一种基于Interactive KeyPoints的目标检测算法*
2022-01-15王志达丁胜夺
王志达 丁胜夺 韩 亮
(中国石油集团安全环保技术研究院有限公司HSE信息中心 北京 102206)
1 引言
在计算机视觉领域,自然图像中存在着多目标、姿态和位置等问题[1],因此目标检测是一项富有挑战性的任务。在过去的二十年中,基于卷积神经网络(CNNs)[2~5]的检测器占据主导地位且取得巨大成就,在精度和速度上都有显著的提高[6]。但这些检测大多依赖于锚框来实现检测任务,锚的设定具有高度的类不平衡问题,使得分类性能下降。模型的检测性能对人工设定的锚框较为敏感,模型鲁棒性差。尤其是对于小目标的检测,需要设置较小尺寸的锚框,导致锚涉及的相关参数多、计算复杂、占用内存大等问题。
近年来,无锚检测器因其克服了锚框的问题而迅速发展起来。目前有两种主流的方法来构建无锚检测器:基于中心的检测器[7~10]和基于关键点的检测器[11~15]。无锚的方法通过直接获取目标的中心点或关键点来构成目标的边界框,它们比基于锚的检测器在速度和计算量上都更高效。但大部分无锚检测器[7,11,13]在检测精度方面仍有劣势,尤其是小目标。主要的原因有三个:1)无锚的检测方法难以建立关键点之间密切的关系,对于目标,往往会产生大量的误报,导致检测精度低;2)无锚的检测方法可能会错误地将不相关的关键点分组到一个对象中。3)无锚的检测方法有利于分类任务,但缺乏先验边界框,导致回归效果未能达到最优。
近年来,有研究发现Transformer的核心思self-Attention可以建立目标之间的长距离依赖,能够获取全局的上下文信息,从而具有很强的表达能力[16],基于Transformer的方法得到进一步的研究。将Transformer应用到计算机视觉中的各种特定任务中,如分类[17~19]、目标检测[20~24]等,通过自注意力获取全局信息来建立特征之间的联系,同样可以获得更好的性能,但仍未能很好地解决小目标问题。
2 算法设计
2.1 算法思路
基于锚的检测方法不仅需要设定不同尺度和宽高比的锚框,如RetinaNet[25]在每个位置包含了45个锚框,且需要对这些锚框进行回归,这些过程涉及到的参数较多且计算量大。锚框需要人工设定,模型的性能对锚框较为敏感,从而鲁棒性较差。
在本文中,使用一种关键点集的表示法[13],如图1所示。
通过学习限制对象的空间范围和指示语义上重要的局部区域的方式,自适应地将具有代表性意义的点定位在目标上。这些点的训练是由识别目标和目标定位共同驱动的,计算它们的相似性,忽略无关紧要的点,这样就可以被真值紧紧包围,引导检测器进行正确的目标分类和更细粒度的定位。该方法不需要使用锚来在边界框的空间上采样,是以自上而下的方式从输入图像或对象特征中学习的,有利于端到端的训练。
2.2 模型框架
本文提出一种基于交互关键点的无锚检测模型,该模型主要包含:1)主干网用以生成多尺度特征{F1,F2,F3};2)交互的特征金字塔{Ft1,Ft2,Ft3}(如图2所示);3)自适应采样方法生成具有代表意义的关键点以构建预测边界框;4)头部网络对关键点进行精炼来实现分类和回归(如图3所示)。
为了更清楚地阐述检测基线,只构建了特征金塔单个尺度F2的检测流程。首先对特征F2进行卷积操作以进行自适应采样式(1)得到一些具有代表意义的关键点:

其中,n为总的采样点个数,本文中的n设为9。然后计算这些采样点的重心作为将要预测对象的中心点(x,y),假设采样点分别为{x1,x2,…,xn},并计算偏移(offset)式(2)对这些关键点进行精炼:
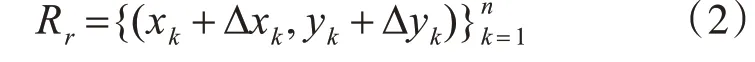
其中,T1为在这些采样点的两个坐标轴方向的Min-max操作来确定Bp,即连接所有采样点的边框。T2为子采样点的空间Min-max操作来决定矩形边框Bp。T3为采用采样点的均值和标准差来计算矩形边框Bp的中心点和尺寸。本文采用T3作为变换函数,同时利用自注意力机制计算这些关键点之间的相似性,在训练和预测过程中关注与重要关键点相似的点,忽略不相似的点,以此实现更精确的关键点之间的匹配,同时在对关键点回归时计算关键点之间的相似性并评分,得到与每个真值框上的关键点相似性最高的哪些点,然后根据每个真值关键点进行回归,实现更细粒度的定位。如果特征图中的每个关键点都作为一个随机变量,任意两个关键点a(xi,yi),b(xj,yj)之间的相似性计算公式如下。
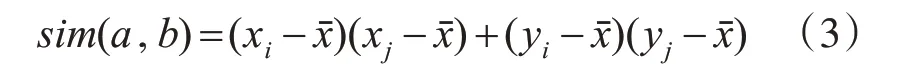
然后根据真值框和pseudo box的差别计算关键点的损失用以训练。与此同时,对上述方法获得的offsets进行可变卷积得到类别分数映射和偏移域(offsets field),分别用以分类和定位。对offsets field进行上述同样的操作并根据真值框对关键点进行回归形成最终的检测边框。
2.2.1 交互的特征金字塔
为了获取特征图的全局信息,本文在主干网生成多尺度特征后,将自注意力层代替卷积层以生成具有局部和全局信息的特征金字塔。对于self-attention层,本文采用scaled-dot-product[26]的形式,给定query矩阵Q,key矩阵K以及value矩阵V,首先将Q和K相乘计算相关性,然后除以缩放因子再进行soft max运算,得到的结果与value向量的加权和就是最终输出。
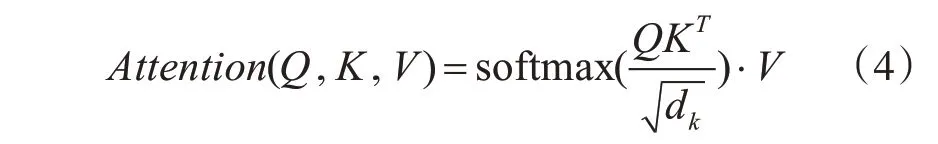
其中:
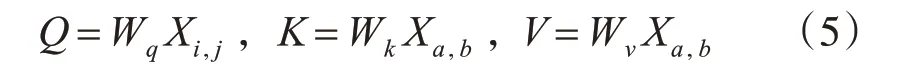
Wq,Wk,Wν分别为Transformer矩阵。
如图3所示,以特征F2的转变为例,首先给定一个像素点xi,j,特征的其他像素位置为a,b∈Nk(i,j),Nk(i,j)为像素个数。经过单个头部注意力层可以得到该像素的变换输出为

其中,qi,j=Wqxi,j,ka,b=Wkxa,b和νa,b=Wνxa,b为位置i,j像素和其他像素的线性转变,soft maxa,b表示将一个soft max应用到除了位置i,j的其他数字,然后对它们求和。分别对特征{F1,F2,F3}的每个像素进行变换得到特征{a,b,c},然后将他们进行联结(concatenate),并添加了残差连接将特征F2和上述特征进行联结得到转变后的特征Ft2。分别对特征{F1,F2,F3}进行上述操作并加上自上而下的连接得到最终的{Ft1,Ft2,Ft3}。
2.2.2 头部网络结构
本文的头部网络结构(如图3所示)主要包含两个子网络:分类和定位子网络。
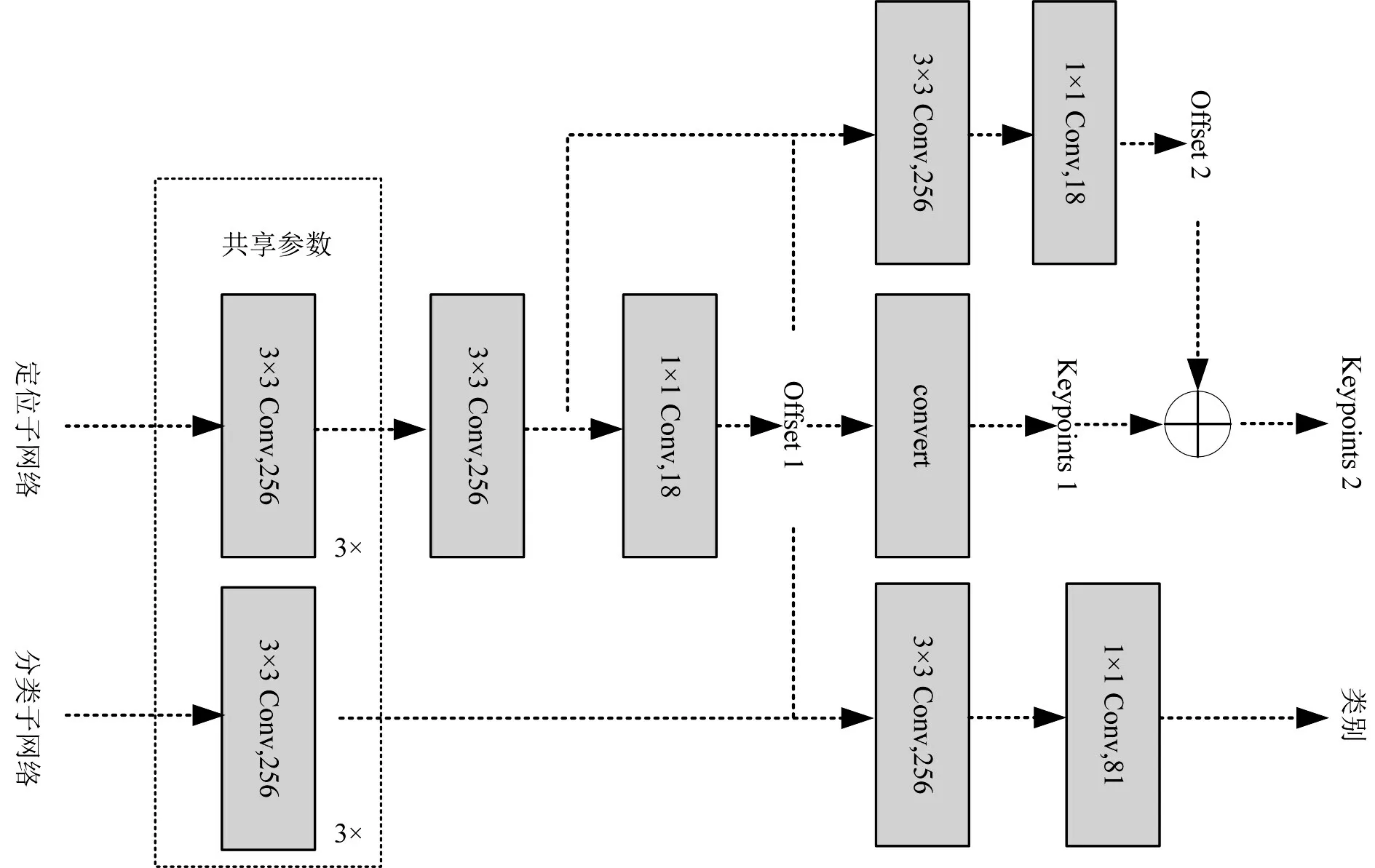
图3 头部网络
分类子网络主要由四个3×3、通道数为256的卷积层组成,然后经过一个1×1、通道数为81(数据集类别加背景)的卷积并进行softmax操作得到最终的类别。定位子网络在经过同样的四个3×3卷积操作后分为两部分,一主干部分通过Offsets 1将采样点转变为构成边界框的关键点Keypoints 1,分支通过一个3×3卷积和1×1的卷积得到Offsets 2,将两个分支进行融合对关键点进行refine和回归得到关键点Keypoints 2用以形成最终的检测边框。
3 实验
本文以MS COCO 2017[27]为数据集进行实验,COCO包含80个类别,118K张图像作为训练集,5K图像作为消融研究的验证集(minival)和20K张图像作为验证(test-dev)。本文采用标准的Average Precision(AP),APS,APM和APL来评估模型性能。
实验配置:CPU为Intel i7-9700k;内存为32G;GPU为NVIDIA GeForce GTX TITAN X;深度学习框架为Pytorch 1.7.1;CUDA版本为10.1。
3.1 训练细节
为了和SOTA进行比较,本文还采用ResNeXt[4]作为主干网。上述主干网在ImageNet[28]上经过预训练,然后整个网络在训练集上冻结主干网参数并进行微调。
我们使用文献[19]的参数设定,采用了SGD进行训练,mini-bacth为2。学习率、权重衰减和动量分别设置为0.01、0.0001和0.9。当训练至80K个interaction时,学习率减少至原来的1/10。本文在训练中采用图像的随机水平翻转。在推理中,NMS(σ=0.5)被作为后处理方法。
3.2 损失函数
本文采用的损失为

3.3 与SOTAs进行比较
本文在MS-COCO[27]基准test-dev 2017的测试中将ITKP与最先进的检测器进行了比较。在这些实验中,本文在训练过程中将图像从640关键点到800关键点随机缩放,并将迭代次数增加至200K(学习率按比例缩放进行变化)。表1列出了实验结果的比较,在相同的主干网上,本文的网络在COCO上的检测精度和基于锚的两阶段检测器Faster R-CNN[28]和一阶段检测器RetinaNet[25]与基于关键点的方法RepPoints[13]相比,虽然有的AP稍低,但整体的检测精度和在小目标上的AP较高且具有较少的计算量。使用ResNeXt-101作为主干网,ITKP的AP达到41.9%。

表1 与SOTAs的比较(%)
3.4 消融研究
本文的消融研究在MS-COCO 2017 val set[27]上实施,主干网为ResNet-50和ResNet-101。消融研究旨在如下。
1)比较边界框和关键点不同表示方法的效果,网络配置都一样,处理方法不同。由表2可以看出,采用关键点为表示方法要比使用边界框为表示方法的精度高约2.1%~2.3%。

表2 边界框(BB)VS关键点(KP)
2)比较单个锚和单个中心点作为初始表示方法。由表3可以看出,中心点作为初始表示方法比锚作为初始表示方法的AP高1.3%~1.6%。

表3 单个锚(SA)VS单个中心点(SC)
3)比较基于锚和无锚的检测方法,RetinaNet和FPN为基于锚方法,其余的为无锚方法。由表4所示,在相同的主干网上,相比基于锚的检测器,无锚检测器不仅避免了锚的设定,还较大幅度地提升了AP。

表4 基于锚和无锚方法的比较
4)比较使用(w)和不使用(w.t)交互的特征金字塔(TFP)的结果。由表5可以看出,使用交互的特征金字塔不仅可以提升整体的AP,还提升了小目标APs为2.3%。
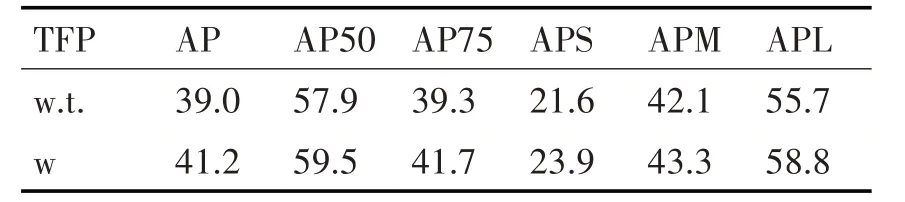
表5 w TFP VS w.t TFP
另外,由图4所示,我们将采用卷积操作得到的特征金字塔(b)和通过自注意力层得到的特征金字塔(c)的特征进行可视化,可以看出,相比(b),(c)的特征更加丰富,特征之间也存在一定的关联,对小目标特征更加敏感。

图4 特征可视化
3.5 实验结果
通过上述实验结果表明,本文提出的模型可以有效地提升目标检测的精度且具有较少的计算量。本文在COCO中的测试集中挑选了一部分难以检测的图像进行检测,检测结果如图5所示。

图5 检测结果可视化
4 结语
针对小目标检测精度低,锚框设定涉及的参数量大、计算复杂和导致模型鲁棒性弱的问题,本文提出一种基于交互关键点的无锚检测模型。该模型避免了锚的设定,通过学习限制目标的空间范围和语义重要的局部区域的方式,自适应地将具有代表意义的点定位在目标上。另外,使用自注意力机制建立关键点之间的联系。设计了一个交互的特征金字塔,结合CNN提取的局部信息和自注意力层来获取的全局信息。通过上述方法,提升了基于关键点的检测器的小目标的检测精度。本文提出的检测模型的性能得到较大的提升且具有较少的计算量。但是,本文提出的模型在精度方面仍有很大的优化空间。
