基于知识图谱推理的风险车辆识别方法研究 *
2022-02-10俞山川谢耀华
俞山川,谢耀华,陈 晨,周 健
(招商局重庆交通科研设计院有限公司 自动驾驶技术交通运输行业研发中心,重庆 400067)
0 引 言
随着高速公路数字化、智能化建设的加速,高速公路运营者基于海量运营数据为每辆车建立电子档案,通过运维管控系统对潜在风险车辆进行识别、监控和预警。高速公路运营者可从2个方面进行数据收集:①从具有车辆属性识别、事件检测模块的高速公路路侧信息采集设施(如:摄像头)获取车辆颜色、车型、车牌号、异常驾驶行为类型(如:超速、倒车、停车)等信息,并在运维管控系统中存储为结构化数据;②从外部相关网站(如:各省市交通运输局官方网站)抓取公开文本资料(如:交通违法判决书)等半结构化数据,获得车辆颜色、车型、车牌号、所属公司、历史违法行为(如:擅自改装运输危化品、危险货物运输专用车辆未悬挂或喷涂危险货物运输标识、未采取必要措施防止货物脱落扬撒)等信息。目前,如何将这些多源异构的信息进行融合,找到车辆和风险之间的潜在联系,形成知识体系,从而让风险车辆被快速“捕捉”,这是一个亟需解决的问题。
知识图谱是一种用图模型来描述知识和建立世界万物之间关联关系的技术方法,旨在从多源数据中识别、发现和推断事物与概念之间的复杂关系[1],将孤立的数据信息整合在一起。因此,知识图谱可以有效地从多源异构数据中挖掘出车辆与风险相关联的问题。知识图谱的自动构建主要通过传统关系型数据库转化和互联网开放数据抽取[2]。前者依赖关系型数据库到本体模型的映射,通过映射表将关系型数据库的表结构数据转化为图数据库中的三元组数据[3],适用于运维管控系统中的结构化数据;后者则需要知识抽取和推理算法支撑,从半结构化的网页数据抽取本体模型中定义的本体、属性和关系,并通过推理对潜在关系进行完善[4],适用于从外部相关网站抓取公开文本资料,该部分是知识图谱构建的重点和难点。
近几年,研究者针对纯文本中自动构建或填充知识库,在知识图谱表示学习或知识图谱嵌入方面做了很多工作,目的是将实体和实体间的关系映射到连续低维度的向量空间,简化知识图谱的计算,捕获知识图谱中数据固有的复杂性和语义[5]。典型的嵌入技术包含3个步骤:①表示实体和关系;②定义得分函数;③学习实体和关系的表示。表示模型分为转移距离模型和语义匹配模型2类。前者使用基于距离的得分函数,主要包括TransE系列模型[5]、考虑实体和关系不确定性的高斯嵌入模型[6-7];后者使用基于相似度的得分函数,主要包括RESCAL系列模型[8]、神经网络匹配模型[9-10]。TransE系列模型参数较少、简单高效、可解释性强,其中的TransH[11]、TransD[12]和TransR[13]能很好地建立一对多、多对一和多对多的复杂关系,适用于高速公路运维管控系统中海量风险车辆数据知识图谱的建立。实体和关系的表示学习普遍采用开放和封闭世界2种假设[14]。其中,开放世界假设更适合于不完整知识图谱,而且在训练微调中的效果更好。尽管运维管控系统中存储有海量车辆数据,但从结构上讲,相关数据仍属于不完整知识图谱。因此,开放世界假设更适合笔者的研究内容。
知识推理旨在从已有关系数据中推断出新的关系,从而丰富知识图谱,支撑更进一步的应用。知识推理可以分为对实体属性的推理和对实体关系的推理。前者主要包括对会发生变化实体的属性值进行及时的发现、更新,或者为实体创建新的属性;后者则是对实体间潜在的关系进行推断和补充,适用于车辆和风险潜在关系的建立。基于逻辑规则的知识推理是关系推理中应用最广泛的一类方法,主要包括谓语逻辑推理、本体推理和随机游走推理等。其中,随机游走推理模型由于其高准确度和高计算效率,适合大型知识图谱的构建[15]。
综上,笔者选择考虑一对多、多对一和多对多关系的表示模型,基于开放世界假设进行知识学习,从半结构化的网页数据中进行车辆信息的关系提取,采用随机游走推理模型进行基于逻辑规则的知识推理,从而完成基于表示学习的高速公路风险车辆知识推理和图谱构建,以达到识别潜在风险、将知识图谱技术应用于高速公路运行风险预警管控场景的目的。
1 问题描述
1)引入三元组的概念:假设有一个包含n个实体,m个关系的知识图谱,其中事实被存储为三元组D+={(h,r,t)|hE,rR,tE}。每个三元组由一个头实体hE、一个尾实体tE和两者之间的关系rR组成。其中E表示实体集,R表示关系集。例如:(渝A***08,隶属于,重庆**运输有限公司)、(渝A***08,违法类型为,危险货物运输专用车辆未悬挂、未喷涂危险货物运输标识)、(李**,驾驶,渝A***08)等。
2)从各省市交通运输局官方判决书文本中,通过三元组抽取技术[16]筛选所有可能的三元组。三元组抽取技术包括基于网络爬虫的文档正文提取和基于CoreNLP句法解析的实体关系抽取[17]。根据各省市交通运输局官方判决书文本数据,确定高速公路风险车辆类型:①未采取必要措施防止货物脱落扬撒;②擅自改装已取得《道路运输证》的车辆;③危险货物运输车未随车携带《道路运输证》;④运输车辆为报废、擅自改装、拼装、检测不合格或其他不符合国家规定的车辆;⑤运输车辆未按照规定的周期和频次进行车辆综合性能检测和技术等级评定;⑥违法超限运输;⑦未在罐式车辆罐体的适装介质列表范围内或者移动式压力容器使用登记证上限定的介质范围内承运危险货物;⑧危险货物运输专用车辆未悬挂、未喷涂危险货物运输标识;⑨危险货物承运人未按照规定制作危险货物运单或者保存期限不符合要求;⑩客运班车不按规定的线路、班次行驶;未按规定取得道路货物运输经营许可证,擅自从事道路货物运输经营;未取得道路危险货物运输许可,擅自从事道路危险货物运输;未取得相应从业资格证件,从事道路危险货物运输活动;未按照规定使用卫星定位汽车行驶记录仪进行实时传送。
2 模型建立
2.1 建模步骤
2.1.1 实体和关系的表示及得分函数的定义
将实体和关系映射在一个连续的向量空间中,表现成向量;在每个事实(h,r,t)上定义得分函数fr(h,t)以量化似然性,观测到的事实比未观测到的事实有更高的得分。
2.1.2 学习实体和关系的表示
随机生成负样本,学习这些实体和关系的表示,解决所有观测事实(即D+中的事实)的最大似然优化问题。
2.1.3 推理实体间潜在关系
基于所有三元组推断不同三元组实体之间的潜在关系。
2.2 TransH、TransR和TransD关系表示模型

尽管TransE简单高效,但在处理一对多、多对一和多对多关系时仍有缺陷。以1对N关系为例,给定一个关系r,即∃i=1,…,m,TransE使得h+r≈ti对所有i=1,…,m成立,并且t1≈t2≈…≈ti。这表明,给定一个1对N关系,TransE对t1、t2、…、ti可能会学习出十分相似的向量表达。事实上,这些实体是完全不同的。为克服此缺陷,可采用一种有效的策略即允许实体在不同的关系中有明显不同的表现形式。TransH通过引入特定关系的超平面,实现了这个理念。
2.2.1 TransH模型
如图1(a),TransH将实体表示成向量,将每个关系r表示成在以wr为法向量的超平面上的向量r。给定一个事实(h,r,t),实体向量h、t首先被投影在超平面上,即
(1)
如果(h,r,t)成立,假设两个投影通过超平面上的r以较小的误差连接,即h⊥+r≈t⊥,则,得分函数定义为

(2)
各向量的约束条件为
(3)
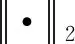

图1 TransH、TransR和TransD模型原理Fig. 1 Principles for TransH, TransR and TransD model
2.2.2 TransR模型
(4)
式中:Mr为从实体空间到关系空间r的投影向量,Mrk×d。
TransR的得分函数定义为
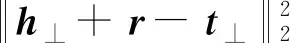
(5)
各向量的约束条件为
(6)
(7)
2.2.3 TransD模型
TransD通过进一步将投影向量分解成两个向量的积进行简化,即用投影向量来获取头、尾实体关于关系的向量表示,如图1(c)。TransD引入额外的映射向量wh,wtd和wrk,其中实体向量和关系向量h,td和rk。投影向量和被定义为
(8)
(9)
式中:I为单位向量。
将这2个投影向量分别施加在头实体向量h和尾实体向量t上,得到投影
(10)
(11)
得分函数用式(12)计算:
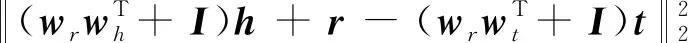
(12)
各向量满足约束条件(13)、(14):
(13)
(14)
2.3 基于开放世界假设的模型训练
开放世界假设表述如下:知识图谱只包含真实的事实,而未被观测到的事实只会是错误的或者丢失了。在此情形下,D+只存储正样本,负样本通过启发式生成。(h,r,t)的负样本用D-表示,D-={(h′,r,t)∪(h,r,t′)}。在训练过程中,负样本通过随机替换头实体h或尾实体t得到,即
D-={(h′,r,t)|h′E∧h′≠h∧(h,r,t)D+}∪{(h,r,t′)|t′E∧t′≠t∧(h,r,t)D+}
(15)
给定正样本集D+和相应建立的负样本集D-,可以通过最小化对数损失值[14]来学习实体和关系表示Θ,即
(16)
式中:τ=(h,r,t)为D+∪D-中的训练样本。
如果(h,r,t)D+,yhrt=1;(h,r,t)D-,则yhrt=-1,从而保证正样本的得分高于负样本。
此外,此最小化问题还需要满足向量的约束条件,对于TransH模型,为约束条件(3);对于TransR模型,为约束条件(6)、(7);对于TransD模型,为约束条件(13)、(14)。
模型训练还需要对于实体和关系进行初始化嵌入,通常通过均匀分布或高斯分布随机初始化,或使用TransE的结果来初始化嵌入。以TransD模型为例,基于开放世界假设的训练算法步骤如下:
Step 1给定观测到的事实D+={(h,r,t)},初始化实体和关系嵌入。
Step 2从D+中取一个正事实的小集合Z,生成2个空集合B+=∅、B-=∅。
Step 3对Z中的每一个正样本τ+=(h+,r+,t+),根据式(15)生成一个负样本τ-=(h-,r-,t-),并更新集合B+=B+∪{τ+},B-=B-∪{τ-}。

Step 5若梯度近似于0,返回Step 2;否则,输出实体和关系嵌入。
2.4 基于随机游走的知识推理模型
推理的目的是使用机器学习的方法推断出实体对之间的潜在关系,从而完善知识图谱。例如,如果风险车辆知识图谱包含关系(李**,驾驶,渝A***08),(渝A***08,隶属于,重庆**运输有限公司),然后可以获得丢失的关系(李**,工作于,重庆**运输有限公司)。
笔者基于随机游走模型[19],推断出不同三元组实体之间的潜在关系。计算每条路径的特征值函数sh,Q(t),从而建立一系列路径。一个路径Q由一系列的关系向量r1,…,rl,…,rn组成,即
式中:Tn-1为关系向量rn的作用域及关系向量rn-1的值域,即Tn-1=ran(rn)=dom(rn-1)。
关系的作用域和值域指的是实体的类型,T0={h},Tn={t}。特征值函数sh,Q(t)为沿着路径Q从头实体向量h开始能够到达尾实体向量t的概率。路径走到任意中间实体向量e时,sh,Q(e)的更新方法为
(17)
在随机游走的初始阶段,如果eQ,sh,Q(e)=1;否则,sh,Q(e)=0。I(rl(e′,e))是指示函数,如果rl(e′,e)存在,I(rl(e′,e))=1;否则,I(rl(e′,e))=0。
通过随机游走算法得到一系列路径特征Qr={Q1,…,Qn},然后对关系向量r下的每个训练样本(即一个头实体和尾实体的组合)建立得分函数
fQ(hk,tk)=θ1shk,Q1(e)+θ2shk,Q2(e)+…+θnshk,Qn(e)
(18)
每个样本的概率为
(19)
损失函数最小化的表达式为
minwk[yklnPk+(1-yk)ln(1-Pk)]
(20)
式中:yk为训练样本向量(hk,tk)是否具有关系向量r的标记。
如果三元组向量(hk,r,tk)存在,则yk=1;否则yk=0。
训练算法流程与TransD模型训练算法类似,不做详述。
3 算例分析
3.1 数据集
对广东省下属市交通运输局2020年1—8月公开的交通违法判决书文本(图2)抽取三元组数据,对TransH、TransR和TransD模型进行性能比选和知识图谱结果展示。
采集广东省肇庆、东莞、云浮、佛山、茂名、中山、惠州、韶关、汕头、揭阳、江门、梅州、河源、阳江、潮州、深圳、汕尾、清远等18市的数据,共计15 541条,其中肇庆、东莞、佛山、茂名等4市超过2 000条。实体包括驾驶员姓名、车牌、挂车车牌、时间、车型、所属公司、违法类型等。

图2 交通违法判决书文本示例Fig. 2 Text example of traffic violation judgment
由于Dbpedia、Wikidata和YAGO等代表性知识图谱公开测试数据集不包含中文数据,算例中知识图谱训练数据集来自重庆市及广东省部分高速公路运维管控平台数据库处理得到的三元组数据,以及清华大学自然语言处理实验室公开的数据集。
3.2 表示学习模型比选
算例TransH、TransR和TransD均使用高斯分布生成实体和关系的初始嵌入向量。设定实体和关系的向量维度为100,训练轮次为1 000次。训练时使用随机梯度下降法更新嵌入向量,学习率设为1.0%。综合比较效率和性能之后,在基础实验中选择关系负样本的采样数量为5[20],评价指标连续两次下降则终止程序,取最后一次评价指标结果进行比较。
使用Hits@K、MR、MRR、准确率和训练时间来评估各模型的性能。Hits@K表示测试集中排名在顶部前K个实体所占的百分比,笔者选择K=1、3、10;MR为排名的平均值;MRR为排名倒数的平均值。Hits@K值和MRR值越高、MR值越低,模型的实体对齐效果越好[20]。TransH、TransR和TransD的性能对比如表1。

表1 风险车辆知识图谱中TransH、TransR和TransD性能对比Table 1 Performance comparison among TransH, TransR and TransD in risky vehicle knowledge graph
从表1可以看出,TransR和TransD在对齐效果和准确率方面不相上下,并均优于TransH;而TransD比TransR有近2倍的计算效率。因此,TransD模型适合于文中风险车辆知识图谱的构建。
3.3 风险车辆知识图谱展示及应用
基于TransD模型,通过随机游走的知识推理模型完善三元组实体之间的潜在关系,形成广东省高速公路风险车辆知识图谱,并将风险类型按照出现频率排序(仅展示前5类型),如图3。
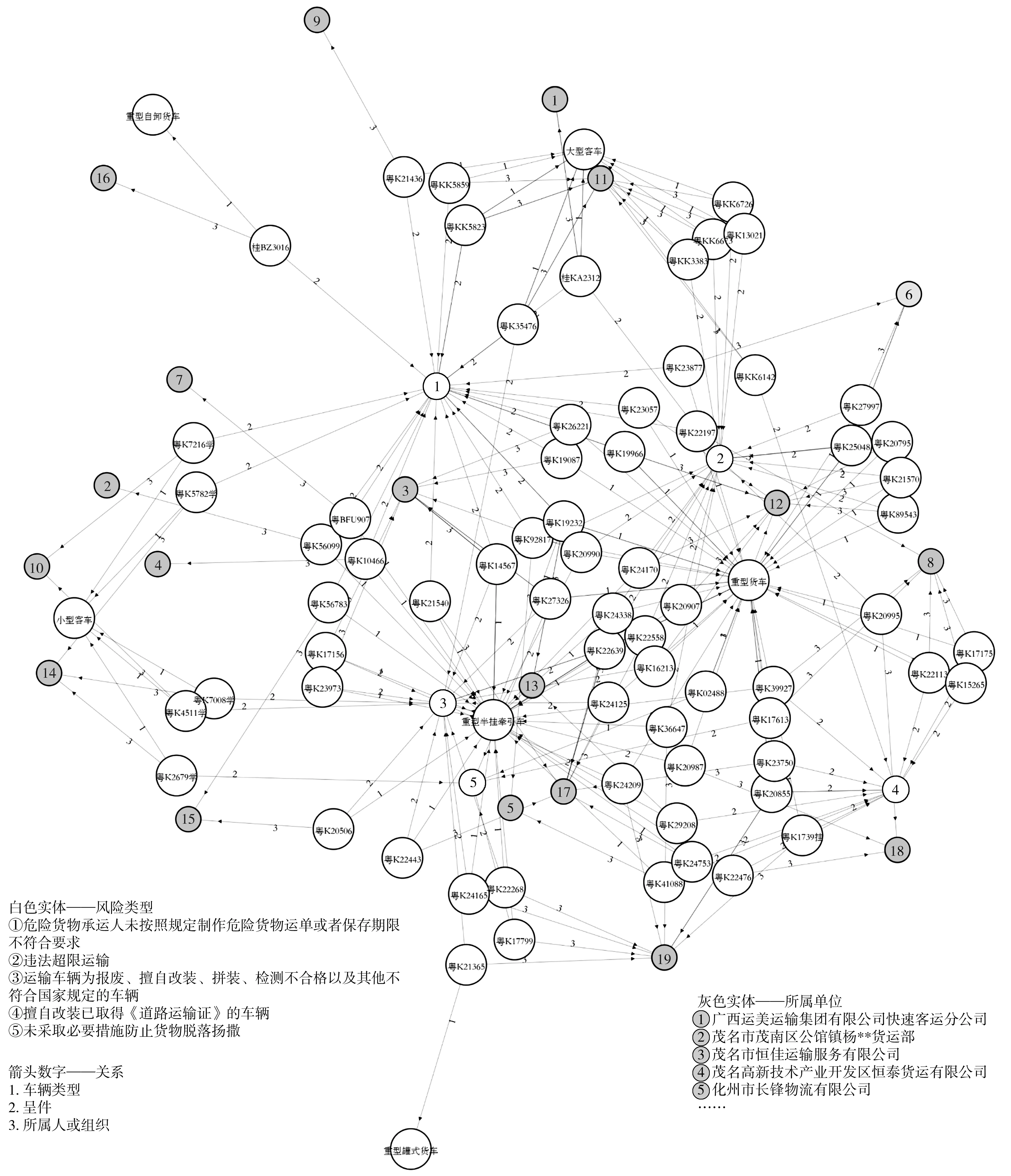
图3 广东省高速公路风险车辆知识图谱Fig. 3 Knowledge graph for risky vehicles on freeways of Guangdong province, China
从图3可以看出,普通货车超限运输和危化品车辆不规范运输为高速公路主要的交通违法行为。这些车辆一旦发生交通事故,无论事故本身是大或是小,其潜在的二次事故都将会对高速公路的安全运行产生极大的影响。
将图3的知识图谱作为高速公路运维管控系统的智能分析模块,按照每月1次的频率从交通运输局官方数据中定期更新风险车辆数据。只要高速公路运维管控系统通过监控摄像头检测到车辆的车牌,就能自动识别其历史违法信息,并判定是否为潜在风险车辆以及风险等级,从而为高速公路运行风险预警和管控提供科学依据。
4 结 语
根据外部网站抓取公开文本资料等半结构化数据,抽取高速公路风险车辆三元组;建立考虑一对多、多对一和多对多关系的表示学习模型,以最小化对数损失为目标,基于开放世界假设进行训练,提炼风险车辆三元组;采用随机游走推理模型进行基于逻辑规则的知识推理,从而完成高速公路风险车辆知识推理和图谱构建。研究发现,TransD模型对齐效果好、准确率高、计算效率高,适合于高速公路风险车辆知识图谱的构建。所提出的模型能达到对高速公路运行潜在风险进行识别的目的,可为高速公路运行风险预警和管控提供依据,完成语义关系识别领域的知识图谱技术在高速公路运行风险预警管控场景的应用。
