基于机器学习算法的脑梗死伴颅内动脉狭窄预测模型研究☆
2022-02-03娜迪热艾孜热提艾力严伟鲁庆波玉苏普江麦麦提
娜迪热·艾孜热提艾力 严伟 鲁庆波 玉苏普江·麦麦提
中国颅内动脉粥样硬化性狭窄登记研究(The Chinese Intracranial Atherosclerosis Study, CICAS)研究发现颅内动脉严重狭窄和多发狭窄是卒中复发的危险因素[1]。早期识别颅内动脉狭窄,早期干预可减少卒中复发,提高脑梗死治疗效果[2]。颅内动脉狭窄常用筛查方式为CTA、MRA或DSA等血管成像检查,其费用较高,为有创性检查,部分县级及以下基层医院无法完成。既往已有研究者使用机器学习算法研究脑卒中诊疗过程[3],建立卒中发病风险预测模型,评估卒中患者病情严重程度,进行卒中疗效评估及卒中预后预测[4]。但国内利用机器学习分析脑梗死伴颅内动脉狭窄方面研究较少,本研究利用机器学习的特征选择方法从众多因素中筛选出与脑梗死伴颅内动脉狭窄相关性最强的预测因子,在此基础上采用3种机器学习算法建立预测模型并评价及比较模型的预测性能。
1 资料与方法
1.1 一般资料 本研究回顾性收集2013年1月至2019年9月喀什地区第一人民医院神经内科住院的脑梗死患者临床资料。纳入标准:①符合脑梗死诊断标准;②住院期间完善颅脑平扫(CT或MRI)和头颈血管成像(CTA或MRA)检查。排除标准;①出院时诊断为动脉夹层、大动脉炎、动静脉血管畸形、烟雾病等病因所致的急性脑梗死;②颅脑影像检查发现颅内占位性病变、急性脑梗死合并出血、严重感染、肿瘤、严重肝肾功能障碍、癫痫及妊娠等情况;③合并有房颤或严重心瓣膜病等心源性栓塞因素;④血管成像检查中有伪影;⑤检验指标缺失率达40%的患者。本研究经伦理委员会审批通过[批件号:喀什地区第一人民医院(2019)快审第(81)号]。
1.2 变量采集及标准 从喀什地区第一人民医院信息系统中提取研究对象的首页诊断信息、血管成像检查结果、住院期间检验结果等数据。为了避免涉及患者隐私,在提取数据时隐去姓名、住院号等可能暴露患者身份信息的数据并为每位患者进行单独编码。
提取的首页信息包括年龄、性别、出入院时间、出院主诊断、出院其他诊断等。性别按编码记录,如男性记录为1,女性记录为0。根据出院时诊断信息记录患者是否有高血压病、是否有糖尿病、是否有冠心病、是否有脂代谢异常等研究因素,结果记录为二分类变量。
从医院检验系统中获取研究对象住院期间所有检验结果数据,规定每项指标仅保留首次检验结果。从系统中提取的检验项目值共有139种,为减少缺失值对研究结果的影响,删除缺失比例高于40%的检验项目,并删除检验项目完成率少于60%的研究对象。利用原有检验结果数据构建两个新的特征,即“是否贫血”和“外周血中性粒细胞-淋巴细胞比值(neutrophil to lymphocyte ratio, NLR)”。
从我院影像归档和通信系统中调取研究对象头颈部血管成像结果,包括MRA和CTA。纳入研究的颅内动脉包括:颈内动脉C6-7段、大脑中动脉、大脑前动脉、大脑后动脉,椎动脉V4段、基底动脉。颅内动脉狭窄率的计算公式为:,其中Dn为病变血管近段正常处的直径、Ds为病变血管最狭窄处直径。颅内动脉狭窄定义为上述动脉一处或多处狭窄率50%以上的病变[5]。根据患者影像检查结果记录每位脑梗死患者是否伴有颅内动脉狭窄,记录为二分类变量。按照是否有颅内动脉狭窄将患者分为动脉狭窄组和无狭窄组。
1.3 预测模型建立方法 机器学习是利用数据构建模型,并将其用于预测的统计方法。机器学习第一步为特征工程,包括数据清洗,缺失值处理,数据转换,特征构建,特征选择等步骤。第二步通过训练数据集构建机器学习模型。第三步测试模型性能[6]。具体过程如下图1所示。本研究利用Python程序设计语言的Scikit-learn机器学习库创建和训练机器学习模型。

图1 机器学习流程图
特征选择是指从众多的特征中选择出与目标因素相关性较强的、能够提升模型预测性能的特征子集的过程。特征选择能够降低特征数量,避免维度灾难,降低训练的难度,提升模型预测性能,是特征工程中重要的部分[7]。本文采用机器自动的特征选择方法,利用方差分析的F值大小及对应的P值从众多变量中筛选出与脑梗死伴颅内动脉狭窄相关性最强的变量作为预测因子纳入预测模型中。
在特征选择基础上,本文利用训练数据集分别构建决策树、随机森林和神经网络等三种机器学习模型,并利用准确率、灵敏度和曲线下面积(AUC)值等指标对模型预测性能作对比,选择出最佳预测模型。
2 结果
2.1 基线信息 本研究共纳入了2365例脑梗死患者,其中男性占58.7%(1389/2365)。无颅内动脉狭窄组1651例,平均年龄(60.3±11.6)岁;有颅内动脉狭窄组714例,平均年龄(61.6±11.3)岁。
本研究共纳入74种特征,包括患者性别、年龄、是否有高血压病、是否有糖尿病、是否有冠心病、是否贫血等6种基础基线信息,及空腹血糖、白细胞、低密度脂蛋白、同型半胱氨酸等67种化验值以及NLR。
2.2 特征选择结果 本文利用方差分析的F值,即f_classif,计算每个特征与目标因素之间的相关性,f_classif值越大,则表明该特征与目标因素之间的相关性越强,越能够提升模型的预测性能。在74种特征中选出组间差异有统计学意义(P<0.05)的23个特征作为脑梗死患者伴颅内动脉狭窄的预测因子,具体结果如表1所示。
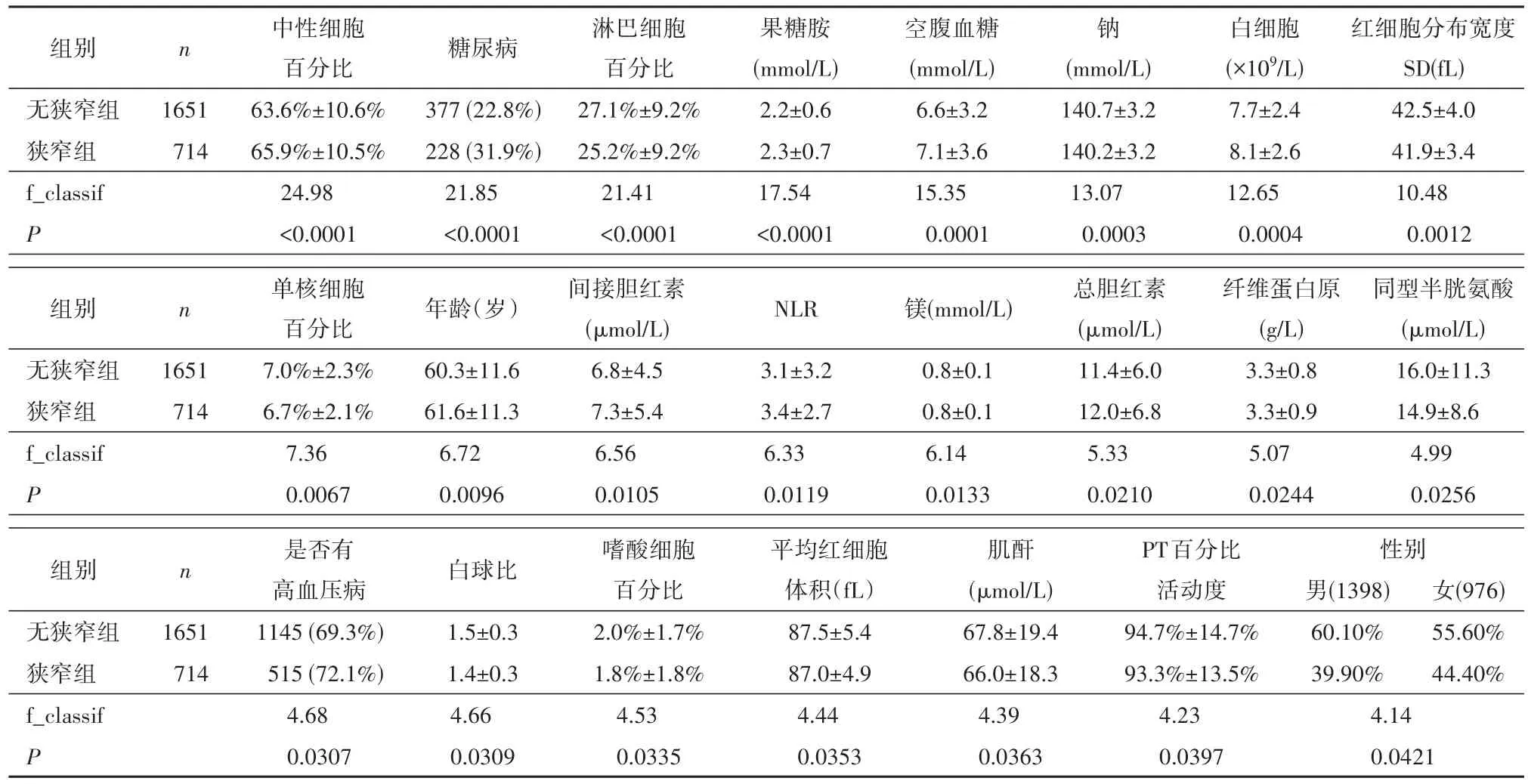
表1 颅内动脉狭窄组与无狭窄组患者特征指标比较
2.3 预测模型性能比较结果 本文为了综合衡量模型的性能,利用十折交叉验证法分别计算每个模型的准确率、灵敏度和AUC值等性能指标。随机森林模型预测脑梗死伴颅内动脉狭窄的准确率最高,即(0.85±0.13);决策树模型的灵敏度最高,即(0.92±0.05);随机森林模型的 AUC值最高,即(0.89±0.10)。三种模型中随机森林模型的综合性能最佳。见图2、表2。
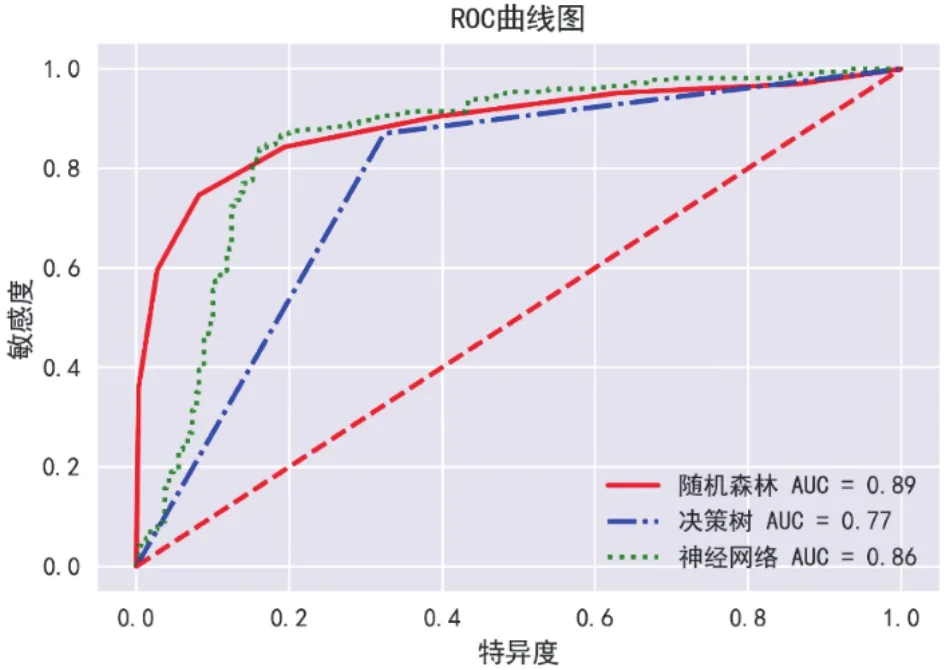
图2 三种机器学习预测模型性能比较

表2 三种机器学习预测模型的性能比较
3 讨论
机器学习作为智能时代新兴的数据处理方法,可发现数据中隐藏的关联关系,已在国内外广泛运用于各类医学研究[8]。本研究利用特征选择方法在众多因素中筛选出脑梗死伴颅内动脉狭窄的预测因子并在此基础上使用三种机器学习算法建立脑梗死伴颅内动脉狭窄的预测模型,以期能为颅内动脉狭窄的防治提供参考依据。
特征选择结果显示中性细胞百分比、糖尿病、淋巴细胞百分比、果糖胺、空腹血糖、血钠、白细胞、红细胞分布宽度SD、单核细胞百分比、患者年龄、间接胆红素、NLR、镁、总胆红素、纤维蛋白原、同型半胱氨酸、是否有高血压病、白球比、嗜酸细胞百分比、平均红细胞体积、肌酐、PT百分比活动度、性别等23个因素与脑梗死伴颅内动脉狭窄相关。上述指标中糖尿病、空腹血糖、高血压病、年龄、同型半胱氨酸等因素是经典动脉粥样硬化危险因素,已有研究[9-10]提示其与脑梗死伴颅内动脉狭窄有关。本研究发现血清镁离子水平是颅内动脉狭窄相关,这与ARSAVA等[11]研究者的结论一致,其机制仍需进一步研究。特征选择发现白细胞,淋巴细胞百分比,单核细胞百分比,NLR等指标与颅内动脉狭窄有关。既往研究推测上述4种指标与动脉粥样硬化相关性机制可能由炎症、内皮功能紊乱等原因所致[12-13]。本研究数据分析提示胆红素作是颅内动脉狭窄的预测因子,这与YU等[14]研究结果一致。已有研究表明胆红素具有抗炎及抗氧化的特性,可抑制氧自由基,抑制血管慢性炎症反应,延缓动脉粥样硬化的进展等作用[15]。本研究提示血钠,白球比,肌酐等指标与颅内动脉狭窄相关,但有关上述三种指标与颅内动脉狭窄的相关性方面研究较少,作为回顾性研究结果可能受到其他混杂因素的影响,需要后续前瞻性研究来进一步证实本研究的结论。
在特征选择基础上,本文利用训练数据集分别构建神经网络、决策树和随机森林等三种机器学习模型,并利用准确率、灵敏度和AUC值等指标对模型预测性能作对比。不同的机器学习模型有各自的优缺点[16]。神经网络是一种模仿人脑神经网络进行分布式并行信息处理的机器学习模型,具有自学习和自适应能力,但收敛速度较慢,对计算资源的需求较高。此模型已被国外研究者用于卒中分类系统的研发,该模型的脑卒中分类准确率达到98.9%[17]。本研究中神经网络模型准确率最低,为(0.77±0.13);敏感度较高,为(0.91±0.06);综合性能AUC值为(0.85±0.12)。决策树模型基于树结构进行决策,能够可视化展示决策过程,但容易出现过拟合的情况。AJCEVIC等[18]建立的决策树模型基于入院时的NIHSS、缺血核体积和年龄等特征预测醒后卒中患者的预后,模型预测准确率为86.5%,AUC为0.88。本研究中决策树的训练速度最快,而且灵敏度最高,为(0.92±0.05);但是容易出现过拟合的情况,因此在测试数据集中AUC值最低,为(0.78±0.11)。虽然随机森林模型的训练速度比决策树慢,但是利用集成学习算法防止出现过拟合,有效提高模型的泛化能力,综合性能最佳,灵敏度为(0.88±0.10),AUC为(0.89±0.10)。
综上所述随机森林模型对脑梗死患者是否伴有颅内动脉狭窄的预测性能最佳,对于暂无条件完善血管成像检查的基层医院,可通过此模型更高效地筛选出可能伴有颅内动脉狭窄的脑梗死患者并转诊,从而提高颅内动脉狭窄的检出率,同时避免过多有创检查,减少无效转诊,提高颅内动脉狭窄患者的诊疗效率,节省医疗资源。
虽然本研究数据量较大,但仍存在如下局限性:①因回顾性收集既往患者资料,部分缺乏检查结果的患者被排除,可能存在选择偏倚;②作为单中心研究,缺乏外部验证,尚需在不同人群中加以验证;③因研究数据获取方法为从医院网络系统中批量提取并清洗,研究中并未纳入基线NIHSS、卒中类型、卒中史、吸烟史等现阶段不易直接提取的潜在预测因子。随着医院病历系统的结构化,后期研究会利用自然语言处理等方法将上述因素纳入分析并不断优化预测模型。
