基于卷积神经网络的说话人识别方法*
2022-02-28楚宪腾王华朋杨海涛林暖辉
楚宪腾 王华朋 杨海涛 林暖辉
1. 中国刑事警察学院 2. 广州市刑事科学技术研究所
引言
采用个体声纹特征进行检材语音的鉴定是目前司法语音鉴定的一个重要方向。生物特征(指纹、虹膜、声纹等)本身具有一定程度的稳定性,在很长时间内都不会发生改变,并且不同个体间会表现出明显的差异性,因此生物特征可以作为判别不同人身份的依据[1]。说话人识别根据个人声纹特征进行身份同一认定,首先使用算法提取语音信号中的深层个人属性特征,然后将目标说话人与已知说话人进行特征匹配。在实际应用中,说话人识别系统的准确性、鲁棒性和实时性都是需要考虑的因素。当输入数据为高维度的时候,其大部分数据可能与说话人身份无关,利用全联接神经网络直接处理会造成过拟合现象,而卷积神经网络(Convolutional Neural Network,CNN)则可以有效避免这种问题[2]。CNN采用稀疏连接和共享权重的思想,即增强了神经元之间的数据计算效率,又减少了模型参数存储量,从而降低了模型训练难度。本研究将卷积神经网络引入到说话人识别模型中,利用CNN强大的特征数据挖掘能力,充分提取语音特征中代表说话人的本质特征,从而提高说话人识别的准确率。
一、说话人识别模型
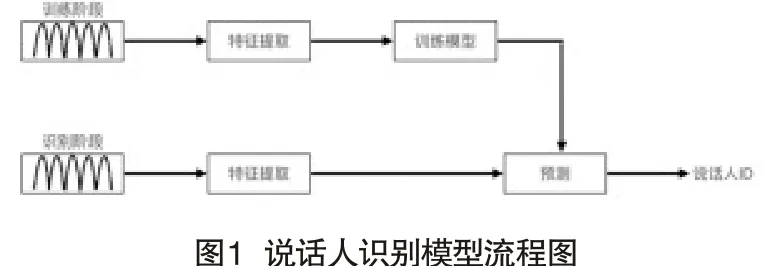
说话人识别的模型有很多,流程框架如图1所示。Reynolds等率先提出了高斯混合-通用背景模型(Gaussian Mixture Model-UniversalBackground Model,GMM-UBM),该模型使用大量非目标用户语音训练出一个具体说话人模型的先验模型,然后在模型上使用最大后验概率(Maximum A Posteriori probability,MAP)进行参数调整来得到目标说话人模型[3]。此模型训练周期长、复杂度高,且训练背景模型时无法克服语音采集的信道差异。基于这种问题,Kenny[4]等提出了JFA,抽取了和说话人有关的特征而去掉信道方面的特征,但此方法失去了信道包含的说话人信息,忽略了数据间的联系,且划分空间时每一步均会引入误差[5]。受JFA的启发Dehak提出ivector模型,将不同说话人差异和信道差异都使用全局差异空间进行建模,但针对时长较短的语音和含噪语音,识别率不理想[6]。d-vector模型由谷歌提出,使用监督训练的DNN(DeepNeural Network)来提取特征,说话人模型由DNN的最后一层隐藏层输出的平均值来表示,此模型结构简单,但特征提取能力不强[7]。端到端系统从输入到特征训练和分类打分都由网络完成,一体化的结构易实现联合优化,且最大限度的保留了说话人信息。但端到端的模型对训练数据需求量大,设备要求高,在一般实验条件下无法完成研究[8]。
因此,为了简化说话人识别模型,降低网络复杂度以及获得良好的识别结果,本文提出将卷积神经网络应用在说话人识别中。首先将说话人的原始声音转化为梅尔频率倒谱系数(Mayer-Frequency Cepstral Coefficents,MFCC),再利用CNN的结构优势从梅尔频率倒谱系数自动提取出说话人的个别特征,最后利用SOFTMAX函数进行分类,完成说话人识别。
二、卷积神经网络的基本原理
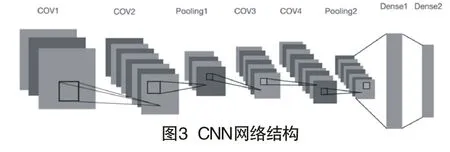
卷积神经网络是由卷积层、池化层、全连接层、激活函数构成的特征提取器[9,10]。卷积神经网络的一个卷积层通常包括多个维度,每个维度都由多个神经元组成,同一维度下的神经元采用相同的卷积核。卷积核通过神经网络训练更新权值,可以降低过拟合的风险。由于卷积神经网络采用了卷积核的采样方式,因此可以获取相邻数据之间的位置关系,从而提高特征提取的能力。卷积层的具体表示为:
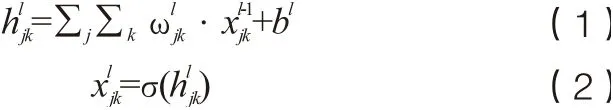
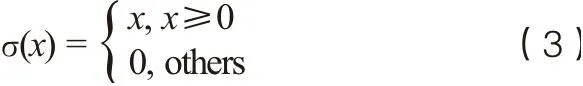
池化层有最大池化和均值池化两种方式,其都是通过对卷积后的数据进行重采样,降低模型复杂度,减少模型参数,提高模型训练效率。最大池化采用特征图的局部最大值达到降维的目的,在有噪声的语音中,相邻帧的时频图的局部最大值通常为语音,局部最小值通常为噪声,本文采用了最大池化操作,最大池化层表示如下:

其中,表示第l层池化所覆盖的区域i和j表示池化之后对应的输出,经过卷积、池化之后,特征会被展开平铺后送入到全连接层中。全连接层充当分类器的作用,使用SOFTMAX函数得到各类的预测值,SOFTMAX计算方法如下:

其中,i表示第i类别,j表示预测总类别数,表示第i类别的预测得分。随机失活层(Dropout)使网络的泛化性能得到提高,随机响应网络的节点,保证了网络的稀疏性,防止了过拟合。
三、实验设置
(一)语音特征的提取
由于每段语音长度不同,其静默段、噪声段时长也不同,直接送入神经网络训练会影响训练结果。因此本文提出首先提取语音的帧级特征,将每段语音划分为同等大小的帧级数据。帧级特征采用Fbank特征,然后经过离散余弦变换,得到梅尔频率倒谱系数。梅尔频率倒谱系数(Mel-Frequency Cepstral Coefficents,MFCC)是一种在说话人识别中广泛使用的特征,是用来表征语音信号的参数,凭借其在噪音环境下良好的鲁棒性以及极其符合人类听觉的特性,成为在说话人识别领域非常流行的特征参数,是一种帧级特征[11]。
卷积神经网络可以充分利用帧级特征之间的相关性,从而学习到更优的参数值。帧级特征提取过程如图2所示。
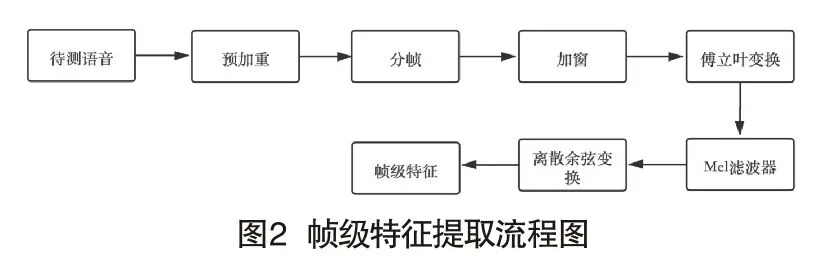
(1)预加重。目的是为了消除发声过程中,声带和嘴唇造成的效应,来补偿语音信号受到发音系统所压抑的高频部分,并且能突显高频的共振峰。

其中,k表示预加重系数,本文中取值为0.95。
(2)分帧。由于信号中的频率会随时间变化,因此在大多数情况下,对整个信号进行傅立叶变换是没有意义的,因为会随时间丢失信号的频率,假设信号的频率在很短的时间内是固定的,根据这一原理进行语音分帧。本文中设置25ms(帧大小)和10ms跨度(重叠15ms)。
(3)加窗。采用汉明窗以平滑每帧信号的边缘:
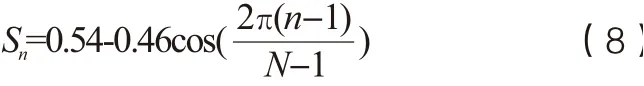
(4)DFT(离散傅立叶变换)。DFT处理Sn信号得到频域信号:
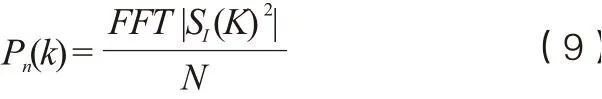
(5)Mel滤波器。Mel滤波器是一组非线性分布的滤波器组,其在低频部分分布密集,高频部分稀疏,从而更好的满足人耳听觉特性。可以使用以下公式在赫兹(f)和梅尔(m)之间转换:
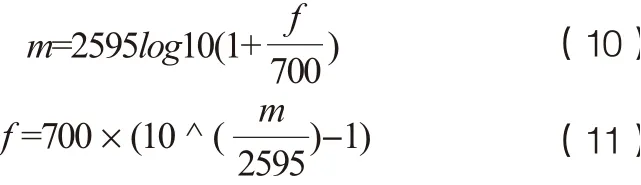
(6)DCT(离散余弦变换)。在上一步计算出的滤波器系数是高度相关的,在机器学习中可能会出现问题。因此应用DCT去除相关滤波器系数,对数据进行降维压缩和抽象,获得最后的特征参数。
(二)卷积神经网络设置
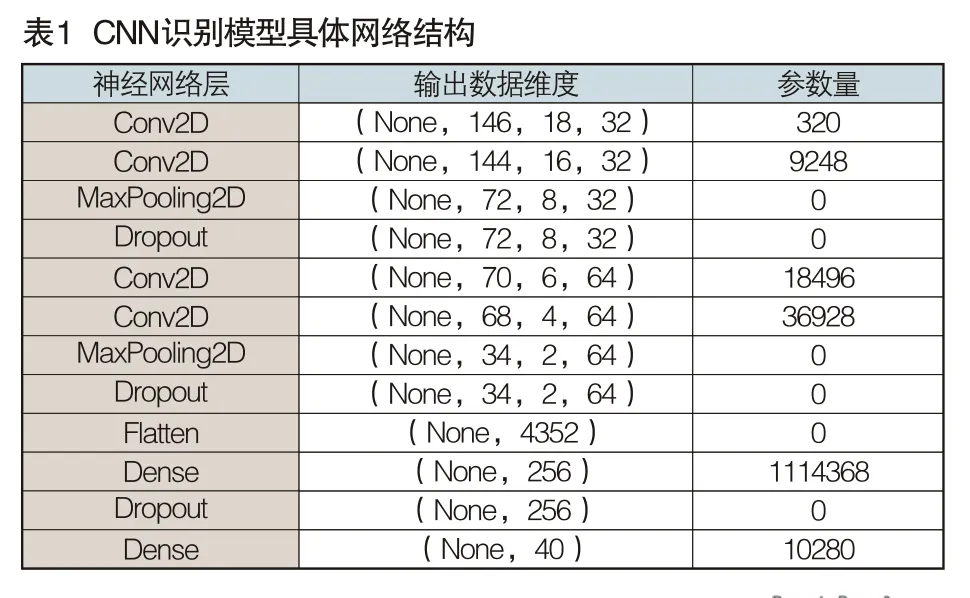
本文采用基于CNN的说话人识别模型,首先输入语音特征,经过两次卷积操作后采用最大池化进行下采样,并设置dropout防止训练过拟合。经过下采样后的数据再次经过卷积池化后进行全连接,最后利用SOFTMAX分类器设置40个节点实现分类(40个样本),网络的batch-size设置为64,即一次训练64个数据。
网络具体架构如表1所示。
?
(三)数据集和实验系统搭建
本文采用LibriSpeech数据库与中文数据库进行训练。由于中英文发音机制的不同,普通话区别于英文:(1)普通话时间熵密度较低,每秒字符较少;(2)普通话每个字有自己的发音,识别过程困难;(3)普通话相比于英文具有更大的字符集合,并且有很多同音字,相较于英文语音识别,中文识别会更加困难。
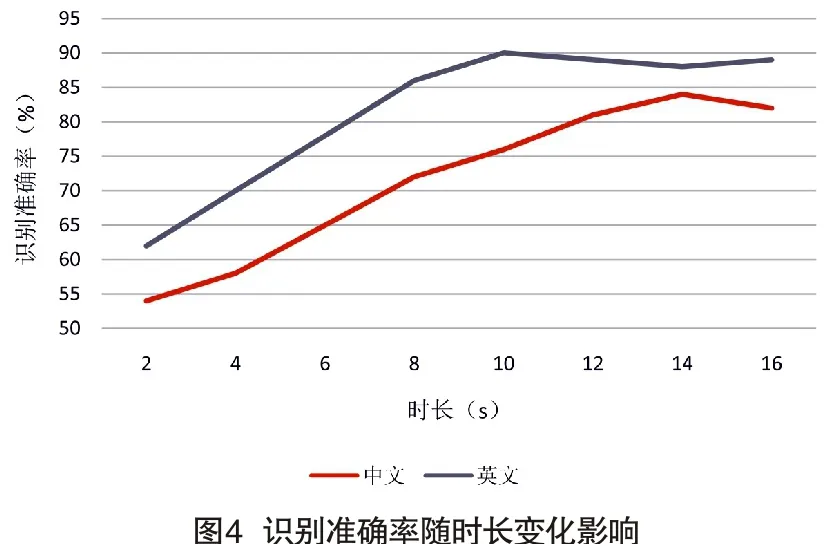
如图4所示,时长为2s的语音就可以采用本文算法进行测试。说话人识别准确率随着测试时长的增加而提高,但是时长增加到一定程度之后,识别率没有明显的升高趋势,而且计算机的计算量会大大增加,甚至会出现梯度爆炸现象。使用本文算法进行英文语音识别,语音时长在10s左右效果最好,对于中文语音识别,语音时长在15s左右最好。
中文数据库中共包含60名20岁左右的男性说话人(年龄相差不超过五岁)的语音样本,采样率为16KHz,每人录音两次,时长间隔一个月,全部采取单声道录音方式,录音内容为朗读指定的文本,录音信道为固定的电话线路。将音频去除静音段后,分割成15s左右的音频文件,每名说话人包含约25个音频文件,共1485个音频文件。从中选取80%音频文件(1188个)作为训练卷积神经网络的样本,20%音频文件(297个)作为测试样本。
LibriSpeech是一个采样率为16kHz、语料时长为接近1000小时的英语书籍朗读语音库,分为7个子集。本研究使用dev-clean子集,共有5.4小时的录音时长,其中男女共40个说话人,每名说话人的时长在八分钟。经过切割,控制每名说话人的语音时长在10s左右,经过切割后的音频文件共2938个,选取其中80%(2350个)音频文件作为训练卷积神经网络的样本,20%(588个)音频文件作为测试集样本。实验采用准确率作为模型评估指标。
本文选择实验仿真平台为ubantu18.04操作系统,选用Python3.7+tensorflow2版本,满足测试过程中对语言版本的要求。
四、实验结果及分析
(一)Librispeech数据集实验操作及结果分析
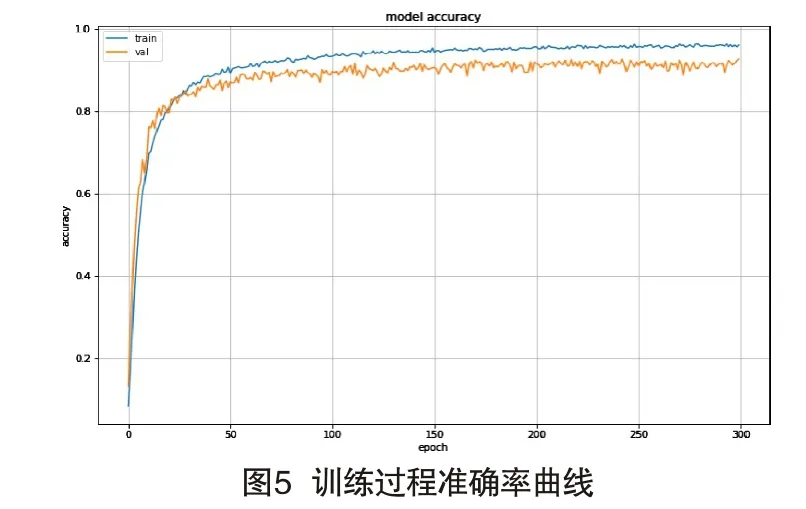
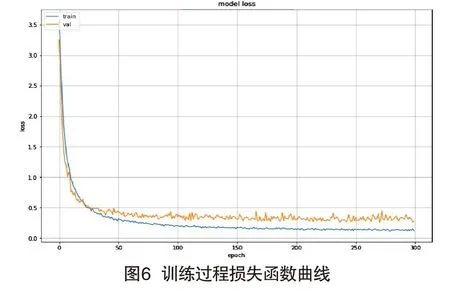
图5显示训练过程使用LibriSpeech库识别准确率变化曲线,即每次送入64个训练数据后分类的准确度,准确度是指预测正确样本数占预测总样本数的比例。图6显示训练损失曲线,得到交叉熵损失函数值,用来评判当前得到的概率分布与真实分布的差异情况,损失函数值越小,表明模型预测越准确。分析以上两图可得,随着训练次数的增加,模型的准确率在不断提高,损失值在不断减小。在迭代300次后,准确率曲线与损失曲线都达到收敛状态,识别准确率在95%附近,交叉熵损失函数值在最小值附近,识别结果较好。表明此网络可以训练更多的语音样本,从而进一步的优化提高模型的识别准确率。训练集的准确率高于测试集是因为模型对测试集的拟合程度不如对训练集的好。可以看出在迭代150次时,准确率曲线趋于平缓,在迭代200次后,测试集的准确率曲线也趋于平缓,表明模型已经基本训练完毕。loss曲线有助于观察模型的训练情况,从而调整训练参数。本实验将迭代次数设置为300,减少模型训练时间,同时对模型的性能也不会有很大影响。
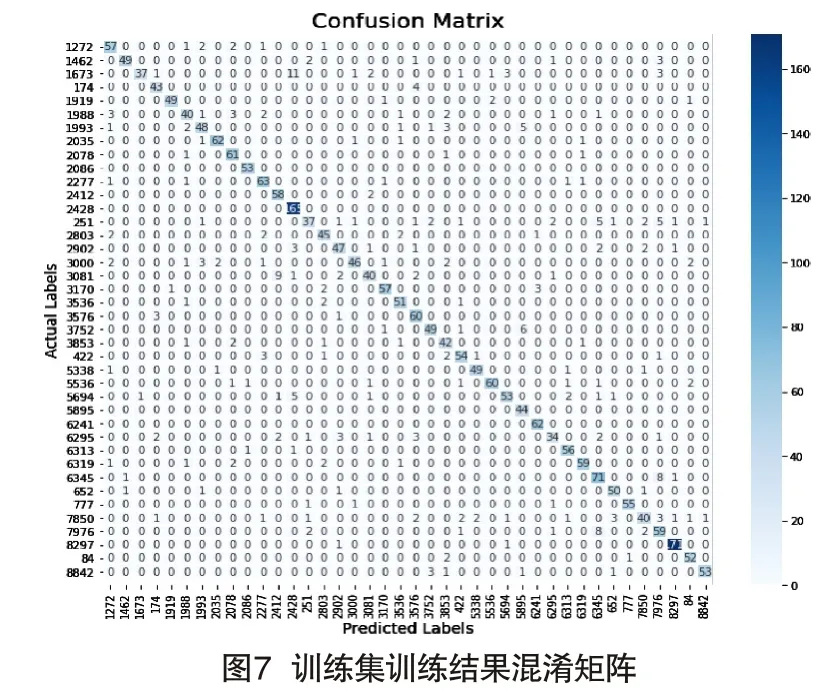
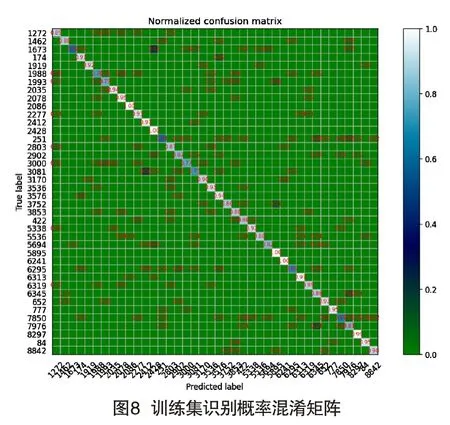
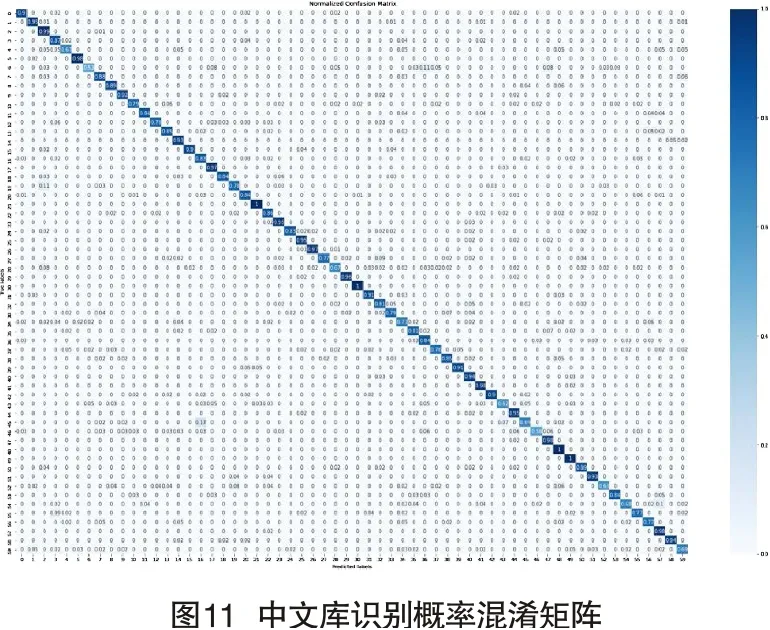
为清晰显示训练结果,本文以混淆矩阵为例对结果进行说明。如图7所示,纵轴表示真实标签,横轴表示预测标签,图中数字表示预测的结果次数。比如左上角“1272”值为57,表明结果有57次被预测为“1272”说话人。每一行数字之和代表10s语音组成的数据个数,如果对角线位置上的数字越大,表明被预测的结果越准确。图8表示训练过程的准确率混淆矩阵,纵轴代表真实值,横轴代表预测值,图中数字代表预测的概率值,对角线上的值越大,表明预测结果越准确。从图7和图8可以看出,对角线上的值均为最大值,表明所有音频文件分类结果都是正确的,表明训练过程中未出现梯度爆炸或梯度消失现象。
(二)中文数据集实验操作及结果分析
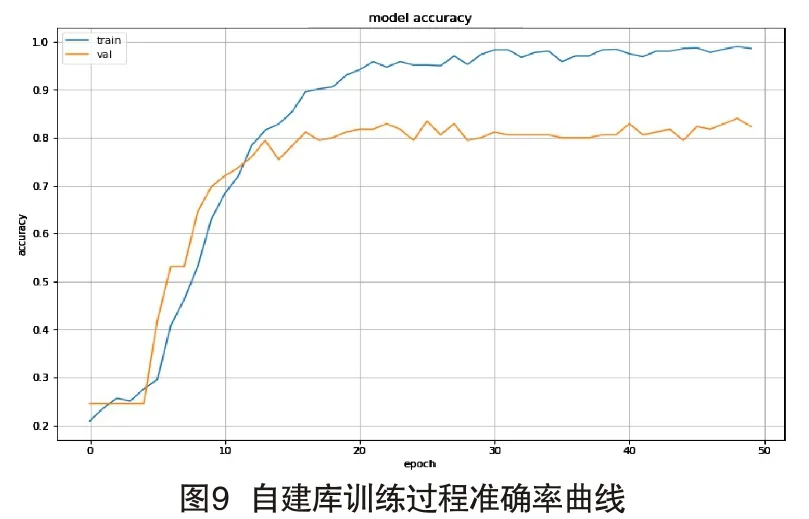
为验证此模型的有效性,本文将中文数据库送入模型进行训练。首先对中文语音信号进行预处理。相关操作为:语音信号经过预处理和分帧加窗操作,设定帧长为25,帧移为10,帧长不足的在后面补零,窗函数为汉明窗。然后经过MEL滤波器和DFC变换得到帧级语音特征。由图9可以看出,训练集的准确率要高于测试集的准确率,原因是自建库包含的训练数据较少,增加训练音频文件后准确率会进一步提高。图10和图11分别直观的表现出该模型预测正确的次数,可以看出,每名说话人预测结果均为正确值,预测概率值较高,说明该模型对识别中文仍具有较高的准确率。

五、结语
为充分利用卷积神经网络的特征提取能力,本文提出一种基于卷积神经网络的说话人识别方法,简化了传统识别方法的步骤,同时利用CNN在图像处理上的优势,利用提取的音频文件的MFCC特征进行训练,神经网络强大的特征提取能力也提高了识别效果。在LibriSpeech数据库中训练准确率达到了95.8%,测试准确率达到92.1%。在中文库中训练准确率也较高,达到96.3%,测试准确率达到85.83%,中英文识别准确率与发音机制的不同有关。CNN可以利用卷积的不变性来克服说话人自身以及环境的多样性,从而将语音信号当作一张图像来处理,可有效提高语音识别效果。实验结果表明,该网络模型泛化能力强,适合大规模的说话人识别任务。本文提出的CNN模型也有许多不足,即不能有效利用语音的时序性。未来将尝试不同的神经网络模型、优化本身结构或与其他网络结构结合来解决上述问题,从而进一步提高说话人识别性能。
由于智能移动设备特别是智能手机的普及,使语音数据采集更为方便,并且不需要加入任何额外的采集成本,加之声纹识别技术本身的高安全性,使声纹技术被广泛应用在各个领域中。本文使用卷积神经网络进行说话人识别时,卷积神经网络直接对二维图像进行处理,将待检测语音经过预处理变为频谱图像后,直接送入卷积神经网络中对频谱图像进行特征提取,大大降低模型的复杂度和减少权值数量。由于本文所用模型结构较为简单,识别准确率较高,可以满足一般的说话人识别要求。未来可以尝试将本模型与移动端相结合,实现语音采集、训练、识别一体化,使声纹识别应用更加便捷、高效。
