基于目标检测模型的无人机影像识别技术
2022-02-07孙盼盼丁学文常黎玫蔡鑫楠董国军
孙盼盼,丁学文,3,常黎玫,蔡鑫楠,董国军
(1 天津职业技术师范大学 电子工程学院,天津 300222;2 天津市高速铁路无线通信企业重点实验室,天津 300350;3 天津云智通科技有限公司,天津 300350)
0 引言
目标检测作为计算机视觉的研究热点之一,引起了各国学者的关注。近年来深度学习的目标检测算法得到了快速发展,识别精度和速度也在不断提升。基于深度学习的目标检测算法分为2 类:一阶段和两阶段。其中,SSD[1-2]和YOLO(You Only Look Once)系列[3-6]是一阶段检测算法,R-CNN[7]、Fast R-CNN[8]和Faster R-CNN[9]是两阶段检测算法。与两阶段识别相比,一阶段识别准确率略低,但识别速度要快上数百倍。在单阶段算法中,YOLOv5比SSD 快2~3 倍,所以YOLOv5 在开发人员中更受欢迎。目前,YOLOv5 已然广泛应用在对实时性要求较高的各种目标识别领域中。虽然YOLOv5 具有良好的目标检测性能,但对无人机影像这类小目标的识别率却较低。与其他目标相比,容易发生漏检和误检,这在一定程度上限制了YOLOv5 的使用。在实际应用场景中,会有相当多的对象都是小目标,小目标在图像中面积小、特征也不明显,采用多层卷积神经网络后,可能出现部分特征丢失的问题,从而导致识别率的下降。针对以上问题,本文提出改进的YOLOv5 目标检测算法,该算法增加了有利于小目标的处理,从而提高了精确率、召回率和平均精确率。
1 YOLOv5 算法及改进
1.1 YOLOv5 网络结构
YOLOv5 按照网络深度和网络宽度的大小,可以分为YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x。YOLOv5s 的网络结构最为小巧,同时图像推理速度最快达0.007 s,故本文使用YOLOv5s模型。YOLOv5s 的网络结构如图1 所示。由图1 可知,YOLOv5s 的网络结构主要由输入端、基准网络、Neck 网络以及Head 输出端四部分组成。对此将展开研究分述如下。
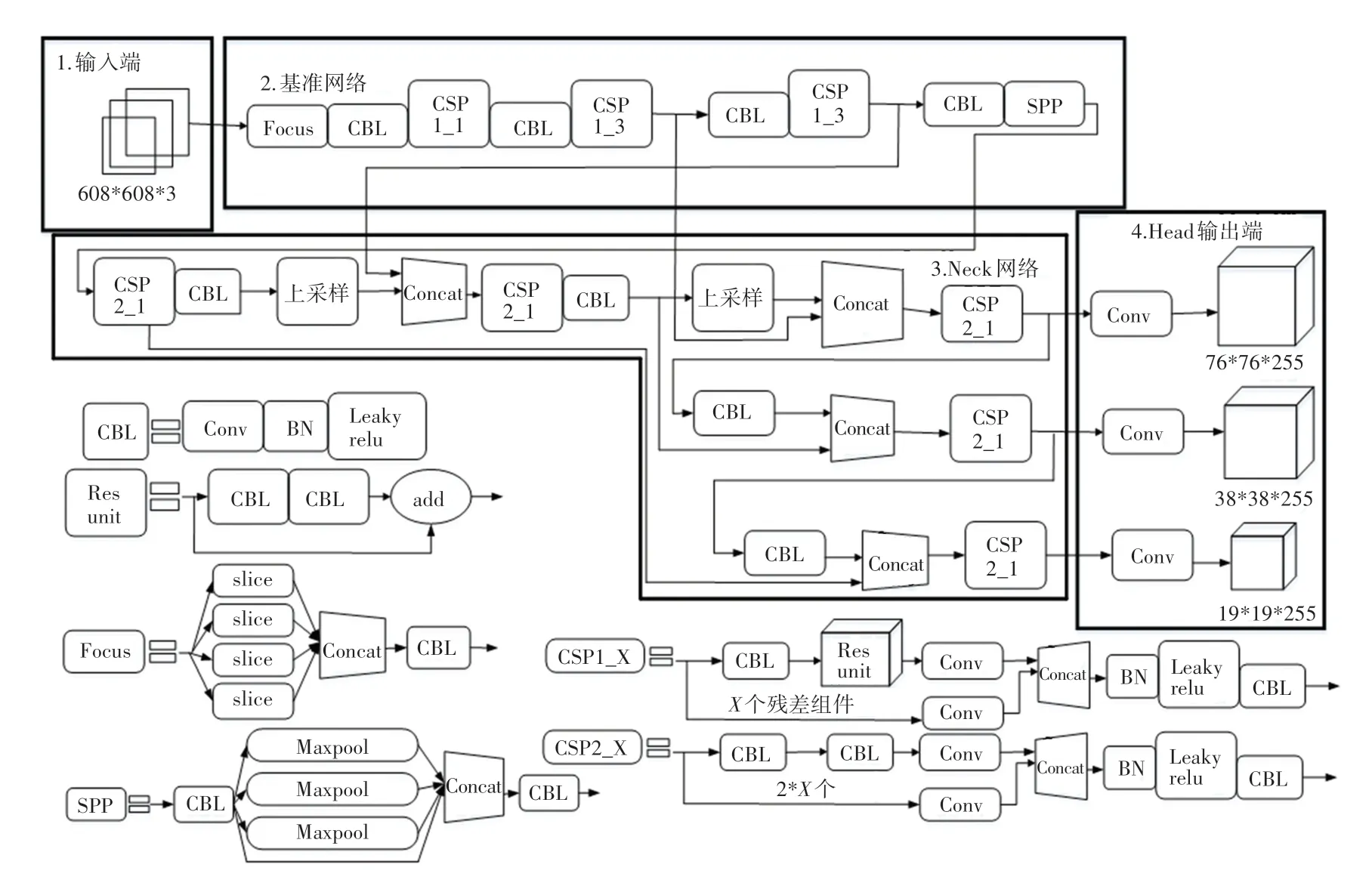
图1 YOLOv5s 的网络结构Fig. 1 Network structure of YOLOv5s
(1)输入端。表示输入的图片的部分。YOLOv5s 输入大小为608*608 的图像,该阶段会把输入图像进行缩放,直至与网络的输入大小相等,再对图像进行归一化处理。在网络训练阶段,YOLOv5s 为了提高网络模型的训练速度和网络精度,在网络模型中增加了Mosaic 数据增强操作;为了使数据集多样化以及减少GPU 的占用,在网络模型中增加了自适应锚框的计算以及自适应图片缩放。
(2)基准网络。通常是提取一些通用的特征。YOLOv5s 中使用了CSPDarknet53 和Focus 网络结构作为基准网络,CSP 结构是用来进行下采样的,但和传统卷积的下采样不太相同,CSP 结构可以对Focus 的计算量和普通卷积的下采样计算量进行比较。
(3)Neck 网络。通常位于基准网络和输入端之间的位置,利用Neck 网络可以使提取的特征具有多样性及更好的稳定性。YOLOv5s 用到了FPN+PAN模块,FPN 层是自顶向下的特征卷积用于传达强语义特征,而特征金字塔是自底向上的特征卷积用于传达强定位特征,两两联合,从不同的主干层对不同的检测层进行参数聚合,进而达到很好的效果。
(4)Head 输出端。用来完成目标检测结果的输出。YOLOv5s 主要是GIoU_Loss代替IoU作为bounding box 回归的损失,IoU的缺点是不重合或者重合面积相等,而YOLOv5s 的GIoU在计算时,不同位置的预测框都会对GIoU产生影响,从而弥补了IoU的不足,并进一步提升算法的检测精度。
1.2 YOLOv5 效果展示
不同版本的YOLOv5 检测算法在COCO2017 验证集与测试集上的检测效果如图2 所示。
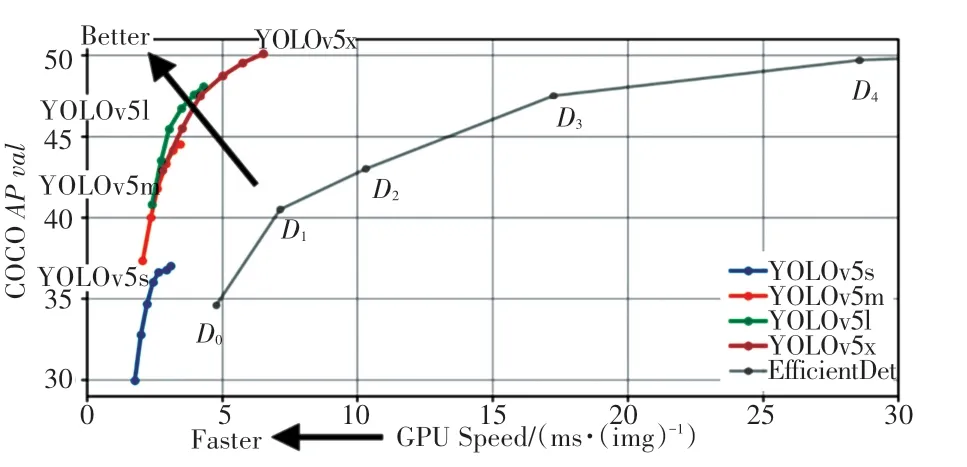
图2 YOLOv5 效果展示Fig. 2 YOLOv5 effect display
图2 中,横轴表示YOLOv5 算法在GPU 上推理出每张图片需要的毫秒数,距原点越近、效果越好;纵轴表示YOLOv5 算法在COCO2017 的测试集上测试出的AP值,距离原点越远、效果越好。通过观察分析可以看出,相较于EfficientDet,YOLOv5s 的AP值更高,而且推理速度更快;相较于YOLOv5m、YOLOv5l、YOLOv5x,YOLOv5s 具有更高的速度,但AP值并不高,不过也在可接受范围内。
YOLOv5 的整体效果展示见表1。由表1 可知,YOLOv5s 的输入图片分辨率为640*640,在COCO测试集与验证集上的AP指标为36.8,AP50 指标为55.6。该算法在V100 GPU 上的推理速度仅仅需要2.2 ms,帧率为455 FPS,该网络的模型大小仅为7.3 M。相对YOLOv5m、YOLOv5l 及YOLOv5x 模型来说,YOLOv5s 的速度更快、模型较小、且精度也较高。故而,在本文中拟选择YOLOv5s 模型进行研究。

表1 YOLOv5 效果展示Tab.1 YOLOv5 effect display
1.3 YOLOv5s 算法的改进
考虑到YOLOv5s 对传统目标检测较好,但对小目标经常出现误检、漏检,从而造成精度较低的问题,本文提出了改进的YOLOv5s。改进的YOLOv5s主要是在第17 层后,对特征图增加上采样操作,使特征图继续扩大,如此一来就改善了小目标浅层语义信息不足的缺陷。
2 实验及结果分析
2.1 数据集的相关说明
本文实验采用无人机影像VisDrone 数据集。VisDrone 数据集由中国天津大学机器学习和数据挖掘实验室的AISKYEYE 团队收集并且标注的[10]。该数据集在采集时把摄像机架设在无人机上,在中国14 个不同地区的城市和村庄以及不同的天气和光照下,采集稀疏程度不同的行人、小汽车、三轮车、自行车等不同的物体。VisDrone 目标检测数据集中包 括 pedestrian、people、bicycle、car、van、truck、tricycle、awning-tricycle、bus、motor 共10 类被标注的物体。其中,pedestrian 为直立姿势或者行走的人,除pedestrian 以外的人定义为people。通过对数据集进行分析,得到可视化结果,如图3 所示。

图3 数据集可视化结果Fig. 3 Visualization results of the dataset
由图3(a)中可以看出,图像中的大多数都是较小的标记框。由图3(b)中可以看出,物体中心点位置在x轴方向大多数分布在0.4~0.6 之间,在y轴方向大多数分布在0~0.6 之间。在图3(c)中,横坐标表示物体的宽,纵坐标表示物体的高。综合图3(b)和图3(c)的分析可知,该数据集中小物体较多,并且存在一定程度的遮挡。
2.2 实验环境参数
本文实验采用的电脑硬件配置及Pycharm 软件设置情况见表2。

表2 实验环境参数Tab.2 Experimental environmental parameters
2.3 模型评价指标
预测值为正例,记为P(Positive);预测值为反例,记为N(Negative);预测值与真实值相同,记为T(True);预测值与真实值相反,记为F(False)。改进的 YOLOv5s 采用平均精度(mean average precision,mAP)来验证所提模型相较于YOLOv5s模型的优越性。mAP在计算时需用到Precision、Recall、AP,对此可做阐释表述如下。
(1)精度。具体计算公式为:
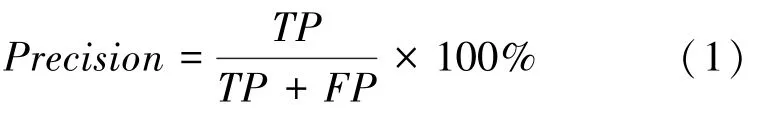
(2)召回率(Recall)。具体计算公式为:

(3)AP和mAP。具体计算公式为:

2.4 不同模型检测精度对比
本实验选用数据集中的6 471 张图片作为训练集,548 张图片作为验证集训练300 次,YOLOv5s 和改进YOLOv5s 的VisDrone 数据集的评估结果见表3。
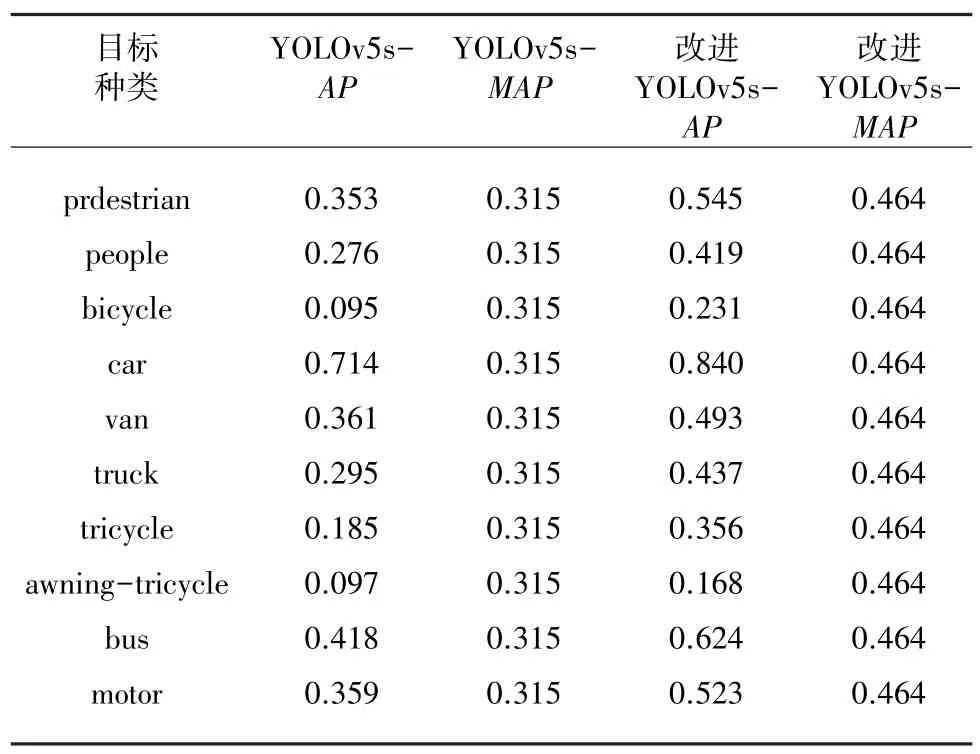
表3 VisDrone 数据集结果评估Tab.3 Results evaluation of VisDrone data set
从仿真实验结果可以看出,改进YOLOv5s 各个类别的AP值都有10%~15%的提升,mAP值提升了14.9%,由此可见改进的YOLOv5s 确实对小目标有了很好的改善。
训练结束后,本文采用无人机重新捕获图片进行测试,运行的效果如图4 所示。

图4 测试结果Fig. 4 Test results
为方便查看无人机影像的检测结果,从图像中选取图4(a)的局部区域①、②、③,如图5(a)~(c)所示,选取图4(b)的局部区域①、②、③,如图6(a)~(c)所示。
图5(a)中把井盖误检为bicycle,图6(a)中此井盖没有被认为是标签中的物体;图5(b)中漏检多辆被树木遮挡的car,图6(b)中被树木遮挡的car 均被正确检出;图5(c)中把tricycle 误检为car,漏检pedestrian 和people,car 的概率为39%;图6(c)改进YOLOv5 测试结果中将该car 的概率提升为72%,pedestrian 和people 均被正确检出,但此图却把tricycle 误检为motor。因此改进的YOLOv5s 改善了漏检、误检以及检测效果不佳的问题,也仍有待进一步扩充数据集,并且进行更多训练来优化模型。总之,改进的YOLOv5s 算法在小目标检测方面已经具有较好的检测性能。

图5 YOLOv5s 测试结果Fig. 5 YOLOv5s test results

图6 改进YOLOv5s 测试结果Fig. 6 Improved YOLOv5s test results
3 结束语
针对自然环境使用YOLOv5s 检测无人机影像时出现的漏检、误检以及检测效果欠佳等问题,本文提出了一种基于YOLOv5s 模型改进的无人机影像检测模型。研究中,在17 层后增加上采样模块,来弥补浅层特征语义信息的不足,从而提高了模型的特征提取能力,模型的检测精度也得以提升。改进后的YOLOv5s 与原网络的无人机影像检测模型对比,获得了很好的检测结果,然而整体的平均精度稍微偏低。在今后的研究当中,将会在这一方向做更加深入的探讨,以利于有效提升最终效果。
