高语义相似度的文本对抗样本生成方法
2022-02-18汪可馨
汪可馨
(安徽理工大学 计算机科学与工程学院,安徽 淮南 232001)
文本对抗样本的存在降低了基于深度神经网络的分类模型鲁棒性和安全性[1],但对文本对抗样本的研究有助于建立针对此类攻击的检测防御工作,提高文本分类模型的鲁棒性和安全性。目前的文本对抗攻击研究根据扰动粒度可分为字符级攻击、词级攻击和句级攻击。词级攻击因其在攻击效果和样本质量等方面表现更好而受到更多关注。现有的词级攻击方法主要有白盒条件下基于梯度的攻击和黑盒条件下基于重要性的攻击。Papernot等[2]提出白盒条件下基于梯度的攻击方法,该方法虽然在LSTM模型上达到很高的攻击成功率,但所生成的对抗样本的语法错误率也非常高。Sato等[3]提出iAdv-Text,通过在嵌入空间中使用余弦相似度限制扰动的方向找到输入文本中单词的替换词,减少了拼写和语法错误。Wang等[4]提出快速梯度投影方法(FGPM),将词替换引起的分类置信度变化近似为梯度大小与原词和其同义词在梯度方向上投影距离的乘积,从而选出最优替换词。以上基于白盒条件下的攻击虽然可以达到很好的攻击效果,但在实际生活中应用较少,日常使用较多的是黑盒条件下基于重要性的攻击。
为了避免基于梯度的方法应用于文本领域的局限性,Alzantot等[5]提出一种基于遗传算法的词级黑盒攻击方法来生成语义和语法相似的对抗样本,解决了离散文本的生成和搜索难题。Ren等[6]提出概率加权词显著性方法(PWWS),该方法虽然保持了很低的词替换率,但低词替换率不等价于高语义相似度,不能保证产生最优的结果。Jin等[7]提出一种有效攻击BERT模型的黑盒攻击方法TEXTFOOL。但以上研究大都针对英文文本,语言不同使得针对英文文本的方法不能直接应用到中文数据上。因此,王文琦等[8]提出一种针对中文文本的词级黑盒攻击方法WordHanding,该方法生成的对抗样本虽然可以表达原始文本的意思,但视觉上的扰动太大,影响了对抗样本的质量。仝鑫等[9]也提出一种基于重要性的中文文本对抗样本生成方法CWordAttacker,采用定向词删除评分机制,确定关键词后使用繁体、拼音替换等多种攻击策略生成与原句语义一致的对抗样本。以上基于黑盒条件的研究虽取得很好的成果,但攻击效果和对抗样本质量仍有提升空间,尤其先前的工作容易忽视语义相似性的约束和评估。
本文在前人探索的基础上,提出一种新的在黑盒条件下基于同义词替换的词级文本对抗攻击方法,基于分类概率变化为单词找到最佳同义词且保证词性相同,再根据语义相似度确定最优的对抗样本,在保证攻击成功率的同时最大化了与原始样本的语义相似性,满足词汇、语法和语义的约束,最后通过使用所生成的对抗样本进行对抗训练,提高了模型的鲁棒性,使模型能够有效防御此类攻击。
1 高语义相似度文本对抗样本生成
1.1 对抗样本参数定义
给定一个包含r个输入样本的输入空间X和一个包含k个可能输出标签的输出空间Y,x=w1w2…wi…wn表示由n个单词组成的输入样本,x∈X,wi∈D,D表示包含输入样本中所有可能单词的字典,Y={y1,y2,…,yk},分类器F需要学习一个从输入样本x∈X到正确标签ytrue∈Y的映射f:X→Y。在文本分类任务中,分类器F可以根据最大后验概率将输入样本x正确分类为ytrue,即
(1)
式中:P(yi|x)表示分类器F将输入样本x映射到标签yi的概率,概率最大的标签即为正确标签ytrue。
攻击者通过在x上添加一个不易察觉的扰动Δx生成对抗样本xadv,使分类器F输出错误标签,即
(2)
则对抗样本xadv的定义为
xadv=x+Δx,
(3)
1.2 算法描述
一个高质量的对抗样本在攻击效果好的同时需要令扰动足够小以使人无法察觉,这就要求文本对抗样本满足词汇、语法和语义约束。具体而言,就是不能出现单词拼写错误,语法必须正确,原始样本的语义不应发生显著变化。本文方法基于同义词替换,避免出现单词拼写错误,满足了词汇约束,过滤停用词,再为其余非停用词的单词找到词性相同的替换词,保证语法正确,满足了语法约束,按照分类概率变化程度排序“原词-替换词”,保证攻击性能,最后根据语义相似度进行数轮单词替换,决定最终的对抗样本,最大化与原始样本的语义相似度,满足了语义约束。算法流程如图1所示。

图1 对抗样本生成流程
1.2.1 过滤停用词
过滤停用词是自然语言处理中的一个预处理方法,停用词是指文本中所含信息很少的单词,如冠词、介词、代词、连词等。停用词在人类语言中大量存在,但所含的信息量却很少,删除这些词可以关注文本中更重要的信息,并且会减小数据集的大小,从而提高效率。鉴于对效率的考虑,本文方法只保留名词、动词、形容词和副词,而将其他词性的单词都设置为停用词,特别指出,专有名词也被设置为停用词,如人名、地名、国家名等。
1.2.2 选择替换词

(4)

1.2.3 排序“原词-替换词”
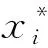
(5)

为保证最大化语义相似度,仅使用此排序前25%的单词进行下一步的单词替换。
1.2.4 单词替换

2 实验
为进行实证评估,在两个目标模型上用两个流行数据集进行了试验,比较本文方法与其他攻击方法所生成的对抗样本对模型分类准确度的影响及与原始样本的语义相似度,用来评估方法的攻击效果和对抗样本质量,并进行对抗训练,验证其防御效果。
2.1 实验设置
实验所使用的数据集是AG’s News和DBPedia。AG’s News是一个多类的新闻分类数据集,分为4个类:World、Sports、Business和Sci/Tech,每个类包括30 000个训练样本和1 900个测试样本。DBPedia数据集是通过从DBPedia 2014中挑选14个不重叠的类构建而成的,包括Company、Athlete、Artist、OfficeHolder等类别,分别从这14个类中随机选择40 000个训练样本和5 000个测试样本进行实验。
模型采用的是卷积神经网络(CNN)和循环神经网络(RNN)。具体而言,实验使用了文献[11]中的CNN模型,该模型由3个卷积层、1个dropout层和1个最终的全连接层组成,卷积层中的滤波器大小分别为5、4、3。RNN模型使用的是长短期记忆网络模型(LSTM),该模型将CNN的3个卷积层替换为3个LSTM层,每个层有128个单元。为了评估本文方法的攻击效果,将其与PWWS和FGPM两种方法进行对比,这两种方法都是基于同义词替换的文本对抗攻击方法,其中PWWS是黑盒攻击,FGPM是白盒攻击。
2.2 攻击结果
从对抗样本的模型分类准确度和与原样本的语义相似度2个方面评估攻击的性能。两种模型对原始样本和基于AG’s News和DBPedia数据集不同攻击方法生成的对抗样本的分类准确度如表1 所示。攻击方法越有效,模型的分类准确度下降得越多。结果表明,与PWWS和FGPM相比,在4种情况下,本文方法最大程度降低了模型的分类准确度,在AG’s News上平均降低了61.95%,在DBPedia上平均降低了60.5%。

表1 不同分类方法的分类准确度
不同方法生成的对抗样本与原始样本的语义相似度如表2所示。语义相似度的计算方法与1.2中用到的方法相同,使用TF-IDF模型将预处理后的样本转换为TF-IDF向量,再计算向量之间的余弦相似度,即得到样本之间的语义相似度。结果表明,与PWWS和FGPM的相比,本文方法所生成的对抗样本与原始样本的语义相似度在AG’s News上平均高7.85%,在DBPedia上平均高6.93%,不仅保证了词汇和语法的正确,也最大程度保留了语义。

表2 不同方法的语义相似度
使用本文方法在CNN模型上基于AG’s News数据集生成的对抗样本实例如表3所示。括号前的单词是原始样本中被替换的词,括号内的单词是替换词。

表3 对抗样本实例
2.3 对抗训练
防御对抗攻击的目标是建立一个强大的深度神经网络模型来很好地处理各种已知和未知的对抗攻击技术。在现有的研究中,主流的防御策略可分为对抗样本检测和模型增强,对抗样本检测是指根据观察到的细微差异直接区分对抗样本和合法输入,文本领域中通常采用的是拼写检查[12],用来防御字符级攻击。模型增强包括更新模型参数或修改模型架构,例如对抗训练[13]和添加额外的层。
本文采用对抗训练评估本文方法对提高模型鲁棒性的作用。对抗训练通常是将生成的对抗样本加入到训练集中,重新训练模型,从而提高模型的泛化能力和鲁棒性,使模型在被对抗样本攻击时仍能保持较高分类准确度。为了验证本文方法所生成的对抗样本通过对抗训练是否有助于提高分类模型的鲁棒性,使用本文方法在CNN模型上基于AG’s News数据集生成4 000个对抗样本作为集合A,从集合A中随机抽取一定数量的对抗样本加入到原始训练集中,重新训练该模型,再用本文方法、PWWS、FGPM对重新训练后的模型进行攻击,如果模型相较于对抗训练之前分类准确度有所提高,即说明本文方法可以有效防御对抗攻击。如图2所示,横坐标表示从集合A中抽取加入到原始训练集中的对抗样本的数量,纵坐标表示经过对抗训练的模型对不同攻击方法生成的对抗样本的分类准确度,在对抗样本数量为1 000个时,模型被本文方法攻击即可以保持82%的分类准确度,且在对抗样本数量为3 000个时分类准确度最高,为84%。另外在用其他方法攻击时,也可以达到最高76%和68%的分类准确度,相较于未进行对抗训练分别提高了38.5%和30.5%。结果表明,用本文方法生成的对抗样本进行对抗训练可以提高模型的鲁棒性,使模型有效防御对抗攻击。

图2 对抗训练后分类准确度
3 结语
针对文本分类任务提出一种生成对抗样本的有效方法,基于分类概率变化为单词选择最佳同义词作为替换词,再由语义相似度决定最优的对抗样本。实验表明,生成的对抗样本可以大大降低文本分类的准确度,并与原始样本保持高语义相似度,满足词汇、语法的约束,使人难以察觉扰动,与其他方法相比具有显著优势。最后通过对抗训练试验,提高了模型的鲁棒性,可使垃圾邮件过滤、虚假新闻检测等应用有效防御此类攻击。不足之处是本文方法更适用于短文本,对于长文本效率较低。
