PEC-V: 基于RISC-V协处理器的内存溢出防御机制①
2022-01-06张雨昕芮志清李威威罗天悦吴敬征
张雨昕, 芮志清, 李威威, 张 画,4, 罗天悦, 吴敬征
1(中国科学院 软件研究所 智能软件研究中心, 北京 100190)
2(伊利诺伊大学香槟分校 The Grainger College of Engineering, Urbana-Champaign 61820)
3(中国科学院 软件研究所 PLCT实验室, 北京 100190)
4(北京航空航天大学 高等理工学院, 北京 100191)
1 引言
缓冲区溢出攻击是计算机系统安全领域的重要攻击手段之一.攻击者通过对未做边界检查的缓冲区写入恶意数据, 达到控制程序甚至获取整个系统操作特权的目的.然而因为以C语言为代表的被广泛使用的编程语言并不具有强制进行缓冲区边界检查的功能,所以众多使用此类语言的系统中存在着诸多溢出漏洞易被攻击者利用.如今, 每年此类漏洞被检测到的数量在各类关于计算机安全的漏洞依旧中占据前列[1].虽然随着技术的进步与发展, 操作系统、应用软件和硬件层面都发展出许多预防此类攻击的安全机制, 例如内存地址空间随机化(ASLR)[2], StackGuard[3], 数据不可执行(DEP)[4]等.与此同时, 攻击的方式也随之复杂, 发展出各类变种, 例如Return-to-libc Attack (Ret2libc)和Sigreturn Oriented Programming (SOP)等[5,6], 以此绕过各类安全机制.
指针加密是一种通过保护指令地址的溢出攻击预防机制.溢出攻击的主要原理是注入恶意数据, 修改指令寄存器指向的地址使控制流跳转到攻击者构造的代码中, 最终劫持程序或者获取更高的系统权限.而指针加密的主要机制是将程序返回地址和函数指针等重要数据加密后再存储在内存中, 而在需要将此类数据加载到指令寄存器中时再解密使指令寄存器指向正确的目的地址.通过此种方法, 指令的地址被加密隐藏, 即使攻击者通过各种方式改变了指令寄存器中的值, 也无法预测指令指针实际指向的位置, 更无法使指针指向恶意构造的代码处.因此这一安全预防机制可以有效阻止各类溢出攻击.
PointGuard是一种通过软件手段实现指针加密机制的技术[7], 此机制将密钥存储在内存中某一区域, 在加解密时取出密钥值将其与指针的值做异或运算.但是, 此方式在加解密时均需要访问内存, 会增加时间开销以及内存占用的空间开销.而且对于能够读取数据的攻击, 易泄露加密键值从而导致预防机制失效.针对这些问题, 本文提出基于RISC-V自定义指令设计的指针加密协处理器PEC-V (Pointer Enryption Coprocessor on RISC-V), 通过硬件手段实现这一机制.
RISC-V作为一个新型开源指令集架构, 同样易受到缓冲区溢出攻击.Jaloyan等在论文中阐明了此类攻击在RISC-V架构上的可行性, 并利用内核中的代码片段成功实现了ROP (Return Oriented Programming)攻击并绕过多种安全防御机制[5].因此, 针对RISC-V的安全性研究十分必要.
RISC-V具有的显著特性之一便是开放的可扩展性, RocketChip是一款基于RISC-V的SoC (Systemon-a-Chip)生成器, 它基于RISC-V预留的自定义指令设计的RoCC (Rocket Custom Coprocessor)接口可以方便的扩展协处理器.而协处理器PEC-V的内部设计主要通过使用PUF (Physical Unclonable Function)[8]加解密数据.PUF对不同激励输入做出唯一且随机的响应, 但对于同样的输入总是输出固定值.因此本文将被加密数据地址作为激励输入, 将PUF响应作为密钥加密数据以此减少访问内存的时间开销, 减少内存占用, 同时保障了安全性.
2 背景
此节主要介绍针对溢出攻击的其他安全预防机制和这些机制存在的问题, 以及介绍RISC-V自定义指令和RoCC接口的细节和选择这一架构的原因.
2.1 预防缓冲区溢出攻击的机制介绍
目前, 针对缓冲区溢出攻击的研究十分广泛, 研究者们提出了许多预防机制.首先, ASLR[2]和DEP[4]便是两种已经被广泛使用的预防机制.其中, ASLR机制在加载程序地址空间时, 通过在栈、堆、代码区和动态链接库等内存段的起始地址前加入一段随机偏移量达到地址随机化的目的.此种方法可以加大攻击者定位漏洞跳转到目的地址的难度.而DEP机制是在内存页添加额外标识字节表示此页是否可执行, 通过操作系统的控制区分内存为可执行段和不可执行段, 因此写在缓冲区中被攻击者恶意注入的代码将不再可以被执行, 从而阻止攻击.然而面对更加具有针对性和复杂的攻击手段, 这两种预防机制变得十分有限.对于ASLR机制, 攻击者通过在注入代码中添加nop指令的方式使程序控制流最终仍能被攻击者掌握.并且在32位的系统架构上, ASLR存在内存地址空间小的时候随机化不足的问题[9].而对于DEP机制, 攻击者可以利用动态链接库或者程序中已经存在的代码片段构造栈中的返回地址和数据实现Ret2libc攻击[10].
而后Stack Canary[3]作为一种更加有效的预防机制被提出, 并被实际应用.Stack Canary可以通过将NULL值插在缓冲区的末尾, 以此识别缓冲区中数据是否越界, 当发现NULL值被覆盖时说明缓冲区溢出,则立刻终止程序.然而如果使用NULL值插在缓冲区末尾, 会有一些系统函数允许写入NULL值导致溢出攻击依旧可行.此问题的一个解决方式是使用随机数代替NULL值.然而如果使用随机数, 那么此数值需要对攻击者保密, 如果使用软件实现此机制, 随机数的种子值需要存储在TCB中, 而这将成为一个易受攻击的薄弱环节.De等[11]在论文中使用PUF在RISC-V架构上设计了一个Canary Engine.然而此种硬件实现方式依旧不能避免一些攻击.Stack Canary机制只能检测到改变了缓冲区和返回地址之间所有数据的攻击, 对于通过指针直接覆盖返回值的攻击, Stack Canary无法避免, 例如printf格式化字符串溢出等.此外, 对于堆上的溢出攻击, Stack Canary同样无法阻止[12].
近年来另一种防御机制控制流完整性(CFI)[13]逐渐成为研究的主流, 针对此方面的研究主要分为粗粒度控制流完整性[14]和细粒度控制流完整性[15].这些机制在编译阶段构建程序的控制流图并通过某种方案在程序执行时使其只能按照流图中的边跳转.然而这些方案大部分并未投入实际使用, 它们依旧各自存在一定的问题.由于静态分析并不能完全确定程序的控制流图, 例如函数指针指向的函数无法在编译阶段确定, 因此粗粒度的控制流完整性方案无法精准定位程序跳转的位置, 这导致此机制依旧存在漏洞可被攻击者利用,而细粒度方案则会增添大量空间和时间的开销[16,17].
类似于CFI机制, 指针加密也通过保护程序控制流达到阻止攻击的目的.Cowan等[7]提出的PointGuard技术便是通过加解密指针的方式阻止溢出攻击.此技术为了保障加密密钥的随机性, 每当开启一个新进程时都需要重置此密钥(REF), 而此值将被存在进程的TCB中.因此TCB可能会成为整个系统中易受攻击的环节, 对于有可能存在数据泄露或者存在可以修改TCB值的漏洞的程序, 攻击者可以破解或绕过此机制.此外由于每一次加解密返回地址或者其他可改变指令寄存器值的数据时, PointGuard都需要从内存中取出密钥的值, 将其与返回地址或者函数指针执行异或运算[18].从以上描述中可以看出在存储和使用此类数据时, Point-Guard都需要额外增添1条访存指令, 这将影响到程序的运行效率.综上, 本文受Canary Engine[11]的启发, 提出基于RISC-V自定义指令设计的指针加密协处理器PEC-V, 通过硬件手段实现这一机制, 可在增强安全性的同时有效解决运行效率低的问题.
2.2 RISC-V自定义指令和RoCC接口介绍
RISC-V预留了众多未被定义的编码空间[19], 其中,为了便于非标准化的扩展, RISC-V预留了4种自定义指令custom0/1/2/3, 使用者可以将这4种指令扩展成为协处理器的控制指令.RocketChip是一个开源的RISC-V的SoC生成器.RocketChip的代码实现了RoCC接口, 此接口支持custom0/1/2/3指令, 可用于连接用户自定义的协处理器[20].
ROCC接口支持的custom指令的格式和字段如图1所示, 其中rd字段为目的寄存器, rs1和rs2为源寄存器, xs1和xs2表示协处理器是否读取源寄存器中的值, xd表示是否写回目的寄存器, opcode为custom指令的操作码, funct7的值可由用户自行扩展以控制协处理器完成不同操作.本文使用custom0指令, 编码funct7字段使custom0扩展成为4条不同的协处理器控制指令.

图1 自定义指令格式
RoCC接口的架构[21]如图2所示, 其中cmd是散开的接口, 包括两个源寄存器的值和输入指令, 主处理器通过cmd将命令和数据传入协处理器中; resp将协处理器中的值传递回cmd中rd字段指明的目的寄存器中; mem.req和mem.resp分别用于协处理器发送内存读写请求和主处理器返回请求结果; busy表示协处理器是否能继续接收指令, busy值为真时表明协处理器处于堵塞状态.
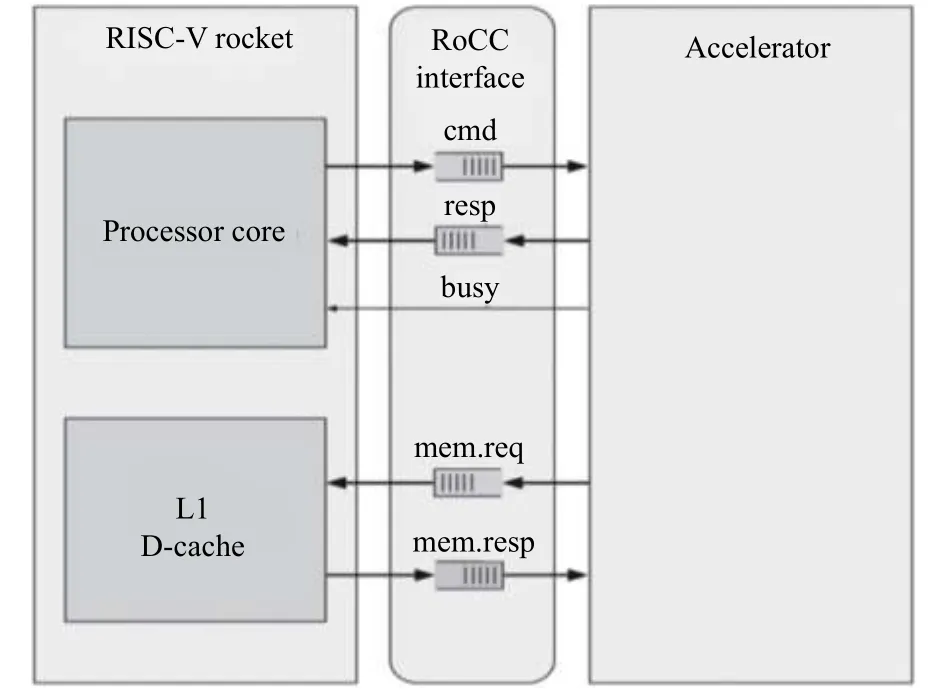
图2 RoCC接口架构细节
从上文介绍中可以看出, RISC-V指令集可扩展的特性以及RocketChip已经实现的RoCC接口可以允许本研究方便地接入自定义的协处理器, 实现指针加密的机制.因此本文选择使用此指令架构和接口设计和运行试验.
3 PEC-V的内部设计和指针加密实现机制
3.1 PEC-V内部构造
本文设计的用于指针加密的协处理器内部构造如图3所示.其中, PUF是一种硬件结构, 其利用硬件某些方面不可预测的随机性, 对某一输入可产生固定的随机响应.一个输入和对应的响应被定义为一个Challenge-Response-Pair (CRP), PUF依据CRPs数量的多少被分为强PUF和弱PUF, 其中, 强PUF的CRPs数量可以达到指数级[8], 足以满足指针加密的需要.同时PUF成本低, 面积小, 耗能低, 且能一定程度上预防常见的对loT的侧信道攻击[22].本文中使用的PUF为SRAM-PUF.图中, 每当rs1传入输入时, PUF产生唯一对应的随机响应并传到异或门中.

图3 PEC-V的电路逻辑图
TRNG是真随机数发生器, 它利用机器产生的噪声例如热力学噪声、光电效应和量子现象等产生真正的随机数.图中的TRNG在产生随机数后将其传入secret register中保存.
3.2 自定义指令
本文对RISC-V自定义指令custom0的funct7字段进行编码, 在custom0的基础上扩展了4条协处理器控制指令.协处理器中的译码器通过funct7字段的不同识别不同的指令.4条指令如表1所示.

表1 增添的自定义指令
指令1无输入和输出, 它的作用是命令协处理器中的TRNG产生1个真随机数并将值保存到secret register中.每当建立1个新进程的时候, 操作系统都会发送指令1到协处理器, 这样每一个进程初始化后都会获得一个真随机数值.
指令2的作用是将协处理器secret register中存储的值取出存入rd字段指定的寄存器中.每当CPU进行上下文切换将正在运行的进程切换出去的时候, 操作系统负责发送指令2到协处理器中取出此进程的随机数值并存入其PCB中.
指令3的作用是将rs1字段中指定的寄存器中的值传入协处理器的secret register中, 当CPU将某一进程切换进入的时候, 操作系统负责将PCB中存储的随机数值装载到常寄存器中并且发送指令3到协处理器,协处理器再将随机值存入secret register中.
指令4是唯一由用户进程使用的指令, 其作用是将rs1中的值作为输入传入PUF中, PUF产生的响应与secret register中的值进行异或后再与rs2中的值进行异或, 最后传入rd中.对于进程中的返回地址, 函数指针等需要加密的数据, 进程负责将需要加密的数据以及数据的存储地址分别传入rs1和rs2中并且发送指令4给协处理器, 等到协处理器返回值存入rd, 进程再将加密后的数据存入内存.而当进程需要使用此加密数据时, 同样将数据和地址存入rs1和rs2中, 发送指令4到协处理器, 余下过程与加密相同, 最后rd寄存器中即为解密后的数据.
通过上述的机制, 对于每一个进程都有唯一的真随机值, 这样不同的进程中即使是相同地址的数据, 加密后的密文将不会相同, 而对于同一进程, 在同一虚拟地址空间的数据, 由于地址不同, 地址作为PUF的输入得到的固定的随机响应也不相同, 所以PUF起到了在同一虚拟内存地址空间中随机化的目的.综上, 此设计指针加密的键值的随机性更高, 所以此机制的安全性具有足够的保障.
3.3 汇编指令的修改
在RISC-V指令集增加自定义指令后, 为达到指针加密的目标, 还需在程序中插入自定义汇编指令.本文首先将程序编译为汇编程序, 接着使用程序扫描编译后的汇编指令, 识别以下4处需要对指令做出修改的地方, 分别为: 函数指针赋值前, 函数指针解引用前, 被调用过程保存返回地址前和被调用过程返回之前.之后自动在此些位置插入计算地址的指令和指令4进行加解密, 修改后的汇编指令再转换为二进制文件执行.除了此插入方法之外, 还可通过使用Clang/LLVM编译器实现插入指令方式的方案.首先将程序编译为LLVM的中间代码, 增加pass插入加解密的指令, 最后转换为可执行文件.相对于本文的方法, 修改编译器的方案更为完善, 但为快速验证PEC-V的安全性, 本文未采取复杂的修改编译器的方案.
对于程序需要做的具体的改变本文通过图4中简单的示例程序进行说明.
图4(a)中的程序是使用函数指针的一个简单示例, 图4(b)中是针对返回地址加密的简单示例.首先将程序编译成中间指令, 扫描定位到程序赋值和使用函数指针的位置以及调用过程时返回地址压栈以及出栈的位置, 接下来在这些位置插入需要的汇编指令进行加密和解密操作.图中黑色方框中的汇编指令即为后期添加的加密和解密操作, custom_rd_rs1_r2即为新增的指令4.

图4 对函数指针和返回地址的处理
对于函数指针, 在地址存入指针之前, 先将指针的地址通过指令addi a4,s0, -24放入常用寄存器a4中,a5中本身存着函数指针的值, 接着a4、a5作为指令4中的rs1、rs2传入协处理器中, 协处理器进行加密后的返回值返回到a5, 接着a5中加密后的值被存入指针中.而当程序需要使用函数指针时, 同样将指针的值和指针的地址传入协处理器进行解密.
而针对返回地址,ra寄存器中存储的是返回地址,图中jalra, offset指令执行的过程是:
ra = pc + 2, pc = pc + offset;
所以, 被调用函数保存返回地址之前, 通过add a4,s0, -56获得返回地址存在栈上的位置, 将ra和a4中的值都传入协处理器获得加密的地址.当被调用函数返回时, 在返回地址出栈后, 插入同样指令进行解密.
从以上的例子中可以看出此机制的设计不会增加额外的内存访问, 因此减少了对程序运行效率的影响.而从安全方面来看, 对于一个程序p1中一个需要加密的数据d1, 它的密文是同时和TRNG产生的真随机数rp1和PUF对其地址a1产生的响应sa1异或的结果, 即密文m1=d1⊕rp1⊕sa1.所以一个程序中的某个需要加密的数据的键值将由rp1和sa1共同决定, 这在PointGuard的基础上更增添了安全性.而当攻击者试图修改地址执行恶意代码时, 如果通过穷举的方式, 对于64位系统将有264种可能的加密键值.当遭受溢出攻击, 程序指令寄存器的值被修改后, 虽然程序不会识别到值已经被改变, 但是解密后的地址会跳转到任意位置并造成程序崩溃, 阻止了攻击者试图控制程序的意图.
3.4 总结
根据以上的原理介绍可以看出, 此机制主要防御的攻击模式是, 利用缓冲区溢出改变指令寄存器指向的代码, 跳转注入代码或者库中以ret指令结尾的gadgets, 最终实现攻击者想要的操作.此机制实现安全性的前提是攻击者无法访问只有特权级进程才能控制的PCB区域, 无法获取PCB中存储的进程唯一的真随机键值.在此前提下即使攻击者可在同一机器上运行自己的程序, 读取加密键值, 也无法从此数据中获取任何其他进程加密键值的信息, 而对于攻击者试图攻击的进程, 即使有几处内存位置的加密键值被读溢出漏洞所暴露, 其他位置的加密键值仍然无法被攻击者获取.由于一般攻击都需要多处的代码段链接在一起执行, 因此, 攻击者能成功的概率将大大降低.而如果通过暴力破解的方式, 需要的次数取决于PUF产生响应的字节数, 对于可产生32位响应的PUF, 破解需要的时间将是指数级的.
4 实验与分析
本研究使用Chisel电路语言[23]实现了PEC-V的逻辑电路, 接入RocketChip的RoCC接口, 接着使用RocketChip已实现的Cycle-accurate C++ Emulator进行实验.实验的主要目的有二:
(1) 验证此机制的安全性.
(2) 测试此机制对程序运行效率的影响.
4.1 机制的安全性
测试程序.首先, 本文设计了缓冲区溢出攻击的测试程序, 简单的程序示例如图5所示.程序中strcpy函数将str中的值复制到buff中的时候, 由于没有边界检查, 栈中的返回值将被覆盖, 当函数执行完后指令指针指向到了if代码块之中, 然而if中指令在程序正常执行的情况下并不会被执行.

图5 简单的攻击代码
实验结果与分析.当示例程序在仿真器上模拟运行的时候攻击者成功使得if中本不应被执行的代码执行, 而当PEC-V被使用时, 程序跳转到未知位置造成程序崩溃, 阻止了攻击者的目的.
除了自行设计的溢出攻击程序之外, 对于此机制的安全性, 进一步根据Wilander等设计的缓冲区溢出的测试集进行分析.Wilander等罗列出了20余种针对缓冲区溢出的攻击[24], 主要分为4类, 分别为针对return address, function point, old base point和longjmp buffer的攻击.因为本文的机制针对的是return address和function point的加解密, 所以在此处只讨论关于前两者的攻击.攻击的方式又可分为栈溢出和堆溢出攻击,攻击方式如表2所示.

表2 Wilander等[24]研究中的攻击种类
因为此些攻击过程中都需要通过覆盖返回地址或函数指针指向目的地址, 然而由于此类数据已被加密,在攻击者无法获得加密密钥的情况下, 覆盖后的值解密后将指向随机地址造成程序崩溃, 因此攻击者的目的将无法实现.
4.2 机制的效率
(1) 测试程序.本实验首先使用Juliet Test Suite[25]这一常见漏洞测试集进行效率测试.测试集中存在着几种针对缓冲区溢出漏洞的分类(cwe121_stack_based_buffer_overflow, cwe122_heap_based_buffer_overflow和cwe124_buffer_underwrite, cwe680_integer_overflow_to_buffer_overflow), 选取这4种分类中的测试程序t1,t2,t3和t4, 进行针对返回地址的防御实验.其中,t1为向栈上缓冲区复制数据越界,t2为向堆上缓冲区复制数越界,t3为数组下标越界,t4为整数溢出导致数组越界.由于Juliet测试集中缺少针对函数指针的攻击示例, 对于函数指针的效率测试使用Wilander testbed中的测试集, 包括栈上溢出修改函数指针w1和堆上溢出修改函数指针w2和w3.测试过程首先将t1-t4和w1-w3编译成原始的没有加密机制保护的版本, 在此基础上按照前文介绍的方式修改汇编代码, 增加使用PEC-V的防护机制.接着在C++仿真器上本研究使用RISC-V的ProxyKernel运行测试程序, 通过在测试程序开始前和结束后读取时钟寄存器的值来获得精确的运行周期.
除了使用已存在的测试集之外, 为了进一步探究此防御机制的效率问题, 本文对于栈上溢出修改函数指针和返回地址的测试程序进行修改, 增加对程序中嵌套调用函数和多次使用函数指针的情况的测试.test1测试针对返回地址的加解密的效率, test1中子函数迭代调用的次数从1到6增加.test2测试针对函数指针保护的效率, test2中使用的函数指针从1到6不断增多.
(2) 实验结果与分析.对Juliet Test Suite和Wilander Testbed中的程序进行实验后结果如图6所示, 从中可以看出使用此机制对于常见的可利用漏洞进行防御, 程序效率的下降未超过4%, 未造成严重影响.而在对test1和test2加密前后两个版本测试后, 实验的运行结果分别如图7(a)和图7(b)所示.从图中可以看出test1和test2在受到协处理器的加密机制保护后, 运行效率的下降在1%-3%之间.
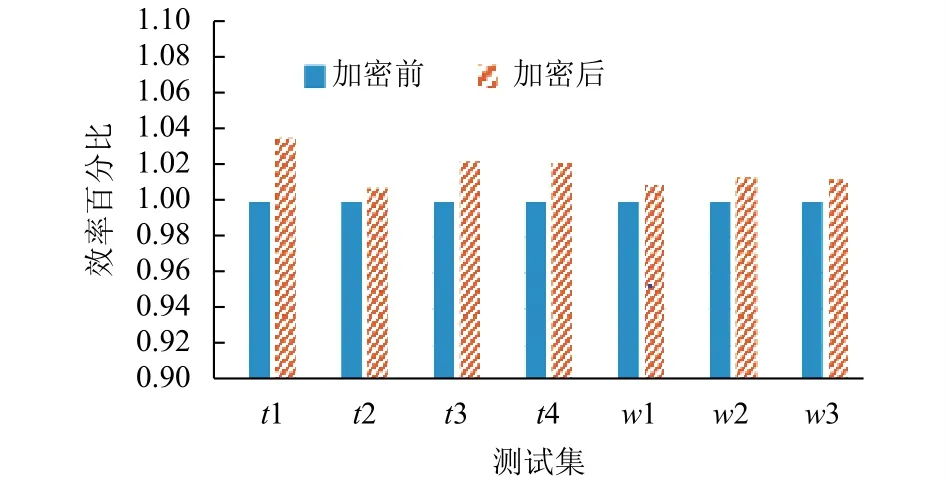
图6 测试集运行效率

图7 性能比较
从数据中可以看出, 对于一般测试程序而言, 硬件实施指针加密的方式并不会对程序的运行效率产生显著影响.
5 结论与展望
本文旨在介绍一种通过硬件方式实现的缓冲区溢出攻击保护机制.通过RoCC接口接入指针加密协处理器, 加密返回地址和函数指针使得攻击者定位目标代码的难度大大增加, 同时使得对程序的运行效率的影响降到最小, 而PUF和TRNG在协处理器中的使用使得加密键值的随机性得到保障, 并且PUF的特性可以加大物理手段获取随机键值的难度.实验结果表明,未使用PEC-V机制时针对对RISC-V的溢出攻击能够成功, 然而增加这一防护机制后, 攻击的难度增加, 并且未对程序运行效率造成显著影响, 优于以往的实现方案.
此外本文主要针对返回地址和函数指针进行讨论,而常见的溢出攻击针对的目标还有帧指针等, 此机制略作修改便可同样运用于帧指针值的保护.而此预防机制存在一定的不足之处, 对于不需要返回到特定地址, 直接通过溢出改写重要变量或者泄露重要信息的攻击, 此机制暂时无法防御, 这方面的防御手段还需进一步研究.
