基于Python的拉勾网数据爬取与分析
2022-02-24贾宗星冯倩
贾宗星 冯倩

摘 要: 研究并设计实现了一个基于Python的爬虫,用来爬取拉勾网数据资源。针对想要的信息数据进行定向爬取,对爬取到的信息进行存储、数据清洗及可视化分析。最终得到全国范围内招聘Python工程师的公司以及相关的待遇及要求。
关键词: Python; 爬虫; 数据清洗; 可视化分析
中图分类号:TP399 文献标识码:A 文章编号:1006-8228(2022)02-05-03
Crawling and analyzing data of lagou.com with Python
Jia Zongxing, Feng Qian
(College of Information Science and Engineering, Shanxi Agricultural University, Taigu, Shanxi 030801, China)
Abstract: In this paper, a Python based crawler is designed and implemented to crawl data resources of lagou.com. Directional crawling is carried out for the desired information data, and the crawling information is stored, cleaned and visually analyzed. Finally, the company that recruits Python engineers nationwide and relevant treatment and requirements is obtained.
Key words: Python; crawler; data cleaning; visual analysis
0 引言
每到畢业季,毕业生须对招聘职位等信息有详细地了解,才能更好地应聘到心仪的工作。比如,要了解全国范围内招聘Python工程师的公司以及相关的待遇及要求,网上有海量招聘信息,靠人工采集数据方式速度慢效率低,且容易出错。本文针对此种情况,设计出了一个基于Python的爬虫,用来爬取拉勾网招聘信息,并对这些数据进行清洗以及可视化的分析,最后得到想要的信息。
1 相关技术介绍
1.1 Python语言
Python 语言作为一种当前最为流行的数据分析语言, 有着简单易学、 面向对象、 可扩展、 库丰富等特点[1]。
1.2 网络爬虫技术
网络爬虫,又称蜘蛛机器人,是抓取网页数据的程序,最终是根据用户需求,在一定规则下,得到用户需要的数据信息[2]。爬虫模块的系统框架由解析器、控制管理器、资源库这三部分组成。控制器的首要任务是给多线程中的各个小爬虫线程确定它们的工作任务。解析器的主要作用是进行网页的下载,页面的整理。资源库的作用是存放下载好的网页信息,通常采用数据库来存储。
2 拉勾网数据爬取与分析
本文选取的目标网址为:拉勾网https://www.lagou.com。这是较专业的互联网相关行业招聘网站,速度快,职位多。本文要抓取的内容是全国范围内招聘Python工程师的公司相关的要求信息及待遇,包括岗位id、所在城市、公司全名、工作地点、学历要求、职位名称、薪资以及工作年限等。
本次设计将爬取到的信息存到Excel表中,以表格及图表的形式来进行结果的展示。
2.1 数据的获取
利用爬虫获取数据的思路就可以确定为:发送get请求,获取session、更新session,发送post请求、获取数据并存储。具体实现如下:
首先设置要请求的头文件。请求头文件是访问网站时访问者的一些信息,如果不设置头文件的话,很大程度会因为访问频度过高而被当作机器人封杀。再通过开发者工具获取User-Agent和Referer。将以上内容写入代码中:
my_headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS
X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36", "Referer":https://www.lagou.com/jobs/list_Python?city=%E5%85%A8%E5%9B%BD&cl=false&fromSearch=true&labelWords=&suginput=","Content-Type":
"application/x-www-form-urlencoded;charset=UTF-8"
}
其次在测试时发现一次最多能爬取1-3页爬虫就会被中断,解决办法是使用time.sleep()间隔爬取。
接下来就是session的获取以及两次请求的发送,代码如下:
ses=requests.session() #通过requests获取session
ses.headers.update(my_headers)
#对头文件中的session进行更新
ses.get(
"https://www.lagou.com/jobs/list_python?city=
%E5%85%A8%E5%9B%BD&cl=false&fromSearch=true&labelWords=&suginput=")
content = ses.post(url=url, data=datas)
这样就可以得到存储职位信息的json对象,先创建一个空的列表,然后对json格式的数据进行编码转换,遍历获得工作地点、学历要求、公司名、发布时间、职位名称、工作年限、福利待遇、工作类型、薪资等,这样数据获取的工作就完成了。
2.2 爬虫主函数的编写
首先确定将要交给爬虫的工作量,代码如下:
page=int(input('请输入你要抓取的页码总数:')),
接下来设置一个空的列表,并设置好表头信息,代码如下:
info_result=[]
title=['岗位id', '城市', '公司全名', '福利待遇', '工作类型',
'工作地点', '学历要求','发布时间', '职位名称', '薪资',
'工作年限']
info_result.append(title)
之后利用循环以及try,except模块循环采集信息。代码如下:
for x in range(1, page+1):
url'https://www.lagou.com/jobs/positionAjax.json?
needAddtionalResult=false'
datas={
'first': 'false',
'pn': x,
'kd': 'python',
}
try:
info=get_json(url, datas)
info_result=info_result + info
print("第%s页正常采集" % x)
except Exception as msg:
print("第%s頁出现问题" % x)
采集好信息后,将采集到的信息存储在Excel表中以备待用。
3 数据的可视化展示
这里主要对上面爬取到的数据进行清洗和分析,再通过Excel表可视化展示。基本步骤为:提出问题,理解数据,数据清洗[4],构建模型,数据可视化[5]。
3.1 提出问题
本次数据分析主要研究的问题为:
⑴ 各个城市的招聘情况;
⑵ Python工程师招聘对于学历的要求;
⑶ Python工程师招聘对于工作年限的要求。
3.2 理解数据
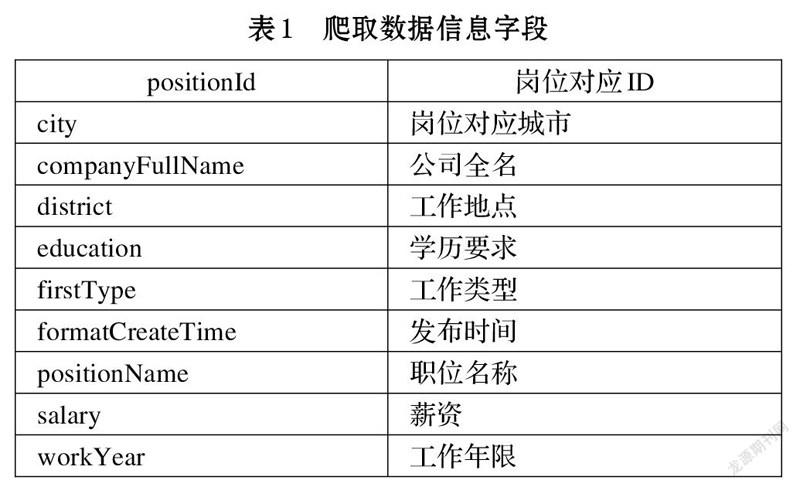
本次爬取的数据一共有10个字段,如表1所示。
3.3 数据清洗
数据清洗的步骤为:①选择子集,②列名重命名,③删除重复值,④缺失值处理,⑤一致化处理,⑥数据排序,⑦异常值处理。
⑴ 选择子集
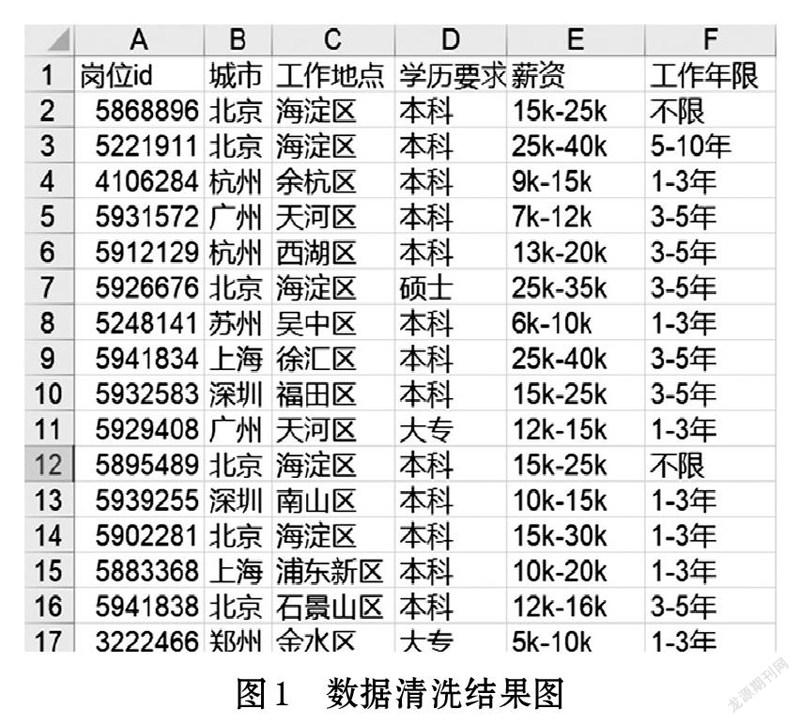
根据提出的问题,本次分析主要要用到的有positionId、city、district、education、salary以及workYear字段。先将不需要的信息进行删除或隐藏,可以得到清洗结果,如图1所示。
⑵ 删除重复项
在前面的步骤中列名已经设置好了,所以可以忽略列名的重命名这项工作,直接进行删除重复项的工作。由于每一个岗位都有一个它们独特的岗位id,所以可以用该id键做主键进行去重操作,删除重复项。
⑶ 缺失值处理
对删除过重复项的数据进行查看,发现不存在缺失值,所以这项操作就可以直接忽略了。如果存在缺失值的话,可以用以下方式进行填充。①通过人工手动补全。②删除缺失数据。③用平均数,中位数,众数等统计值进行代替。④用机器学习的算法或者是统计模型来计算出相应的值,并用该数据进行填充。
⑷ 一致化处理
对于薪资列,都是数字,之后可能会进行排序的操作,而且这部分的数据以范围的形式存在,不好处理。所以将这个薪水列细化为:最低月薪[bottom],最高月薪[top],平均月薪三列。
3.4 构建模型和数据可视化
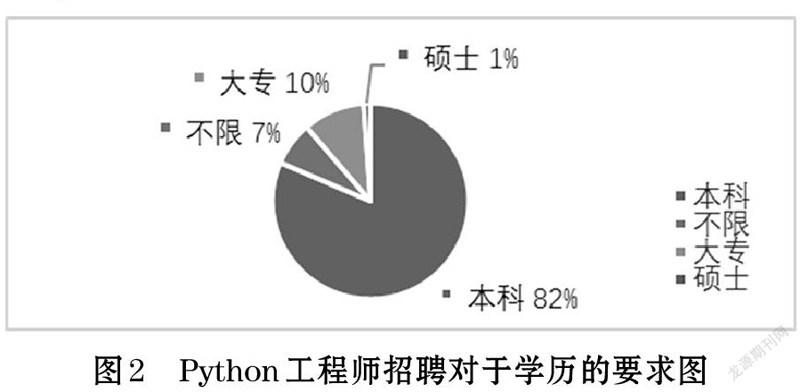
数据清洗的工作做完之后,就开始进行模型的构建,这部分主要用到的Excel表中的数据透视图来进行关系之间的建模。根据提出的问题构建模型:Python工程师招聘对于学历的要求(如图2)。
从图2可以看出,我国对于Python工程师的学历并不是很看重。本科生的机会岗位有360个,占了总岗位数量的82%。大专学历次之。也就是说,现阶段对于Python工程师人才需求,准入的门槛不高。
Python工程师各个城市的招聘情况如图3所示。由图3各个城市的招聘情况看,北京明显一枝独秀,有148个岗位机会,上海和深圳次之,分别有87和75个。可以看出北上深等城市对于Python工程师的需求多。
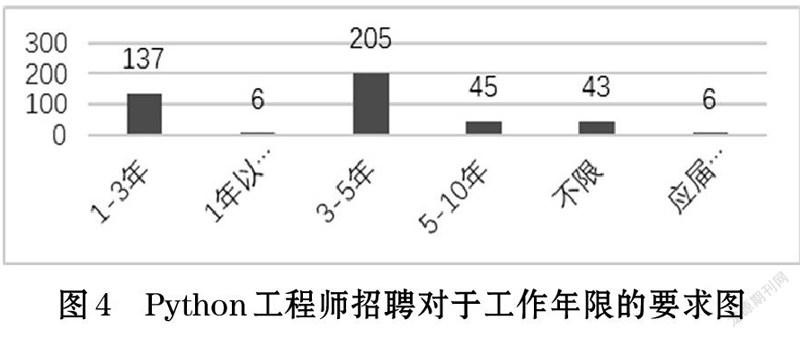
Python工程师招聘对于工作年限的要求如图4所示。从图4可以看出,3-5年工作经验的机会岗位比较多,几乎占据了总岗位的一半。接下来是1-3年工作经验的,有137个。而招聘应届生和工作经验在一年以下的几乎没有。
4 结论
本文设计了一个基于Python的爬虫,爬取拉勾网招聘信息,对数据进行清洗以及可视化的分析。通过可视化的图表分析得出:北上深等一线城市对Python工程师的需求较多,对于Python工程师的学历要求不高,但对工作经验要求较高。
参考文献(References):
[1] 宋超,华臻.电脑编程技巧与维护[J].2021.2
[2] 郭锋锋.基于python的网络爬虫研究[J].佳木斯大学学报
(自然科学版),2020.3
[3] 张懿源,武帅等.基于Python的疫情后就业影响分析[J].
计算机时代,2021(1)
[4] 戴瑗,郑传行.基于Python的南京二手房数据爬取及分析[J].
计算机时代,2021(1)
[5] 魏程程.基于Python的数据信息爬虫技术[J].电子世界,
2018(11):208-209
