针对多线程应用程序的片上网络优化设计
2022-02-07胡海洋李悦瑶赵玉来李建华
胡海洋,李悦瑶,李 阳,赵玉来,李建华
(1 合肥工业大学 计算机与信息学院,合肥 230601;2 合肥工业大学 情感计算与先进智能机器安徽省重点实验室,合肥 230601)
0 引言
随着半导体工业的不断发展,芯片上集成了越来越多的处理器核,这些集成在芯片上的处理器核在提高性能的同时,各处理核间的通信也带来了高延迟和高能耗的问题,因此芯片上多个处理器核之间的通信延迟成为制约芯片性能提高的重要因素。当下,片上互联网络正在发生巨变,计算机体系结构专家提出了一种叫做片上网络(NoC)的具有高扩展性的资源管理方案。NoC 逐渐取代了像总线(Bus)和交叉开关(Crossbar)这样的传统片上互联方案[1-6]。
同步屏障(Barrier)是并行计算的一种方法。对于一组线程,程序中的一个同步屏障意味着任何线程执行到此后必须等待,直到所有线程都到达此点才可以继续执行下面的程序。同步屏障(Barrier)是用来将程序分段而被设计出来的。举一个例子,在任何线程使用步骤t +1 中的值作为输入之前,步骤t中的共享矩阵中的值已经被更新[7-10]。
对于基于NoC 的多核处理器来说,数据包在网络中的路由过程占据了较多的线程执行时间。有的线程由于缺失地址较多,需要在NoC 传输的数据包较多,因此这个线程执行得较慢。而同步屏障(Barrier)的存在,使得其他执行进度快的处理器需要等待这个执行进度慢的处理器,不仅影响性能、且浪费功耗。
同步屏障示例如图1 所示。由图1 可看到,线程A产生了一个蓝色的数据包A,线程B产生了2 个红色数据包B和C。在传统没有线程感知的NoC中,数据包A和数据包B会平等地竞争路由器10 和路由器15 的端口和虚拟通道。实际上,由于线程B缺失2 块地址,需要等待2 个请求的回复都收到才能继续执行,所以这是一个进度较慢的线程。而同步屏障(Barrier)的存在,使得线程A需要等待线程B。此时,数据包A不必与数据包C竞争路由器10和路由器15 的端口和虚拟通道,因为即便数据包A优先到达终点,其线程依旧需要等待数据包C的线程,对程序的执行进度没有影响。
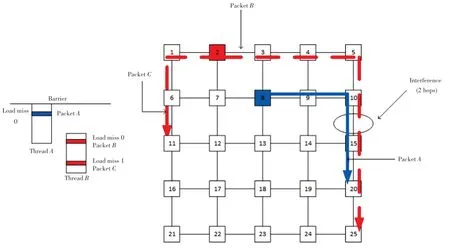
图1 同步屏障示例Fig. 1 Barrier demo
Das 等人[11]通过将影响应用程序执行的重要的数据包重新路由来解决这个问题,即挑选另外一条路由来避开拥塞区域,从而使影响应用程序执行的重要数据包可以更快地到达终点。这种方法可以使应用程序执行进度更快,同时解决饥饿、活锁、死锁等问题,但是当网络负载较高,由于没有可选的重新路由的路径,导致这种方法的效果达不到预期。
Das 等人[12]通过为每个数据包头部添加一个叫做CFI(Critical Flit Identifier)的标签来使影响程序顺利执行的数据优先仲裁成功。其中,CFI 表示重要的数据存储在这个数据包的第几个flit 当中。这种方法可以使程序执行进度更快,但是却会导致没有重要数据的flit 发生饥饿。
本文提出AVCA(Adaptive Virtual Channel Allocation)机制和CTCAR(Critical Thread Congestion-Avoid Routing)算法来优化这个问题。AVCA 机制,即动态地为执行进度慢的线程分配更多的虚拟通道。CTCAR 路由算法选择策略会计算当下节点到目的节点每一条备选路径中,从当下路由器开始下2 跳路由器中空的只能存储执行进度慢的线程数据包的缓冲区槽数之和,然后选择这2 跳空闲缓冲区槽数之和最大的那条路径传输数据包。图2 展示线程感知和非线程感知的比较,当NoC 有线程感知时,会减少处理器A因为同步屏障(Barrier)等待处理器B的时间。

图2 线程感知和非线程感知比较Fig. 2 Thread-aware and thread-unaware comparison
实验结果表明,本文方案在4×4 mesh random流量模式下,注入率为0.023 packets/node/cycle 时相比SAR[11]可以降低19%的平均延迟。
本文内容第1 节对相关工作进行介绍,包括本地感知自适应路由算法、区域感知自适应路由算法和全局感知自适应路由算法。第2 节,对AVCA 和SSA 的设计与实现进行详细描述。第3 节,提出了CTCAR 路由算法选择策略。第4 节,通过实验的方式将本文方案和对比方案进行比较。第5 节,总结全文。
1 相关工作
在NoC 中,国内外学者设计了大量的路由算法来解决NoC 拥塞的问题[13]。本文通过一种基于动态分配虚拟通道的路由算法,来平衡不同线程执行进度。
Jerger 等人[4]提到由于确定维度的路由算法(dimension-ordered routing)很简单,因而成为应用最为广泛的路由算法。然而,由于确定维度路由算法从源点到终点只有一条路径,所以不能有效绕开NoC 中故障区域或者拥塞区域,从而降低了NoC 的吞吐量,以及提高了NoC 的延迟。自适应路由算法(Adaptive routing)有效解决了确定维度路由算法(Dimension-ordered routing)的缺点,给NoC 增加了路径多样性,可以有效避开NoC 中的拥塞区域,从而提高NoC 的性能。自适应路由算法可以分为3类,分别是:本地感知自适应路由算法、区域感知自适应路由算法和全局感知自适应路由算法。
1.1 本地感知自适应路由算法
在本地感知自适应路由算法中,仅仅使用当前路由器所在节点的局部信息作为衡量NoC 是否拥塞的标志。
Dally 等人[14]选择空的虚拟通道的数量作为某个端口是否拥塞的标志,当数据包到达NoC 中某个节点时,会比较相邻节点的输入端口的空的虚拟通道的数量,随后选择具有最多空的虚拟通道的端口传输数据。
Kim 等人[15]选择空缓冲区的数量作为某个端口是否拥塞的标志。Singh 等人[16-17]使用输出队列长度作为某个端口是否拥塞的标志。当本地感知自适应路由算法被应用在不拥塞的区域时,由于本地感知自适应路由算法需要额外的逻辑来决定哪一条路径更好,从而导致本地感知自适应路由算法相比确定维度路由算法拥有更高的延迟。
Hu 等人[18]设计了一种叫做DyAD 的路由算法,这种路由算法集合了确定维度路由算法和本地感知自适应路由算法的优点,能够根据NoC 的拥塞情况在确定维度路由算法和本地感知自适应路由算法之间切换。当网络不拥塞时,路由器在确定维度的路由算法下运行;当网络变得拥塞下,路由器会转换为在本地感知自适应路由算法的情况下运行。
1.2 区域感知自适应路由算法
根据NoC 局部拥塞情况做出的路由判断,可能会由于缺乏对更远处节点的拥塞情况的了解,做出不合理的判断。区域感知自适应路由算法的提出就是为了解决这个问题。
Gratz 等人[19]提出区域拥塞感知路由算法、简称RCA,这是第一个跳出相邻节点观察更远处节点拥塞情况的路由算法。RCA 通过使用一个低带宽的监控网络在相邻路由器之间传输拥塞信息,在NoC 的每一跳中,传输进入的拥塞信息与本地拥塞信息聚合后再一起传输到网络中。为了减少非最短路线上节点的拥塞信息的干扰,RCA 使用与本地节点的相对距离来对拥塞值进行加权。
在RCA 中使用一个拥塞传递网络来综合本地拥塞信息和非本地拥塞信息,从而使NoC 做出合理的路由选择。但是却因没有隔离不同的应用程序,从而导致过多的拥塞信息会对NoC 路由选择做出干扰。
Ma 等人[20]设计了一种叫做DBAR 的路由算法。在这种路由算法中,NoC 路由器做出路由选择时只会考虑起点路由器到终点路由器该二维象限的拥塞情况,不会考虑这个二维象限之外的拥塞情况。如此一来,当本应用程序做出路由选择时,就减少了被不同应用程序在NoC 执行时拥塞情况的干扰。然而,在不分区的NoC 中,DBAR 的性能和RCA 的性能很接近。
区域感知自适应路由算法会形成一个用来专门传输非本地拥塞信息的拥塞传输网。当NoC 的负载很大时,拥塞传输网将会以消耗不可忽视的线路和功耗开销为代价来提高NoC 的性能。
Liu 等人[21]设计了一种把非本地的拥塞信息通过二进制位的形式嵌入到数据包的头flit 中的路由算法来解决这个问题。这种叫做FreeRider 的路由算法通过3 步来选择输出线路。第一步,检查备选线路是不是热点,及这条线路是不是有一半以上的虚拟通道被占用。如果第一步没有选择成功,第二步会比较这2 条备选线路的“后院”。如果第二步没有选择成功,第三步会比较这2 条备选线路空的虚拟通道的数目,并选择空的虚拟通道最多的那条线路来传输数据。
1.3 全局感知自适应路由算法
区域感知自适应路由算法使数据包到达某个节点做出路由选择时,除了会考虑相邻节点的拥塞情况,还可以考虑更远处节点的拥塞情况,从而做出更合理的路由选择。但是因为区域感知自适应路由算法只考虑了NoC 一部分节点的拥塞情况,就使得可能会因为对整个NoC 的拥塞情况了解并不全面而做出不合理的路由选择。
全局感知自适应路由算法在选择路由路线时,综合考虑整个NoC 每一个节点的拥塞情况,从而做出合理的路由选择。
Manevich 等人[22]提出自适应切换确定维度路由(ATDOR)的NoC 架构,在这种NoC 架构中通过使用一个二级网络,可将每一个节点的拥塞信息传输到一个专用节点,从而使每一个源点/终点对自适应地切换为XY 确定维度路由算法或者YX 确定维度路由算法。
Ramakrishna 等人[23]提出了GCA 全局感知自适应路由算法。在这种路由算法中,拥塞信息被嵌入到数据包头部,NoC 的每一个路由器读取到达这个路由器头flit 的拥塞信息,并嵌入到自己本地的图当中。GCA 通过为每个节点构建一个专属于该节点的图,从而使数据包到达某个节点时会根据全局网络的情况做出合理的路由选择。一个全局感知路由算法可以知道这条备选线路的拥塞值是多少,而不是只大概地了解这个方向的拥塞情况。
2 AVCA 和SSA 的设计与实现
2.1 SSA 仲裁机制
文献[13]提到尽管系统中有大量未解决的负载缺失,但不是每一块负载缺失都会导致性能瓶颈。假设,一个线程有2 个同时发出的网络请求,第一个向网络中较远的节点发送请求,第二个向网络中较近的节点发送请求。由于到更远处节点的数据包比到更近处节点的数据包有更高的延迟,所以到更近处节点的数据包是不重要的数据包。
文献[13]定义了一个参数Slack,用来表示在不影响程序整体执行时间的情况下,一个数据包的最大延迟是多少个周期。因此,网络中Slack等于0的数据包越多,线程的执行进度越慢。
Slack流程如图3 所示。图3 中,数据包A到路由器20 有4 跳,数据包B到路由器21 有5 跳。只有节点8 收到请求数据包A和请求数据包B的回复,线程才可以继续执行。因此数据包A的Slack是1,数据包B的Slack是0。
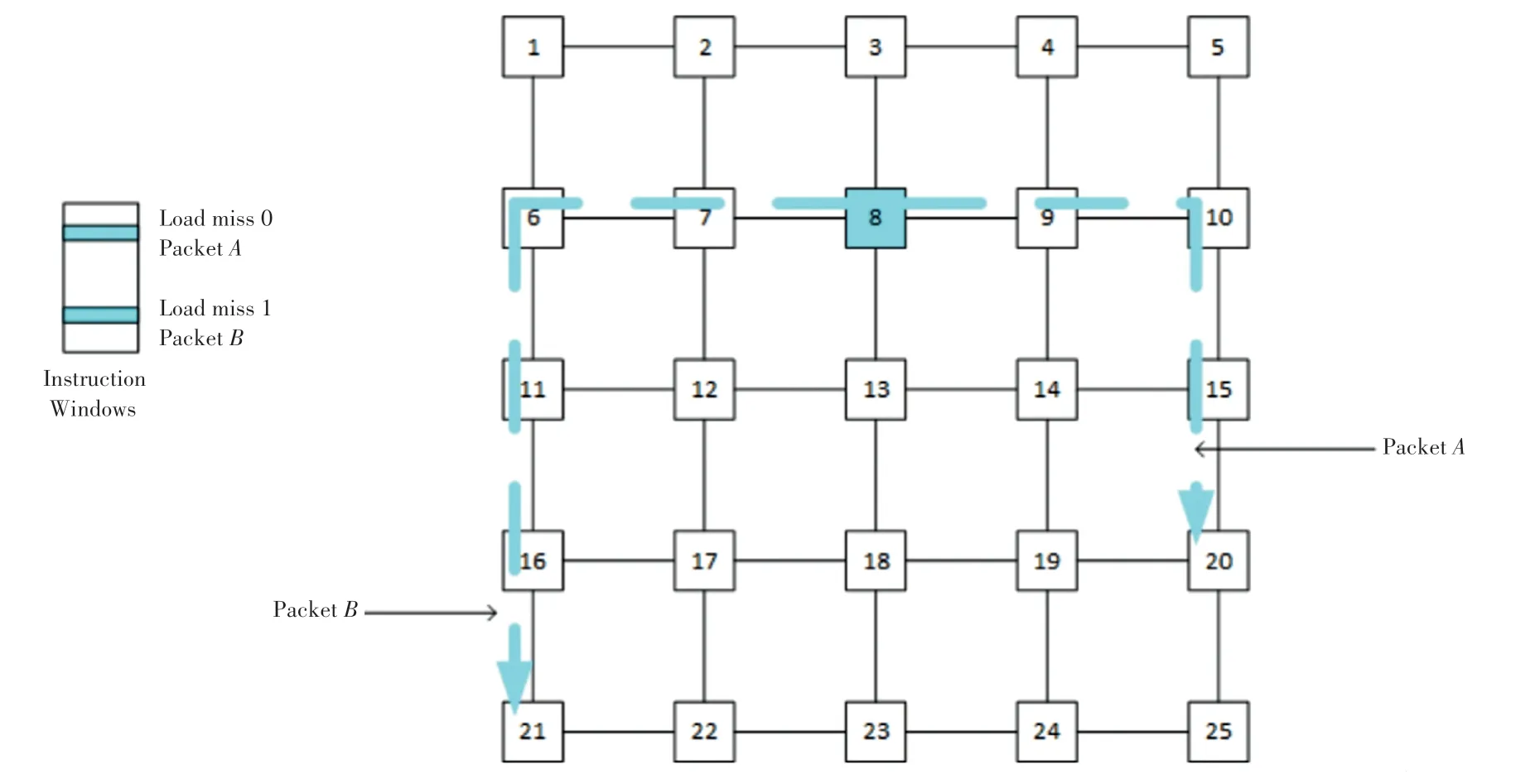
图3 Slack 流程图Fig. 3 Slack flow chart
本文引入SSA(Slack Switch Allocation)仲裁机制,将每个数据包的Slack嵌入到数据包头flit 的空闲位中,2 个数据包不再是平等地竞争同一个端口,而是根据数据包的Slack仲裁同一个端口。
2.2 数据包格式
传统数据包[21]中,头flit 通常含有2 bits flit 种类信息,31 bits 路由信息,3 bits 请求种类信息和40 bits 物理地址信息。数据包格式如图4 所示。图4表明头flit 至少还有52 bits 空闲位。
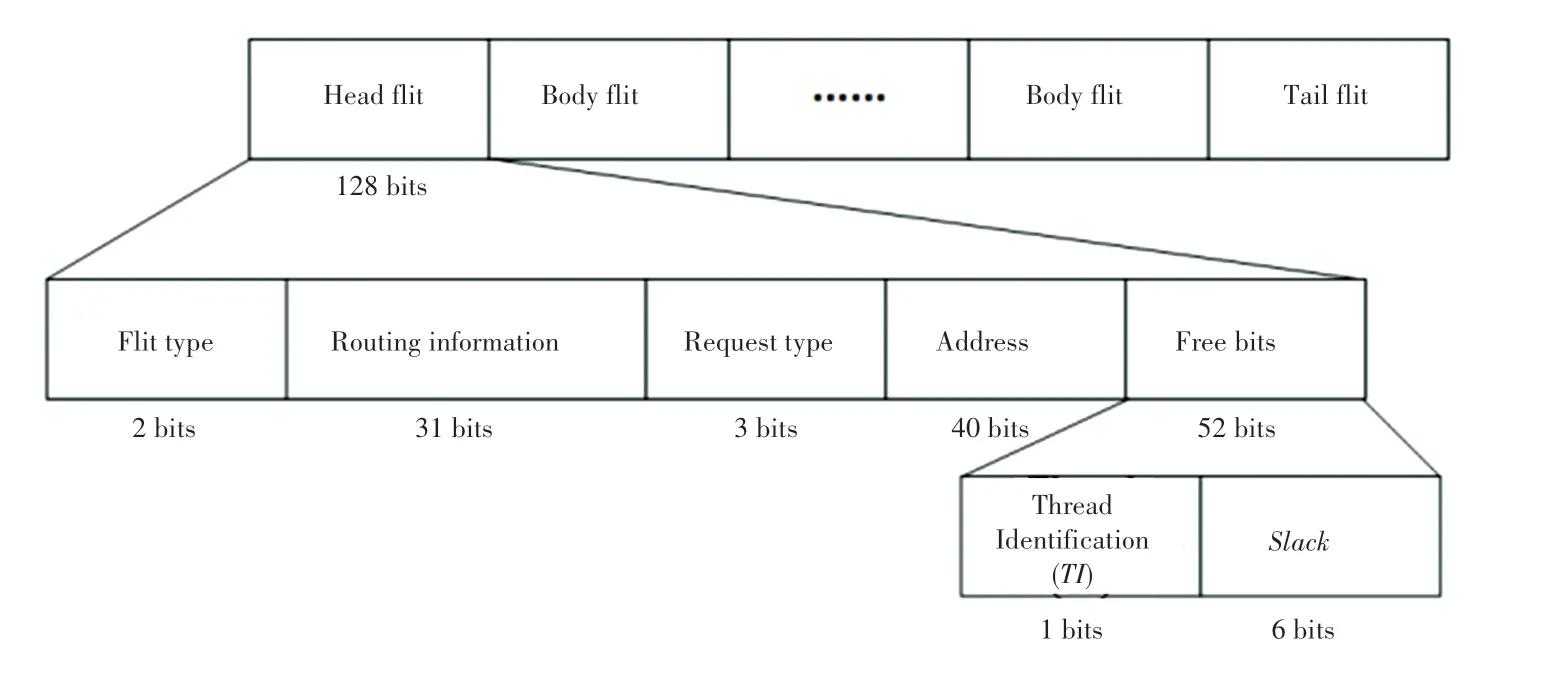
图4 数据包格式Fig. 4 Packet format
本文在数据包头flit 的空闲位中添加1 位线程识别(Thread Identification,TI)信息和6 位Slack信息。为了区分不同种类的线程,本文将线程随机地分为2 类,将一类线程数据包的TI信息标记为0,另一类线程数据包的TI信息标记为1。
2.3 AVCA 机制
由于已经为不同线程的数据包标有不同的标记,虚拟通道分配如图5 所示。图5 中,白色的虚拟通道只传输TI值为0 的数据包,紫色的虚拟通道只传输TI值为1 的数据包,蓝色的虚拟通道会根据NoC 中实际流量情况动态地传输TI值为0 或者TI值为1 的数据包。
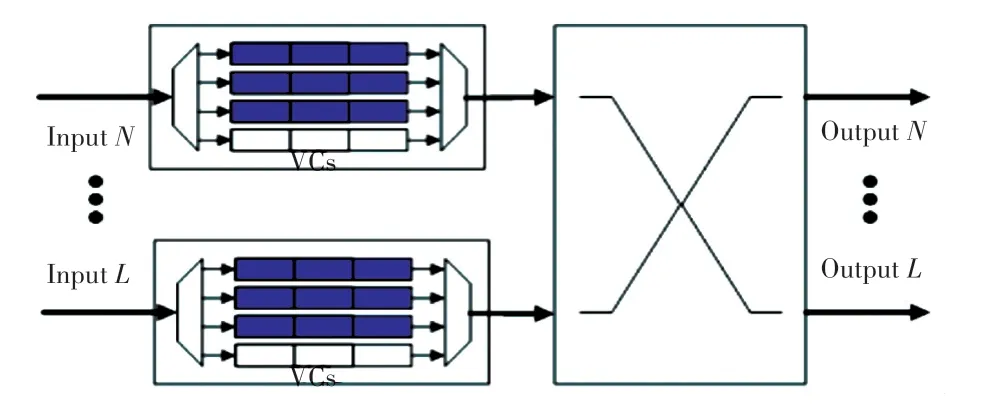
图5 虚拟通道分配图Fig. 5 Virtual channel allocation diagram
假设开始情况下2 个蓝色的虚拟通道传输TI值为0 的数据包,当NoC 中某一路由器某一个端口紫色虚拟通道满载,这说明网络中TI值为1 的数据包不再是低优先级的数据包,此时网络中蓝色的虚拟通道需要做出调整。
发生拥塞的紫色虚拟通道所在的路由器,通过信号线发送VCAI(VC Adjustment Information)虚拟通道调整信息到网络中所有其他的路由器,所有其他路由器收到VCAI 后,将2 个蓝色的虚拟通道转换为只能传输TI值为1 的数据包。
2.4 流水线变更
传统流水线如图6 所示。由图6 可知,传统的五级流水线有固定的虚拟通道分配阶段,及头flit经过路由计算确定输出端口以后,还需要仲裁成功一个与该输出端口相应的虚拟通道。
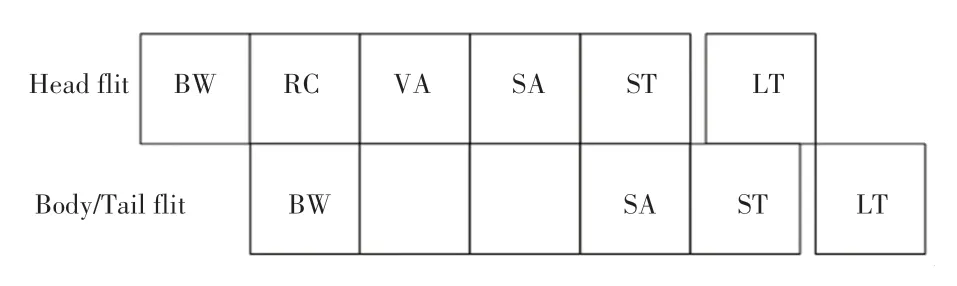
图6 传统流水线Fig. 6 Traditional pipeline
由于本文为数据包做了不同的标记,故而也得匹配不同的虚拟通道。在本文中,与传统的虚拟通道分配阶段相比,本文添加了一个数据包识别(Packet Identification,PI)阶段。如果识别出来的数据包是低优先级线程数据包,由于低优先级线程数据包只匹配一个虚拟通道,所以将没有VA(VC Allocation)阶段,可以直接进行ST(Switch Traversal)阶段。如果识别出来的数据包是高优先级线程数据包,由于高优先级线程数据包匹配3 个虚拟通道,所以就还要进行VA 阶段。图7 展示了本文设计的流水线。

图7 本文流水线Fig. 7 The pipeline in this paper
仲裁策略是指,当多个程序的数据包都要请求使用相同的输出端口时,哪一个线程的数据包可以优先使用这个输出端口。传统的仲裁策略包括Round-robin 和Age-based,都是没有程序感知的。
本文在数据包头flit 中嵌入Slack信息,使数据包仲裁时变成程序感知,及Slack小的数据包可以优先使用输出端口。本文的头flit SA(Switch Allocation)阶段变成了SSA(Slack Switch Allocation)阶段,即根据Slack数值的大小进行仲裁。
当需要仲裁的2 个数据包的Slack不同时,用Slack进行仲裁。当需要仲裁的2 个数据包Slack相同时,用Round-robin 进行仲裁。同时,如果数据包经过SSA 阶段,仲裁成功的输出端口会专供这个数据包来使用,因此Body 和Tail flit 无需再仲裁这个输出端口,直到相应的Tail flit 离开这个端口。而如果没有经过SSA 阶段,那么Body 和Tail flit 还需要继续再仲裁这个输出端口。
2.5 AVCA 和SSA 总体设计与实现
路由器基础架构如图8 所示。由图8 可知,本文提出的路由器基础架构,主要由5 部分组成,分别是:输入/输出端口、输入缓冲区、AVCA、交叉开关(Crossbar)和SSA。
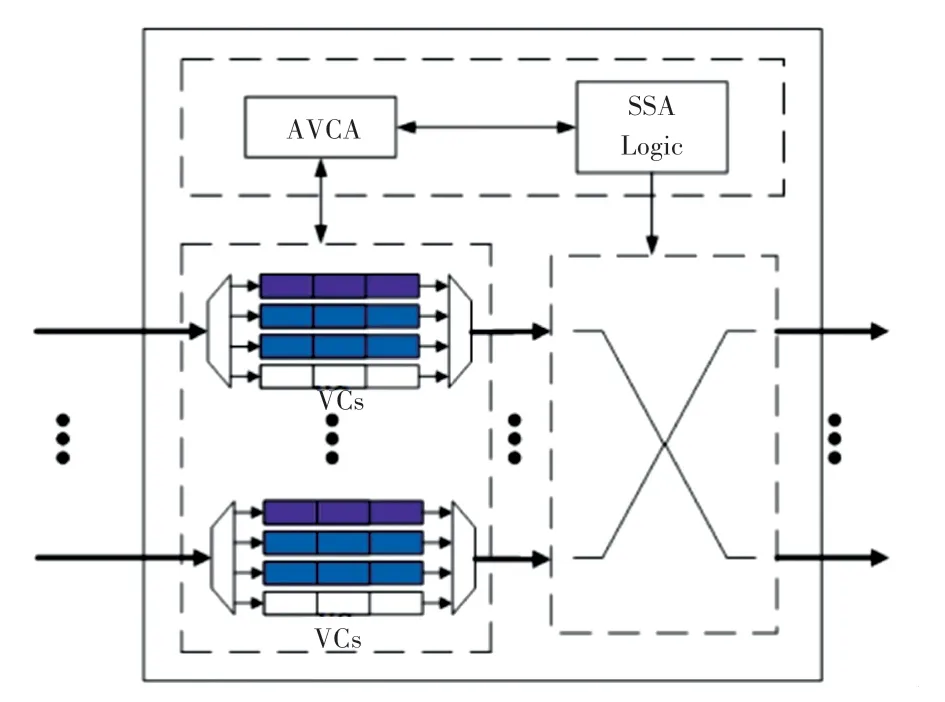
图8 路由器基础架构Fig. 8 Router architecture
AVCA 的灵活分配虚拟通道和SSA 的基于Slack的仲裁策略,相互作用,促使制约程序执行进度重要的数据包在路由器中传输时得到更多资源。
图9 是有关AVCA 的详细设计,本文为每个路由器添加了一个虚拟通道控制器(VC Controller,VCC)。VCC 会通过多路复用器(Multiplexer)收集每个端口4 个虚拟通道的信息。例如,北端口的紫色虚拟通道满载,北端口会将VCAI(VC Adjustment Information)信息传输到本路由器VCC 中,VCC 通过信号线将VCAI 传输到网络所有其他路由器中。其他路由器的VCC 收到VCAI 后,将VCAI 传输到每个端口的蓝色虚拟通道中,蓝色虚拟通道收到VCAI 做出调整,改为只传输TI值为1 的数据包。
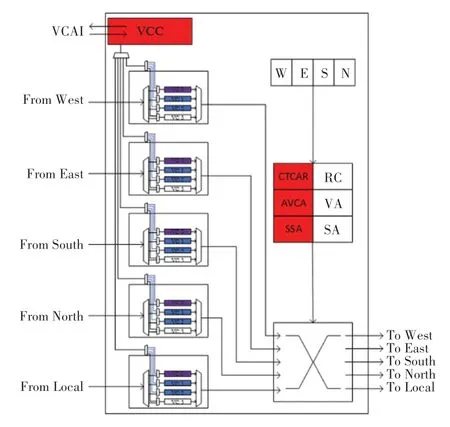
图9 AVCA 详细设计Fig. 9 AVCA detailed design
2.6 AVCA 举例
数据包传输实例如图10 所示。在图10(a)中,假设有一个低优先级线程数据包A的路由路径是从起点路由器1 通过中间路由器4 传输到终点路由器3,预期则应从路由器1 的北端口传输到路由器4,再从路由器4 的西端口传输到路由器3。
但是此时,路由器4 的西端口没有空闲的缓冲区可以传输数据,所以数据包A不能传输到路由器4,只能在路由器1 的北端口停留。在图10(a)中,红色的虚拟通道,代表这个虚拟通道已经被数据包占据,不能传输数据。
随后,路由器1 又需要分别传输3 个和数据包A的路由路径相同的低优先级线程数据包B,C和D,由图10(b)可知,这时数据包A,B,C和D将占据路由器1 北端口的4 个虚拟通道。
当路由器1 需要把高优先级线程的数据包E从路由器1 传输到路由器7 时,即便路由器4 的北端口有空缓冲区可以传输数据,但是因为路由器1 的北端口的4 个虚拟通道已经被4 个低优先级线程数据包占据,所以路由器1 此时不能传输数据包E。
如果使用本文方案,数据包传输具体见图10(c)。在图10(c)中,每个端口只有一个虚拟通道可以传输低优先级线程的数据包。每个端口蓝色的虚拟通道表示只能传输高优先级线程数据包的虚拟通道,白色的虚拟通道表示只能传输低优先级线程数据包的虚拟通道。当数据包A占据了路由器1 北端口唯一一个可以传输低优先级线程数据包的虚拟通道时,由于数据包B,C和D都是低优先级线程的数据包,因此数据包B,C和D不会再占据路由器1 北端口剩余3 个空的虚拟通道。随后,当路由器1 需要传输高优先级线程的数据包E时,因为路由器1 的北端口有3 个空的虚拟通道,所以路由器1 可以将数据包E顺利地传输到终点。
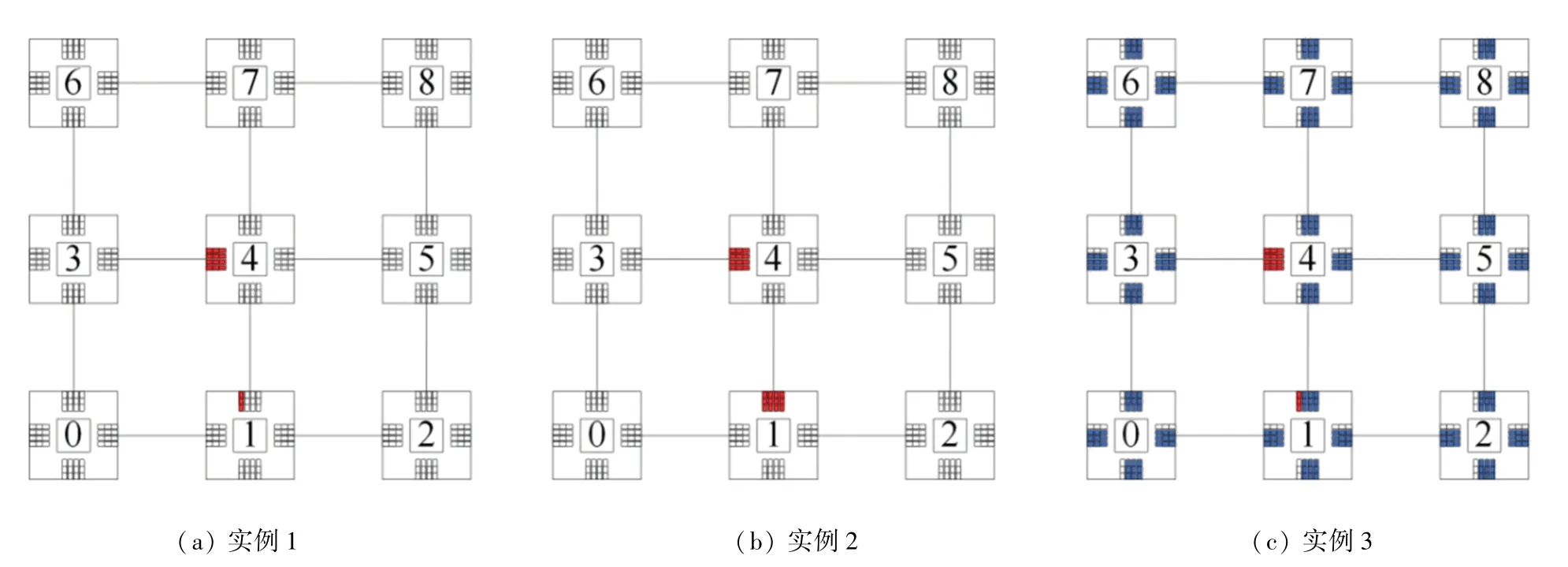
图10 数据包传输实例图Fig. 10 Packets transmission instance diagram
3 CTCAR 路由算法选择策略
3.1 CTCAR 概述
本文提出一种专门为高优先级线程优化的路由算法选择策略,即重要线程拥塞避免(Critical Thread Congestion-Avoided Routing,CTCAR)路由算法选择策略。
CTCAR 实例如图11 所示。在图11(a)中,这是一个4 行4 列的mesh 拓扑结构,其中每一个节点中的数字表示这是第几个节点。图11 中,实例的数据包传输起始路由器为节点5,终点路由器为节点15。
当高优先级线程的数据包要从起点路由器5 传输到终点路由器15 时,有路由器6 和路由器9 两个路由器可以选择。本文通过计算路由器6 和路由器6 的下一跳路由器的空闲缓冲区之和以及路由器9和路由器9 的下一跳路由器的空闲缓冲区之和,然后比较这两者的大小,最终指定这两跳缓冲区之和最大的那条线路为选择成功的线路。在图11(b)中的黑色虚线表明,路由器5 在选择下一跳是路由器6、还是路由器9 时,会根据路由器6 和路由器9 发回来的信息作为判断。
绍圣元年(1094),山谷50岁,居家待命,宥《书自作草后》:“绍圣甲戌在黄龙山中,忽得草书三昧,觉前所作太露芒角。若得明窗净几,笔墨调利,可作数千字不倦,但难得此时会尔。”(《山谷题跋》卷五)山谷与黄龙诸禅师请益参禅,于书法亦别有心得,以前所作书锋芒毕露,似应内敛含蓄。山谷以后遭遇证明,此时山谷实未得草书三昧。
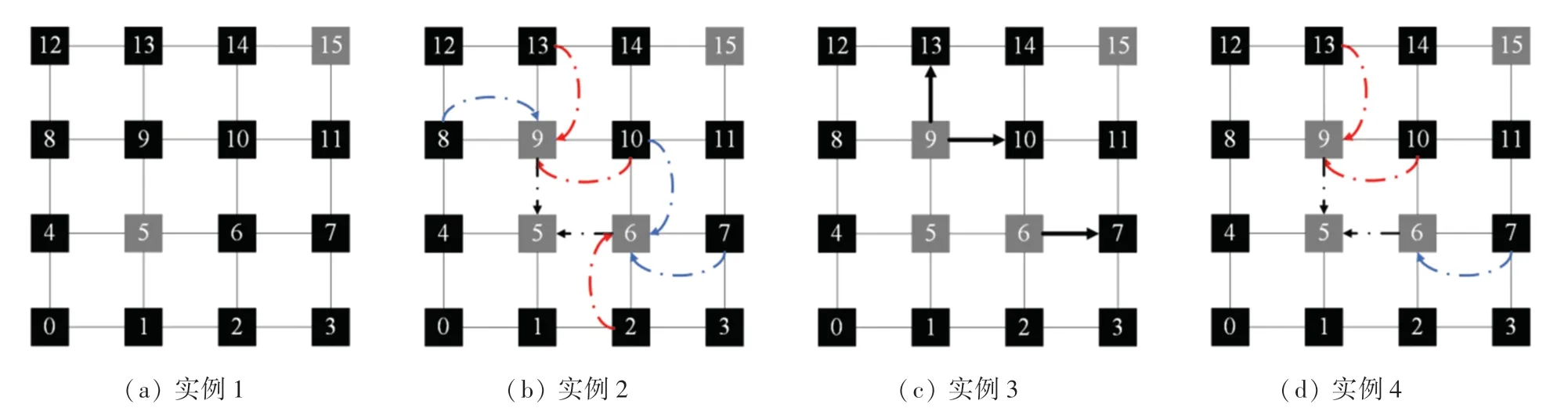
图11 CTCAR 实例图Fig. 11 CTCAR instance diagram
本文定义了2 个参数,分别是Vc_reservation和Slot_number。因为本文为高优先级线程数据包分配了3 个虚拟通道,所以一个路由器在收集相邻路由器的信息时,会得到相邻路由器专门存储高优先级线程数据包的虚拟通道是否被其他数据包预定的信息,及Vc_reservation是1、还是0。如果Vc_reservation是1 代表这个虚拟通道已经被预定,不能传输数据;如果Vc_reservation是0,代表这个虚拟通道没有被预定,可以传输数据。
Slot_number代表这个没有被预定的虚拟通道有多少个空闲缓冲区槽。信息传输示意如图12 所示。在图12 中,路由器9 收集与其相邻的3 个路由器,即路由器8、路由器10 和路由器13 的每个专门存储高优先级线程数据包虚拟通道的Vc_reservation和Slot_number。
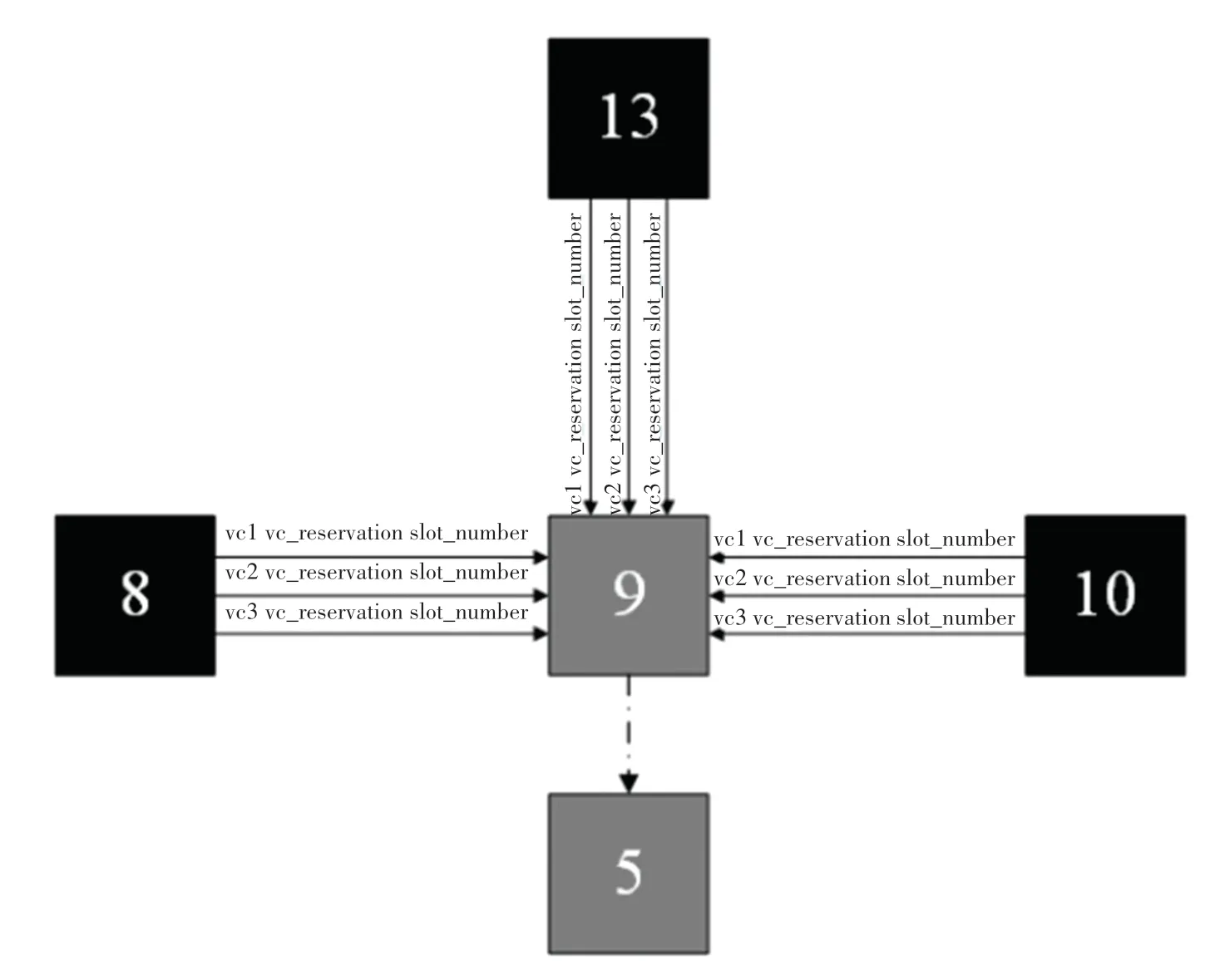
图12 信息传输图Fig. 12 Information transmission diagram
图11(b)中,蓝色虚线表示下一跳存在没有被预定的专门传输高优先级线程数据包的虚拟通道,可以传输数据。图11(b)中,红色虚线表示下一跳的3 个专门传输高优先级线程数据包的虚拟通道已经被预定,不能传输数据。
图11(c)中,3 条深黑色实线表示路由算法计算出路由器6 和路由器9 的下一跳可以到达哪个路由器。
在本文中,用的路由算法是基于奇偶转向模型的自适应路由算法。当高优先级线程的数据包由路由器5 传输到路由器9 时,因为这是奇数列不能做由向北到向西的转向和由向南到向西的转向,及路由器9 的下一跳可以到达路由器10 和路由器13。因为路由器6 位于偶数列,不能做由向东到向北的转向和由向东到向南的转向,及路由器6 的下一跳只能到达路由器7,不能到达路由器10。
在图11(d)中,由于路由器10 和路由器13 专门传输高优先级线程数据包的虚拟通道,已经被其他数据包预定。而路由器7 专门传输高优先级线程的虚拟通道没有被其他数据包预定,所以本例应该选择路由器6,因为路由器6 的下一跳路由器7 可以传输高优先级线程的数据包。
3.2 CTCAR 详细设计
以图11 为例CTCAR 流程如图13 所示。首先,确定当下网络中,TI值为1 是高优先级线程数据包,还是TI值为0 是高优先级线程数据包。如果数据包是高优先级线程数据包,使用CTCAR。如果数据包不是高优先级线程数据包,退出流程,使用XY 路由算法。
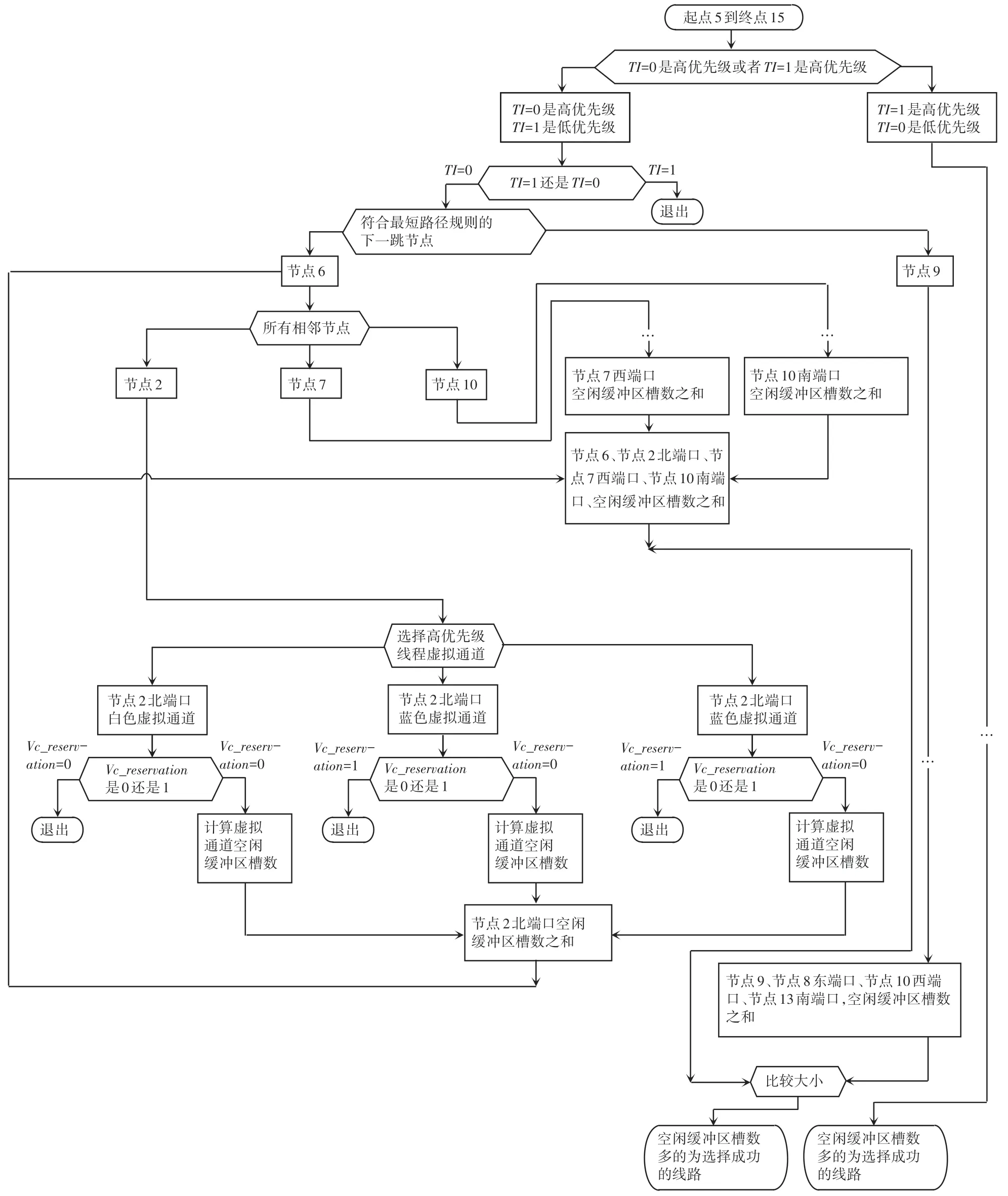
图13 CTCAR 流程图Fig. 13 CTCAR flow chart
其次,计算当下节点到目的节点每一条备选线路中,从当下路由器开始下2 跳路由器中,空的只能存储高优先级线程数据包的缓冲区槽数之和,再选择这2 跳空闲缓冲区槽数之和最大的那条线路传输数据包。CTCAR 算法设计代码见如下。

4 实验
4.1 仿真环境配置

表1 实验参数表Tab.1 Experimental parameters table
在本文中,每经过10 000 个周期设置一个同步屏障(Barrier),即低优先级的线程每仿真10 000个周期就会停下等待高优先级的线程。
在本文中为每个路由器的输入端口设置了4 个逻辑大小为8 个flit 的虚拟通道。
本文采用3 种流量模式进行仿真,分别是Random、Transpose1 和Transpose2。对此可做阐释分述如下。
(1)Random 流量模式中,NoC 中每个节点向NoC 中任意其他节点随机地发送数据包。
(2)Transpose1 流量模式中,假设准备发送数据包的起始节点的坐标是(x,y),那么这个数据包将会被发送到的终点是(mesh_dim_x -1-y,mesh_dim_y -1-x),其 中mesh_dim_x和mesh_dim_y表示这个NoC 设置的横坐标和纵坐标上分别有多少个节点。这种流量模式的特点是:越靠近中间区域的路由节点注入网络的数据包的跳数就越小,但是从整体上来看,长距离多跳数据包占的比重更大。
(3)在Transpose2 流量模式中,假设准备发送数据包的起始节点的坐标是(x,y),那么这个数据包将会被发送到的终点是(y,x)。在本文中,每次仿真包括1 000个周期的预热阶段和20 000个周期的仿真阶段。
4.2 性能分析
4.2.1 平均延迟
图14~图16 是4×4 mesh 拓扑结构3 种流量模式下的延迟对比图。图17 是8×8 mesh 拓扑结构random 流量模式下的延迟对比图。4 幅图中,横坐标是网络的注入率,纵坐标是以周期为单位的数据包平均延迟。
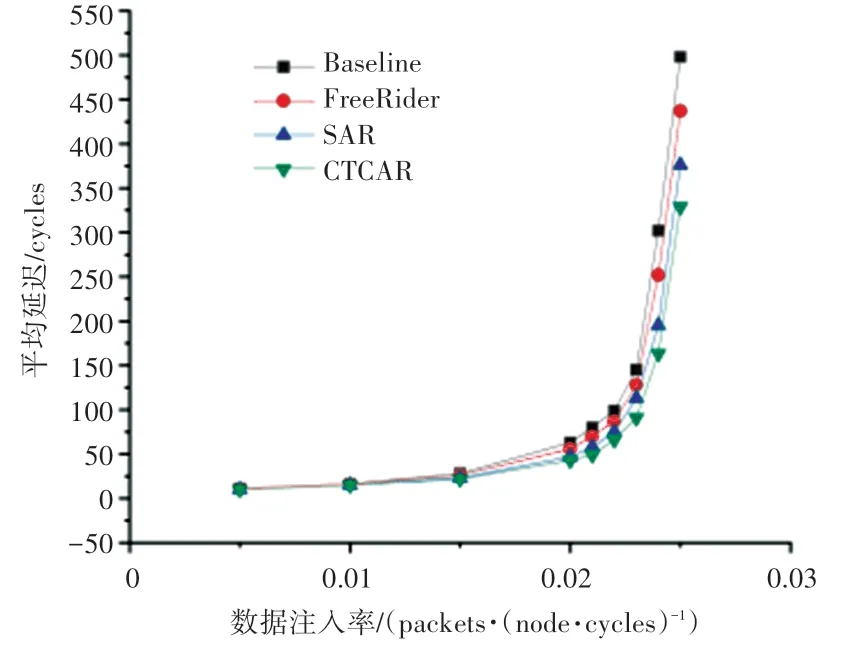
图14 random 流量模式下4×4 mesh 网络延迟Fig. 14 Latency of 4 × 4 mesh in random traffic
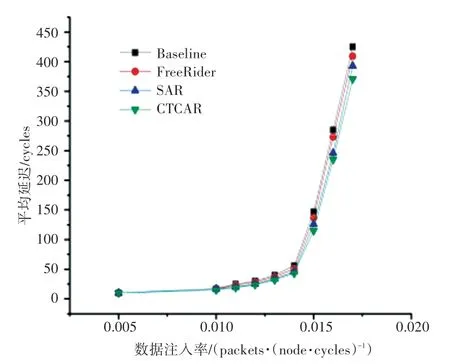
图15 Transpose1 流量模式下4×4 mesh 网络延迟Fig. 15 Latency of 4 × 4 mesh in Transpose1 traffic
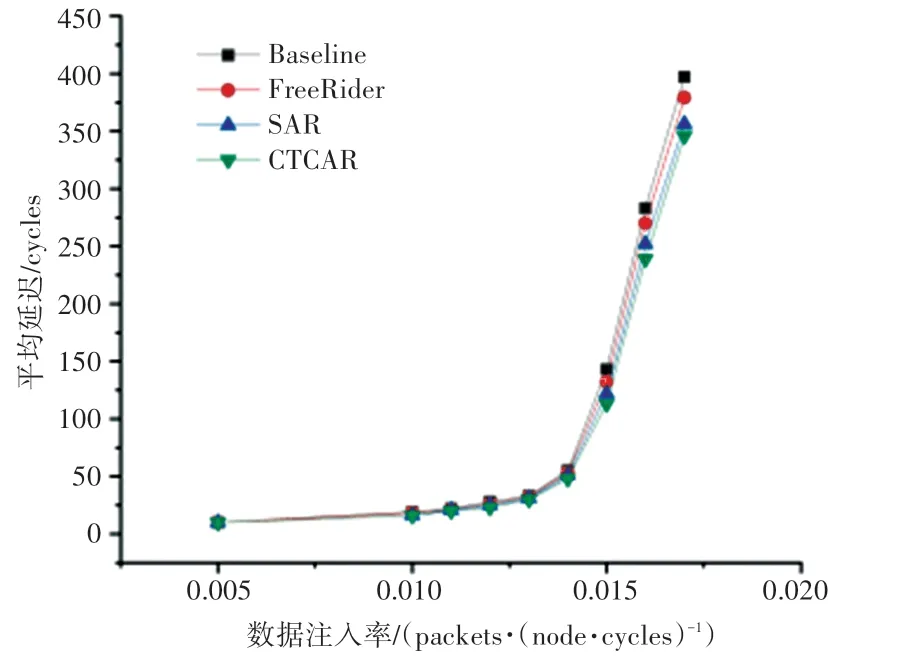
图16 Transpose2 流量模式下4×4 mesh 网络延迟Fig. 16 Latency of 4 × 4 mesh in Transpose2 traffic
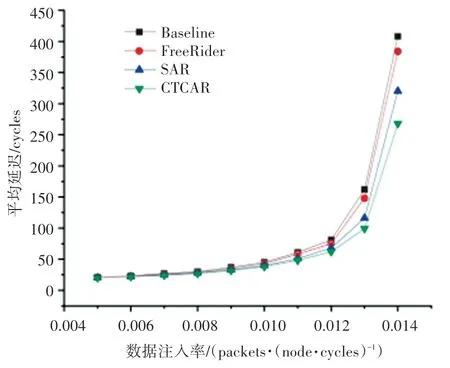
图17 random 流量模式下8×8 mesh 网络延迟Fig. 17 Latency of 8 × 8 mesh in random traffic
本文对4 种方案进行对比分析。方案一是Baseline 方案及没有采用AVCA 机制、SSA 机制和CTCAR 路由算法选择策略。方案二采用了传统的没有程序感知的路由算法,即Freerider 路由算法。方案三采用了程序感知的路由算法,及SAR 路由算法。方案四采用了本文方案,及应用了AVCA、SSA和CTCAR。各对比方案的比较结果见表2。
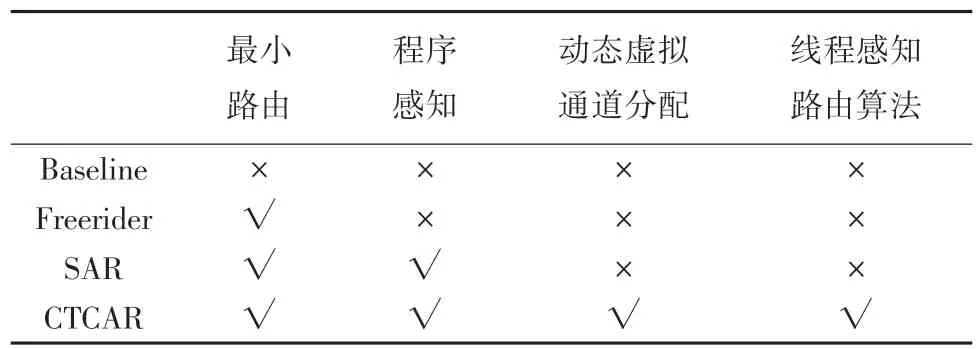
表2 各对比方案比较Tab.2 Comparison of different schemes
SAR 和本文所提出的CTCAR 都是程序感知的路由算法。从图14~图17 可以看出,在不同的流量模式下CTCAR 较SAR 在高注入率或低注入率下都有一定的延迟改善。
在4×4 mesh random 流量模式下,注入率大于0.021 packets/node/cycle 小于0.025 packets/node/cycle 时,CTCAR 与对比方案相比有较大的延迟改善。其中,注入率为0.023 packets/node/cycle 时,CTCAR 效果达到最佳,相比SAR 可以降低19%的平均延迟。
在8×8 mesh random 流量模式下,注入率大于0.012 packets/node/cycle 小于0.014 packets/node/cycle时,CTCAR 与对比方案相比有较大的延迟改善。其中,注入率为0.014 packets/node/cycle 时,CTCAR 效果达到最佳,相比SAR 可以降低16%的平均延迟。
这是由于CTCAR 引入Slack,在仲裁阶段是程序感知的。同时CTCAR 考虑到同步屏障的存在,可以动态为不同线程数据包分配不同的虚拟通道,从而平衡各个线程的执行进度。CTCAR 在灵活分配虚拟通道的基础上,还引入了区域拥塞感知的思想,从而进一步降低了网络的平均延迟。
4.2.2 吞吐率
4×4 mesh 和8×8 mesh 拓扑结构random 流量模式下,CTCAR 和对应的3 种对比方案的吞吐率比较结果如图18、图19 所示。图18、图19 中,横坐标表示网络注入率,纵坐标表示网络中平均每个节点的吞吐率。
从图18、图19 中可以看出,CTCAR 具有更高的网络吞吐率,这是因为本文提出的AVCA 机制可以动态地为不同优先级线程数据包分配不同的虚拟通道,同时CTCAR 可以有效避免高优先级线程数据包发生拥塞。
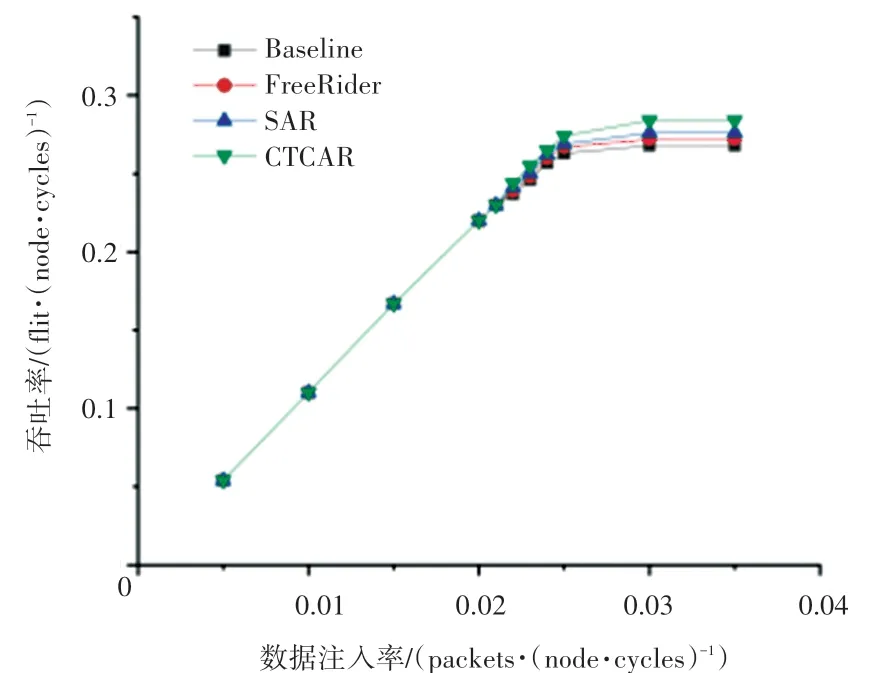
图18 random 流量模式下4×4 mesh 吞吐率Fig. 18 Throughput of 4×4 mesh in random traffic
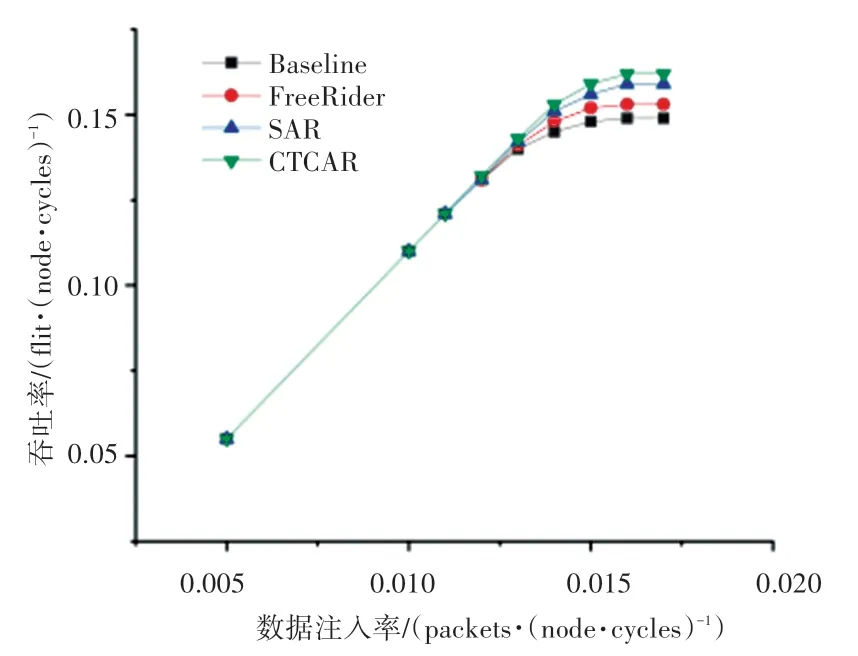
图19 random 流量模式下8×8 mesh 吞吐率Fig. 19 Throughput of 8×8 mesh in random traffic
图18 中,当注入率为0.03 packets/node/cycle时,4×4 mesh random 流量模式下4 种方案均达到饱和状态。在饱和注入率下,CTCAR 与SAR、DBAR和Baseline 相比分别降低了2.8%、4.2%和5.6%的饱和吞吐率。
图19 中,当注入率为0.016 packets/node/cycle时,8×8 mesh random 流量模式下4 种方案均达到饱和状态。在饱和注入率下,CTCAR 与SAR、DBAR和Baseline 相比分别降低了1.9%、5.6%和8%的饱和吞吐率。
4.2.3 面积及功耗分析
本文采用的实验工具是Synopsys 公司的Design Compiler,所采用的工艺库为45 nm 标准单元库,对相同规模的4 种方案进行逻辑综合。
表3 为本文方案与对比方案的硬件开销。由于CTCAR 中添加了AVCA 模块、SSA 模块和VCC 模块,使得本文的面积和功耗开销都有微小的增加。但是,通过SSA 仲裁机制,AVCA 动态为高优先级线程分配虚拟通道,CTCAR 防止高优先级线程数据包发生局部拥塞,可以有效降低网络的平均延迟,以及提高网络的吞吐量。考虑到CTCAR 整体性能优势,CTCAR 中额外面积和功耗开销所带来的影响是可以接受的。
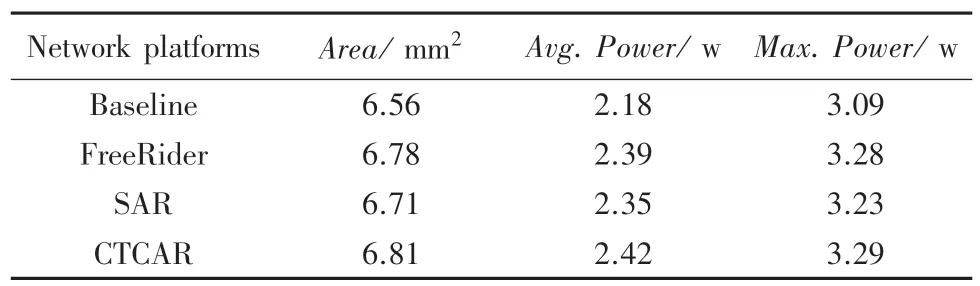
表3 面积与功耗开销Tab.3 Area and power consumption overhead
5 结束语
对基于NoC 的多核处理器来说,数据包在网络中的路由过程占据了较多的线程执行时间。有的线程由于缺失地址较多,需要在NoC 传输的数据包较多,因此这个线程执行得较慢。而同步屏障(Barrier)的存在,使得其他执行进度快的处理器需要等待这个执行进度慢的处理器,不仅影响性能且浪费功耗。
本文首先引入文献[13]中Slack参数,提出了基于Slack的仲裁机制SSA。其次,本文通过在数据包头flit 中嵌入标签的方式,将不同线程的数据包分类,用VCC 为不同类别的线程分配不同数量的虚拟通道。最后,本文提出了CTCAR 路由算法选择策略,可以有效降低高优先级线程数据包发生拥塞的可能性。
实验结果表明,与SAR 相比,本文方案在增加可接受的硬件开销、功耗开销下,可以有效降低网络平均延迟,提高网路吞吐率。
