联邦学习在移动通信网络智能化的应用
2022-02-14吴墨翰马丽萌杨爱东王达叶晓舟欧阳晔
吴墨翰,马丽萌,杨爱东,王达,叶晓舟,欧阳晔
(亚信科技(中国)有限公司,北京 100089)
0 引言
近年来,物联网设备、各种传感器、智能手机等设备呈现爆发式增长,产生了大量的不同类型的数据[1-2],为了提高移动通信服务质量并实现更智能化的移动应用,在移动通信网络中引入人工智能技术受到广泛的关注。传统的思路是将利用机器学习所需的数据集中在一个中央服务器中进行模型训练和分析,然而,在部分场景下,出于隐私保护的考虑,基于数据集中式的机器学习将无法实施。同时,网络还涉及不同厂家、跨网元、跨域以及第三方应用的数据,由于厂家竞争、数据安全和地址位置等因素,数据往往以孤岛形式存在[3],无法互通,难以满足网络智能化对数据标签和特征维度的要求[4]。此外,网络地域覆盖广、数据体量大,即使数据可传输到中央服务器,也可能会占用较大的带宽和较长的传输时延,导致AI 分析效率低下[5]。
因此,移动网络需引入分布式可信的人工智能技术,能够在保护数据隐私的前提下,打破数据孤岛,解决传输短板。联邦学习作为一种能够让数据拥有者利用数据/计算/ 模型加密实现本地化共同建模的技术,可实现数据无法直接互通下的模型训练,保障用户隐私和数据安全,降低数据传输开销,为网络智能化的开展打开了新思路。本文对联邦学习的现状进行了分析,介绍了基于联邦学习的网络智能化架构,并基于该架构对客户体验管理应用案例进行了分析,对有/ 无联邦学习、独立/ 非独立同分布的实验结果分别做出了对比。实验证明,联邦学习可在无需集中汇聚各地域数据的前提下,通过联合建模的方式,提高训练模型效果,并且相比较数据的非独立同分布,独立同分布更有利于提高模型的预测能力。
1 研究背景
1.1 联邦学习研究现状
随着数据在生产生活中的重要性不断提高,数据安全问题已被人们广泛关注。2016 年,欧盟通过了通用数据保护法案(GDPR,General Data Protection Regulation)[6],并且于2018 年强制在所有欧盟国家全面实施该GDPR 法案[7-8],目的是让用户对个人数据有更强的控制能力与保护能力。与之相似地,中国政府近年来也发布了关于数据管理的法律条文,2016 年通过了《中华人民共和国网络安全法》[9],2021 年通过并实施《中华人民共和国数据安全法》与《中华人民共和国个人信息保护法》。
数据安全相关法规使现有人工智能研究面临一个重要的问题,即如何合法合规利用数据。联邦学习作为一种新的人工智能学习框架应运而生:数据源之间不直接交换原始数据,而是交换加密后的模型信息,即数据不动模型动,参与方实现数据隐私保护的同时,共同协作构建共享的学习模型。
联邦学习包含两个过程,即模型训练及模型推理。在模型训练过程中,模型相关信息以加密的方式在各参与方之间进行传输交换,合作训练好的模型,再发送给各参与方,更新各参与方本地模型,直至全局模型性能最优为止。模型推理时,训练好的模型可以运用新的数据实例进行推理预测,例如在医疗行业应用,联邦医疗图像系统可能会接受一名患者,该患者的诊断数据来自不同医院,各方协作进行病情预测,并将预测结果反馈给用户。
联邦学习的架构有两种,分别为有协调方的联邦学习架构和无协调方的联邦学习架构。有协调方的联邦学习架构即客户-服务器架构,如图1 所示,协调方视为一台聚合服务器,将初始的模型发送给各个参与方,各个参与方将各自的数据集进行训练,并将模型更新发送到聚合服务器,协调方聚合从各个参与方接收到的模型,并将聚合后的模型发送给各个参与方。无协调方的联邦学习架构即对等网络架构,如图2 所示,各个参与方之间无须借助协调方即可直接通信,提高了数据和系统的安全性,但可能需要很多的计算操作来对消息内容进行加密和解密。

图1 客户-服务器架构
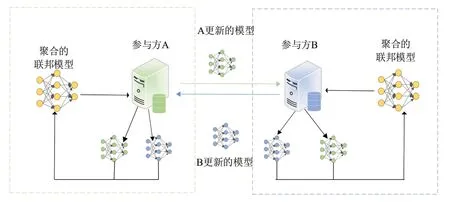
图2 对等网络架构
1.2 联邦学习标准现状
近年来,移动通信网络领域的联邦学习相关标准工作已逐步开展。国际上,2018 年12 月,IEEE 标准化协会批准了联邦学习架构和应用规范的标准P3652.1(联邦学习基础架构与应用指南)立项,2021 年3 月30 日联邦学习标准通过IEEE 确认并形成正式标准文件进行发布。2020 年6 月,3GPP R17 标准提案TR23.700-91 中提出“多NWDAF 用例之间的联邦学习”,将联邦学习引入5G 网络中[10]。在2021 年第四季度,推动“使能网络自动化阶段三”(FS_eNA_Ph3)和“5G 系统支持基于AI/ML 的服务”(FS_5GAIML)这两个R18 课题在3GPP SA2 立项,其中:在FS_eNA_Ph3 中,研究5G-Advanced 中联邦学习的应用场景、智能架构、关键技术等;在FS_5GAIML 中,研究应用层与终端之间的联邦学习。2021 年,ITU-T 在SG16 发起“联邦机器学习服务可信贡献评估框架”的新项目立项,SG20 Q3 发起“面向物联网和智慧城市的联邦学习需求与参考框架”新项目立项。在国内,2019 年3 月,中国人工智能开源软件发展联盟(AIOSS)发布团体标准《信息技术服务联邦学习参考架构》,包括联邦学习参考架构的概念、用户视图、功能视图以及两者之间的关系。中国通信标准化协会(CCSA)密切关注联邦学习,2021 年涉及联邦学习的项目包括研究课题《联邦学习数据安全保护技术研究》、《面向电信领域的人工智能联合学习应用场景和需求》、《基于分布式联合学习的5G 及演进移动通信网关键技术研究》,研究联邦学习与5G-Advanced 结合的关键使能技术及应用。
2 基于联邦学习的网络智能化架构
2.1 总体架构
基于联邦学习的网络智能化需要联邦学习技术与移动通信网络紧密结合,使得网络中各个参与方在保护数据隐私的前提下以联邦学习的方式开展网络智能化,以满足用户、运营商和行业的联合建模需求。图3 为中国移动提出的面向联邦学习的分布式智能网络架构[11]。
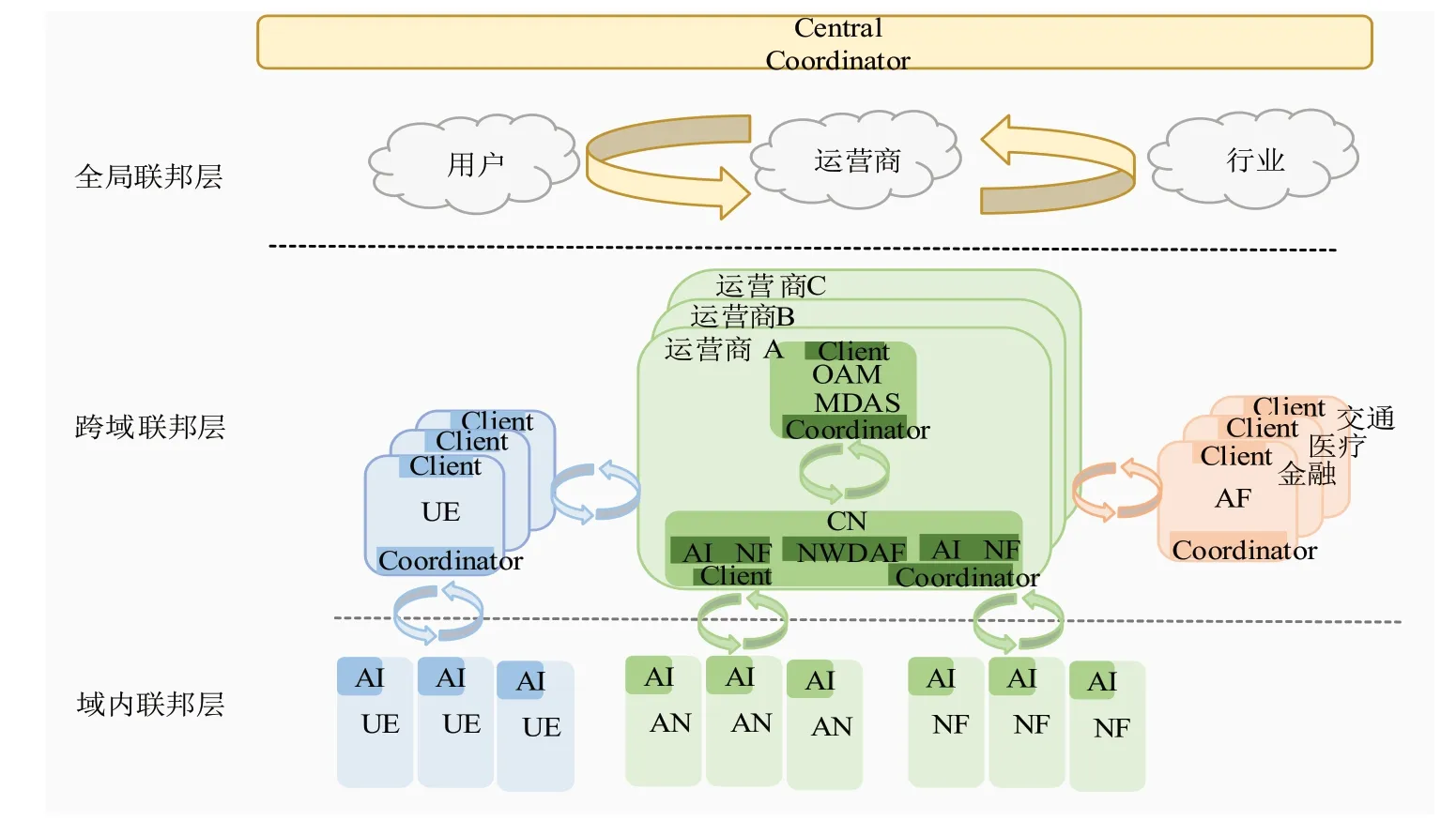
图3 面向联邦学习的分布式智能网络架构
该架构包括域内联邦、跨域联邦、全局联邦三层,涉及用户、运营商和行业等AI 建模需求方。在全局联邦层中,运营商可作为Central Coordinator,成为用户和行业的纽带,提供跨界互通、任务协调、资源调度、安全认证等功能,解决用户与行业之间的跨域隐私等问题,打破各行业间的数据孤岛。在跨域联邦层中,运营商侧主要包括OAM(Operation Administration and Maintenance,操作、维护和管理)、CN(Core Network,核心网络)等网络节点,这些节点可承担Client、Coordinator 双重角色。当作为Coordinator 时,协调域内或者域间各个节点间联邦学习;当作为Client 时,作为参与方参与域内或者域间联邦学习,例如CN 中的NWDAF[12](Network Data Analytics Function,网络能力分析功能)可以协调域内NF(Network Function,网络功能)/其他域联邦学习,用户侧的UE 和行业侧AF 均可作为Coordinator/Client 实现域内或者域间联邦学习。
2.2 实现架构分类
基于联邦学习分类特征(客户-服务器架构、对等网络架构)及未来网络的发展,基于联邦学习的网络智能化架构可分为中心化的联邦学习网络架构和去中心化的联邦学习架构[13]。
如图4 所示,以核心AI 单元的Coordinator 为中心节点,协助核心网、终端、无线、网管、应用等领域进行域内或者域间联邦学习。中心节点将初始模型发送至分布式节点,分布式节点使用自己本地的数据集训练模型,并将模型权重更新信息发送至中心节点,数据不出本地,保证了用户隐私和数据安全,中心节点将从各个分布式节点接收到的模型更新进行聚合,并将聚合后的模型发送给各个分布式节点,分布式节点接受聚合后的模型,开始更新本地模型,应用新的数据实例,进行本地化推理[14]。例如在移动通信网络架构中,核心网元NWDAF 可作为中心节点协助域内或者域间联邦学习,应用于监测域内各节点的异常情况或者提供端到端的整体业务质量服务。

图4 中心化的联邦学习网络架构
去中心化联邦学习网络架构如图5 所示,该架构无需中心节点Coordinator,核心网、终端、无线、网管、应用等领域智能单元之间也无需借助第三方即可直接通信,交换模型中间结果进行共同建模,可采用轮流制,各个分布式节点可以临时承担中心节点任务。临时中心节点将初始模型发送至分布式节点,分布式节点使用自己本地的数据集训练模型,并将模型权重更新信息发送至临时分布式节点,数据不出本地,保证了用户隐私和数据安全,临时中心节点将从各个分布式节点接收到的模型更新进行聚合,并将聚合后的模型发送给各个分布式节点,分布式节点接受聚合后的模型,开始更新本地模型,应用新的数据实例,进行本地化推理。临时中心节点应选择当前性能相对较高或者资源空闲的分布式节点,例如域内各节点的智能业务监测或者域间端到端智能辅助用户选网等场景。
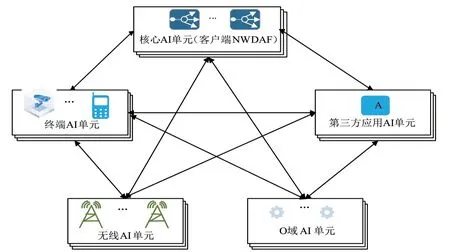
图5 去中心化的联邦学习网络架构
综上所述,中心化的联邦学习网络架构可面向规模大、跨域的业务场景应用,去中心化联邦学习网络架构则适用于小规模、域内的场景应用,两种架构可相互补充、结合使用。在选择联邦学习网络架构时,可根据业务应用场景统筹考虑。
3 客户体验管理应用案例
3.1 案例简介
情感链结分数(ECS,Emotional Connection Scoring)是评价用户对公司品牌忠诚度的一个重要标准,更高的分数意味着用户对公司产品理念的认同感更高。相对于用户对公司及相关产品的满意度评分,ECS 更好地描述了一个用户的未来潜在价值。为了获得更加精准的ECS,大量的数据分析是必不可少的。通常ECS 的计算方法是结合用户体验评分和服务信息计算,按照规定,用户体验评分属于用户隐私数据,不能随意交换,因此,需要使用联邦学习框架来进行分析,以遵守相关的数据安全规则。
客户体验管理(CEM,Customer Experience Management)是一个结合联邦学习与ECS 的实际应用案例。CEM 是近年兴起的一种崭新客户管理方法和技术,是战略性地管理客户对产品/业务或公司全面体验的过程,通过对客户体验加以有效把握和管理,可以提高客户对公司的满意度和忠诚度,并最终提升公司价值。该场景的目标是获得ECS 端到端体验评估,从而为后续服务与用户反馈提供帮助。所需分析的数据一方面是O 域(OSS,Operation Support System)信息,如终端和网络故障的数据;另一方面是B 域(BSS,Business Support System)信息,如用户的关键事件详细信息、退服影响、工单开启和关闭等。具体输入信息如表1 所示。基于这些输入,使用基于电信心理学的ECS 评测算法,计算得到用户对于高清语音和数据业务的评分。最后根据评分的变化趋势为用户提供服务,主动向客户提出解决方案以及赋予开启工单并反馈的能力。

表1 客户体验评分ECS算法输入数据
本案例选取了重庆市的渝南、城一、渝中南、渝东、渝东北、城三、渝西北、渝东南、城二、渝西北等10 个大区的数据进行实验。
3.2 部署架构
本案例共选取10 个大区,每个大区可视为一个节点,将模型训练放置于每个大区中的NWDAF 网元节点中,由于涉及的大区数量较多,将以3 个大区进行具体说明。由于本案例中各个区域节点所包含的数据类型相似,且具有相同的数据特征和标签,因此符合使用横向联邦学习算法的条件。如图6 所示,本案例架构采用了基于横向联邦学习的网络智能化架构中的中心化联邦学习架构,在此架构中将首次发起联邦学习的大区节点设置为中心节点,其他大区设为分布式节点即从节点,根据上述的输入数据信息,各个大区节点将收集来自UPF(User Platform Function,用户平面功能)网元、OMC(Operation and Maintenance Center,操作维护中心)的数据。

图6 客户体验管理应用架构
3.3 工作流程和算法
在本案例中,工作流程如图7 所示。

图7 联邦学习工作流程图
①10 个大区中的某个大区的节点向本区内的NWDAF A 发起联邦学习请求。
②将首次被触发联邦学习的NWDAF 设为中心节点,即将NWDAF A 作为中心节点,开启联邦学习。
③中心节点NWDAF A 向从节点NWDAF B 和NWDAF C 发起联邦学习请求,包括一些参数(数据类型列表、最大响应时间窗口),以帮助本地模型训练进行联邦学习。
④从节点NWDAF B 和NWDAF C 向中心节点NWDAF A 响应,同意加入联邦学习。
⑤各个从节点NWDAF 通过从OMC 和UPF 中收集其本地数据,从节点NWDAF B 和NWDAF C 根据其自身的数据和从中心节点NWDAF A 接受到的参数,进行客户体验感知模型训练,根据算法需要,NWDAF B 和NWDAF C 可以对中间结果进行加密和交换。中间结果双方用来计算模型的梯度(参数)和损失。
⑥从节点NWDAF B 和NWDAF C 将加密模型梯度(参数)与加密损失传输给NWDAF A。
⑦中心节点NWDAF A 聚合各个从节点发送的模型信息,将聚合后的模型信息发送给从节点NWDAF B 和NWDAF C,各个从节点根据中心节点分发的聚合模型信息更新本地模型。
⑧重复步骤⑤~ ⑦,直到完成整个客户体验感知模型的训练。
⑨训练过程完成后,可以将全局最优的客户体验感知模型或模型参数分配给各个从节点NWDAF 进行推理应用。
整个训练过程中双方数据都不出本地,互相交换的是模型加密梯度(参数)和中间结果,没有暴露彼此的用户隐私数据,符合相关数据隐私法规,因此整个模型是安全的、可控的。
具体算法如下:
事先定义:B 节点数据集{xb}和对应标签集{yb},C 节点数据集{xc}和对应标签集{yc},同态加密算法[[·]],满意度预测算法F(x,θ),其中F是各参与方共同使用的神经网络预测算法、x是输入数据、θ是神经网络参数、F(x,θ)是通过神经网络预测的标签结果,损失函数L采用平方损失函数。


3.4 实验结果
(1)无联邦学习与有联邦学习测试结果
用于实验的案例设定为通过用户数据预测用户对于各项服务的满意度以及整体满意度,其中用户数据包括套餐费用、上传下载速率、通信时延、音视频时延等O 域及B 域等信息,目标满意度包括手机上网满意度、资费满意度、语音通话满意度和整体满意度。为了测试联邦学习对实际预测效果的影响,每个地区的用户数据汇集在各自地区所分配的NWDAF中,随机抽取90%数据作为训练集,剩下10%数据作为测试集。实验时先使用本地区数据在本地NWDAF 执行无联邦学习的模型训练,再使用全部地区数据在全区NWDAF 组成的联邦学习架构中进行多数据源的联邦学习训练。结果如图8 所示,在所有地区,使用联邦学习的模型准确度都显著高于无联邦学习的准确度。实验结果证实联邦学习可以有效整合多个数据源的数据,并提高训练模型效果。

图8 无联邦学习与有联邦学习测试结果
(2)独立同分布与非独立同分布的测试结果
另外在实验时,数据的分布也会对结果造成影响。在概率统计理论中,如果变量序列或者其他随机变量有相同的概率分布,并且互相独立,那么这些随机变量是独立同分布的。而当变量不满足独立或者不满足相同概率分布时,这些随机变量被称为非独立同分布(Non-IID,None Independently Identically Distribution)变量。在传统应用场景中,数据存储在中心,机器学习模型可以获取所有数据的整体信息,因此可以假设训练数据和测试数据是满足相同分布的,它是通过训练数据获得的模型,能够在测试集获得好效果的一个基本保障。但是在联邦学习中,由于数据仅存储在本地,不同用户间由于地理位置和个人习惯等因素,导致数据之间存在概率分布的不一致性,因此联邦学习使用的是非独立同分布数据。而且由于模型的训练是先在本地进行,生成局部模型参数,因此可能会导致整合后的全局模型效果并不能很好地适应局部数据的特点。
为测试独立同分布特性对联邦学习的影响,本案例增加了相关实验。由于用户对各项业务的需求不同,因此数据的分布会出现差异。实验设计如下:首先使用每个地区的语音通话满意度及相关用户数据进行联邦学习,两个预测模型结构分别为多层感知器(MLP)和卷积神经网络(CNN),计算10 个训练周期后模型精度,然后使用整体满意度和与上一步同数量级的数据重复之前的实验。实验结果如表2 所示,对于不同的训练模型结构,使用同一数量级的非独立同分布数据的模型预测结果比独立同分布数据的准确度都有所下降。这个结果意味着当使用联邦学习时,确保数据的独立同分布特性可以提高模型的预测能力。

表2 IID与Non-IID数据的联邦学习测试准确度
4 结束语
本文介绍了联邦学习发展背景、技术概念、算法原理与分类,研究了联邦学习在移动通信网络中应用的标准进展以及基于联邦学习的网络智能化整体架构与分类,并通过应用此架构进行了客户体验管理案例分析,对训练结果做出归纳总结,为该架构的实际应用提供了参考和借鉴。未来联邦学习的发展方向可以是设计模型算法来降低非独立同分布的数据对模型效果的影响,从而提高联邦学习的适用性,推进联邦学习在移动通信网络应用的标准,更好地应用于各行各业,发挥更大的效能。
