.170%,而当聚类数为5时,MAE和MSE都比聚类数为4时的MAE和MSE稍大。通过图6也可以看出,K-GRU混合模型的预测效果显著优于前面四种方法(标注*的数字为最佳预测结果)。

表1 场景A各方法预测误差
表2为场景B中各方法预测误差的具体数值,可以看出多项式模型、傅里叶序列、LSTM模型和GRU模型的预测效果几乎一致,K-GRU混合模型预测效果明显优于前面四种方法。K-GRU混合模型随着聚类数增加,MAE和MSE都在下降,但聚类数为5时,MAE和MSE的下降幅度明显变小。通过图5也可以看出,K-GRU混合模型的预测效果显著优于前面四种方法,且聚类数为5时,误差下降幅度明显减缓(标注*的数字为最佳预测结果)。

表2 场景B各方法预测误差
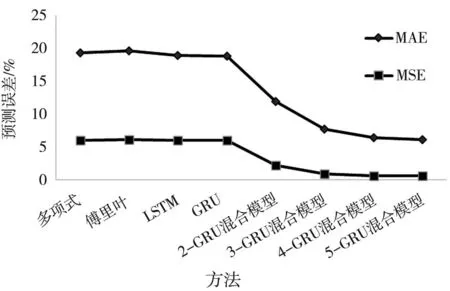
图5 场景B各方法预测误差比较
图 6(a)和图 6(b)分别为场景C中各方法预测的MAE和MSE,可以看出在样本量固定的情况下,随着标准差的增加,并未对预测结果的MAE和MSE造成较大的波动,说明预测模型具有鲁棒性。K-GRU混合模型在聚为2类、3类、4类和5类的情况下都比多项式模型、傅里叶序列、LSTM模型和GRU模型的预测效果更好,随着聚类数的增加,K-GRU混合模型的MAE和MSE的下降幅度变缓。
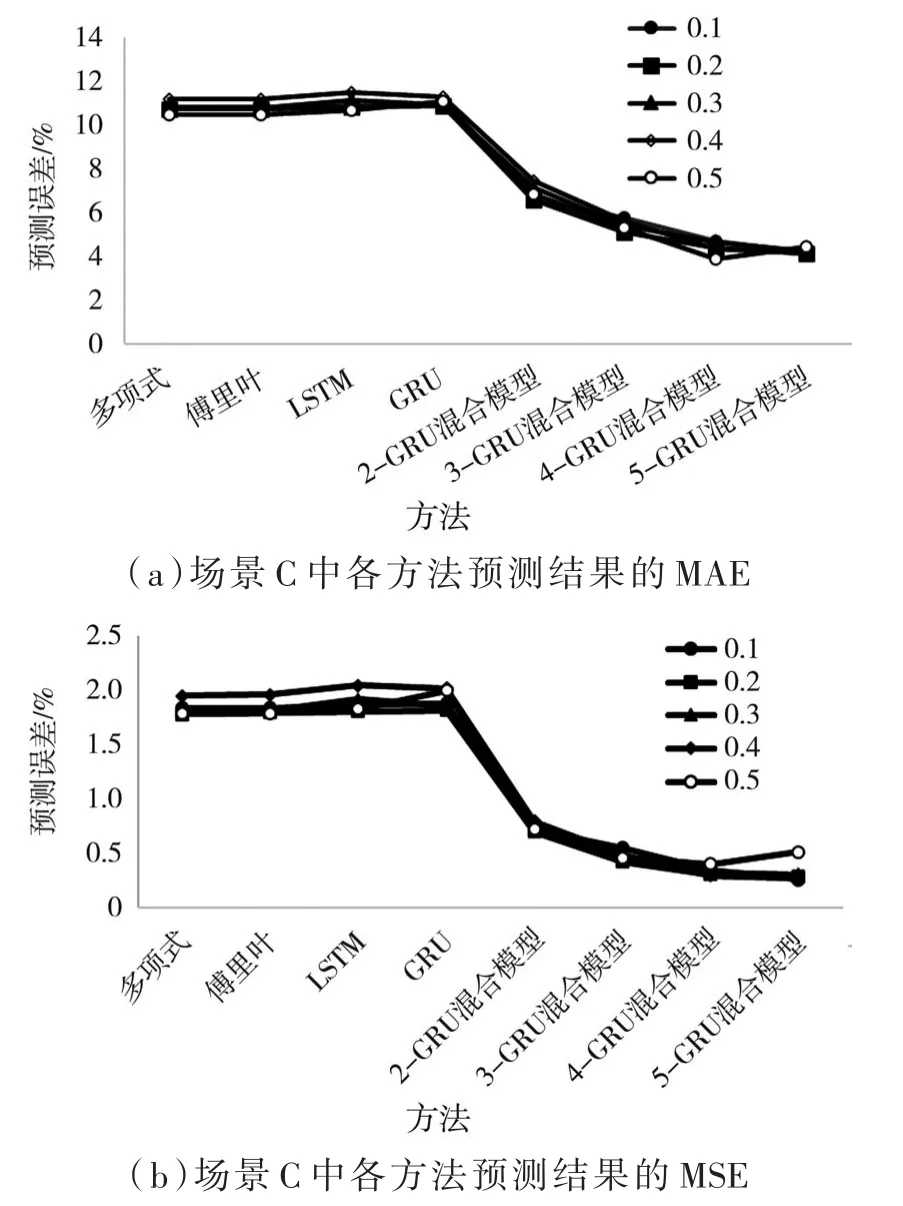
图6 场景C中各方法预测的MAE及MSE
3 实证分析
本文使用的数据是2018年12月1日到2019年2月28日深圳市南山区招商路90天的历史街边停车数据。在该数据集中,记录到招商路总共59个有效停车位,共计18 899条停车记录。图7是招商路的地理位置及街边实景图。

图7 招商路百度地图及街边实景图,有效停车位共59个
在数据预处理过程中,数据按10 min的时间间隔统计停车位的占用数量,并根据总的有效停车位数量计算街边停车位的占用率。经过数据预处理后,可以得到时间从10:10分到19:50分,共计5 310条时间间隔为10 min的街边停车位占用率数据。招商路三个月的停车位占用率变化趋势如图8所示。
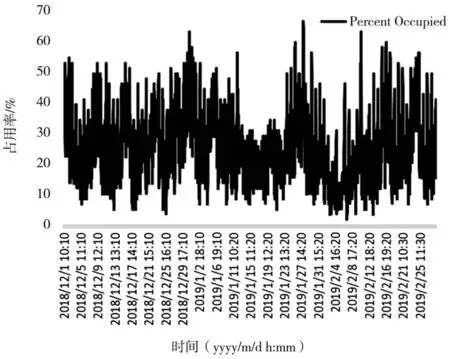
图8 招商路的停车位占用率
通过图8可以看出,招商路的街边停车占用率符合一般的停车规律,即周末占用率普遍偏高,工作日的占用率普遍偏低,可看作是以一个星期为周期的时间序列。
根据图8,对招商路的周末和工作日占用率数据进行描述统计,分别得到两个Q-Q图,如图9和图10,可以看出周末的占用率服从正态分布,工作日的占用率服从beta分布。

图9 招商路周末的街边占用率正态Q-Q图

图10 招商路工作日的街边占用率beta Q-Q图
将K-GRU混合模型应用于招商路的实际占用率数据,并与多项式拟合、傅里叶级数、LSTM、GRU四个方法进行了比较。其中多项式和傅里叶级数的阶数分别取8和12,LSTM和GRU的激活函数为 linear,epochs为 30,bitch_size为 500,训练集与测试集的比例均为8∶2。实验结果如表3所示。

表3 招商路各方法预测结果
由表3可以看出,K-GRU混合模型的实验误差比多项式模型、傅里叶序列、LSTM和GRU都小。随着聚类数的增加,MAE和MSE都在下降,但聚类数为5时,混合模型的预测误差开始上升。聚为4类时,K-GRU混合模型的表现最好,MAE为3.315%,MSE为0.173%。
图 11(a)和图 11(b)分别为招商路各方法占用率预测的MAE和MSE值的条形图,可以看出使用多项式模型和傅里叶序列进行预测的实验误差很高,LSTM、GRU和GRU混合模型的实验误差都明显低于前两种方法。在混合模型中,实验误差随着聚类数增加而降低,聚类数为4时,MAE和MSE都达到了最低,分别为3.315%和0.173%,但聚类数达到5时,MAE和MSE略微上升。
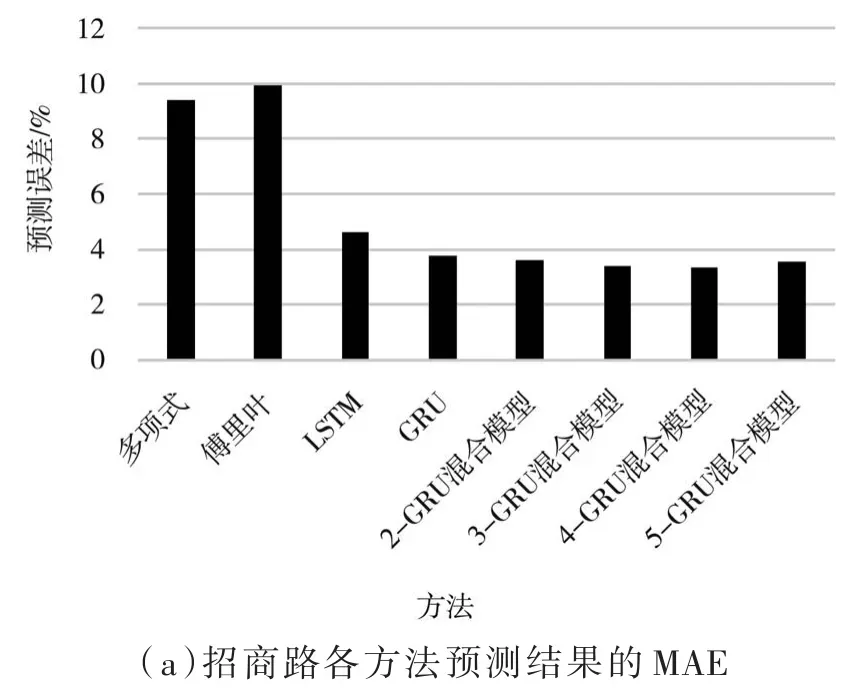

图11 招商路各方法预测结果的MAE及MSE
从图 12(a)和图 12(b)可以看出,K-GRU 混合模型在分别聚为2类、3类、4类和5类时预测的MAE比多项式模型和傅里叶序列预测的MAE下降比例超过了60%,MSE比多项式模型、傅里叶序列的MSE下降比例超过了80%。K-GRU混合模型在聚类处理后MSE比LSTM的MSE下降超过40%。K-GRU混合模型的MSE比GRU的MSE下降超过20%。聚类数达到4的时候,MAE及MSE下降百分比达到最高。

图12 K-GRU混合模型预测的MAE及MSE下降的百分比的条形图
4 结论
本文提出了K-GRU神经网络混合模型,使用K-GRU混合模型对混合分布下的时间序列数据进行预测。利用R语言随机生成的数据进行了仿真实验,并且将混合模型应用于实际的街边停车位占用率预测中。与多项式回归模型、傅里叶级数、LSTM神经网络、GRU神经网络相比,本文所提的方法具有较低的预测误差。通过仿真实验结果,K-GRU混合模型在聚类数为4时,通常能得到最佳预测效果。而聚为5类时,预测误差下降幅度变缓甚至会略微上升。其原因是固定样本量的条件下,随着聚类数增加,每个类的样本量变小,神经网络从单个类中无法学习到完整的信息。
