基于深度卷积神经网络的伪造语音检测*
2022-02-28杨海涛王华朋楚宪腾牛瑾琳张琨瑶中国刑事警察学院
杨海涛 王华朋 楚宪腾 牛瑾琳 张琨瑶 中国刑事警察学院
引言
深度学习(Deep Learning,DL)的进步促进了伪造语音技术的发展[1]。与此同时,利用以深度伪造为技术支撑的伪造语音通过欺骗机器听觉系统或人类听觉系统严重威胁到人们的生命财产安全[2,3]。现阶段的司法实践中对于伪造语音的识别主要依靠专家经验,对自动识别伪造语音算法的研究还不够充分。结合公安实践来说,在电信网络诈骗案件中犯罪分子主要使用虚拟空间实施诈骗,专家对伪造语音可干预部分较少,亟需发展自动识别伪造语音的算法。通过对伪造语音的快速准确识别,可以及时给人提供预警信息,提示语音、视频通话的风险程度从而减少电信网络诈骗案件的发生。
ASVspoof挑战赛(Automatic Speaker Verification Spoofing And Countermeasures Challenge)自2013[4]年召开后使得人们愈发关注伪造语音检测。国内外研究伪造语音检测技术主流方法是声学特征选取及识别模型选择[5]。在对伪造语音进行检测的模型选取上,高斯混合模型(Gaussian Mixture Model,GMM)是进行伪造语音检测的经典模型,在ASVspoof2015~2019挑战赛中都取得了不错的成绩,且被当作基线系统[6,7,8]。随后被学者应用于伪造语音检测领域的是深度神经网络(Deep Neural Network, DNN)[9]。卷积神经网络(Convolutional Neural Network,CNN)是深度学习的重要模型之一,Yann Lecun在文献[10]中提出了LeNet-5,并将BP算法应用到LeNet-5的训练上,形成了CNN的雏形。随后Hinton等提出的 Alexnet改进了网络结构并引入了dropout,在图像识别领域取得了巨大成功[11]。CNN能够加强前后神经元的关联性,且其共享权重的特性能够减少网络参数,加快训练速率[12]。借鉴于CNN在图像领域的成功,越来越多的学者将其引入到语音识别领域[13]。语音识别准确率与语音信号的多样性有关,卷积神经网络在空间和时间上具有平移不变性,将卷积神经网络模型用于语音识别领域则可以克服语音的多样性从而提高识别准确率。Chettr等使用基于CNN网络的识别系统去识别伪造语音,并分析了语音欺骗检测性能与语音样本的相关性[14]。本文选取多种语音声学特征,借助卷积神经网络的强大学习能力提出一种深度卷积神经网络进行欺骗语音检测研究,图1为本文伪造语音检测流程图。
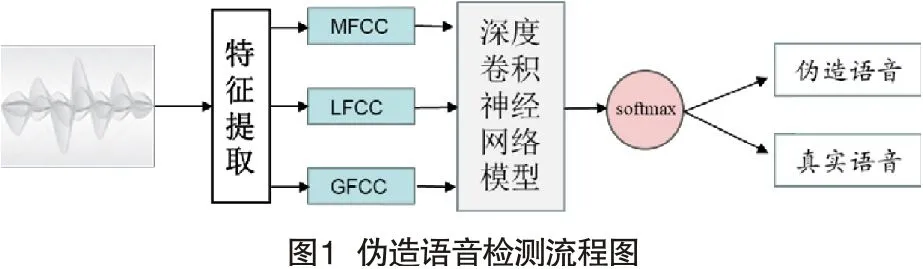
一、语音伪造方法
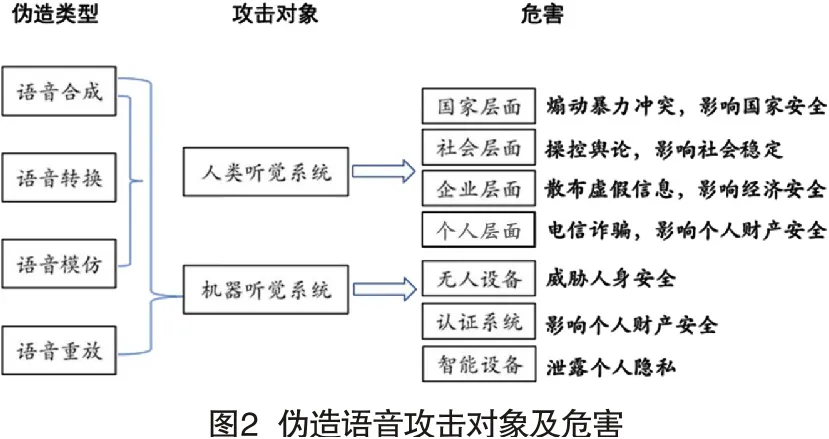
语音伪造的方法通常包括语音模仿、语音重放、语音转换、语音合成四类。其中语音模仿和语音重放这两类语音伪造方法操作简单、成本低廉,主要针对的是人们的听觉系统,稍加技术手段即可分辨。语音转换和语音合成这两种方法属于自动化的、主流的语音伪造手段,在语音伪造中被广泛使用,但检测成本高,难度大。在公安实践中常遇到的使用声卡、变声软件等进行伪造的语音大多数属于合成、转换语音,犯罪嫌疑人利用这两种方式来掩饰自身的声学特性并以此来实施欺诈。图2中总结了几种攻击方式的主要攻击对象及可能带来的危害[5]。合成、转换语音对社会的危害性更大,因此作为本文的主要研究对象。
二、声学特征
在说话人识别领域常用的声学特征之一是梅尔倒谱系数特征,它首先对输入的语音序列进行预处理,然后采用FFT将时域信息转换到频率域,之后用梅尔滤波和对数进行运算,最后使用DCT将空域信息转换到频域,得到MFCC特征,使用公式(1)在赫兹和梅尔之间转换。
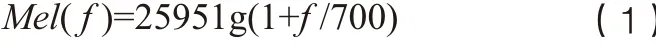
线性频率倒谱系数是声音的线性倒谱表示,它是对语音信号的对数进行离散傅里叶变换的结果,采用线性滤波器组,由于其能区分语音信号高频率区间,其在伪造语音检测中表现突出,其倒谱函数表达式如公式(2)。
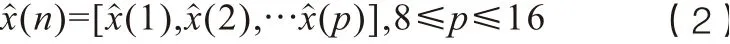
伽玛通频率倒谱系数与MFCC机理类似,伽玛通滤波器的排列模仿了人类基底膜的排列,它能够区分不同频率段的声音,能够对伪造语音进行区分,其时域表达式如下。
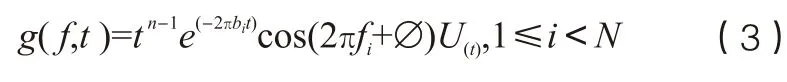
三、深度卷积神经网络
卷积神经网络通常包括卷积层、池化层、全连接层和激活函数,在伪造语音检测过程中多个卷积核的卷积层的目的是学习到语音序列的特征;池化层可以对语音特征进行下采样,通过改变语音序列特征映射的分辨率来实现偏移不变性;全连接层能够对真伪语音进行分类,激活函数通常包括sigmoid,tanh,ReLU。
本文提出一种深度卷积神经网络来进行伪造语音检测,检测的内容为语音合成、语音转换这两种目前较为流行的伪造语音,图3所示为提出的深度卷积神经网络结构图。
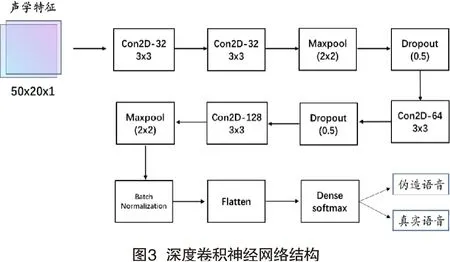
其中共有4个卷积层1个展平层1个全连接层。卷积层的输入是已经提取好的声学特征(X,height,width,channel),本文语音特征经维度扩增后其大小为[X,50,20,1],其中X为语音特征的个数,特征序列长度为50,语音特征维度为20,通道数为1,(4)式为卷积层的计算公式。其中padding为加零操作,stride为卷积核移动步长。
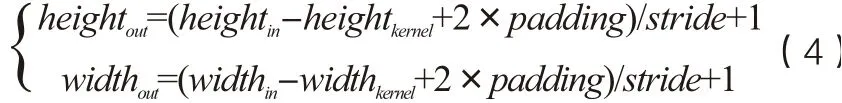
声学特征经过卷积层后进入最大池化层下采样处理,计算公式如(5)所示,最大池化层取窗口中的最大值,能够去除特征的冗余信息,简化网络复杂度简化计算,加快网络运算能力。i为3×3的窗口区域。

展平层的目的是将卷积处理后的语音特征平滑处理,使其进入全连接层,对语音实行分类任务。在卷积层中使用的激活函数为ReLU,ReLU激活函数没有复杂的指数运算,计算简单效率较高,因此神经网络的收敛速度会更快,其计算公式为(6)(7)。
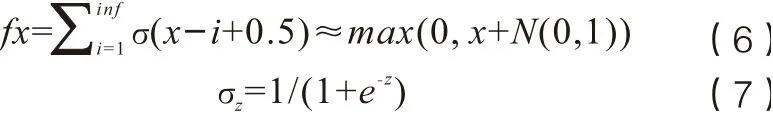
在分类过程中选择的损失函数是Softmax,该函数在分类问题中经常使用,在本文中它将多个神经元的输出映射到(spoof,bonafide)区间来实现伪造语音分类,其计算公式为(8),其中xi为第i个节点的输出值,C为输出的类别。
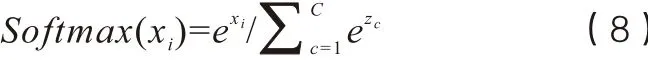
在构建网络模型的过程中使用了丢弃法(Dropout)和批标准化(Batch Normalization)两种优化策略,在神经网络前向传播的过程中使用丢弃法让神经元以一定的随机概率停止工作,这样使得模型的泛化能力更强,运算速度更快[15]。批标准化将数据分成小批进行计算,将数据映射到(0,1)之间,减少网络模型的计算量,防止网络过拟合,增强神经网络的稳定性[16]。
四、实验设置
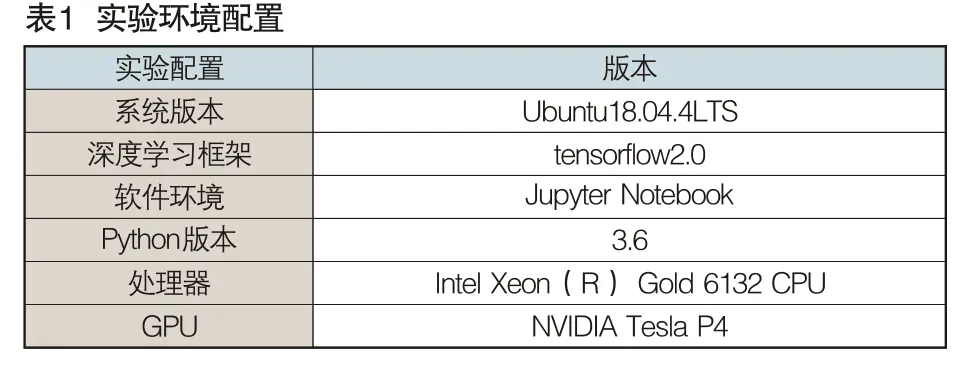
(一)实验环境
本文实验环境配置如表1所示。
?
(二)数据库
英文数据库ASVspoof2019中的LA中的训练集是基于VCTK数据库进行开发的,该数据集伪造语音由4种语音合成算法和2种语音转换算法生成,共2580条真实语音和22800条伪造语音,是进行伪造语音检测常用的数据集[8]。
中文数据库采用的是第二届CSIG图像图形技术挑战赛伪造语音检测项目所开源的数据集FMCC-A ,该数据集是目前最大的开源伪造中文数据集,由10000段真实语音和40000段由语音合成语音转换算法合成的伪造语音构成[17]。
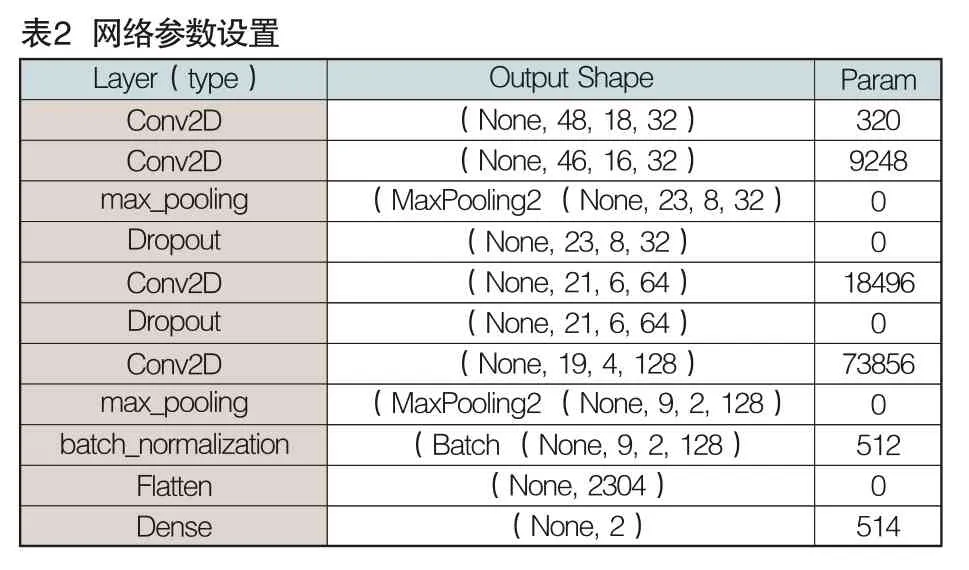
(三)网络参数设置
第一层卷积神经网络设置有32个3×3卷积核,形状为[X,50,20,1]的语音特征,输入第一层后输出为(None,48,18,32),第二层卷积神经网络设置有32个隐藏节点输出为(None,46,16,32),第三层设置最大池化层进行下采样,随后设置丢弃层随机丢弃50%个神经节点,防止神经网络过拟合,之后经过具有64个隐藏节点的卷积层后设置Dropout层丢弃50%个神经节点,然后再进入有128个隐藏节点的卷积层,后面为最大池化层,之后进行批标准化处理,最后展平进入Dense层分类。其中卷积层激活函数采用ReLU,Dense层激活函数为softmax。Batchsize设置为512,训练次数为1000次,网络参数设置及输出详细信息如表2所示。
?
(四)实验结果及分析
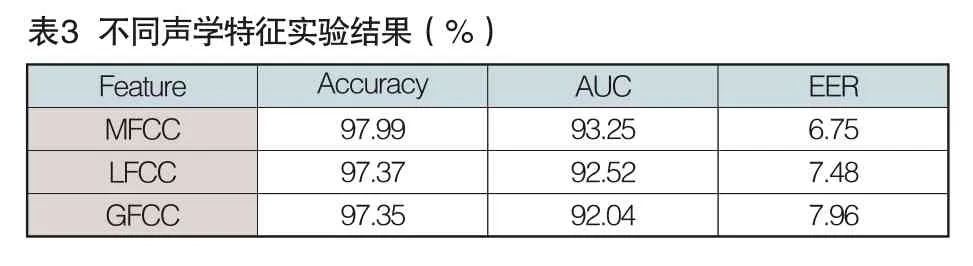
分别对MFCC、LFCC、GFCC这三种声学特征使用所提方法进行实验,实验过程中控制其他变量,实验结果如表3所示,比较的标准采用测试集准确率(Accuracy);AUC(Area Under the Curve,AUC),等错误率(Equal Error Rate,EER)。其中AUC指标越接近于1说明使用该种特征的模型更稳定,EER指标越接近于0说明模型对伪造语音的区分度越高。
?
由上表,MFCC特征在准确度、AUC及EER指标上表现均超过LFCC和GFCC特征,在本文所提出的深度卷积神经网络上表现最好,能够作为伪造语音检测的声学特征。
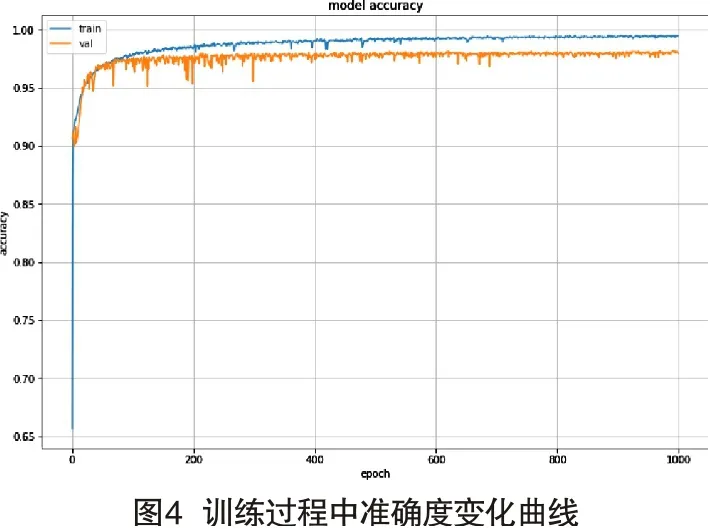
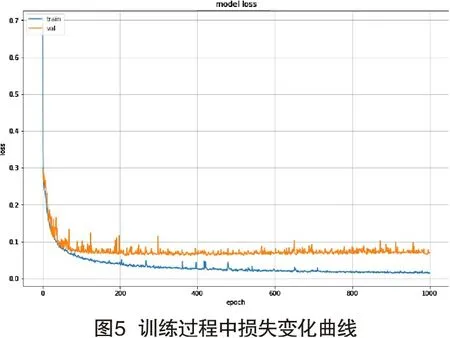
使用提取到的MFCC特征,设置训练周期为1000Batch-size为512的条件下训练过程的识别准确度变化曲线及损失变化曲线如图4、图5所示。在迭代200个周期后,准确度变化曲线及损失大小变化曲线进入收敛状态,训练集和验证集准确度达到了97%以上,损失函数值在0.09以下,训练过程稳定未出现梯度爆炸或梯度消失现象。
为验证本模型在中文伪造语音上的表现,本文实验引入FMCC-A中文伪造语音数据库进行实验。提取中文语音库的MFCC特征,其他实验参数保持不变进行实验。图6中(a)(b)图分别为英文数据库和中文数据库的混淆矩阵图,可以显示本文所提方法对这两种数据库真实类或伪造类语音的区分程度。横坐标为预测类标签,纵坐标为真实类标签,对角线上数值越大表现该类区分准确度越高。
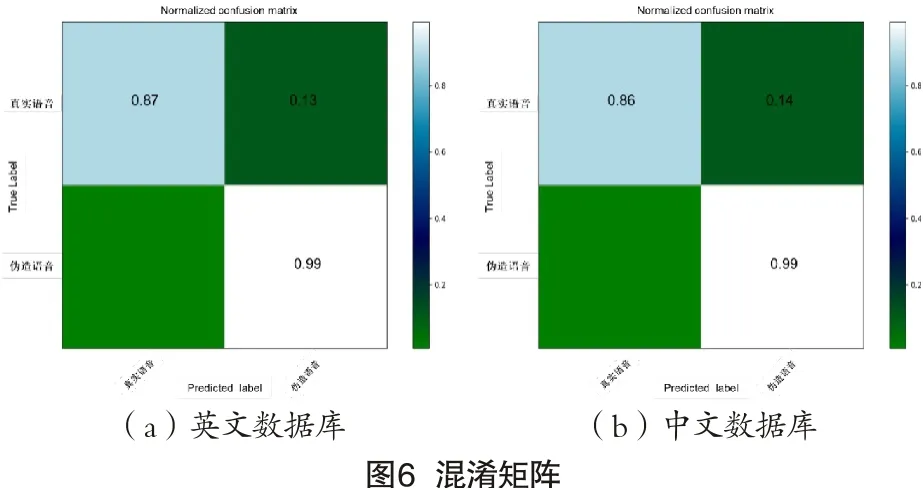
图6可以看出本文所提方法对英文库或中文库中的伪造语音的检出率都达到了99%,对真实语音的检出率在中文数据库上表现稍差,其原因可能与中文语音较英文语音更复杂有关。
五、结语
快速准确的对伪造语音进行检测在公安工作中具有十分重要的意义,为此本文提出一种深度卷积神经网络并提取了三种语音声学特征来进行伪造语音检测,实验在英文和中文伪造语音数据库上进行。三种声学特征中表现最好的为MFCC,且在两种数据库中对伪造语音的检出率均达到99%,证明了所提方法的有效性,但是对于真实语音的检出率还有待提升,将来的工作应进一步加强。
