用于自动驾驶车辆的融合注意力机制多目标跟踪算法
2022-01-13迟志诚陈一凡
张 平,迟志诚,陈一凡,惠 飞
(1. 长安大学 汽车学院,西安 710064,中国;2. 长安大学 信息工程学院,西安 710064,中国)
近年来,多目标跟踪问题(multiple object tracking,MOT)在智能交通、自动驾驶等领域受到了大量关注,并具有重要的应用前景[1-2]。例如,对于道路上行人和车辆的准确跟踪可以帮助自动驾驶车辆做出更好的驾驶决策。要完成多目标跟踪,通常的流程是利用检测器检测图像序列中的特征信息,然后跟踪算法会基于检测结果将相关目标进行关联以实现目标的跟踪。目前,很多概率推断模型已经应用于多目标跟踪中的数据关联,例如基于多假设跟踪(multiple hypothesis tracking,MHT)[3],联合概率数据关联(joint probabilistic data association, JPDA)[4]等经典的多目标跟踪方法,可以捕获图像序列中固有的时序相关信息。
随着目标检测技术的不断增强,基于此的目标跟踪方法已成为主流框架。在这种以目标检测为核心的算法中,跟踪框架的性能极大地依赖于对目标的有效准确的检测。许多不同的图像特征描述方法可以提取图像特征并应用于目标检测中。传统方法是基于图像底层特征,通过训练好的分类器将图像特征进行分类以确定目标信息。
文献[5]在支持向量机(support vector machine,SVM)的基础上增加了自适应增强算法(adaptive boosting, AdaBoost)作为粗细结合的两级检测方法以检测出复杂背景下的多姿态行人目标。文献[6]设计将方向梯度直方图(histogram of oriented gradient, HOG)与SVM结合的归一化算法用于行人检测方案。HOG可以很好地描述局部目标的形状,这使得该算法对于一些特定的图像变化例如光照条件改变是有效的。但是此类手工设计特征在一些目标交互频繁的复杂场景中,经常会产生大量的漏检和误报问题。
近年来,深度学习思想的兴起和发展在多个计算机视觉相关领域取得了很好的应用,相关检测算法逐渐从传统的手工设计特征提取方法转变成了基于深度学习的特征提取算法。SORT算法[7]使用了Faster R-CNN[8]卷积神经网络对行人的外观特征进行建模,神经网络可以直接输出目标的位置和大小,使跟踪算法可以快速实时运行。为减少SORT算法中存在的频繁更换目标标识(identity, ID)的问题,Deep SORT[9]算法应用在行人识别数据集上训练的广域残差网络,降低了跟踪过程中ID值变换次数。文献[10]在孪生神经网络的基础上融合扰动感知模型,提高了算法在复杂场景下的跟踪精确度。但是仅仅采用外观特征是不够的,因为参数量的增长会带来计算量的大幅增加,而单一外观特征在一些复杂的场景下,如相似外观和频繁遮挡等情况下就容易受到干扰,无法正确地对目标做区分并进行有效的跟踪。
针对上述多目标跟踪算法存在的一些问题,为了进一步提高跟踪过程的鲁棒性和准确性,本文在目标检 测 算 法YOLO-v3网 络(YOLO为“You Only Look Once”系列算法)[11]的基础上融合注意力机制,通过对目标特征图的空间和通道两个维度的特征施加不同的权重,在基本不影响实时性的前提下改进了其对于关键特征的提取筛选能力,从而提高物体在形变和运动状态改变时的检测效果。
此外,增加了基于长短时记忆网络(long shortterm memory network, LSTM)以提取物体的运动特征。通过提取视频流中帧与帧之间长期的时序关系构建目标的运动模型,对每个目标的轨迹进行动态建模。这样当出现仅仅依靠外观特征无法正确区分目标或者同一目标因为遮挡导致目标ID值频繁变换的问题时,运动特征可以帮助算法正确分配目标轨迹。在完成对象运动状态的回归和预测步骤之后,它们的特征表示将被结合起来以对检测结果和轨迹进行匹配,实现逐帧的目标检测和跟踪。
1 多目标跟踪框架
1.1 整体框架
多目标跟踪整体框架如图1所示。
对于给定图像序列,首先进入YOLOv3网络的外观特征提取模块,在网络末端的全连接层之前还增加了注意力机制,目的是为了提高跟踪的准确性和稳定性;然后,通过长短时记忆网络LSTM获取物体在运动过程中的运动特征,提取时序相关特征表达;最后,对LSTM网络的输出计算出目标的相似度数值,最终匹配并关联对象以完成整个多目标跟踪过程。
本文整体框架是基于检测的多目标跟踪方法,主要任务包括:目标检测,特征提取,目标匹配。研究中将目标外观特征和运动特征的提取作为跟踪框架的关键部分。表1给出了多目标跟踪框架中各模块的输入以及输出。

表1 各模块输入输出
1.2 目标检测
构建一个足够准确的外观模型,对于目标跟踪问题至关重要。YOLO-v3作为一种基于深度学习的检测方法,已在计算效率和识别精度之间取得了很好的平衡[11]。本文基于该方法并融合后面介绍的注意力机制设计了外观模型,目的是增强关键特征的提取筛选能力。YOLOv3算法主要由两部分构成,即Darknet-53骨干特征提取网络和特征金字塔网络。图2给出了YOLO-v3算法的检测流程。输入的图像数据先经过Darknet-53骨干神经网络提取特征,再经过金字塔结构预测网络对不同尺度目标做出预测。
YOLO v3的检测结果包括 (x,y,w,h,c,p),其中:x、y为目标的位置,w、h为目标的宽度、高度,c为置信度,p为目标的类别概率。置信度的作用是表明图像中包含目标的概率以及预测的边界框位置的准确性。置信度为
式中:IOU为预测候选框与原始真实框之间的重叠率,
式中:A表示区域面积,box表示某一方框,truth表示真实结果,pred表示预测结果。
预测过程会产生多余的边界框,因此在随后的步骤中,筛选层使用非极大值抑制操作,过滤掉IOU分数小于阈值的检测结果,选择重叠度最大的检测框作为最终的特征提取框进行输出。
1.3 注意力机制
通常,卷积神经网络的卷积运算仅考虑局部区域进行操作,感受野的面积受到卷积核的限制。如果想要捕获更多图像数据则需要通过堆叠卷积层来扩大感受野,但是太多卷积层会导致算法的计算复杂度提高。引入注意力机制后,神经网络将能更关注目标跟踪任务的重点信息,提高目标检测的准确性。本文采用的卷积模块的注意力机制模块(convolutional block attention module, CBAM)[12]如图3所示。
在通道注意力的基础上,进一步加入空间注意力机制,整个注意力模块可以从通道和空间两个维度对特征进行加权调整,定位到目标跟踪任务的有用信息,抑制目标跟踪任务的无关信息,从而有效应对目标跟踪时遮挡、形变、光照、运动状态变化等外部因素的影响。
若假设图像输入特征为Fi(Fi∈RH,W,C,H、W和C分别代表初始特征的高度、宽度和通道),输出特征为Fo,中间特征为Fm,Mcha为通道注意力参数,Mspa为空间注意力参数,以 °表示矩阵的Hadamard积;则输入输出之间的关系如下:
式中:σ表示sigmoid函数,MLP表示带有一个隐藏层的多层感知机,AvgPool表示平均池化,MaxPool表示最大池化,f7×7表示经过7×7的卷积核。
通过式(3)和式(4)的矩阵乘法可以获得加权目标特征。第1步使用通道注意力参数完成对目标特征的筛选,从而更好地提取目标的通道信息;将筛选过的特征经过第2步的空间注意力机制,得到加权目标特征信息,最终的目标特征图与原图像的特征图维度一致。
通道注意力机制可以选择性地增强与目标跟踪场景相匹配的特征。当目标的外观发生变化时,通道注意力可以使跟踪框架更加注重图像的某些特征,增强算法的鲁棒性。但是,单一的通道注意力机制忽略了全局特征之间相互的位置关系。作为通道注意力机制的补充,空间注意力机制更加关注图像的特定位置。两种注意力机制相辅相成,从而达到对目标增强和干扰抑制的效果。
1.4 运动模型
传统的循环神经网络(recurrent neural network,RNN)对于处理短时序数据具有良好的表现。但是,该方法并不能捕获长时依赖关系,因为当通过反向传播计算梯度时,梯度将呈指数衰减,这使得神经网络靠前的卷积层权重参数无法更新。在梯度消失的情况下,RNN会丧失学习远处单元信息的能力,导致时间间隔长的信息无法进行有效传递。
作为RNN的变体,LSTM(如图4所示)引入了3个控制门(分别是遗忘门、输入门和输出门)以防止网络权重随时间传播而衰减[13]。门是一种让信息有选择通过的机制。例如,如果LSTM单元从输入序列中检测到了一个重要的特征,遗忘门会决定它携带该信息的程度,因此它可以很容易携带一个长时信息,捕获潜在时序依赖。通过应用这种策略,LSTM可以处理长期依赖问题,有助于遮挡时目标跟踪丢失的重新捕获,进而提升目标跟踪的稳定性。
研究中,目标检测网络提供的目标特征信息将送入LSTM中进行处理,循环神经网络会计算出图像特定区域属于目标或背景的概率,达到或超过预定义阈值的分数将被识别为确定目标,可以为其保留外观特征以供下一次迭代使用。
为了确保在复杂环境下目标跟踪的可行性和稳定性,本文将融合注意力机制的YOLO-v3网络与LSTM网络相结合形成整体跟踪框架。在训练阶段,使用均方误差损失函数来衡量目标的预测位置(Bpre)和目标的真实位置(Btar)之间的距离,即
式中:n为批次中训练样本的数量。
2 数据集选择及计算平台设置
为了验证上述跟踪框架的有效性,本文选择比较常见的行人、车辆检测数据集MOT16、KITTI和TUD-Crossing对算法进行验证。研究中采用Adam优化方法将损失函数值降到最低,在训练开始之前,对数据集进行了预处理将图像缩小至512×512,以提高算法的运行速度。由于图像尺寸减小,设置训练过程中的批量大小(batch size)为64,以提高内存利用率并减少训练时间。按照经验值,设置学习率(learning rate)初始数值为0.001,权重衰减率为0.000 5,动量为0.900。在整个迭代过程中的迭代周期(epochs)为200次。为了进行状态估计和跟踪管理,LSTM网络设置了300个隐藏单元。对于每次迭代,在序列中输入6帧的长度进行训练。训练和验证工作在配备16 GB内存 和NVIDIA GeForce GTX 1080Ti GPU的PC中 的TensorFlow平台上完成。
由表2可知:相比于YOLO-v3神经网络,融合了注意力机制的特征提取网络实现了更好的目标识别效果。添加注意力机制的YOLO-v3网络在运行速度基本一致的情况下,平均精确度(mean average precision, mAP)值比原来提高了1.9个百分点。因此,注意力机制可以提高网络对目标的检测精度,实现检测精度(mAP)和检测速度(frame per second, FPS)之间的平衡。
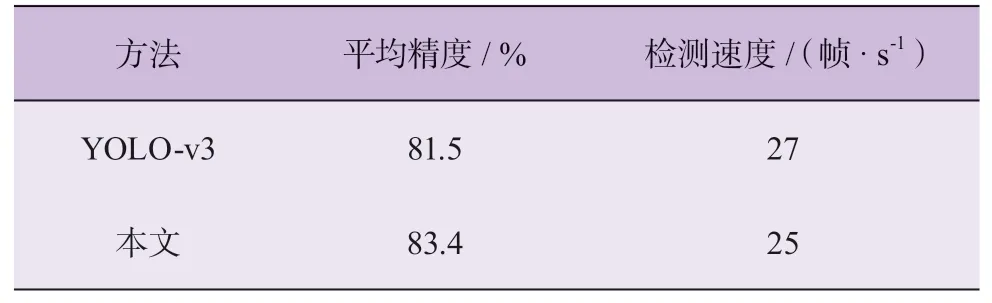
表2 特征提取效果对比
针对MOT16数据集有较为完善的多目标跟踪效果评价体系,具体评估指标包括:多目标跟踪准确度(MOTA↑),多目标跟踪精确度(MOTP↑),大部分(80%以上)轨迹被跟踪到的轨迹占比(MT↑),大部分(80%以上)未被跟踪到时的轨迹占比(ML↓),误检数(FP↓),漏检数(FN↓),同一轨迹目标ID值变换次数(IDS↓)。其中:“↑”表示高值高性能;“↓”表示低值高性能。
3 实验结果及分析
表3 给出了本文跟踪算法和其他已有跟踪算法(JPDA_m、LMP、AMIR、oICF、STAM、EAMTT)在MOT16数据集上表现结果的对比。
由表3可知:本文算法在多个评估指标上都取得了较好的成绩。与其他跟踪器相比,本文算法获得了最高的MOTA分数和较高的MOTP分数。这得益于目标检测框架输出的精确目标位置,因此也验证了所融合的注意力机制不仅较好地提高了特征提取的精确度,也提高了目标跟踪整体框架在持续跟踪过程中的鲁棒性。增加的注意力机制使目标位置定位更加准确,相应的分类损失以及置信度损失也会随之降低。

表3 不同跟踪算法的效果对比
本文算法得到了最高的MT分数和较低的ML分数,即使在目标运动过程中发生了遮挡现象,跟踪框架中注意力机制和运动模型也可以继续保持跟踪对象的运动状态。FP表示被认为是正例但实际为负例的数据,而FN表示被认为是负例但实际为正例的数据,本文算法得到了最低的FN分数和较低的FP分数,说明识别目标的准确性较好。本文算法获得的IDS分数较低,说明跟踪的稳定性较好。
在MOT16数据集上的部分跟踪结果见图5。
本文所提方法可以在出现大量目标的多帧图像中做到连续跟踪,同时对场景中出现的部分遮挡和目标丢失仍能成功跟踪。跟踪框架中的注意力机制,可以使跟踪器快速指向关注的目标,从而抓住跟踪任务的重点,当有目标形变或跟踪丢失时,该机制可以帮助跟踪器快速搜索并检测到原有目标;LSTM网络通过捕获视频流中的时序关系,实时更新目标的特征表示和运动轨迹,从而可以在更长的时间序列中维持目标的ID值。
图5 还展示了本文多目标跟踪算法在KITTI和TUD-Crossing数据集上的良好测试效果。由此可知:本文所提跟踪框架在多目标跟踪问题上有着较好的综合表现。
4 结 论
本文针对多目标跟踪问题构建了一种新的跟踪框架。借鉴人类视觉系统在多目标跟踪任务中的优异表现,在YOLOv3的基础上融合了注意力机制,相对于其他特征提取算法,在基本不影响算法实时性的前提下改进了对关键特征的提取筛选能力,有针对性地提高了整体跟踪算法可靠度和准确性,实现复杂场景下持续稳定的目标跟踪。
利用LSTM网络固有的循环结构,本文的跟踪框架可以捕获运动物体长时的运动特征,并记录跟踪过程中物体的动态外观和运动变化,从而有助于长时间跟踪到目标。
通过在目标检测数据集MOT16、KITTI和TUDCrossing上的计算验证,说明了本文所提目标跟踪框架整体上具有很好的表现,并将有望应用于自动驾驶领域。
