基于机器学习的典型制药企业工艺过程VOCs排放特征因子识别
2022-03-04景德基程娜娜蔡兴农石展宏杨春亚李素静王俏丽
景德基,程娜娜,蔡兴农,石展宏,杨春亚,李素静,王俏丽,李 伟,*
(1.浙江大学 化学工程与生物工程学院,浙江 杭州 310007;2.浙江工业大学 环境学院,浙江 杭州 310014)
0 引 言
深入打好污染防治攻坚战,不断改善空气质量,是建设美丽中国的必要前提。地级及以上城市空气质量优良天数比率到2025年达到87.5%,已成为我国“十四五”时期经济社会发展的一项约束性指标[1]。当前,我国大气细颗粒物(PM2.5)污染形式依然严峻[2-3]且臭氧(O3)污染日益凸显[4],成为影响空气质量的主要因素。京津冀及周边地区、长三角地区、汾渭平原区域现阶段源解析研究表明,挥发性有机物(VOCs)是PM2.5和O3大气复合污染的重要来源[5]。此外,环境空气中部分VOCs具有特殊气味并且表现出刺激性、腐蚀性、器官毒性、致癌性,对人体健康造成较大的影响[6-7]。部分VOCs可以被传输到平流层,对臭氧层造成破坏,少数VOCs属于温室气体[8]。因此,减少VOCs的排放对于提高空气质量有着重要意义。
实施VOCs减排,要抓好污染严重的重点行业,准确识别重点企业和工艺过程,全面推进工业园区、企业集群等VOCs的精准治理和综合治理[9]。随着医药行业的迅速发展,中国已经成为一个医药大国,医药行业的VOCs排放成为一个不可忽视的环境问题[10]。随着化工企业“退城入园”工作的推进,化工园区的企业密度日益变大,作为精细化工产业的代表,制药行业在化工园区占据重要的地位。化学合成类制药行业,生产原料使用大量有机溶剂,合成工艺复杂,各类副反应繁多,存在大量间歇性、无组织的VOCs排放,使得排放规律不明晰、排放特征不明确,同时还存在监测难度大,污染来源追溯难等问题[11-14]。
针对污染排放源监测构建的污染源成分谱是描述源排放特征的重要数据集之一[15-17]。然而,VOC污染源成分谱由于数据量大、因子多、信息不完备、数据规则不明显,在其应用过程中难以充分挖掘排放特征。而特征污染物可以简化源成分谱描述,减少数据干扰,以少量的组分表征污染源的排放特征,实现污染源类的定性判定[18-20]。随着科学研究的基本手段从传统的“理论+实验”走向现在的“理论+实验+计算”,乃至出现“数据科学”这样的提法,机器学习的重要性日趋显著。在环境领域,已有部分研究者采用机器学习的手段提取各种类型的特征因子。张云鹏等使用典型相关性分析和空间网格化逻辑回归分析方法获得了影响土地利用变化的全局特征因子和空间特征因子[21]。孙笑笑采用聚类分析和相关性分析提取了浙江近海岸赤潮发生时产生突变的赤潮特征因子[22]。曹丛华等采用主成分分析(PCA)和聚类分析提取了辽东湾鲅鱼圈赤潮的环境特征因子[23]。吴超凡采用回归分析、相关性分析和特征选择方法识别了与森林生物量相关的特征因子[23]。机器学习具备适应复杂数据,能获得预测模型的优点。
本文以长三角地区某精细化工园区内一家典型化学制药企业为研究对象,深入分析其VOCs排放特征,利用机器学习的手段开展统计分析,通过数据驱动识别其生产工艺过程的排放特征因子。识别的特征因子种类精简,易于监测,与污染源类能够高度对应,可为化学合成类制药行业实施VOCs减排、合理选择排放控制技术及后续地方标准的制定提供基础信息,为实现化工园区大气污染溯源提供了一条新思路。
1 数据与方法
1.1 数据来源
污染源VOCs成分谱来自长三角地区某精细化工园区内一家典型化学合成类制药企业,该企业生产的恩诺沙星、阿奇霉素、罗红霉素等产品份额约占海内外市场的30%。根据环评资料和现场调研,对厂区内VOCs排放源开展了全覆盖的样品采集工作,收集了20个污染源样本,分析了116种VOCs组分的浓度,并基于分析结果构建了基于工艺过程的精细化污染源成分谱,参见前期相关成果[25]。采样信息如表1所示。将污染源成分谱表示为数据集D={x1,x2,…,xm},其中m=20,代表样本数量。xi=(xi1,xi2,…,xid)代表每个样本由各个VOC物种浓度组成的特征向量,单位μg·m-3;d=86,为所有检测出的VOCs物种的数量。

表1 污染源采样信息
1.2 技术路线
污染源成分谱中的每个VOC物种被定义为一个特征,构成一个特征集。特征因子的识别过程被转化成机器学习中的一个特征选择过程,对特征子集的评价采用分类器的分类准确率作为标准。识别特征因子的技术路线如图1所示。
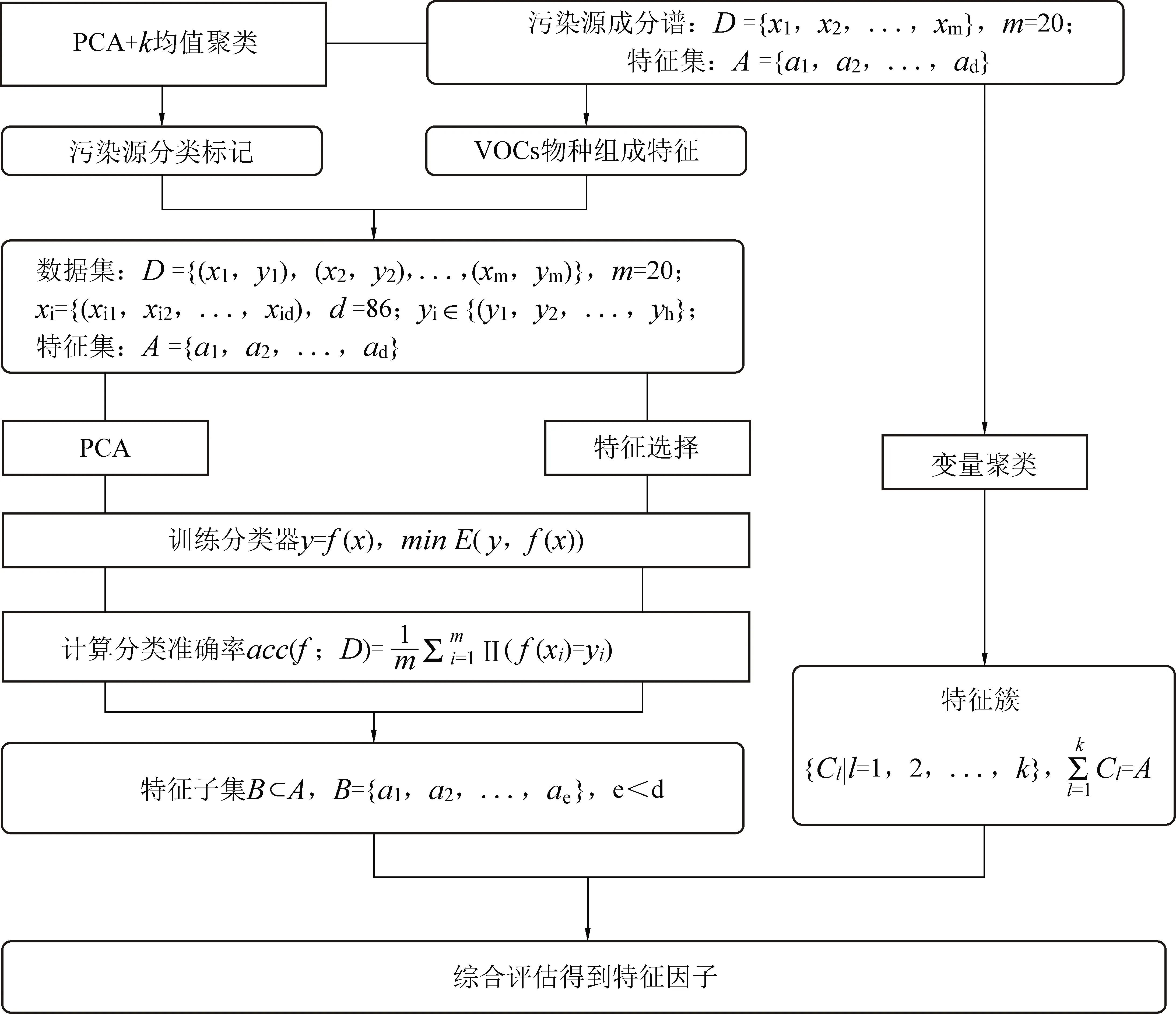
图1 特征因子识别技术路线
首先采用PCA加聚类分析将所有样本按照VOCs的物种组成相似度分为若干类别,并予以标记,实现污染源类别的区分。聚类分析通过对无标记训练样本的学习,将数据集划分为若干个通常是不相交的子集,每个子集称为一个簇[26]。k均值聚类作为被广泛使用的聚类算法,是一种基于中心的聚类方法[27]。它通过迭代,将样本分到k个类中。通过这样的划分,每个簇可以对应一类排放特征相似的污染源。本研究中的污染源成分谱检测出了86种VOCs的浓度,属于高维度的样本数据集,将导致聚类分析中的向量相关计算量呈指数增长,并且使样本距离的度量失去意义,大大降低性能。为了使各类样本在VOCs组成上的差异更容易区分,PCA用少数主成分近似表示原有数据集的所有信息,实现降维处理,提高聚类性能。
然后,对标记后的数据集分别使用PCA处理后的数据和特征选择处理后的数据训练若干分类器,并计算其分类准确率。分类器是从数据中学习到的一个分类模型或分类决策函数,可以对新的输入进行输出的预测,称为分类[28-29]。从给定的特征集合中选择出相关特征子集的过程,称为特征选择[30]。特征选择在于选取对提高分类器性能有所贡献的特征,即选取能够对污染源类别进行准确分类的VOCs物种。比较PCA处理和特征选择处理对分类器性能的影响,筛选出初步的特征子集作为预选特征因子。
最后对污染源成分谱进行变量聚类处理,将所有VOCs物种划分成若干个特征簇。变量聚类根据各个物种在污染源间的浓度分布,将其分为若干个特征簇,构成同一个特征簇的物种拥有相似的污染源间浓度分布。根据综合评估特征选择和变量聚类的结果,确定最终的特征因子。
2 结果与讨论
2.1 特征选择识别特征因子
2.1.1 源样本类别标记
先对原始数据集进行PCA的降维处理,选取95%的解释方差,提取获得前15个主成分,如图2(a)所示。在经过k均值聚类后,所有样本被划分为3个子集,如图2(b)所示,将其污染源类别分别标记为1、2、3。将聚类结果与采样点所属工艺过程进行对比,如表2所示。拥有相同聚类标记的样本拥有相似的VOCs排放组成,结果显示来自相同工艺流程的样本基本上被划分到了一类。在阿奇霉素生产线,只有103肟化车间的样本被赋予了不同标记。同样,在地克朱利生产线,只有402车间后段的样本被赋予了不同标记。这说明该企业阿奇霉素生产过程与地克朱利生产过程有着与其它工艺过程显著区分的VOCs排放特征,而恩诺沙星、罗红霉素、麻保杀星等生产过程的VOCs排放特征则较为相似。聚类标记与工艺过程对应趋势明显,说明通过分析PCA提取的主成分信息,该企业的工艺特征得到了明显的区分。然而PCA获得的主成分是所有VOCs物种的线性组合,无法直接指向具体的物种作为污染源的特征因子,这将给实际的监测工作带来困难,也提高了溯源模型在数据输入方面的难度。
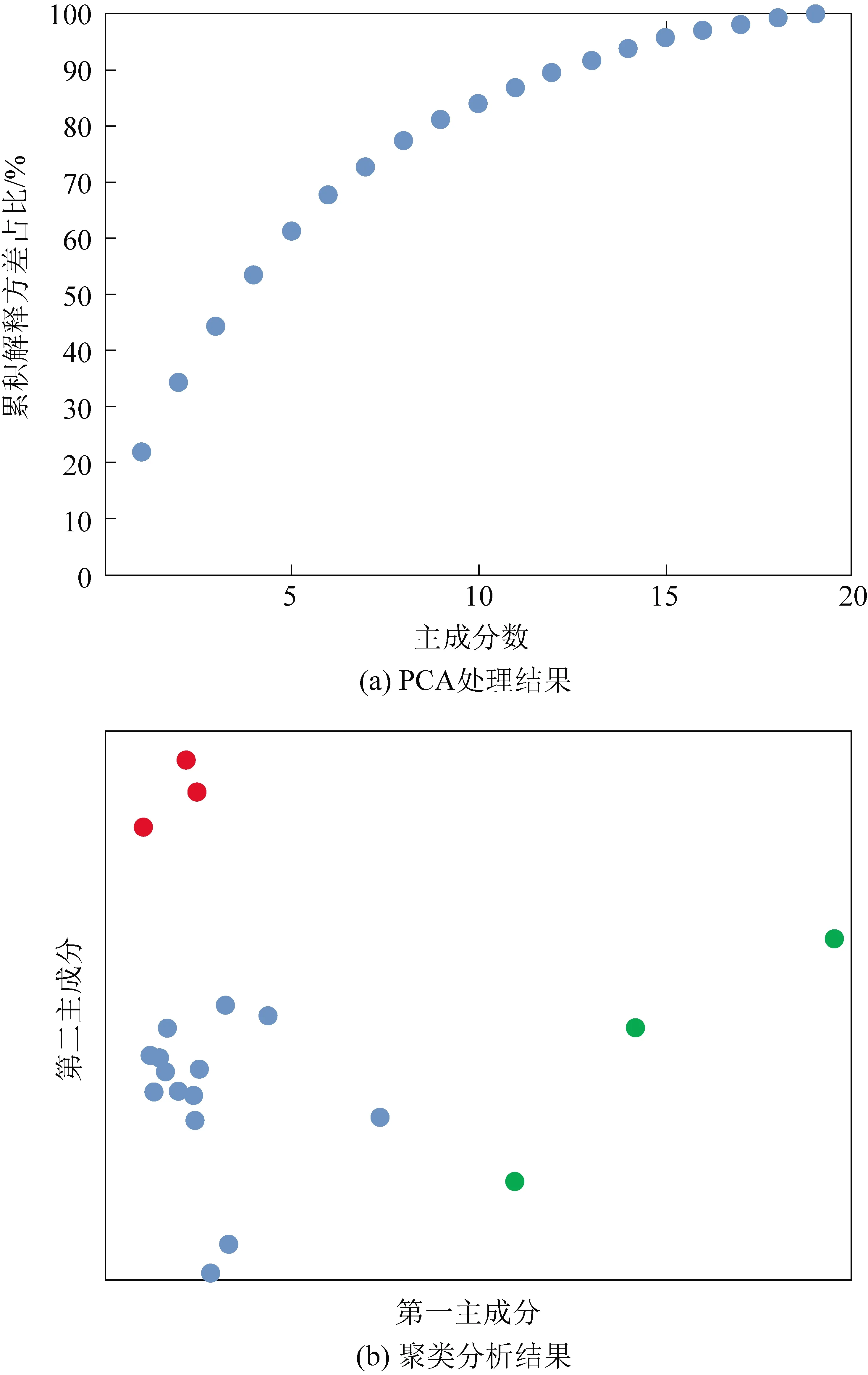
图2 源样本类别标记
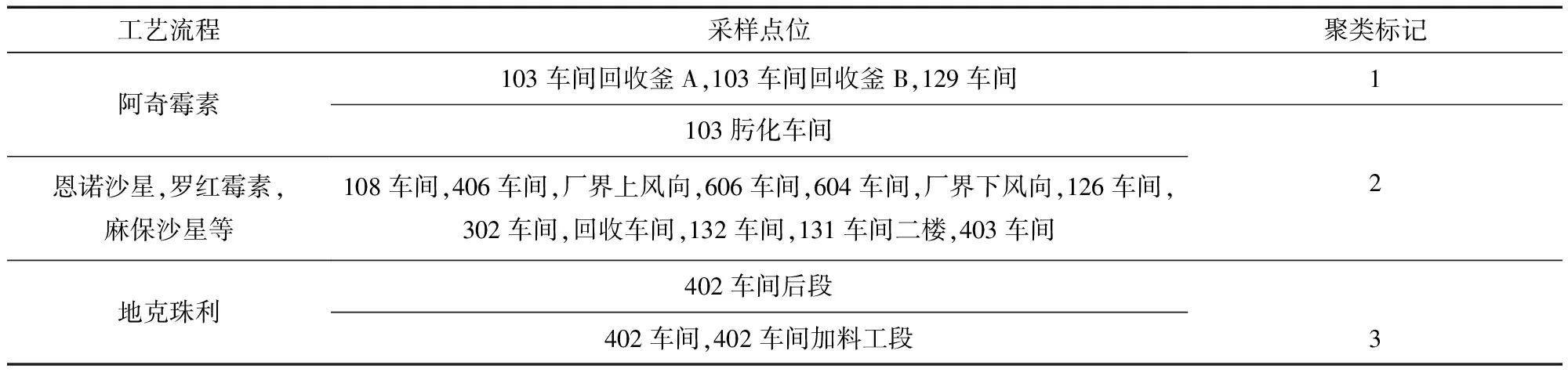
表2 聚类结果与工艺过程对比
2.1.2 特征选择结果
对标记后的数据集进行特征选择处理。参考PCA选择正交变换组合的原理,特征在不同样本间的方差越大,蕴含的信息越丰富。将86个VOCs物种按照方差降序排列,对照2.1.1中提取的15个主成分,选择前15个物种特征作为数据输入,训练分类器,并计算其分类准确率。训练过程在MATLAB软件自带的机器学习与深度学习工具箱中的Classification Learner模块进行,验证方式选择五折交叉验证。训练的分类器类型包括决策树、判别分析、逻辑回归分类器、朴素贝叶斯分类器、支持向量机、最近邻分类器和集成分类器。作为对照,另设一组实验,直接使用PCA处理后的带标记数据训练分类器,并计算器分类准确率。观察性能较好的分类器,结果如表3所示,经过特征选择处理后的数据,有2个分类器的分类准确率达到了85.0%,说明通过观察被选择的这15个物种可以实现对污染源的准确分类。对比PCA处理后数据训练得到的分类器性能,可以发现,特征选择在对污染源进行分类方面,达到了与PCA处理同样的效果。因此这15个物种被认定为初步识别到的特征因子,如表4所示。

表3 特征选择和分类分析结果

表4 预选特征因子
2.2 变量聚类识别特征因子
针对未标记的原始数据集,对86个VOCs物种进行k均值聚类分析。变量聚类根据各个VOCs物种在不同样本间的浓度分布将其分成若干个特征簇,被分为同一类的特征拥有相似的样本间浓度分布。结果如表5所示,所有物种被分为3个特征簇,其中甲苯、丙酮、乙醛、苯甲醛、正己烷、乙酸乙酯被分为一组。除乙酸乙酯外,其余物种均包含在步骤2.1识别出的15个预选特征因子当中。结合现场调研与污染源成分谱分析,甲苯是该企业多个车间的主要特征污染物,而丙酮、乙醛、苯甲醛和正己烷被划分到与甲苯一类,说明它们在各个车间的浓度分布与甲苯类似。对比特征选择和变量聚类的结果,综合特征因子的特征性和精简性,该企业的特征因子被最终认定为:甲苯、丙酮、乙醛、苯甲醛和正己烷。

表5 变量聚类分析结果
3 结 论
本研究以基于工艺过程的精细化污染源成分谱为基础数据,采用特征选择和变量聚类的机器学习方法识别出某典型化学合成制药企业的VOCs排放特征因子为:甲苯、丙酮、乙醛、苯甲醛和正己烷。通过这种方法识别的特征因子,拥有相似的污染源浓度分布,并且可以较好地体现各个工艺过程在VOCs排放组成上的差异,对精细化的污染源类别实现准确分类。在对污染源成分谱进行分析时,可通过观察这几种物质的VOCs浓度组成,分析其所属工艺过程。在实际的生产监管过程中,可采集足够丰富的污染源样本构建成分谱,并训练分类器,通过重点监测特征因子的浓度,输入分类器,得到所属类别以及判别概率,有望实现VOCs排放的快速精细化溯源。
