结合类属特征及因果发现的序列优化分类器链
2022-01-13罗森林王海州潘丽敏
罗森林, 王海州, 潘丽敏
(北京理工大学 信息与电子学院,北京 100081)
在图像标注[1-2]、文本分类[3-4]等应用场景中一个样本可以同时属于多个类. 比如在图像标注应用中,一个图像可能同时被标注为“海洋”和“船”;在文本分类应用中,一段文本可能同时包含“演唱会”和“门票”等多个主题. 这种数据被称为多标签数据,针对多标签数据的分类被称为多标签分类. 在多标签分类问题中,标签之间存在关联. 比如标记为“沙漠”的图片很可能被标记为“骆驼”,几乎不可能被标记为“雨林”. 挖掘利用标签间的关联关系能够有效地提升多标签分类效果[5-6].
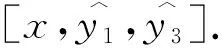
基于上述分析,针对分类器链中各标签的基学习器均在完整特征空间中训练导致学习特征冗余,以及因标签学习顺序随机且分类器链训练过程单向无反馈导致的标签间相关信息利用不充分等问题,提出一种结合类属特征及因果发现的序列优化分类器链(sequence optimization classifier chain based on label-specific features and causal discovery, SOCC). 使用仿射传播聚类构建类属特征,并将类属特征引入分类器链;使用条件熵挖掘标签间因果关系以优化分类器链的标签顺序;在多个数据集上的实验结果表明有良好的分类能力.
1 相关工作
多标签数据通常具有高维度特征,这些特征并不是与每一个标签都相关. 每个标签都有对应的类属特征. 使用类属特征进行分类能够减少特征空间的冗余信息. 现有类属特征构造方法主要包括基于特征选择的方法和基于特征变换的方法. 基于特征选择的方法,其原理是从特征中选出每个标签的特征子集. 比如HUANG等[7]提出的LLSF方法,基于两个强相关标签比两个弱相关或不相关标签共享更多特征的假设,采用线性回归的方法得到每个标签的特征权重,确定每个标签的特征. HAN等[8]提出的LSF-CI方法,利用概率邻域图计算样本关联,利用余弦相似度计算标签相关性. 然后利用样本关联和标签关联对特征进行诱导,以选择更健壮的特征. 基于特征变换的方法,其原理是对原始特征进行变换,以得到标签的类属特征. 比如ZHANG等[9]提出LIFT方法,对于每个标签,考虑样本之间的关联,通过K-means聚类获得其正、负样本的中心. 然后,根据样本到聚类中心的欧氏距离对特征进行变换. ZHANG等[10]提出ML-DFL方法,该方法针对LIFT方法没有利用正负样本之间判别信息的问题,使用聚类方法利用正负样本之间的局部结构,通过查询聚类结果将原始特征转换为用于判别过程的特征. WENG等[11]提出LF-LPLC方法,为在LIFT的基础上利用标签相关性,在聚类前设置每个标签的聚类簇数相同. 完成特征构建后通过样本嵌入实现局部相关性的利用.
现有标签相关性利用的方法主要包括二阶方法和高阶方法. 二阶方法只考虑标签之间的成对相关性,不能反映更复杂的相关性,比如Rank-LSVM[12]和CML-kNN[13]等;高阶方法挖掘所有标签之间的相关性来解决多标签分类问题. READ等[14]提出的CC是重要的高阶方法之一,利用标签向量作为附加特征,按照随机顺序训练得到一个链式的多标签分类器. READ等[15]提出ECC方法,为缓解标签顺序随机对分类器链的不良影响,按照CC的方式生成多个分类器链,再利用集成方法整合所有分类器链的结果以获得最终分类. CHENG等[16]提出PCC方法,在训练阶段同样使用随机顺序. 对于测试阶段的每个样本,估计所有可能的标签组合的联合分布,并寻求最大化标签组合的后验概率. SILVA等[17]提出OOCC方法,按随机顺序建立若干分类器链,对于测试样本,在训练集中找到它的K近邻,并寻找在这些近邻样本中性能最佳的分类器链. 然后,将这个分类器链用于该测试样本的分类.
综上所述,现有分类器链方法的改进主要是减轻标签顺序随机对分类结果的不良影响,而不是通过优化学习顺序来提高分类效果;同时没有为基分类器构建类属特征,造成基分类器特征冗余. 针对以上问题,提出结合类属特征及因果发现的序列优化分类器链.
2 算法原理
2.1 原理框架
针对分类器链方法训练过程使用全部特征导致基分类器特征冗余的问题,通过仿射传播聚类为基分类器构建类属特征,对划分后的正负类样本,经过样本间的消息传递确定聚类中心,根据样本到聚类中心的距离实现特征构建;针对分类器链对标签间相关信息利用不充分的问题,利用条件熵挖掘标签间因果关系,确定标签顺序,并使用分类器链按顺序进行分类. SOCC方法的原理如图1所示.
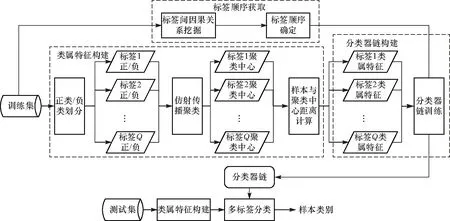
图1 SOCC原理图Fig.1 SOCC algorithm principle diagram
2.2 类属特征构建
在多标签分类问题中,使用D={(xi,yi)|1≤i≤N,xi∈X,yi⊆Y}代表由N个样本组成的训练集,其中(xi,yi)表示一个样本;xi为一个d维的向量,每一个元素代表一个特征;yi为一个Q维的向量,每一个元素代表一个标签,如果第i个样本属于标签lj,那么yij=+1,否则yij=-1.
针对标签lk,将训练集划分成正类Pk和负类Nk,
Pk={xi|(xi,yi)∈D,yik=+1}
(1)
Nk={xi|(xi,yi)∈D,yik=-1}
(2)
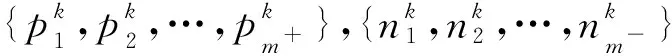
(3)
式中d(·,·)代表的是两者间的欧氏距离. 这一过程与LIFT算法中的类属特征构建相似,但是LIFT算法使用的是K-means聚类方法,K-means聚类本身是不稳定的,聚类结果受初始值和噪声影响大,并且K-means聚类需要人为地指定聚类簇个数,这会导致聚类中心发生偏移,影响类属特征的稳定. 为了解决这一问题,SOCC采用仿射传播聚类替代K-means聚类. 仿射传播聚类能在没有任何先验知识的情况下自动确定聚类簇个数,并且仿射传播聚类结果对初始值和噪声不敏感,弥补K-means聚类的缺陷.
2.3 标签顺序获取
分类器链可以看作是一种有向无环图(DAG),每个基分类器作为DAG中的一个节点[19]. 在DAG中,使用条件熵对标签间的因果关系进行挖掘以确定标签顺序.
H(Y1|Y2)=H(Y1)-I(Y1,Y2)
(4)
式中Y1、Y2分别代表训练集中l1、l2的取值向量,H(·)代表熵;I(·,·)代表互信息. 使用H(Y1|Y2)来衡量l1对l2的因果关系. 若H(Y1|Y2)为0,表示在已知l2的情况下l1能被完美的预测.H(Y1|Y2)越小,l2能为l1提供越多的信息,即l2和l1的因果关系越强. 依据这种关系来确定标签的训练顺序. 首先分别计算标签两两之间的条件熵,得到一个Q×Q的矩阵. 计算矩阵每一行的和,选择值最小的那一行,记录该行对应的标签i,并删除第i行以及第i列,剩下一个(Q-1)×(Q-1)的矩阵. 重复这个过程,直到所有标签都被记录为止. 标签顺序获取伪代码如下.
输入:Y={Yi,i=1,2,…,Q}
输出:Order
1.计算条件熵H(Yi|Yj),i,j∈[1,Q]
2.初始化剩余的标签集合L={1,2,…,Q}
3.初始化标签顺序Order={}
4. While |L|>0
5.对于L中的每一项计算sumH(i)=∑j∈L,j≠iH(Yj|Yi)
7.将i*加入Order中,并从L中删除i*
8. end
9. returnOrder
2.4 分类器链构建
SOCC选择SVM作为分类器链的基分类器,将经过仿射传播聚类构建的类属特征作为输入,按照依据条件熵获取的标签顺序构建分类器链CC={cci,i=1,2,…,|Q|}. 值得注意的是,在之前的分类器链方法中靠后的分类器的输入特征是由样本特征与前面所有分类器的输出组成的,这在各标签独立的假设上有详细地理论推导. 但是标签之间的相关性导致各标签不满足独立的假设,使用样本特征与前面所有的分类器的输出组成输入特征的方式会导致特征冗余. 所以使用余弦相关性对前面的分类器的输出进行筛选,将余弦相关性低于阈值t的从输入特征中剔除. 分类器链构建的伪代码如下.
输入:D={(φk(xi),yi)|1≤i≤N,xi∈X,yi⊆Y},Order
输出:CC
1.CC={}
2. forj∈Orderdo
3.D′j={}
4.y′={y1,y2,…yj-1}
5. forn∈[1,j-1] do
7.y′=y′-yn
8. end
9. end
10. for (φk(xi),yi)∈Ddo
13. end
14.训练模型ccj
15.CC=CC∪ccj
16. end
17. ReturnCC
3 实验分析
3.1 实验目的
为了验证SOCC算法在多标签分类问题上的分类效果,在5个有代表性的数据集上将SOCC算法与对比算法进行比较.
3.2 实验数据
数据集的详细信息如表 1所示,其中,|D|、dim(D)和L(D)分别代表样本数量、特征数量和标签数量.
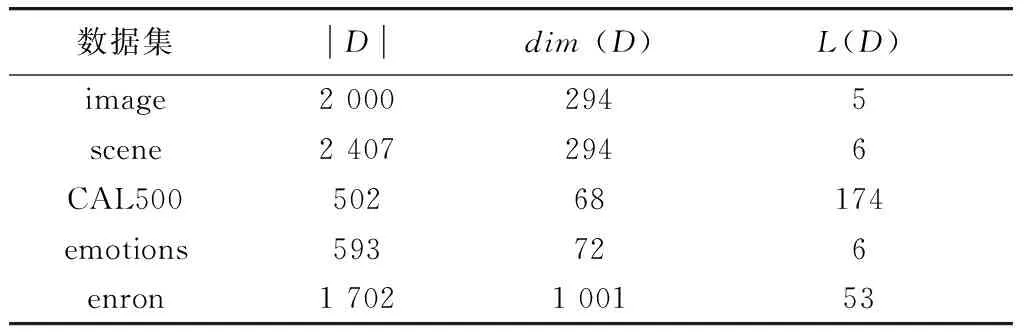
表1 数据集详细信息
3.3 对比算法
实验采用10次十折交叉方法,将SOCC同4种多标签分类方法进行比较,包括ECC[15](2011)、LIFT[9](2015)、LF-LPLC[11](2018)以及MLFE[20](2018)方法. 其中ECC、MLFE和LF-LPLC利用了标签相关性,LIFT、LF-LPLC利用了类属特征. SOCC同其他算法的对比如表2所示.

表2 Image数据集实验结果
ECC方法通过集成学习与分类器链结合的策略进行多标签分类,其中分类器链数量L设置为10. MLFE方法使用基于稀疏重构的特征空间结构丰富标签信息,其调和参数设置为β1={1,2,…,10},β2={1,10,15},β3={1,10}. LIFT方法将原始特征转换为类属特征以提升多标签分类效果,控制聚类簇数的参数r设为0.1. LF-LPLC方法在LIFT的基础上加入局部的标签相关性,其中近邻样本数k设为10. 另外,将SOCC、LF-LPLC、LIFT和ECC算法使用的SVM的核函数设置为Linear核.
3.4 评价指标
为评价SOCC以及对比算法的性能,选择5个广泛应用于多标签学习的评价指标[21]:汉明损失(Hamming loss)、排序损失(ranking loss)、1-错误率(one-error)、覆盖率(coverage)和平均精度(average precision).
汉明损失表示所有分类错误的标签占总标签数的比例,其定义为
(5)
式中:Δ表示对称差运算;h(xi)表示模型对xi标签的预测.
排序损失表示的是相关标签与无关标签对排序错误的比例,其定义为
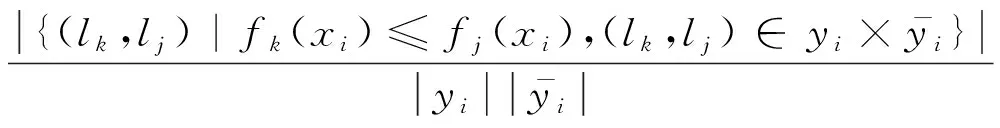
(6)
1-错误率计算模型预测样本最可能的标签与真实标签不符的个数,其定义为

(7)
覆盖率评估平均要在预测的标签序列中搜索多少标签才能够覆盖该样本所有真正属于的标签,其定义为
(8)
式中Trank代表排序操作,如果xi属于标签lk的概率越大,其排名越靠前,Trank(xi,lk)值越小.
平均精度评估在一个给定标签,有多少实际包含标签的Trank在其之前,即预测标签的平均精度,其定义为
(9)
除平均精度的值越大越好外,其余4个指标的值越小越好.
3.5 实验结果
SOCC与对比算法在5个数据集上的性能评价结果如表2~表6所示,其中,Rank表示算法在各个评价指标上的平均排名,以此反应算法的综合性能. 从结果中可以看出,在image、scene和emotions数据集上,SOCC在汉明损失、排序损失、1-错误率、覆盖率和平均精度5个指标上均优于对比算法;而针对CAL500数据集,其标签相关性信息相较特征信息更为丰富,因此SOCC在1-错误率指标的表现略弱于着重利用标签相关性信息的ECC方法;对于enron数据集,SOCC方法在平均精度指标的表现则略弱于对稀疏的文本数据适应性更好的MLFE方法. 为了更清楚地说明SOCC的效果,图2展示了各算法在所有数据集上Trank的平均值,其中Trank值越低表示该算法性能越好. 由此可知,SOCC的综合表现优于对比算法,表现出了良好的多标签分类性能.

表3 Scene数据集实验结果
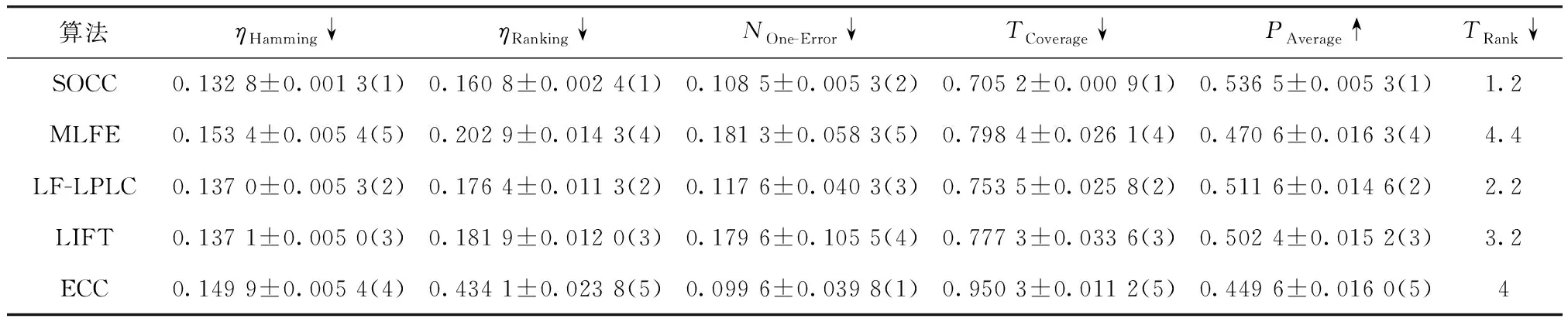
表4 CAL500数据集实验结果
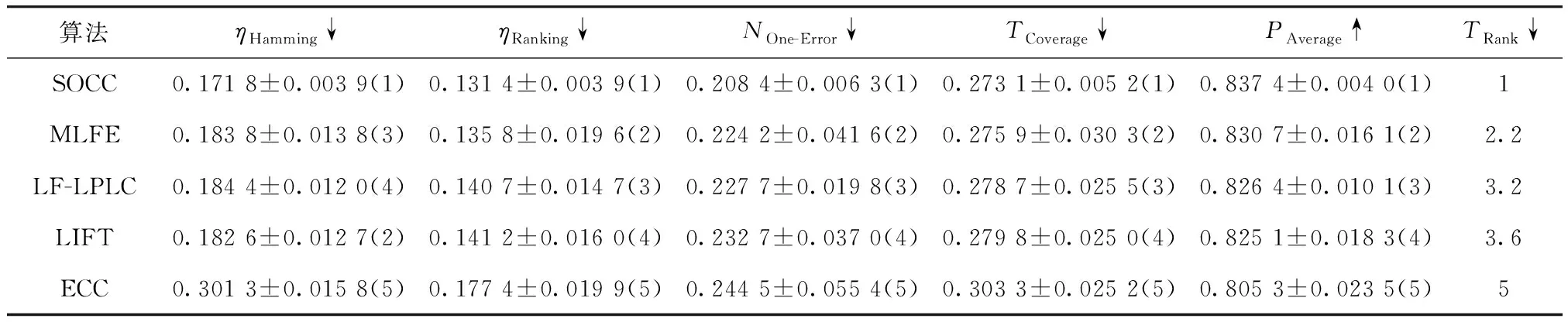
表5 Emotions数据集实验结果
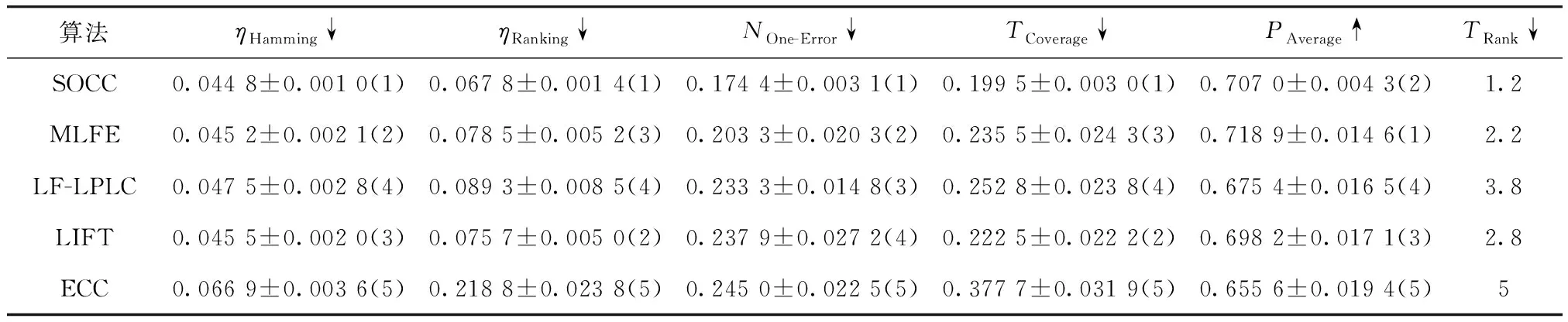
表6 enron实验结果
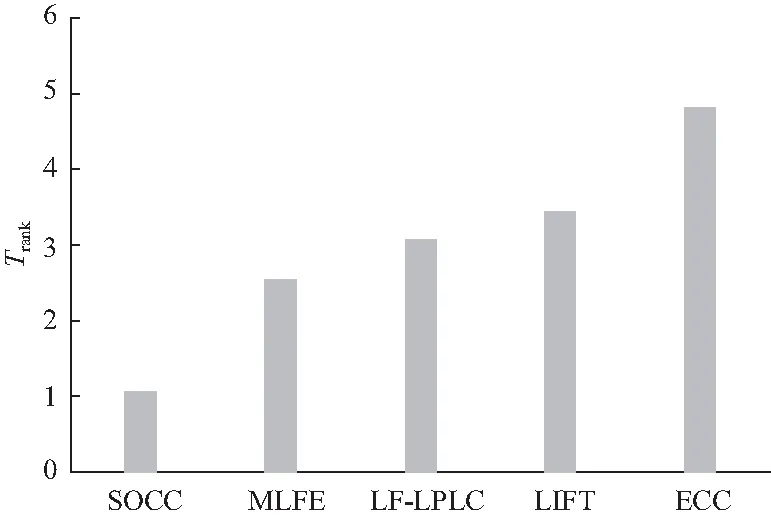
图2 各算法的Rank平均值Fig.2 Average rank of each algorithm
4 结 论
提出结合类属特征及因果发现的序列优化分类器链(SOCC). 该方法首先使用仿射传播聚类,根据样本到各聚类中心的距离为每个基分类器构建类属特征;然后通过条件熵挖掘标签间因果关系,确定标签顺序;最后使用分类器链依标签顺序进行分类. 为了评估该方法在多标签分类问题上分类效果,将SOCC同LF-LPLC、LIFT、MLFE等多标签分类方法在多个领域的数据集进行对比实验,依据汉明损失、排序损失、1-错误率、覆盖率和平均精度5个指标进行评价,结果表明,SOCC能够有效提高分类效果,具有较高的实用价值.
研究未来将继续关注于提升SOCC对稀疏特征的利用与重构,提高其在文本分类等任务上的应用效果,同时尝试通过考虑标签的局部相关性,以进一步提升其多分类性能.
