基于近红外光谱快速预测石脑油单体烃分子组成
2022-01-12刘秋芳褚小立李敬岩
刘秋芳,褚小立,陈 瀑,李敬岩
(中国石化石油化工科学研究院,北京 100083)
炼油过程与原料油的性质息息相关,而原料油的性质是由其组成分子性质决定的,因而从分子水平上认识原料油的组成和性质,深入研究炼油过程的分子化学反应,有利于原料油加工路线的优化。
石脑油是蒸汽裂解制乙烯装置[1-3]和催化重整装置[4-5]的主要原料之一。色谱分析是石脑油分子组成表征最直接、最准确的方法[6-8],通过色谱分析可以定性、定量地表征出上百个单体烃分子[4-5,9-10];但色谱分析周期较长,且需要专业人员操作,很难满足炼油厂优化控制效率的需求。而近红外光谱(NIR)分析方法因具有分析快、成本低、样品不需前处理、适于在线分析等优点而越来越受到重视。
随着化学计量学的应用和计算机的快速发展,NIR与化学计量学相结合的方法可以很好地测定石脑油的族组成(PINA)[2,4-5,10-14]。Chung等[4]采用偏最小二乘(PLS)方法建立了NIR校准模型预测石脑油的详细族组成,预测结果与气相色谱法(GC)分析结果的相关性较好;而且,其进一步探讨了特征区间的选择对模型准确性的影响,优选的特征区间分别为1 100~1 650 nm、1 800~2 100 nm及其合并区间。Lambert等[15]将NIR与多元校正PLS结合建立了TOPNIR在线分析模型,用以优化石脑油蒸汽裂解工艺,发现其优化结果与GC分析结果一致,可以应用于工厂在线远程控制。
针对模型构建优化过程中数据样本少、分布不均匀、代表性差等小样本问题,解决的方法主要有机器学习(Machine Learning)、灰色理论(Grey Theory)、特征提取(Feature Extraction)和虚拟样本生成(VSG)等。其中,VSG方法是在已知样本的基础上通过一定转换关系产生新的虚拟样本,然后加入到原有样本中的过程[16-17]。目前,常用的VSG方法有插值法、噪声注入法、数据采样法、样本增强(DA)法等,其中DA法是将插值法与噪声注入法相结合的方法。采用DA法引入未观测数据或潜在变量,可以构建更准确、适用范围更广的模型,有利于提高模型的分类能力和通用性,克服小样本问题,而且PLS模型的预测误差更小[18-21]。
基于上述分析,本研究提出一种基于近红外光谱快速测定石脑油分子水平组成的方法,以近红外光谱分析结果作为输入项,通过构建石脑油的单体烃分布比例库,并采用DA法解决小样本问题,建立石脑油PINA值和单体烃分布比例预测模型,对石脑油的单体烃分布进行预测。
1 实 验
1.1 样本和数据收集
直馏石脑油样本(馏程为15~180 ℃),由中国石化石油化工科学研究院(简称石科院)分析实验室油品常压蒸馏装置收集,共50个。收集周期为6个月,为防止样本中轻组分挥发,样本保存在4 ℃的冰箱内。样本的PINA组成(w,%)和单体烃含量(w,%)按照《石脑油单体烃组成测定(毛细管气相色谱法)》(SH/T 0714—2002)方法分析获得。
石脑油样本的近红外光谱利用Thermo Fisher Antaris Ⅱ傅里叶变换近红外分析仪表征,采集波数为3 500~10 000 cm-1,分辨率为8 cm-1,扫描128次。
1.2 预测方法
针对石脑油的分子水平组成,提出一种预测方法:①以石脑油PINOA(P,I,N,O,A分别为正构烷烃、异构烷烃、环烷烃、烯烃、芳烃)组成和单体烃含量的GC分析结果为基础,建立石脑油单体烃分布比例库,包括石脑油NIR和单体烃分布比例;②采用DA法生成大量虚拟样本,并与实际样本混合;③以混合样本的近红外导数光谱在特征区间内的吸光度为输入变量、以样本的PINA组成为输出变量,采用偏最小二乘法(PLS)算法建立PINA组成预测模型;④以混合样本NIR的吸光度为输入变量、以单体烃分布比例为输出变量,采用K-近邻回归法(KNR)建立石脑油单体烃分布比例预测模型。
在对待测样本进行单体烃分布预测时,首先测定该样本的NIR;然后利用上述两个预测模型,分别得到待测样本的PINA组成和单体烃的分布比例;最后将PINA组成与相应单体烃分布比例相乘,即得到该样本的单体烃分布结果。
1.3 模型的建立
1.3.1 虚拟样本生成
采用Spxy算法将50个实验室样本分为校正集和预测集。校正集样本用于模型建立,预测集样本用于检验模型预测的准确度。对于PINA组成预测模型,校正集样本40个、预测集样本10个;对于单体烃分布比例模型,校正集样本44个、预测集样本6个。
在实验室样本的基础上,采用样本增强方法,对实际样本信息进行一定范围的扩散,生成虚拟样本。其中,注入的噪声使用重复性光谱的差谱;插值法为样本间随机插值并乘以扩散系数方法,扩散系数设为1.2。
生成虚拟样本时,先采用样本增强方法生成虚拟样本的近红外光谱,然后通过相同的插值方式生成虚拟样本的PINA组成和单体烃分布比例。具体生成步骤:在预测集选取某个样本作为待测样本,近红外光谱范围内,根据待测样本与校正集中所有样本之间的欧氏距离寻找5个距离最近的样本为相似样本;在5个相似样本中任意选取2个样本,进行线性组合并乘以一定的扩散系数生成虚拟样本,共生成虚拟样本250个;然后在5个相似样本和其余样本中各自随机选取 1 个样本,进行线性组合并乘以扩散系数生成虚拟样本,共生成虚拟样本250个。总计共生成500个虚拟样本。
1.3.2 偏最小二乘(PLS)模型的建立
建立模型过程中,首先将采集的校正集样本与样本增强生成的虚拟样本混合,形成混合校正样本集;同时采用2017版Matlab处理光谱数据,对混合样本集的NIR进行二阶差分求导,得到其导数光谱;然后基于混合样本的导数光谱和PINA值,采用PLS算法建立模型;最后采用内部留一交叉验证法,得到最小校正标准偏差(RMSECV);并用RMSECV评估模型不同主因子数(一般为1,2,…,30)的建模效果,确定模型最佳主因子数。
针对石脑油不同PINA族组成,共构建了32个PINA值的预测模型,分别命名为P3~P12,I4~I12,N5~N12,A6~A11模型,如N6表示碳数为6的环烷烃组成模型,A6为碳数为6的芳烃组成模型。
由于样本的NIR特征区间对PLS建模的准确性至关重要[4,22],图1给出了实际校正集样本的NIR及其在特征区间内的近红外导数光谱。由图1可知,石脑油单体烃分子中C—H键(甲基、亚甲基、芳环)的光谱特征区间为5 600~6 100 cm-1和4 000~4 800 cm-1。

图1 样本的NIR及其在特征区间内的近红外导数光谱
1.3.3 单体烃分布比例模型的构建
石脑油单体烃分布比例模型包括石脑油的NIR和单体烃分布比例,石脑油中共有234种单体烃分子。将石脑油样本的NIR按照相同波数的吸光度和样本一一对应整理成矩阵,矩阵的行表示不同样本同一波数的NIR吸光度,矩阵的列表示同一样本的NIR;将单体烃含量按分子类型和样本一一对应整理成矩阵,矩阵的行表示不同样本同一分子的分布比例,矩阵的列表示同一样本的所有单体烃分布比例。因此NIR矩阵的列、单体烃分布比例矩阵的列均与样本一一对应。单体烃分布比例的计算如式(1)所示。
(1)
式中:zi为石脑油中某单体烃的分布比例;xi为某单体烃的质量分数;yi为某单体烃对应其所属PINA族的质量分数。
对于待测样本单体烃分布比例的预测,采用样本增强方法生成的混合样本,然后将待测样本的NIR作为输入变量,采用K-近邻回归法(KNR)建立线性拟合预测模型。KNR是通过比较待测样本与所有样本之间的欧氏距离,选取k个邻近样本进行回归判别。
2 结果与讨论
2.1 样本PINA组成预测
主成分分析是一种统计学方法,通过正交变换可将相关度较高的变量转变为无关的变量来表示。该方法尽可能保持了原来变量的信息,并对变量进行降维,减少了计算量。本研究中,在预测集中任选1个样本作为待测样本,对待测样本、实际校正集样本和样本增强后混合校正集样本的NIR进行主成分分析,观察实际样本、虚拟样本相对于待测样本的位置关系,结果见图2和图3。由图2和图3可以看出:实际样本与待测样本间的差异性较大,以实际样本来预测待测样本,准确性较差;而样本增强后的虚拟样本,在一定范围内大幅增加了待测样本周围训练样本的密度,甚至完全覆盖了待测样本,二者之间的欧氏距离很小。待测样本周围的样本越多,越易找到相似样本,预测的准确度越高。

图2 样本增强前实际样本的NIR主成分分析
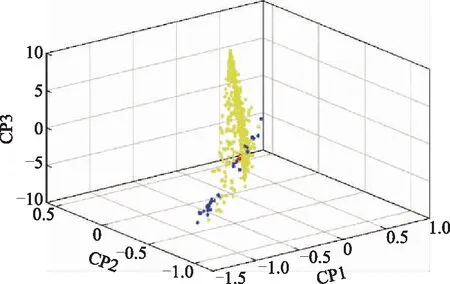
图3 样本增强后混合样本的NIR主成分分析
基于混合校正样本集,对采用PLS算法建立的模型进行优化训练,选取最佳主因子数,并用预测集样本对模型预测效果进行检验,计算模型的预测标准偏差(RMSEP)和相关系数(R)。RMSEP越小、R越接近于1,说明预测的效果越好。样本增强前后构建的PLS模型的预测结果如表1所示。从表1可知:与样本增强前相比,多数样本增强后PLS模型的预测准确度提高,RMSEP减小,R均增大,更接近1;但是,对于单体烃P3,P4,P12,I4,I12,A11,其分布PLS预测模型的校正结果均不理想。这主要是因为:①收集的石脑油样本P3的质量分数范围为0~0.12,P12的质量分数范围为0~0.02,I12的质量分数范围为0~0.15,A11的质量分数范围为0~0.014,含量较少且部分样本检测到质量分数为0,在GC检测限以下,尤其是P3、P12。②由于P3,P4,I4具有一定的挥发性,在进行样品收集、近红外和气相色谱检测时挥发了一部分。综合来看,样本增强方法对基于小样本构建的PLS模型的预测准确度有一定的提高作用,32个PINA组成预测模型中,有26个模型的RMSEP减小,R更接近1。

表1 样本增强前后PLS模型的预测结果
因构建的PINA组成预测模型很多(32个),无法一一说明,因而随机选择3个模型说明其预测结果。图4~图6为样本增强前后所建立的PLS模型对P5,I8,A8的预测值与其GC测定值的对比。由图4~图6可知,采用PLS算法所建PINA组成模型P5,I8,A8的预测值与GC测定值基本一致,说明所建PINA组成模型的预测结果具有较高的准确性。

图4 样本增强前后石脑油P5组分的GC测定值和模型预测值
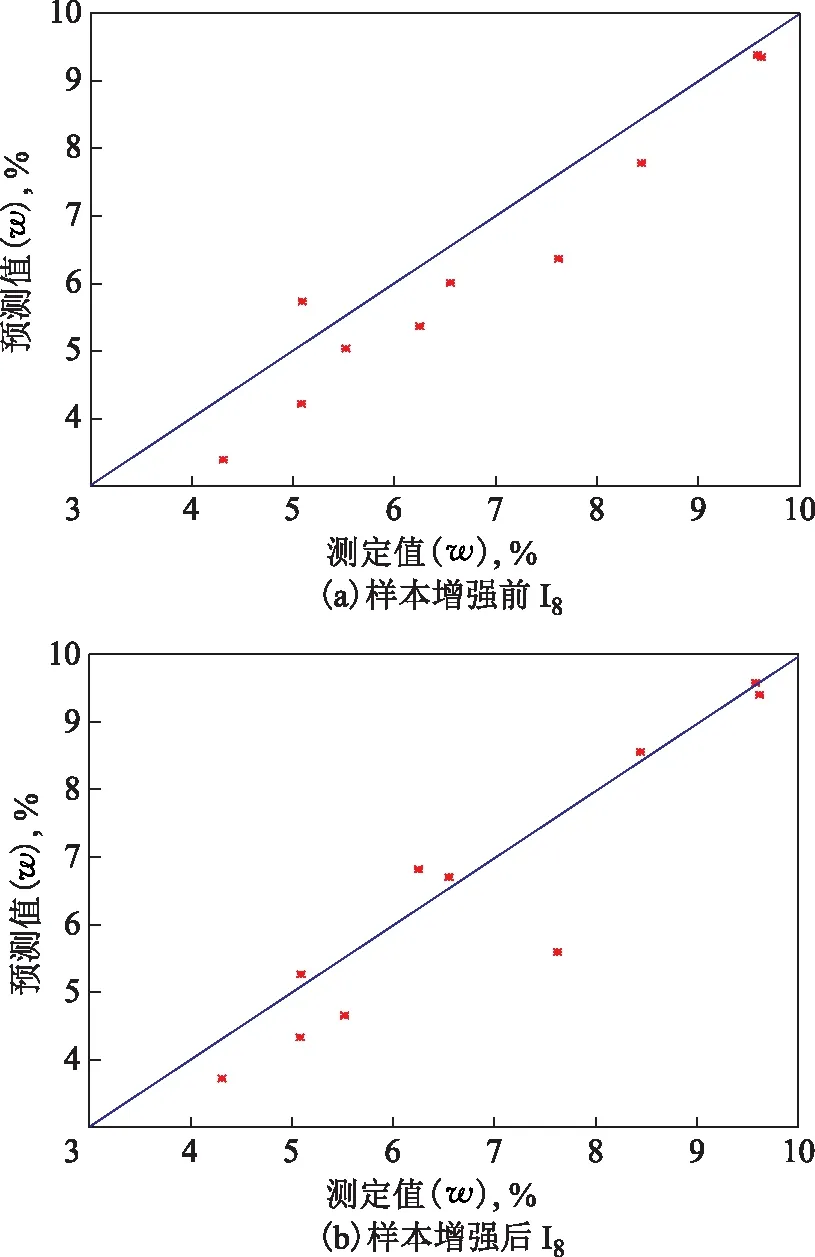
图5 样本增强前后石脑油I8组分的GC测定值和模型预测值

图6 样本增强前后石脑油A8组分的GC测定值和模型预测值
2.2 单体烃分布比例的预测
采用KNR线性拟合预测模型对于待测样本的单体烃分布比例进行预测,预测的关键是确定近邻样本的数量(k)。模拟过程中,通过计算预测集中6个样本预测值与实际值的RMSEP来确定k。样本增强后KNR方法中k与RMSEP的关系见图7。由图7可知,当k=2时,RMSEP最小,因此k的最佳取值为2。

图7 样本增强后KNR模型k与预测集样本预测RMSEP的关系
6个预测集样本单体烃分子比例的KNR预测结果见表2。由表2可知,每个样本单体烃分布比例的预测值与气相色谱测定值的R均在0.91以上,接近于1,且其RMSEP均在0.1以下,说明采用KNR模型预测单体烃样本分子分布比例的效果很好。

表2 预测集样本的模型预测结果
图8~图13分别为预测集样本1~样本6单体烃分布比例的模型预测值与气相色谱测定值的拟合结果。由图8~图13可以观察到,预测集样本的单体烃分布比例的GC测定值和KNR预测值基本吻合。由表2和图8~图13可以看出,在构建石脑油单体烃分布比例数据库的基础上,利用样本增强方法与K-近邻回归法预测未知石脑油单体烃分布比例,具有较好的准确性。

图8 预测集样本1单体烃分布比例的预测值与测定值

图9 预测集样本2单体烃分布比例的预测值与测定值

图10 预测集样本3单体烃分布比例的预测值与测定值

图11 预测集样本4单体烃分布比例的预测值与测定值

图12 预测集样本5单体烃分布比例的预测值与测定值

图13 预测集样本6单体烃分布比例的预测值与测定值
3 结 论
提出了一种基于近红外光谱预测石脑油分子水平组分的方法。该方法以气相色谱法测定的石脑油PINA数据和单体烃含量为基础,通过构建石脑油单体烃分布比例库、建立石脑油PINA组成预测模型,石脑油单体烃分布比例预测模型,成功实现对未知石脑油样本进行单体烃组成进行定性、定量分析。
此外,采用样本增强方法很好地解决了建模过程的小样本问题,扩充了样本量。预测结果表明:所建的模型的预测值与GC实测值吻合度高,预测准确性好。
