基于非对称监督深度离散哈希的图像检索
2022-01-04顾广华霍文华苏明月
顾广华 霍文华 苏明月 付 灏
(燕山大学信息科学与工程学院 秦皇岛 066000)
(河北省信息传输与信号处理重点实验室 秦皇岛 066000)
1 引言
随着实际应用中数据的爆炸式增长,最近邻搜索在信息检索、计算机视觉等领域有着广泛的应用。然而,在大数据应用中,对于给定的查询,最近邻搜索通常是很耗时的。因此,近年来,近似最近邻(Artificial Neural Network,ANN)搜索[1]变得越来越流行。在现有的ANN技术中,哈希以其快速的查询速度和较低的内存成本成为最受欢迎和有效的技术之一。哈希方法[2,3]的目标是将多媒体数据从原来的高维空间转换为紧凑的汉明空间,同时保持数据的相似性。这些二进制哈希码不仅可以显著降低存储成本,在信息搜索中实现恒定或次线性的时间复杂度,而且可以保持原有空间中存在的语义结构。
现有的哈希方法大致可分为两类:独立于数据的哈希方法和依赖于数据的哈希方法。局部敏感哈希(Locality Sensitive Hashing, LSH)[4]及其扩展作为最典型的独立于数据的哈希方法,利用随机投影得到哈希函数。但是,它们需要较长的二进制代码才能达到很高的精度。由于数据独立哈希方法的局限性,近年来的哈希方法尝试利用各种机器学习技术,在给定数据集的基础上学习更有效的哈希函数。
依赖于数据的哈希方法从可用的训练数据中学习二进制代码,也就是学习哈希。现有的数据依赖哈希方法根据是否使用监督信息进行学习,可以进一步分为无监督哈希方法和监督哈希方法。代表性的无监督哈希方法包括迭代量化(IteraTive Quantization, ITQ)[5],离散图哈希(Discrete Graph Hashing, DGH)[6]、潜在语义最小哈希(Latent Semantic Minimal Hashing, LSMH)[7]和随机生成哈希(Stochastic Generative Hashing, SGH)[8]。无监督哈希只是试图利用数据结构学习紧凑的二进制代码来提高性能,而监督哈希则是利用监督信息来学习哈希函数。典型的监督哈希方法包括核监督哈希(Supervised Hashing with Kernels, KSH)[9],监督离散哈希(Supervised Discrete Hashing, SDH)[10]和非对称离散图哈希(Asymmetric Discrete Graph Hashing, ADGH)[11]。近年来,基于深度学习的哈希方法[12]被提出来同时学习图像表示和哈希编码,表现出优于传统哈希方法的性能。典型的深度监督哈希方法包括深度成对监督哈希(Deep Supervised Hashing with Pairwise Labels, DPSH)[13],深度监督离散哈希(Deep Supervised Discrete Hashing,DSDH)[14],和深度离散监督哈希(Deep Discrete Supervised Hashing, DDSH)[15]。通过将特性学习和哈希码学习集成到相同的端到端体系结构中,深度监督哈希[16,17]可以显著优于非深度监督哈希。然而,现有的深度监督哈希方法主要利用成对监督进行哈希学习,语义信息没有得到充分利用,这些信息有助于提高哈希码的语义识别能力。更困难的是,对于大多数数据集,每个项都由多标签信息进行注释。因此,不仅需要保证多个不同的项对之间具有较高的相关性,还需要在一个框架中保持多标签语义,以生成高质量的哈希码。
为了解决上述问题,本文提出了一种非对称监督深度离散哈希(Asymmetric Supervised Deep Discrete Hashing, ASDDH)方法。具体来说,为了生成能够完全保留所有项的多标签语义的哈希码,提出了一种非对称哈希方法,利用多标签二进制码映射,使哈希码具有多标签语义信息。此外,本文还引入了二进制代码的位平衡性,进一步提高哈希函数的质量。在优化过程中,为了减小量化误差,利用离散循环坐标下降法对目标函数进行优化,以保持哈希码的离散性。
2 非对称监督深度离散哈希
2.1 符号和问题定义


2.2 模型表述

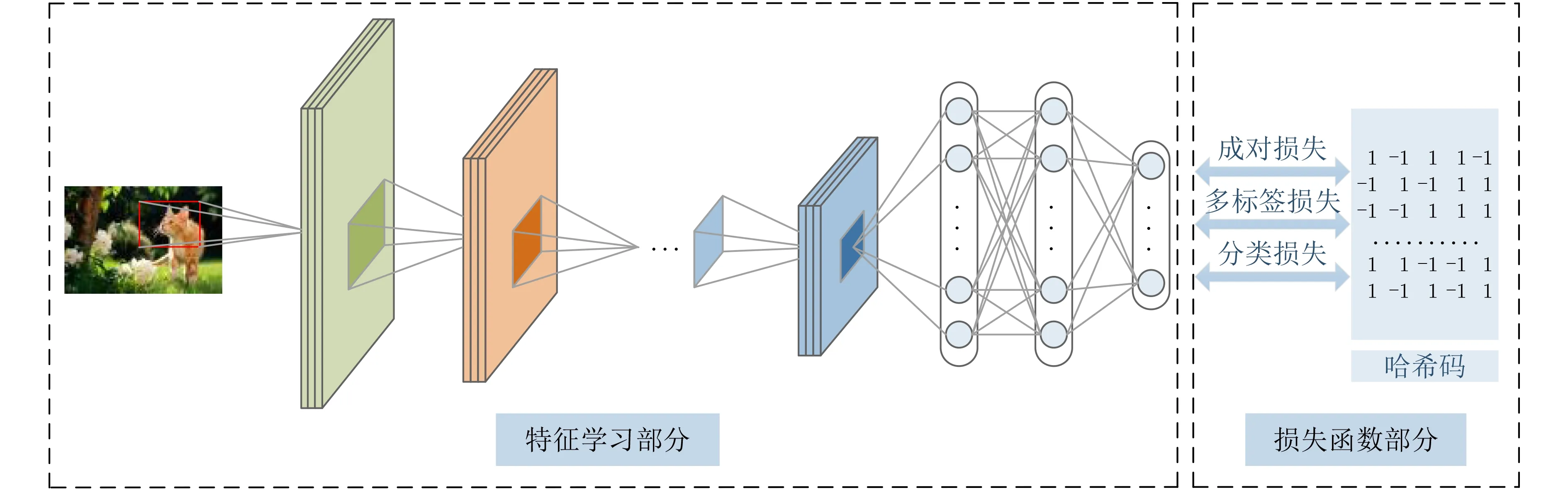
图1 ASDDH模型体系结构
2.3 损失函数

为了提高所学哈希码的准确性,本文还使学习的二进制码具有以下特性:(1)语义分类最优。直接利用标签信息,使所学习的二进制码对于联合学习的线性分类器是最优的。(2)多标签语义保存。引入一种非对称哈希方法,该方法利用多标签二进制码映射,使哈希码保留多标签语义信息。(3)位平衡。使学习的哈希码的每个位有50%的概率为1或-1。
本文使用一个简单的线性分类器来建模学习的二进制代码和标签信息之间的关系:

其中W ∈RK×c是分类器权重。则分类损失可以表示为

这里L(·)是损失函数,本文选择的是线性分类器的l2损失。‖·‖F是矩阵的Frobenius范数,λ是正则化参数虽然式(1)实现了成对监督信息的保存,式(4)实现了最优的线性分类,但忽略了多标签语义的保存。

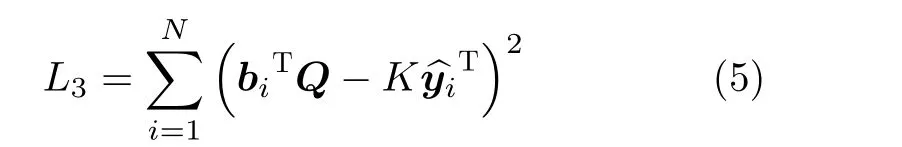
其中y^i=yi×2−1∈{−1,1}c。
为了使哈希码的每一位在所有训练集上保持平衡。本文增加了位平衡损失项来最大化每一位所提供的数据点信息。更具体地,在所有训练点上,对每个位进行了平衡,鼓励所有训练样本中的-1和+1的数目近似。此时编码达到平衡,信息量最大,哈希编码最优。该损失项表示为
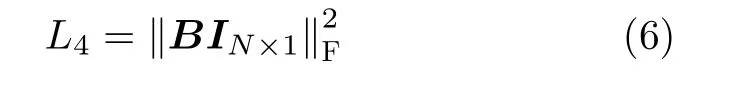
其中IN×1表示所有元素都等于1的矩阵。综合考虑式(1)、式(4)、式(5)和式(6),得到整体目标函数为

由于具有式(7)中的二进制约束离散优化求解非常具有挑战性,现有的方法大多采用对二进制约束进行连续松弛的方法。在测试阶段,对连续输出应用阈值函数得到哈希码。然而,这种连续松弛会通过对哈希码的连续嵌入进行二值化而产生不可控制的量化误差。为了克服这种局限性,本文采用了一种新的离散求解策略,将sign(hi)设置为接近它对应的哈希码bi。然而,由于sign(hi)中的hi梯度处处为零,很难进行反向传播。本文将tanh(·)应用于sign(·)函数的软逼近。为了控制量化误差,缩小期望二进制码与松弛之间的距离,在hi上加了额外的惩罚项来逼近期望的离散二进制码bi。将式(7)重新表述为

2.4 优化算法
由目标函数式(8)可知,该损失函数的优化问题是非凸非光滑的,很难直接得到最优解。为了找到一个可行的解,本文使用的是交替优化的方法,这种方法在哈希文献[13,14]中得到了广泛的应用:固定其他变量更新一个变量。更具体地说,本文依次对深度神经网络参数、分类器权重W、二进制码矩阵B和多标签二进制映射Q的参数进行迭代更新,步骤如下:
(1)更新H,固定W,B和Q。当固定B和Q时,利用随机梯度下降法(SGD)学习深度神经网络的参数。特别地,在每次迭代中,从整个训练数据集中抽取一小批图像样本,并使用反向传播算法对整个网络进行更新。这里表示U=tanh(H)。损失函数的导数为

(3)更新B,固定H,W和Q。将问题式(8)重写为矩阵形式:


3 实验
3.1 实验设置
本文在两个广泛使用的基准数据集上进行了实验:CIFAR-10和NUS-WIDE。每个数据集被分为查询集和检索集,从检索集中随机选取训练集。CIFAR-10数据集是一个单标签数据集,包含60000张像素为32×32的彩色图像和10类图像标签。对于CIFAR-10数据集,如果两幅图像共享一个相同的标签,则它们将被认为是相似的。NUS-WIDE数据集由与标签相关的269,648幅Web图像组成。它是一个多标签数据集,其中每个图像都使用来自5018个标签的一个或多个类标签进行注释。与文献[13,14]类似,只使用属于21个最常见的标签的195,834张图像。每个类在这个数据集中至少包含5000张彩色图像。对于NUS-WIDE数据集,如果两个图像至少共享一个公共标签,则它们将被认为是相似的。
遵循文献[14]的实验设置。对于CIFAR-10数据集,每个类随机选取100张图像作为查询集,其余的图像作为检索集。从检索集中随机抽取每类500幅图像作为训练集。对于NUS-WIDE数据集,随机抽取2100幅图像(每个类100幅图像)作为查询集,其余的图像构成检索集。并且使用检索集中每类500幅图像作为训练集。对于ASDDH方法,算法的参数都是基于标准的交叉验证过程设定的。实验中设置α=1,β=1,µ=0.1,η=55,τ=0.001,γ=1。为了避免正相似和负相似信息的类不平衡问题所带来的影响,将S中元素-1的权重设为元素1与元素-1在S中的数量之比。
3.2 基线和评价标准
本文选择了一些典型方法作为基线进行比较。对于基线,大致将其分为两组:传统哈希方法和深度哈希方法。传统哈希方法包括无监督哈希方法和监督哈希方法。无监督哈希方法包括SH(Spectral Hashing)[19], ITQ[5]。监督哈希方法包括SPLH(Sequential Projection Learning for Hashing)[20],KSH[9], FastH(Fast Supervised Hashing)[21],LFH(Latent Factor Hashing)[22]和SDH[10]。传统的哈希方法采用手工特征作为输入。本文将传统哈希方法的手工特征替换为由卷积神经网络提取的深度特征作为基线进行比较,比如表1中的“FastH+CNN”表示FastH方法利用卷积神经网络提取特征取代手工特征,其它方法同理。深度哈希方法包括DQN(Deep Quantization Network)[23],DHN(Deep Hashing Network)[24],CNNH(Convolutional Neural Network Hashing)[25],NINH[26],DPSH[13],DTSH(Deep Supervised Hashing with Triplet Labels)[27]和DSDH[14]。对于深度哈希方法,首先将所有图像的大小调整为224像素×224像素,然后直接使用原始图像像素作为输入。本文采用在ImageNet数据集上预训练的AlexNet网络初始化ASDDH框架的前7层,其它深度哈希方法也采用了类似的初始化策略。
为了定量地评估本文方法和基线方法,本文采用了一种常用的度量方法:平均准确率均值(Mean Average Precision, MAP)。NUS-WIDE数据集上的MAP值是根据返回的前5000个最近邻来计算的。CIFAR-10数据集的MAP是基于整个检索集计算的。所有实验运行5次,并报告平均值。
3.3 精确度
表1报告了两个数据集上所有基线方法和提出的ASDDH方法的MAP结果。其中DSDH*表示本文重新运行DSDH原作者提供代码的实验结果。从表1可以看出:(1)本文ASDDH方法显著优于所有基线;(2)在大多数情况下,监督方法优于无监督方法。这表明深度监督哈希是一种更兼容的哈希学习体系结构。
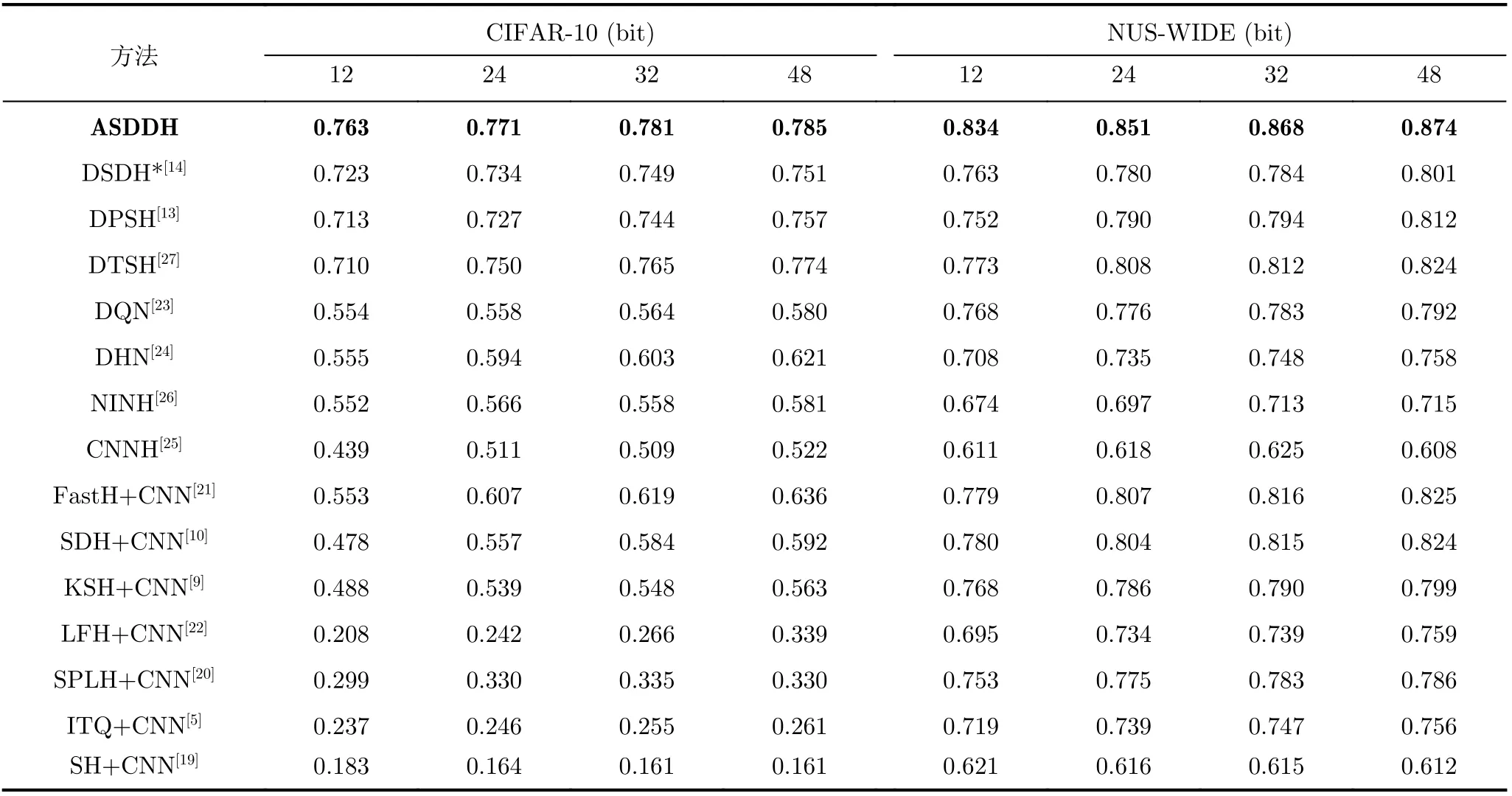
表1 两个数据集上不同方法的MAP
在CIFAR-10数据集上,随着编码长度从12增加到48,ASDDH计算得到的MAP分数从0.763增加到0.785,远远优于传统的基于深度学习特征的哈希方法。基于深度哈希的基线方法中,DPSH,DTSH和DSDH的学习效果显著优于DQN, DHN,NINH和CNNH。将所提出的ASDDH方法与DPSH、DTSH和DSDH进行比较可以看出,在不同的编码长度下,ASDDH方法获得的性能都有不同程度的提高。与DSDH相比,ASDDH方法进一步提高了3%到5%的性能。
在NUS-WIDE数据集上,ASDDH在MAP性能方面取得了显著的提高。在所有编码长度情况下,ASDDH得到的MAP分数始终高于0.834,尤其是当编码长度为48时达到0.874;而DPSH,DTSH和DSDH得到的最佳结果仅为0.824,远远低于本文方法。与DPSH和DSDH相比,当编码长度在12到48之间时,所提出的方法获得了大约6%~8%的增强。与DTSH相比,ASDDH的性能也有5%左右的提高。
本文方法在NUS-WIDE数据集上的效果比CIFAR-10数据集提高得更多,主要原因是NUS-WIDE数据集内包含的图像类别比CIFAR-10数据集更多,而且每个图像都包含多个标签。损失函数中的L3利用多标签二进制码映射进行非对称训练,使哈希码具有多标签语义信息,进一步提高了实际应用中的检索性能。因此,本文提出的ASDDH方法在NUS-WIDE多标签数据集上更有效。
3.4 特征学习网络
为了分析不同深度卷积神经网络对检索结果的影响,本文将原来ASDDH模型中的AlexNet网络改为预训练的VGG-16, ResNet50和ResNeXt50网络进行训练。VGG-16网络由13个卷积层和3个全连接层组成,比AlexNet网络更为复杂且参数更多。残差网络ResNet50包含49个卷积层和1个全连接层,该网络主要通过跳跃连接的方式,在加深网络的情况下又解决梯度爆炸和梯度消失的问题。ResNeXt是ResNet和Inception的结合体,Res-NeXt结构可以在不增加参数复杂度的前提下提高准确率,同时还减少了超参数的数量。ResNeXt50和ResNet50类似,包含49个卷积层和1个全连接层。
为了得到最终的二进制代码,本文将VGG-16,ResNet50和ResNeXt50网络的最后一层用1个完全连通的哈希层(激活函数为tanh)所取代,并将这3种模型分别表示为ASDDH-V16, ASDDHRN50和ASDDH-RNX50。同时对基于深度哈希的DSDH进行了同样的实验并做对比,以保证结论的可靠性。DSDH对应的3种模型分别表示为DSDHV16, DSDH--RN50和DSDH-RNX50。表2显示了CIFAR-10数据集上每个模型的MAP值。
如表2所示,使用VGG-16, ResNet50和Res-NeXt50网络代替AlexNet网络使得最终的检索准确率有所上升,这种趋势在基线DSDH和提出的ASDDH中都有体现。这说明不同的深度网络对模型的性能有一定的影响。并且随着网络复杂度的增加,提取的特征也更加准确,使得模型训练更加可靠。
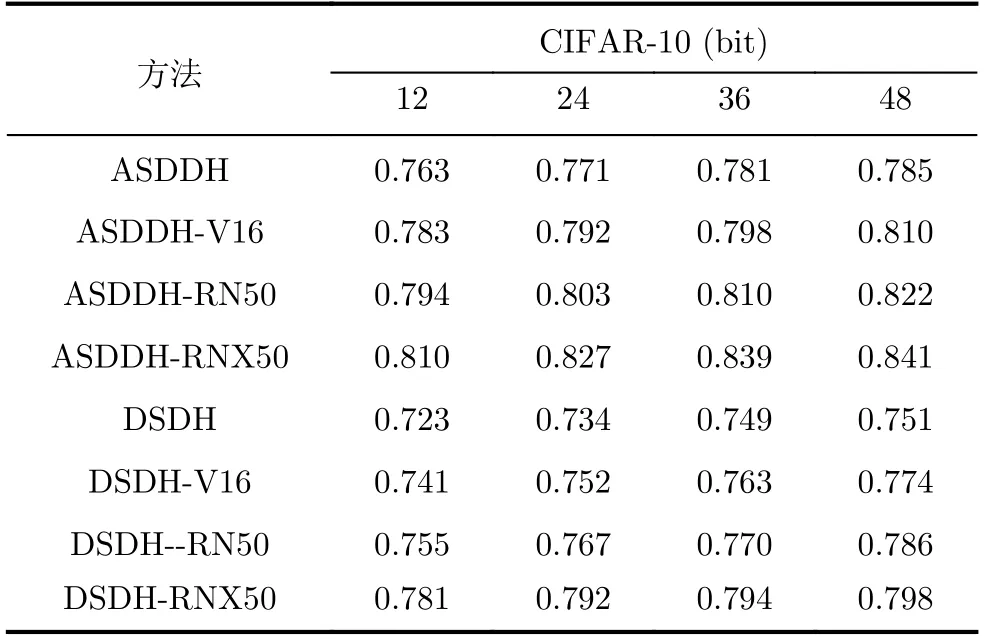
表2 不同网络的MAP
3.5 参数敏感性分析
图2给出了针对ASDDH的超参数γ和τ在CIFAR-10数据集上的影响,二进制代码长度分别为24 bit和48 bit。值得注意的是,当对一个参数进行调优时,其他参数是固定的。例如在[0.001, 0.01,0.1, 1, 10, 100]范围内调优γ时,分别固定其他超参数。由图2 (a)可以看出,在0.001<γ<10的范围内,ASDDH对γ并不敏感。同样,由图2 (b)给出的CIFAR-10数据集上不同τ的MAP结果可以知道,当τ在范围[0.0001,0.1]的时候,该方法总是取得令人满意的效果。除此之外,本文提出的ASDDH方法不管是在24 bit还是48 bit哈希码上,在γ=1,τ=0.001时取得最好的结果。

图2 CIFAR-10数据集上的超参数影响
4 结论
本文提出了一种新的非对称深度监督离散哈希方法,即ASDDH,用于大规模的最近邻搜索。首先利用深度网络提取图像特征,将特征表示和哈希函数学习集成到端到端框架中。然后引入成对损失和分类损失来保存每对输出之间的语义结构。在此基础上,提出了一种非对称哈希方法,既能捕获离散二进制码与多标签语义之间的相似性,又能在训练阶段快速收敛。值得注意的是,非对称哈希项尤其针对多标签数据库更有效。在实际数据集上的实验表明,ASDDH在实际应用中可以达到最先进的性能。
