基于FCOS算法的幼儿识物教育的应用
2022-02-24魏若禹李丹
魏若禹,李丹
(四川大学锦城学院,四川成都,611731)
1 研究背景
幼儿识物教育在幼儿教育中处于特殊的地位,因为在幼儿识字教育前,往往需要接受识物教育,让幼儿对于世界可以有一个懵懂的概念,也是启蒙教育的最初阶段。在过去的幼儿识别物体的教育中,由于幼儿心智未成熟,教育者往往需要多次重复地教授幼儿图像中的物体名称,即使幼儿当时识别到了该张图像的物体,可在不同图像中的同一物体依旧难以识别。这样的识别教育过程需要花费教育者大量的时间以及心力,且教育效果往往会受到不同教育者耐心程度的影响,较为耐心的教育者或许可以使得幼儿得到较好的教育效果,可缺乏耐心的教育者则会使得幼儿的教育效果极差,而教育者的教导水平也与地区等因素有关,这也使得一些不发达地区的幼儿无法接收到较好的幼儿教育。【6】
随着科技的发展,这样需要耐心的重复性的教导工作则可以交给机器去处理。这就导致了幼儿识物教育系统的出现。这些传统的幼儿识物教育系统大都为简单的去识别一开始设置好的信息。例如幼儿用的识物点读机,只能识别固定书目的固定事物,又或者例如一些学习机中的识物系统,只能识别事先输入进去的事物信息,没办法做到为输入图片信息的图片上的物体识别。而由于人工智能的飞速发展,目标识别算法在许多领域的应用都取得了较为不错的成果,这也就使得目标检测算法结合幼儿识物教育成为一种可能。鉴于FCOS算法在目前众多的目标识别算法中有着独特的优势,所以采用FCOS算法与幼儿识物教育系统相结合,可以使得幼儿在识物教育得到更好的教育效果。
不同于传统的识别物体教育系统只能识别特定图像中的物体,本文中提到的FCOS目标检测算法只要预先经过训练就可以较好的检测任意图像中的物体,并将识别结果传送到相应的硬软件系统,将识别到的物体名称以多种语言拼读出来,以达到教导幼儿识别物体的结果。
2 FCOS算法的原理及优势
目前大部分主流目标检测算法例如Faster R-CNN,SSD和YOLOv2,YOLOv3等算法都是基于一组预定义的锚框的。也正因如此,在很长一段时间内人们普遍认为锚框的使用是检测算法能否成功的主要因素。【1】但由于锚框的特性,检测算法的性能对锚框大小、锚框横纵比、锚框个数等因素极为敏感,所以在使用这些检测算法时,需要将这些超参数仔细调整。但即使经过精心调整与设置,有些超参数例如锚框的横纵比、锚框的规模等都是固定的,在处理一些涉及到识别形态变化较大的物体的任务时就会变得比较困难。因而这些检测算法的使用往往需要根据不同的识别目标重新设计相应的锚框大小以及锚框的横纵比。【2】
在使用基于锚框的检测算法时,为了得到较高的召回率,会在输入图像上密集地放置锚框。而在训练过程中,这些锚框大多数被标记为负样本,这样导致了正负样本之间数量的不均衡。而且基于锚框的检测算法还涉及到一些例如真实框的重叠度(IoU)这样较为复杂的运算,加重了系统运算的负担。【2】
3 实验结果以及样本
3.1 训练样本及测试集
本文所使用的训练集是VOC2007数据集的train部分,测试集则采用的是VOC2007数据集的test部分,在VOC2007数据集中一共给出了带标签数据共二十个类别,其中包括四个大的类别,分别是人类、常见的动物、交通车辆以及室内的家具用品,二十个小类分别为人,猫,牛,狗,马,羊,机、自行车、船、公共汽车、汽车、摩托车、火车,子、椅子、餐桌、盆栽、沙发、电视机。每张在角度、光照等面都有一定的不同之处。
之所以使用VOC2007数据集是因为在VOC2007数据集中包含了多种物品,而认识这些物品也是应该存在于幼儿识物教育的内容中的。因此使用VOC2007,利用其包含多种物品的特性,不但可以较好的训练模型,还可以更好的结合幼儿教育所需。
FCOS不同于上述提到的算法,FCOS是一种基于无锚框的单阶段目标检测算法。与上述基于锚框的算法相比,FCOS有着减少设计参数的数量、避免与锚框相关的复杂计算等优点。与同样是基于无锚框的YOLOv1比起来,FCOS可以利用真实边框中的所有点来预测边框,并且由于靠近目标边框中心的位置可以得到更加可靠的预测效果,所以FCOS算法利用“中心度”分支来抑制检测到的低质量的边框。【2】
在FCOS算法中,怎样怎样判断和处理不同边框是极为重要的。如图1所示,FCOS对不同特征图上不同大小的目标做检测,我们使用了五个层次的特征映射{P3;P4;P5;P6;P7.}P3、P4和P5由主干 CNN的特征图C3、C4和C5生成,具有如图1中所示,自上向下连接,P6,P7是在P5,P6上由3x3,步长为2的卷积层处理得到的。该种方案的与RetinaNet从C5获得P6和P7不同,但FCOS算法可以在使用更少参数的基础上保持与其相似的性能。此外,P3、P4、P5、P6和 P7的步长strides分别是 8、16、32、64和 128。【1】
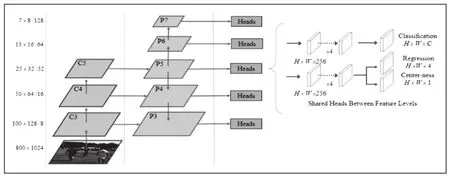
图1 图中显示为FCOS算法结构[1]
而在判断边框类型时,如果一个单位对应的坐标(x,y)在Ground Truth box(真实边框)内,那么这个单位就归为postive,并且其类别为真实边框(Ground Truth box)类别,否则为negative,而如果落入多个Ground Truth box 中,则称其为 ambiguous。【2】而在处理 ambiguous 的过程中,将ambiguous单元与Ground Truth box的四个边的距离(l*,t*,r*,b*)的最大值max(l*,t*,r*,b*)与事先设置好的对应层次的m相比较(m是该层单元需要回归的最大距离。m2,m3,m4,m5,m6,m7分别设为0,64,128,256,512,∞),如果max的值大于该层次所对应的strides的值或是下于其上一层层次所对应的strides的值,则使得该ambiguous为negative;若值在两者之间则设置为postive。【1】在此之后,如果单元仍然为ambiguous,则选择真实边框(Ground Truth box)面积最小的那个与其进行绑定。这样做的目的,简单来说就是因为FCOS使用了基于FPN的多级预测,所以最底层的feature map上的单元就与一些小的bounding box绑定在一起,越往上层,该层的feature map就与越大的bounding box绑在一起。这样就可以较好的解决了真实边框(Ground Truth box)重叠会在训练过程中造成难以处理的歧义的问题。【7】
3.2 实验结果与实验细节
在实验过程中,一共设置了3组实验参数并在两台TeslaV100上进行训练,从而三种方案进行对比。
方案一的网络的训练参数如下:初始学习率设置为0.01,权重衰减设置为0.0001,训练批次大小设置为4,训练轮数 15 轮。【3】
方案二的网络的训练参数如下:初始学习率设置为0.01,权重衰减设置为0.0001,训练批次大小设置为4,训练轮数 30 轮。【3】
方案三的网络的训练参数如下:初始学习率设置为0.01,权重衰减设置为0.0001,训练批次大小设置为8,训练轮数 30 轮。【3】
训练完后,以VOC2007数据集test部分为测试集,比较三种训练方案下得出模型在识别VOC2007数据集中的二十种类别时的准确率。
如图2所示,随着训练批次大小以及训练轮数的增加,三种方案得出的模型在识别VOC2007数据集中的二十种类别时的准确率也明显增加。在方案三下训练出来的模型,在识别VOC2007数据集中的二十种类别时有着较高的准确率。因此,将FCOS算法应用于幼儿识物教育系统有者良好的实用效果。

图2 实验结果
4 FCOS在幼儿识物教育中的应用
在传统幼儿识物教育系统中,往往需要事先将幼儿识物教育所用的图片资料输入到系统中,且每新增一张图片就要连同图片信息一起输入到系统中,因而只能识别系统中保存的图片中的物体,即使是相同物体在不同图片中,传统识物教育系统也无法识别。这就导致了如果幼儿识物能力较强,那么就要频繁对系统进行更新,增加新的图片让幼儿认识不同照片中的事物。
但随着深度学习在图像处理、目标识别、目标检测等领域的应用取得较大成功后,我们便设想是否能够将目标检测算法融入到幼儿识物教育系统中。使得以目标检测算法为基础构建的幼儿识物系统本身就具有物体识别的能力,这样只要通过加载预先训练好的模型去进行操作就可以使得系统不再局限于只能识别固定的图片,而是可以识别任意图片中的物体。在构建系统时,我们既可以将模型部署在云端【4】,只提供服务接口,让用户通过网络远程连接服务器进行运算,也可以将目标检测的算法模型迁移到移动智能终端,如手机,平板电脑等设备上【5】,让用户通过智能终端所连接的摄像头等设备得到需要识别的物体的影像,再通过智能终端中的处理器调用部署在本地的模型进行运算。【9】两种应用都有着各自的优势与局限性,部署在服务器端可以使得模型运行更快速,得到的结果更加准确,但会受到网络连接环境的影响,而部署在移动智能终端则避免了网络环境波动造成的影响,但会受到移动智能设备处理器运算速度的制约。
而在算法的选择上,我们选择FCOS算法作为目标检测的算法。因为该算法不需要预先定义锚框(anchor),与因此避免了和锚框(anchor)相关的大量计算,这样大大减少了训练所需的内存,也使得FCOS可以更快的应用在系统中。
如果一开始传统识物系统中只有第一张图片(图3),而没有第二张图片(图4),那么传统识物教育系统只能通过新增信息去更新系统中的图片和图片资料,才能使得幼儿认识第二张图片中的物体。而基于FCOS算法的识物教育系统则可以根据图片得到图片中的物体信息,即使两张图片都不在系统内,但都可以较为准确的识别出图片中的物体。

图3 狗(左一)和猫(右一)

图4 马
比传统幼儿识物教育系统更好的是,基于FCOS算法的识物教育系统不但可以识别图片中的物体,还可以识别视频中的物体,这样就使得幼儿识物教育不只停留在静态物体的识别,也因此可以强化幼儿识物教育的效果。如图5,图6所示。

图5 所示为某音乐视频中的两个人物角色

图6 则是某道路车况视频
根据图片所示,我们可以得知基于FCOS算法的识物教育系统对于视频中的物体有着较强的“识物“能力,也因此可以使得在幼儿在基于FCOS算法的识物教育系统的教育下可以结合动态物体识别与静态物体识别,从而达到一个更好的学习效果。
