基于降维聚类的双馈风力发电机参数辨识
2021-12-28吴林林张家安刘东李飞王潇刘辉
吴林林,张家安,刘东,李飞,王潇,刘辉
(1.国网冀北电力有限公司电力科学研究院,北京 100045;2.河北工业大学人工智能与数据科学学院,天津 300401;3.河北建筑工程学院信息管理系,河北张家口 075400)
0 引言
风力发电以其发电量大、环境污染小等优点,得到了政府的大力支持。风力发电机根据运行原理不同分为多种类型,其中,双馈异步风力发电机目前占主导地位。双馈异步风力发电机可以根据风速的变化进行恒频发电、最大功率跟踪[1]、变桨矩控制等。风机通过变流器[2]将风机转子与电网连接,在转子、定子、电网之间进行功率交换。在风电场运行中,存在机组老化、控制系统版本升级等情况,使得调度运行分析中的风电场发电机模型参数产生一定的不确定性,在一定程度上对电力系统仿真及安全稳定运行产生影响,使得风机参数辨识成为解决该问题的重要手段。目前风电控制系统中,转子侧控制器[3]、网侧控制器多采用PID控制[4],[5],所以须要针对性地开展相关研究。
目前,参数辨识方法主要有最小二乘法[6]、卡尔曼滤波法[7]、人工神经网络算法[8]、遗传算法[9]、参考模型法[10]、蚁群算法[11]、模拟退火算法[12]、粒子群优化算法及相关方法的混合算法[13]等。其中最小二乘法在处理非线性系统时,其辨识偏差较大,如对于风机控制器等参数要求极高、不确定性较强的系统,最小二乘法及其衍生方法不能满足精度要求。卡尔曼滤波法是用于线性系统状态估计的方法。神经网络[14]方法能够模拟复杂的非线性系统,多层神经网络、大量数据反复训练能够逼近复杂的非线性函数,但风机运行过程风速不断变化,数据特性相关性会较小,辨识过程也要在风机运行中进行,神经网络方法难以满足实时辨识的要求。遗传算法、粒子群算法在复杂的非线性系统中,拥有较好的辨识性,但其需要一个收敛时间,系统越复杂,收敛速度越慢,而且容易陷入局部最优解。
双馈风力发电机为非线性、多变量系统,拥有大量扰动信号和强耦合特性,存在饱和非线性特征。根据差分方程采集相应数据,直接进行线性运算不能得到准确结果,须要将采集数据中的线性数据提取出来进行精确计算。本文提出了一种基于降维聚类的双馈风机发电机参数辨识方法,应用Locally linear Embedding(LLE)降维方法,保留局部数据之间的线性关系,进而应用Kmeans聚类方法将降维后的数据进行分类并提取聚类中心部分的数据,最后应用改进多学习率线性神经网络方法根据控制器差分方程对参数进行精确辨识。
1 双馈风力发电机控制器模型
在风机运行过程中,可以固定周期采集电流、电压、转速等数据。本文以双馈风机转子侧控制系统为例,结合其数学模型线性化,基于采集数据进行参数辨识。
根据转子侧控制器结构,得到q轴解耦控制器差分方程为

式中:Udr,Uqr分别为转子侧d轴和q轴电压;Idr,Iqr分别为转子侧d轴和q轴电流;Qref为无功功率参考值;Pref为有功功率参考值;ω1为同步转速;ωr为转子转速;Iqs,Iqs为网侧dq轴电流;Lr为转子电感;Lm为转子定子互感;Ps为有功功率;Qs为无功功率;s为转差率;kp(β)(β=1,2,3,4)为PI控制器的比例系数;ki(β)(β=1,2,3,4)为PI控制器的积分系数;T为数据采集周期;k为数据采集点数。
基于以上方程可对采集数据进行相关处理。
2 数据提取
2.1 LLE降维
LLE降维算法为一种非线性降维算法,在对高维数据降维后,该算法仍能保持其局部特性,并将高维数据映射到三维或二维可视维度。
对于空间中的一个点,算法首先基于欧式距离寻找其邻近的κ个点,得到该点的局部重建权值矩阵W,对重构的误差进行定义:
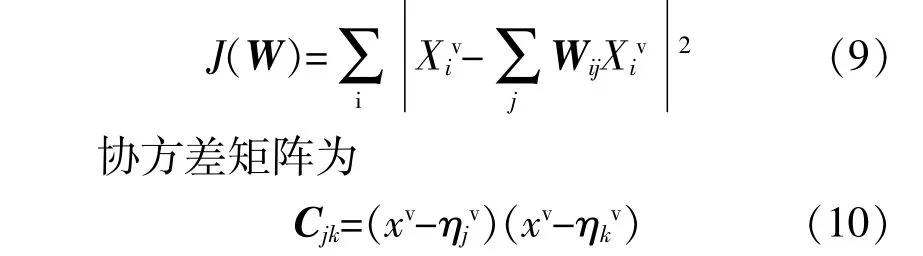
其中:x为选择的点;η为其邻近的点。
得到目标函数式(9),并对其进行最小化,得到:
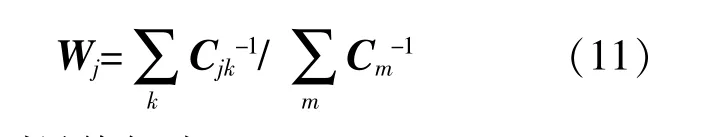
可以得到最终解为

式中:M为对称矩阵;j为第j个权值;i为第i个临近点;N为维度;Y为M的最小m个非零特征值所对应的特征向量;λ为特征值。
在计算过程中,M的特征值为逐渐递加的,取特征值对应的特征向量为最后结果。LLE降维方法对于非线性数据可以保证其中的线性数据降维之后数据特性不被破坏,所在降维之后的数据特性依然与原数据相同。
2.2 K-means数据聚类
K-means聚类算法是一种对数据样本进行分类的算法,根据常用欧氏距离,可将数据分为α个类,每个数据类中数据到中心的距离小于到其他数据类中心的距离。在此,欧氏距离表达式为
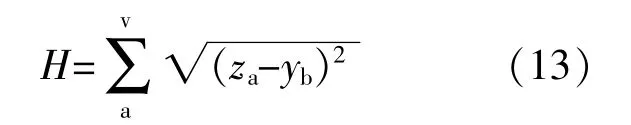
式中:H为欧式距离;z为某一个样本数据;y为某一个样本数据;a为样本数据第a维;b为样本数据第b维;v为数据的维度。
2.3 双馈风力发电机数据提取
根据式(8)进行控制器参数的计算,但实际风电系统存在强耦合、非线性饱和,并含有诸多噪声,所以直接对采集的数据进行线性处理,得到的结果会不准确。将线性数据提取出来再进行计算,可以极大地降低误差。在非线性数据进行线性化时,往往通过支持向量机算法进行处理,但根据式(8)可知数据为7维数据,应用支持向量机的方法显然不能达到计算目标。根据式(8)得到向量:
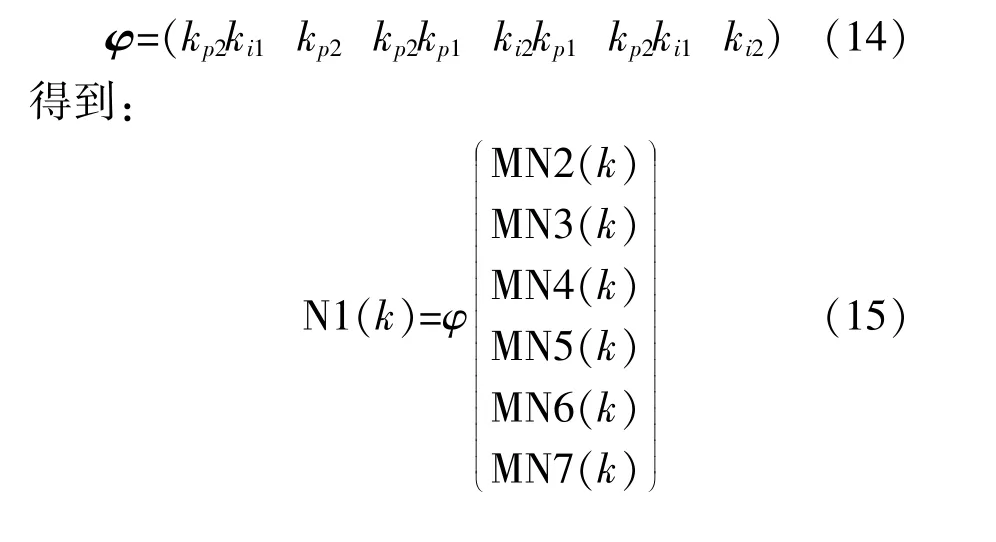
根据式(15),对风电场监控系统所采集的相关数据进行处理,得到一组七维[MN1(k),MN2(k),MN3(k),MN4(k),MN5(k),MN6(k),MN7(k)]非线性数据,并包含大量噪声。首先应用LLE降维方法,将七维数据映射到二维空间上,LLE算法可以保留局部线性特征,故二维空间上局部数据为线性相关。再应用K-means聚类方法将数据分为3类,取3类数据中数据量最多的一类为计算样本类。虽然风电机组中存在大量非线性特征,但线性相关数据依然占大多数。
在两个数据类别的边界处往往会存在分类错误的情况。计算样本类中心点和该类中距离中心最远的点,设其距离为Hm;设置函数D(HS),代表以聚类中心点为中心、半径为HS圆中的数据,即为辨识样本数据。该辨识样本数据中绝大部分为线性相关的,所以可以进行线性计算。其中HS为

式中:σ为(0,1)数值。
在计算过程中,σ从小到大依次取值,得到多个辨识样本数据,分别应用线性计算方法根据式(15)进行向量φ的计算。
3 改进多学习率线性神经网络
3.1 线性神经网络
线性神经网络是一种只有输入层和输出层的神经网络模型。该方法给定一个权值初值,通过输出与实际偏差,改变权值,使输出值接近实际值。
3.2 多学习率改进方法
在权值调整的过程中,线性神经网络的学习率是不变的。每个权值的学习率都为同一个数,但权值之间可能相差比较大。如果选取同一个学习率在调整效果上可能会使较小的系数偏差过大,而且学习率的选择也与数据每次迭代计算次数有关。如果学习率过大,对于较小的参数可能会出现调整量过大,出现局部最优值,所以在应用一个时间段的数据计算时,学习率的选择不应过大,每次调整值较小,并且与整个调整次数一致。
令τ为迭代次数。对于权值Pτ={pτ1,pτ2,pτ3,…,pτn},学习率ζ取值组数为Q(可取Q=3)。权值调整次数为KN(可取KN=1 000),则在第τ次迭代过程中,对于第kn(kn=1,2…KN)组学习率,可按如下方式设置。
首先,获取权值矩阵中的最大数值及索引位置ε:

当满足‖pτ′-pτ‖<ψ时,计算过程结束,否则令pτ+1=pτ′,继续迭代。
在学习率每次调整时都应用此方法进行学习率的动态调整。
3.3 双馈风机参数辨识
应用LLE算法降维和K-means算法进行分类后,得到o组辨识样本数据,根据式(8)应用改进多学习率线性神经网络方法进行计算。将向量φ作为线性神经网络多学习率改进方法的权值P,向量MN=[MN2(k),MN3(k)…MN7(k)]为改进多学习率线性神经网络方法的输入U,MN1(k)为输出期望。计算完成得到o组结果,即为待辨识控制器的PI参数。
辨识过程如图1所示。
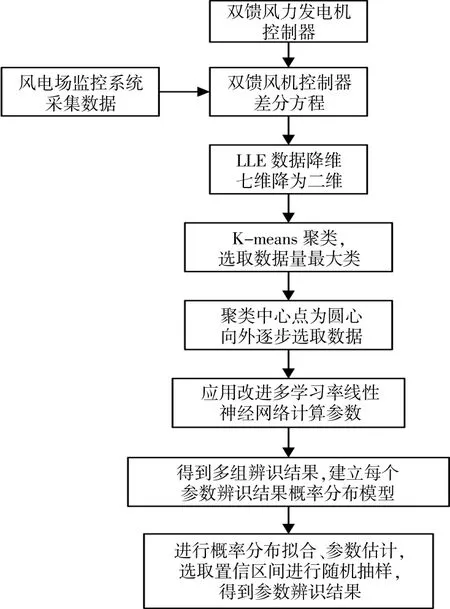
图1 参数辨识流程图Fig.1 Parameter identification flow chart
对o组PI参数辨识结果分别建立概率分布模型,根据各个参数的辨识结果概率分布模型,设置某一置信度,得到辨识结果的置信区间。为得到准确辨识结果,在置信区间内进行随机抽样得到一确定的辨识结果。
4 算例及验证
以华北某风电场运行数据为例,进行双馈风力发电机转子侧控制系统参数辨识。辨识参数为转子侧控制器PI参数,即:比例环节系数kp(β)(β=1,2,3,4)和积分环节系数ki(β)(β=1,2,3,4)。在风机正常运行过程中,根据风机数学模型采集相应电流电压等数据,对采集的电流电压等数据进行解耦,带入差分方程;应用LLE降维方法得到二维数据,再应用K-means算法进行聚类,得到三类数据;提取数据量最大的类为计算样本类,取σ初值为0.1、终值为0.9,变化量为0.01,得到90组辨识样本数据;再分别应用改进多学习率线性神经网络和单学习率线性神经网络进行计算,得到90组辨识结果。另外,应用最小二乘法根据差分方程进行直接辨识计算,得到一组辨识结果,进行对比。
采集数据包含了风速变化信息,本算例数据采集周期为3 ms,采集时间为12 s,采集数据量k为4 000,风速变化为8~10 m/s。
图2为七维数据通过LLE降维,并进行Kmeans聚类后的结果图。
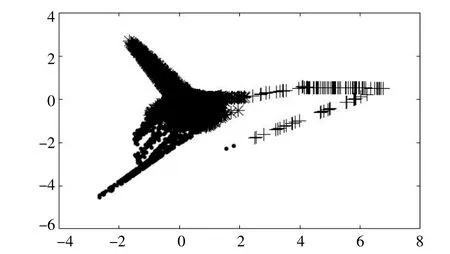
图2 LLE降维后二维聚类结果图Fig.2 Two-dimensional clustering result diagram after LLE dimensionality reduction
由图2可知,将七维数据映射为二维数据后可以直观的观察分类状况。图2中:标识为“+”的数据为噪声,可见噪声数据被明显地分离出来;标识为“·”的数据为各种非线性数据,由于存在饱和、强耦合情况,数据较为分散;标识为“*”的数据为须要提取的计算样本类数据,图中该类数据比较集中,数据间存在线性关系,也有利于提取辨识样本数据,进而有利于线性计算。
图3,4为应用数据降维聚类后,应用改进多学习率线性神经网络的方法进行参数辨识的90组结果。
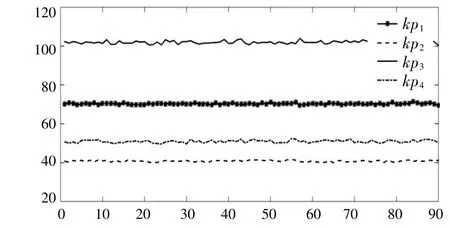
图3 比例环节参数辨识结果图Fig.3 Parameter identification result of scale link

图4 积分环节参数辨识结果图Fig.4 Parameter identification result of integration link
由图3,4可知,比例环节系数的辨识结果浮动较小,积分环节系数的辨识结果浮动相对较大。参数本身数值越大,在辨识过程中辨识的精度越高。参数数值较小,辨识的精度会相对较低,辨识结果会在一定范围内浮动。
图5,6为8个辨识参数90组辨识结果的概率分布图。由图5,6可以得到,8个参数辨识结果的概率分布近似于高斯分布。

图5 比例环节参数辨识结果概率分布图Fig.5 Probability distribution of parameter identification results of proportional link
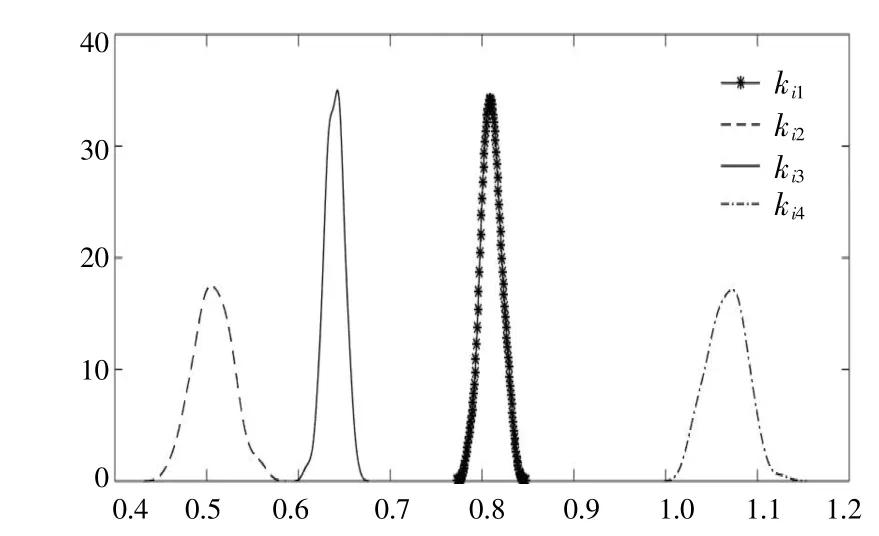
图6 积分环节参数辨识结果概率分布图Fig.6 Probability distribution of parameter identification results of integration link
应用高斯分布对辨识结果的概率分布进行拟合,采用极大似然估计法对各个参数辨识结果的概率分布进行参数估计。选取置信度为0.9,得到参数辨识结果的置信区间。在各个参数的置信区间内进行随机抽样,得到一个确定的辨识值。
采用最小二乘法、数据降维聚类后应用单学习率线性神经网络、改进多学习率线性神经网络等3种方法计算对比,如图7,8所示。

图7 3种方法比例系数辨识结果对比图Fig.7 Comparison chart of identification results of three methods
图8 积分系数辨识结果对比图Fig.8 Comparison chart of three methods for identification of integral coefficient
由图7,8可以看出,最小二乘法计算结果与实际值相差较大,单学习率线性神经网络方法相较于最小二乘法要精确,而改进多学习率线性神经网络方法相对于单学习率线性神经网络辨识更加准确。
图9为3种方法对于实际值的辨识误差率。
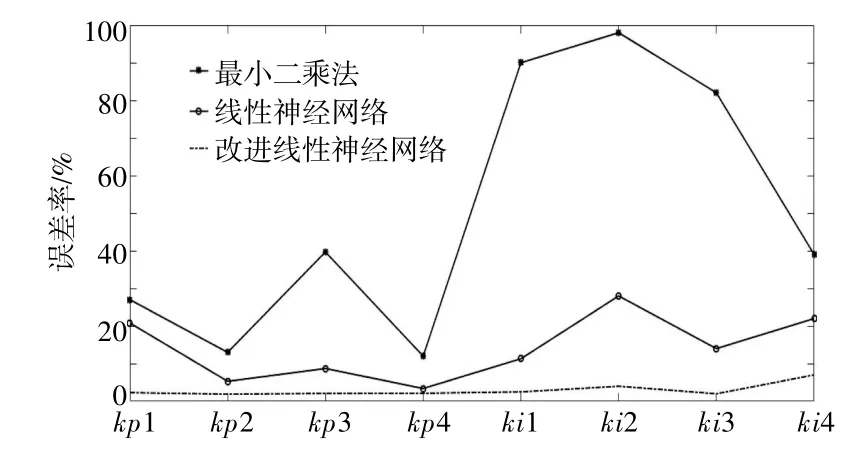
图9 参数辨识结果误差率Fig.9 Error rate of parameter identification results
由图9可以看到,应用降维聚类多学习率线性神经网络方法的辨识误差率基本低于5%,而应用降维聚类单学习率线性神经网络对积分环节的辨识误差率部分超过20%,最小二乘法则部分超过80%。
3种方法所辨识参数对应的仿真结果如图10所示。

图10 辨识参数对应风机输出功率的仿真结果Fig.10 Simulation results of wind turbine output power corresponding to identification parameters
由图10可见,本文所提方法对应辨识参数的仿真曲线与实际曲线非常接近,而其他方法存在较大偏差,由此验证了本算法的有效性。
5 结论
针对双馈风机发电系统控制器参数辨识的准确度问题,提出了一种基于数据降维聚类与改进多学习率线性神经网络的计算方法。在算法中,首先用LLE算法进行数据降维,进而用K-means聚类进行线性数据提取,再基于改进多学习率线性神经网络进行线性计算,得到参数辨识结果的概率分布,在一定置信区间进行抽样,从而确定参数辨识结果。通过双馈风力发电机实测数据测试表明,本方法具有较高的辨识精度。
该方法对于直驱风机、光伏发电系统的参数辨识也有一定的参考价值。
