色噪声下基于白化频谱重排鲁棒主成分分析的语音增强算法
2022-01-04罗勇江杨腾飞
罗勇江 杨腾飞 赵 冬
(西安电子科技大学电子工程学院 西安 710071)
1 引言
语音增强技术是语音信号处理的重要手段,用于抑制含噪语音中的背景噪声,单通道语音增强则是最具挑战性的应用需求[1]之一。于是语音增强技术开始被许多学者所研究,并提出了多种传统的单通道语音增强算法,例如频谱减法[2]、最小均方误差估计算法[3]和维纳滤波算法[4]等,这些算法在白噪声下的性能较好,但在色噪声环境中性能下降。
基于子空间的语音增强算法主要以矩阵分析为基础,并在时域中实现语音增强。Ephraim等人[5]提出了针对含噪语音信号协方差矩阵使用特征值分解的语音增强方法,但该方法的前提是假设噪声为白噪声,对于其他噪声并不能取得较好的效果。Yi等人[6]对该方法进行了改进,提出了广义子空间方法,该方法采用非酉变换将含噪信号分别投影到信号加噪声子空间和噪声子空间,通过对噪声子空间中的信号分量进行置零,并保留信号子空间中的分量来估计纯净语音信号,最终实现对语音信号的增强。该方法中的变换具有内置的预白化功能,可以处理含色噪声语音信号,但该方法需要纯净语音信号样本,计算复杂度较大,不易实现。
相对于传统的语音增强算法,鲁棒主成分分析(Robust Principal Component Analysis, RPCA)作为一种实现矩阵低秩稀疏分解的模型,已用于单通道语音增强中,且具有较好的语音增强性能。纯净语音的能量主要集中在共振峰处,在时频域表现出稀疏的特征,背景噪声的频谱总是呈现重复的模式,具有低秩特性。在基于RPCA的单通道语音增强算法[7]中,含噪语音的时频幅度矩阵可以被RPCA分解为代表噪声分量的低秩矩阵和代表语音分量的稀疏矩阵,然后对稀疏矩阵进行时域重建,实现语音和噪声分离。文献[8]对原始的RPCA进行扩展,将含噪语音谱分解为噪声结构矩阵、纯净语音矩阵和剩余噪声矩阵3个子矩阵,直接将语音信号从噪声中分离。文献[9]将RPCA与语音与噪声词典的稀疏表示相结合,使用一种新的交替优化算法和基于互相关的最小角度及相关标准的语音与噪声词典的稀疏编码来对含噪语言进行分解。相对传统的方法,基于RPCA的语音增强算法对于白噪声环境下的普通语音信号增强具有较好的性能,但存在低秩语音分量丢失和色噪声的抑制能力较差的问题,主要表现为:(1)该算法对于低秩语音分量信号处理效果较差,因为语音中的浊音在时域表现出明显的周期性,在时频域中则为低秩性,因此这部分语音会被RPCA错误分解到低秩矩阵中作为噪声[10,11];(2)该算法在色噪声环境下的语音增强性能较弱,因为白噪声具有较为平坦的时频谱特性且其时频谱的秩近似于1,从而表现为良好的低秩性,但色噪声的时频谱特性并不均匀且其时频谱不具有低秩特性。
为了解决上述问题,本文利用噪声白化和频谱重排改进基于RPCA的单通道语音增强算法,提出一种基于白化频谱重排鲁棒主成分分析(Whitened Spectrogram Rearrangement Robust Principal Component Analysis, WSRRPCA)的单通道语音增强算法,提升色噪声环境下的语音增强效果。
2 基于RPCA的单通道语音增强系统
基于RPCA的单通道语音增强系统由分析-去噪-综合(Analysis-Modification-Synthesis, AMS)框架实现,包括3个阶段:(1)分析阶段,通过短时傅里叶变换(Short Time Fourier Transform, STFT)将时域的含噪语音转换为时频幅度矩阵;(2)去噪阶段,对含噪语音的时频幅度矩阵进行某种修改;(3)合成阶段,对修改后的时频幅度矩阵每一列进行离散傅里叶逆变换(Inverse Discrete Fourier Transform, IDFT),然后利用叠接相加法(Over-Lap-Add, OLA)合成时域的增强语音系统框图如图1所示。
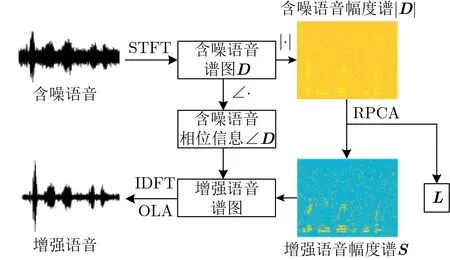
图1 基于RPCA的单通道语音增强算法的系统框图
RPCA模型的输入数据为矩阵|D|∈Rm×n,它是含噪语音的时频幅度矩阵,具有n个短时帧,每一帧有m个频谱元素。利用RPCA可以将|D|分解为两个输出部分:对应于噪声的低秩矩阵L ∈Rm×n和对应于语音的稀疏矩阵S ∈Rm×n,3个矩阵的数学关系表示为

其中,‖·‖∗表示矩阵的核-范数,‖·‖1表示矩阵的1-范数,λ是一个正的加权参数。目前已开发出许多算法来解决式(2)中的凸优化问题,如加速近端梯度法[13]、增广拉格朗日乘子(Augmented Lagrange Multiplier, ALM)法[14]和奇异值阈值法[15]。其中,ALM算法既实用又高效,可以通过如下方式解决式(2)中的凸优化问题

对于高斯白噪声环境下的语音增强,基于RPCA的语音增强算法的核心思想是通过低秩稀疏分解,将含噪语音的时频谱分解为代表噪声分量的低秩矩阵和代表语音分量的稀疏矩阵,然后仅对稀疏矩阵进行时域重建,实现语音和噪声分离。因此对于一些具有弱稀疏特性的语音分量将被分解到低秩矩阵中,从而造成分量的丢失。而对于色噪声条件下的语音增强,由于色噪声的时频特性并不具有低秩特性,常规的基于RPCA算法较难抑制色噪声。
3 基于WSRRPCA的单通道语音增强算法
本文提出的基于WSRRPCA的单通道语音增强算法从将色噪声处理转化为白噪声和破坏低秩语音分量信号的角度出发,构建合理的白化色化模型和频谱重排方法,提高色噪声环境中语音增强性能。
3.1 噪声白化
白噪声频谱是近乎平坦的,其时频幅度矩阵的秩可以被认为等于1,具有出色的低秩特性。色噪声时频图中的能量分布不均匀,难以保证较好的低秩性。因此基于RPCA的单通道语音增强算法在色噪声中的性能不如在白噪声中的性能。为获得较好的色噪声环境下的语音增强性能,本文使用噪声白化将色噪声转变为白噪声。色噪声的白化可以通过Cholesky分解或基于线性预测的有限长单位冲激响应(Finite Impulse Response, FIR)滤波器来实现[16,17]。Cholesky分解方法需要将信号修改为Hankel矩阵模型,这会使信号结构改变,并且后续处理步骤无法直接应用。相反,基于线性预测的FIR滤波器仅改变信号的幅度和相位且能保留信号模型,它可以使用过去样本的线性加权组合来预测噪声信号v(n)在n时刻的值,预测值vˆ(n)可以表示为[18]

利用Levinson-Durbin算法求解上式可以得到用于构建白化滤波器的系数ak,e(n)是色噪声经过白化得到的结果。
利用白化滤波器对含噪语音处理时,不仅要形成对色噪声分量的白化,也要尽可能使得对语音分量的影响最小。语音信号的一个重要特点是具有可预测性,因为它的相邻取样之间存在一定的相关性,可以通过线性预测模型(Linear Prediction Coding, LPC)描述语音信号的特征和产生机理。在LPC中,语音信号可以通过激励一个时变的全极点滤波器产生,语音信号的特性由全极点滤波器获得,激励信号µ(n)通常采用无语音分量的高斯白噪声[19]。此时,语音信号s(n)可以表示为

其中,s˜(n)为语音信号s(n)通过白化滤波器的输出信号,M=max(Q,P)。从式(10)可以看到语音分量经过白化滤波器后得到的输出信号为高斯白噪声与语音信号过去值的线性组合,说明语音信号经过白化滤波器后,仍然符合LPC模型,具有语音信号的稀疏特性。
3.2 频谱重排
在利用RPCA对含噪语音的时频幅度矩阵进行低秩稀疏分解时,纯净语音并非是完全稀疏的。因为含噪语音的频谱中某些语音成分可用有限数量的频谱基来描述,这意味着它们具有低秩特征[10]。因此,可以认为语音信号由稀疏分量和低秩分量组成

因此,式(1)可以写为更精确的形式
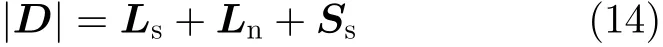
若将Ls和Ss一起分解到主要包含语音成分的稀疏矩阵S中则可以在增强语音中保留较多的语音成分,从而提高算法性能。增加矩阵Ls的秩是获得良好分解结果的一种可行方案。因此,本文采用了一种称为频谱重排的技术来增加矩阵Ls的秩,频谱重排技术需要对含噪语音的时频幅度矩阵|D|的每一列的谱元素进行重新排列,且各列之间的排列规则需要保证互不相同。
为了保证每一列的重排规则不同,且具有可控性和可复现的特点,本文采用哈希函数来为矩阵|D|的每一列生成相应的重排规则。哈希函数定义为

其中,a ∈[2,m),b ∈[0,m)均为控制参数,且a需要和m互质[20],(·)m表示对m取模。哈希函数式(15)实现从k到f(k)的映射,并且映射关系随着a和b的变化而改变。以一个列向量x=[x1x2...xm]T∈Rm×1为例说明元素重排的实现过程。将列向量x中的各个元素的位置记为序列(1,2,...,m),则此序列可以通过式(15)映射为新的序列(f(1),f(2),...,f(m)),且根据数论中完全剩余系的理论,组成新序列的元素是完备的,即新序列中各个元素无重复、无丢失。然后利用序列(1,2,...,m) 和(f(1),f(2),...,f(m))生成一个第k行第f(k)列的元素为1而其余元素为0的重排矩阵T ∈Rm×m。那么,列向量x可以由重排矩阵T转化为其重排向量xr

其中,|D|r表示|D|被重排后的矩阵,Tj为第j列对应的重排矩阵。与式(14)类似,|D|r也可以表示为3个矩阵的总和

综上所述,频谱重排可以提高低秩语音Ls的秩,而又不改变稀疏语音矩阵Ss的稀疏和高秩特征以及噪声矩阵Ln的秩。
3.3 WSRRPCA算法的结构
WSRRPCA算法的结构是在AMS框架的基础上实现的。其算法结构图如图2所示。
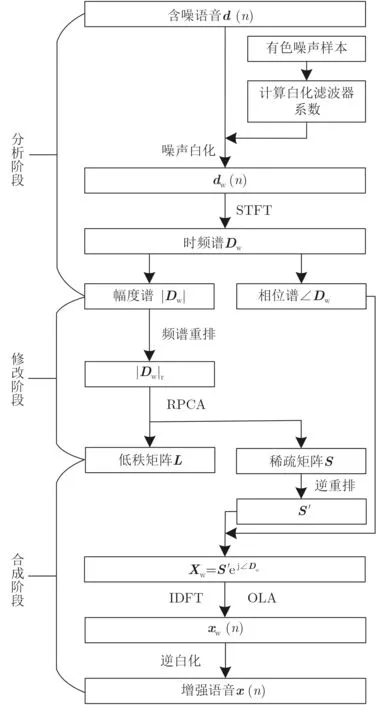
图2 WSRRPCA算法的结构框图
在分析阶段,首先使用含噪语音开始时的非语音段数据来构建白化滤波器,通过该滤波器将输入的含噪语音d(n)白化为dw(n)。然后,使用STFT将dw(n)转换为其时频图Dw,并得到时频幅度谱|Dw|和相位谱∠Dw,其中|Dw|用于去噪阶段,∠Dw将直接用作合成阶段中增强语音的相位信息。
在去噪阶段,对时频幅度谱|Dw|进行频谱重排得到|Dw|r,然后利用RPCA对矩阵|Dw|r进行低秩稀疏分解以获得低秩矩阵L和稀疏矩阵S。
在合成阶段,首先,将对稀疏矩阵S执行逆重排获得S′。然后,使用幅度谱S′和含噪语音的相位谱图∠Dw合成增强语音的时频图Xw

传统的语音增强算法认为相位差较小,且不易被听觉系统感知到,因此重构信号时可以采用带噪信号的相位[21]。然后,对Xw的每一列做IDFT,并使用OLA将多帧语音合成时域信号xw(n)。最后对xw(n)逆白化得到最终的增强语音信号x(n)。
3.4 WSRRPCA算法的参数
在WSRRPCA算法中参数λ会影响稀疏矩阵S的稀疏度。λ越大,矩阵S的稀疏度越大,矩阵S中残留的噪声更少,但使用RPCA进行分离后,语音成分会丢失更多,导致更高的语音失真。相反S的稀疏度小,则语音信号的失真会更少,但会包含更多的残留噪声[8]。因此,选择合适的λ值可以使语音分量和噪声分量之间获得理想的平衡。
为了确定参数λ的取值,完成了相应的仿真实验。在实验中,选择背景噪声为白噪声,信噪比分别为-5 dB, 0 dB, 5 dB和10 dB的含噪语音。然后将λ以0.001的间隔从0.001增大到0.15,并使用每一个λ的取值作为算法参数,利用本文提出的WSRRPCA算法对含噪语音进行增强,最后对每一次得到的增强语音计算其源失真比(Source-to-Distortion Ratio, SDR),得到λ与相应的SDR的关系,结果如图3所示。
SDR是衡量增强语音中语音能量和噪声能量比值的指标,表示的是算法的噪声抑制能力,单位是dB[22]。SDR越大表示算法的噪声抑制性能越好。从图3可以看出,当λ分别约等于0.144, 0.114, 0.094和0.076时,4个SDR曲线达到其峰值。在本文中,将使SDR得分位于曲线最高点的λ确定为算法的最优参数,并将其表示为λopt。显然,在实际应用中搜索λopt是不合理的。本文将λopt的估计值λˆopt用作WSRRPCA算法的参数。从图3可以看出,λopt随含噪语音的信噪比变化而变化,因此,可以根据信噪比来设置λˆopt。尽管含噪语音的信噪比在实践中仍然是未知的,但其粗略估计eSNR可以通过式(27)计算

图3 不同信噪比下SDR与λ 的关系曲线

4 实验结果及分析
4.1 实验设置
用于仿真的30个纯净语音来自NOIZEUS数据库,色噪声则来自NOISEX-92数据库,分别设置这些纯净语音在-5 dB, 0 dB, 5 dB和10 dB这4种信噪比下被色噪声污染,从而得到含噪语音信号。此外,语音和噪声都以8 kHz进行重新采样。在噪声白化过程中,含噪语音的前1024个点用于构建白化滤波器。在使用STFT时,通过汉明窗将含噪语音分帧,长度为256个样本,移位为128点,然后对每个帧应用256点快速傅里叶变换。ALM算法用于进行矩阵低秩稀疏分解。为了衡量算法的性能,使用SDR以及语音质量的感知评估(Perceptual Evaluation of Speech Quality, PESQ)作为评估指标。PESQ是衡量增强语音质量的指标[23],分数越高表示语音质量越好。
4.2 WSRRPCA与RPCA算法分解结果对比
图4显示了当语音被f16噪声污染的情况下,RPCA和WSRRPCA算法对含噪语音的直观分解结果对比。在图4中,图4(a)和图4(d)分别为纯净语音和f16噪声的时频图;图4(b)和图4(e)为由RPCA分解含噪语音时频图而得到的语音分量和噪声分量的时频图;图4(c)和图4(f)为由WSRRPCA分解含噪语音时频图而得到的语音分量和噪声分量的时频图。对比图4(d)和图4(e)可知,采用RPCA处理后,许多低秩语音成分被分解到噪声矩阵中。而对比图4(e)和4(f)可以观察到,采用WSRRPCA获得的噪声矩阵中,低秩语音残留较少。同样,对比图4(b)和图4(c)可知,WSRRPCA的处理结果在RPCA的语音分量结果的基础上保留了更多的低秩语音分量,这将使得WSRRPCA能够获得更好的语音质量。

图4 WSRRPCA与RPCA处理结果对比图
4.3 WSRRPCA与其他语音增强算法的性能对比
为了验证提出的WSRRPCA算法在色噪声环境下具有较好的语音增强效果,本文利用数值仿真实验,将该算法与基于RPCA的单通道语音增强算法[6]、基于约束低秩稀疏矩阵分解(Constrained Low-rank and Sparse Matrix Decomposition,CLSMD)的单通道语音增强算法[24]、几何谱减(Geometric Approach to Spectral Subtraction,GASS)算法[25]、结合信号存在不确定性的对数最小均方误差(Minimum Mean Square Error of the Log-spectra under Signal Presence Uncertainty,LogMMSE-SPU)算法[26]等进行了性能对比分析。
首先,测试语音sp01被buccaneer1,buccaneer2,f16,factory1,hfchannel和pink噪声破坏,其中信噪比为0 dB,数值结果如表1所示。实验结果表明,当语音信号被不同色噪声破坏后,在5种色噪声类型中WSRRPCA获得了最高的SDR分数。就PESQ指标而言,当噪声为buccaneer1,buccaneer2,factory1和hfchannel时,WSRRPCA的得分略低于RPCA的得分。

表1 不同噪声下多种算法的性能对比
大多数的语音增强方法在减少背景噪声的同时也会引入语音失真,因此,语音增强的目的是不明显引入信号失真的前提下,对其中的噪声进行有效抑制。综合SDR和PESQ的结果来考虑,在保证增强语音质量不发生明显降低的同时,本文提出的WSRRPCA算法在多种色噪声环境中具有更好的噪声抑制性能。
为了进一步说明所提算法具有更优的性能,本文用了30组语音信号,语音sp01-sp30分别受到6种类型的色噪声的破坏,且信噪比分别为-5 dB,0 dB, 5 dB和10 dB。对于每种情况,例如sp01被buccaneer1噪声污染,信噪比为-5 dB,进行了100次的蒙特卡罗实验。对于每种色噪声,将30个语音的SDR和PESQ分数的平均值作为最终结果,直观的条形图对比结果如图5和图6所示。
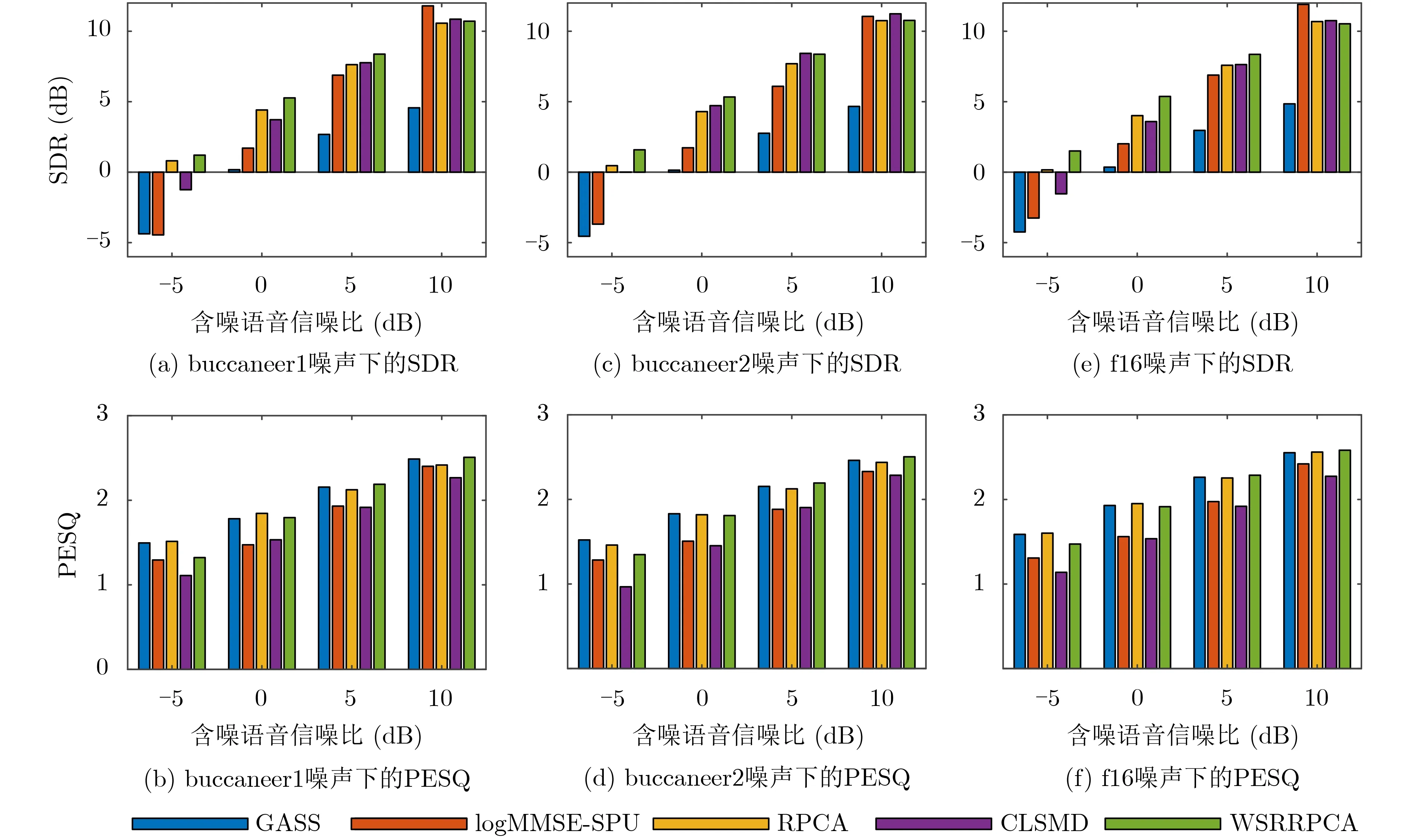
图5 buccaneer1, buccaneer2和f16噪声环境下不同算法的性能对比图

图6 Factory1, hfchannel和pink噪声环境下不同算法的性能对比图
从SDR的结果可以看出,在多种色噪声的低信噪比环境中(-5 dB, 0 dB和5 dB),本文提出的算法比其他算法具有更高的得分。尤其是当信噪比为-5 dB时,相比于其余算法,提出的算法可以实现优异的噪声抑制效果。而在信噪比为10 dB的高信噪比情况下,RPCA算法、CLSMD算法和本文提出的算法获得了几乎相同的SDR分数。对于PESQ,当信噪比为-5 dB时,所提出算法的得分仅略低于GASS算法和RPCA算法的得分。在其他信噪比时,所提出算法的PESQ得分与GASS和RPCA的结果基本相同,甚至稍高一些,综合评估SDR和PESQ这两种指标,当背景噪声为色噪声时,本文提出的算法在尽可能不降低语音质量的同时,可以有效地抑制背景噪声,比其他4种方法更具优势。
5 结束语
在基于RPCA的单通道语音增强算法的局限性的驱使下,本文提出一种基于白化频谱重排RPCA的语音增强算法,该算法通过合理优化噪声白化和色化模型改善原有算法只能适用高斯白噪声场合的能力,并利用频谱重排改善信号的时频低秩特性,从而提升噪声分量和语音分量分离性能,最终实现色噪声环境下的语音增强性能的提升。多种色噪声环境中的数值实验结果表明,与多种算法相比,本文提出的算法表现出更优的噪声抑制性能和更好的语音可懂度。
[1]LOIZOU P C. Speech Enhancement: Theory and Practice[M]. 2nd ed. London: CRC Press, 2013: 1-2.
[2]BOLL S. Suppression of acoustic noise in speech using spectral subtraction[J].IEEE Transactions on Acoustics,Speech,and Signal Processing, 1979, 27(2): 113-120. doi:10.1109/tassp.1979.1163209.
