采用多尺度近邻体素特征的TLS林分点云分类
2021-12-18邢艳秋蔡硕汪献义
邢艳秋,蔡硕,汪献义,2
(1.东北林业大学 森林作业与环境研究中心,哈尔滨 150040;2.长沙智能驾驶研究院,长沙 410000)
0 引言
激光雷达是以发射激光束探测目标的位置、速度等特征量的雷达系统,依据搭载平台的不同可分为星载雷达、机载雷达、车载雷达、地面激光雷达等多种类别,这些激光雷达在相应的应用场景中都具有特定的优势[1]。相较而言,地面激光雷达(terrestrial laser scanning,TLS)能够获取扫描目标的高精度三维信息,被大量应用于众多三维建模的逆向工程中[2]。在林业研究中,有较多研究者基于地面激光雷达展开林业参数提取[3]、树干提取[4]与建模[5-6]、单木分割[7]等研究,将点云快速地分为地面、树干与枝叶可为上述研究奠定基础,所以研究林分点云分类具有重要意义。
现阶段点云分类多分为逐点分类、基于分割的分类与基于多实体的分类。逐点分类需要遍历点计算特征,在大场景分类过程中这种特征计算方式的效率较为低下[8];基于多实体的分类方式多应用于机载点云分类的研究[9-10],且过程较为复杂。基于分割的分类有基于分割面片辅助的点云分类与基于体素分割的点云分类。Zhang等[11]研究了基于分割面片辅助的点云分类,其在分类过程中首先采用区域生长法将点云分割成相对独立的面片,然后计算这些面片关于几何特性、辐射强度特性、回波特性与拓扑关系的一系列特征训练支持向量机实现点云分类[12]。这种分割方式多适用于面特征比较多的城市场景中,林地中局部点云形状多不规则,使用基于分割面片的分割方式往往不能达到较好的分割效果,且在大场景中面片分割效率较低。基于体素分割的方式过程较为简单且能够兼顾算法效率,如Wang等[13]研究了基于体素分割的城市建筑分类,其在分类过程中先将点云分割到相对独立的体素中,然后设计了相关先验信息定义这些体素的垂直与水平特性,并依据垂直与水平特性将这些体素融合为一个个体素群,最终通过计算这些体素群的线度、面度与球度实现城市建筑群的分类。分析分类结果发现,这种分割方式基本能够完全识别高大建筑群,而对一些相对低矮的建筑识别率仅为86.3%,这主要是由于高大建筑面特性明显,低矮建筑形状大多较为复杂,并不是规则的线状、面状或球状。相较于城市建筑,林地目标形状多不规则,实现点云分类挑战更大。
综上所述,本研究提出一种基于多尺度近邻体素特征的地基激光雷达林分点云分类方法。在分类过程中,基于特征选择获得了能够满足与本研究分类场景的六个特征,然后通过多尺度分割点云并分别计算相应尺度下的每个体素与九个近邻体素构成的局部点的特征获得高维特征,最终利用该特征训练LightGBM(light gradient boosting machine)获得分类器模型,并将其应用于测试集实现点云分类。在大场景分类过程中,特征的计算效率尤为重要,为此本研究实现了两种特征估计方式,分别为基于分割的近邻体素特征与基于分割的近邻体素重心特征。
1 数据与方法
1.1 数据与样本
本研究的地面激光雷达设备为徕卡Scanstation C10,具体仪器参数见表1。

表1 三维激光扫描仪技术参数
本研究的数据采集自东北林业大学实验林场的蒙古栎(quercusmongolica)人工林(图1)。该样地地形简单平坦,林下灌木较少,单木间隔约为3 m,单木胸径与树高均值分别为13.55 cm与9.98 m。数据采集时间为2016年6月,样地尺寸为20 m×20 m,在扫描过程中共架设五个扫描站,即A1~A5站(图2),A1~A4站分别架设在方形样地的四个角点,A5站为样地中心,扫描角度为360°,其余测站为定向扫描。

图1 蒙古栎人工林
图2 扫描站布设
训练分类器过程中需要用到训练样本、验证样本与测试样本。训练样本用于训练分类器,验证样本用于判断分类器训练过程中是否出现过拟合或欠拟合。鉴于五个扫描站扫描数据属于一块样地,数据相似,扫描站A5的数据量更大,所以训练样本与验证样本从A5扫描站数据中随机抽取10%,扫描站A1~A4中选择一个站作为测试样本。
1.2 研究方法
1)点云特征。点云特征是点云分类任务的关键,好的特征对不同的类别区分度较高[14]。在目前的研究中,大多数研究者是根据经验尽可能多地构造特征训练分类器[15-16]。本研究数据量较大且需要计算不同尺度下的点云特征,若构造较多的经验特征对运行内存要求较高且对分类器训练效率影响较大[17]。针对这一问题,在处理某一固定场景下的分类任务时较多研究者往往通过特征选择实现特征降维,这样在避免盲目构造特征的同时又能够兼顾分类器性能。本研究先构造19个经验特征,然后使用xgboost特征选择技术实现特征降维[17],在保证分类器性能的前提下在特征选择过程中保留了六个特征,其定义如式(1)所示。
(1)
式中:Pz表示当前点Z坐标;NDSM表示归一化数字表面模型;Gz表示当前点地面投影点Z坐标估计值;V表示垂直度;Oλ表示全向方差;λ1>λ2>λ3>0为近邻点主成分分析对应的归一化特征值;ΔZk-NN表示临近点的Z坐标最大差值,其中k-NN表示快速最近邻搜索;Zmax与Zmin表示对应临近点的最大最小Z坐标值;λ1,2D与λ2,2D表示近邻点在二维XY平面上XY轴坐标值的主成分分析对应的特征值。
2)多尺度体素分割构造特征。点云搜索方式是构造特征效率的关键。考虑到在局部较小空间中的点数据多属于同一类别,点特征基本相同,所以有研究者考虑使用体素分割进行点云分类。那么在计算特征的过程中每个体素只需要计算一次特征即可,这样既可以有效克服数据冗余又可以提升特征的计算效率。同时,在分割过程中要考虑分割尺度,小尺度的点云分割能够分离出空间分布相对紧密的类别,大尺度的点云分割可以将连通域较宽的类别分割成相同的体素。所以,使用单一尺度分割点云很难兼顾点云的局部类别与整体分布。采用点云的多尺度分割不仅可以解决上述问题,而且能增加特征维数,有利于提高分类器的性能。
在点云分割过程中会存在两种情况。情况一是单一体素数据较少,无法完成特征计算,这主要由孤立点或局部点集密度较为稀疏造成;情况二是单一体素会将部分连通区域分割开来,造成估计的特征稳定性降低,比如某10 cm厚度的树干可能被分割到两个10 cm×10 cm×10 cm的体素中。基于上述考虑,本研究在每个分割尺度中遍历体素中心,搜索九个近邻体素内的点集参与计算当前体素点特征,这样既能克服单个体素数据较少的情况又能兼顾局部点集的连通性。同时,考虑到近邻体素的重心能够近似局部点集的分布,为了提升特征计算效率,用近邻体素点云计算当前体素点特征的同时还实现了使用近邻体素重心估计当前体素特征。
本研究的体素分割基于八叉树实现[18]。考虑到林地单木间平均间隔与局部连通区域的树干长度,分割尺度为2×3ncm(n∈0,1,2,3),即4个分割尺度,最小最大体素边长分别为2 cm×2 cm×2 cm与54 cm×54 cm×54 cm。基于特征选择获得的六个特征中特征Z与NDSM不需要通过近邻关系构造,所以仅有剩下的四个特征参与多尺度分割。在遍历四个尺度分割计算特征之后,每个点使用18个特征表示。
3)LightGBM分类器。LightGBM[19]是一种轻量级改进的梯度提升决策树(gradient boosted decision trees,GBDT)[20],且通过计算样本在每个决策树的得分和来估计类别。现阶段众多基于决策树的分类器都能够较好地完成分类任务,比如经典的随机森林[21]或者被较多机器学习研究者视为baseline的xgboost[22]。但在大数据集分类任务中,这些分类器训练效率往往较慢。针对这一问题,LightGBM中引入了数据压缩与特征降维技术,以减少很小的精度为代价提高算法效率。特征降维是将数据集中的稀疏互斥特征合并为一个特征。本研究没有稀疏特征,所以不使用LightGBM的特征降维技术。

在训练决策树过程中,叶子节点的分裂方式非常关键,LightGBM通过信息增益来控制节点分裂。信息增益指决策树在某一节点按某一特征将样本分配到左右子节点对目标函数的贡献,信息增益越大表示按照这种分裂方式的置信度越高。在训练过程中,LightGBM要先遍历特征计算使信息增益达到最大的分裂点,最终依据特征索引与使信息增益达到的最大的分裂点将样本分配到左右子节点中。本研究在训练LightGBM时使用100个梯度决策树,每个决策树最大叶子节点数量设置为64个。
1.3 精度评价
在完成分类之后,需要采用一定的准则定性分析分类器的精度。衡量分类器性能,分别从分类器的准确率、查准率、召回率、F1分数与F1均值(MF1)进行评估。准确率用于分类器表现直观估计,查准率与召回率用于评价分类器在某类上的表现。由于难以用两个量衡量分类器在某一类别上的表现,研究者引入F1。通常还采用MF1衡量分类器的总体表现,其值越大表示分类器分类效果越好。
2 结果与分析
本研究分别实现了基于多尺度近邻体素点云特征与基于多尺度近邻体素重心点特征的林分点云分类研究。本节就基于不同特征的分类器性能及分类性能较好的分类结果展开分析。
2.1 特征计算性能及基于其的分类器表现
表2统计了多尺度近邻体素点特征与多尺度近邻体素重心特征的特征计算性能,其中涉及到占比的部分均为相应特征计算方式中测试集与训练集的比值;效率提升表示基于近邻体素重心的特征计算方式关于测试集与训练集节约的特征计算时间与基于近邻体素点特征计算方式所用时间的比值;体素数量表示四个体素分割尺度下得到体素数量的和;特征估计用时表示相应数据集特征计算耗时。仔细分析在对应的计算方式中两种数据集的特征估计用时比值与点云数量的比值近似,与体素分割数量占比差异较大,表明两种特征计算方式下特征计算效率与点云的数量正相关。由表2易知,基于近邻体素重心的方式特征计算效率明显提高,在训练集与测试集中基于近邻中心计算特征的方式特征计算效率分别提高22.22%与22.58%,效率提升的幅度相近,说明特征计算效率提升程度也与点云数量正相关。

表2 不同特征计算性能分析
表3统计了两种特征计算方式下LightGBM关于测试集的分类结果,基于近邻体素点与近邻体素重心点特征的分类器准确率与MF1分别为0.968 4、0.972 3与0.964 6、0.969 3。两种分类器的性能相近,同时容易发现基于这两种特征训练分类器均能够较好地实现林分点云分类任务。在本研究中,以特征选择获得的六个特征为基础进行多尺度体素分割计算获得的特征几乎能够正确识别所有的地面点,错误识别树干与枝叶的点数量占比均为0.05。表4统计了基于两种特征分类器应用于测试样本的混淆矩阵与错估统计。其中,错估总占比表示错估数量与测试样本数据总量的比值。不难发现,分类器能够识别大多的地面点云,错估大多来自于枝叶与树干类别,部分地面与树干产生错误估计。

表3 不同特征的分类器性能
2.2 分类结果分析
综合2.1节分析发现,基于近邻体素点特征训练的分类器性能略优于基于近邻体素重心点特征的分类器,所以此处仅针对基于前者特征的分类器表现展开探讨。图3分别展示了本研究的训练样本(图3(a))与分类器关于测试集的分类结果(图3(b)),图中灰色、红色与绿色分别表示地面、树干与枝叶。图4给出了部分分类结果的细节图(黑框表示错分类别区域),颜色表示的类别与图3相同。

图3 训练样本与分类结果
由图3(b)易知,分类器基本正确识别了大多地面、树干与枝叶三个类别的点云。由表4易知,大多错分来自树干与枝叶,在地面与树干间也存在部分错分的状况。结合图4(a)发现,错分的地面与树干主要来自于两个类别在空间的交汇处。由于扫描仪的垂直视场有限,距离扫描仪较近的单木多没有树冠数据,结合图4(c)发现,在没有树冠且附近枝叶较多的单木顶部容易将树干标记为枝叶点,在附近没有枝叶数据的单木顶部则能够正确识别树干(图4(b))。在树干产生枝干处,分类器也容易将部分枝叶点标记为树干点(图4(d)),这主要由于部分枝干点特征与树干相近造成。同时分析图4的细节图容易发现,基于分割特征的分类器标记的点云类别间能够保证较好的连通性。
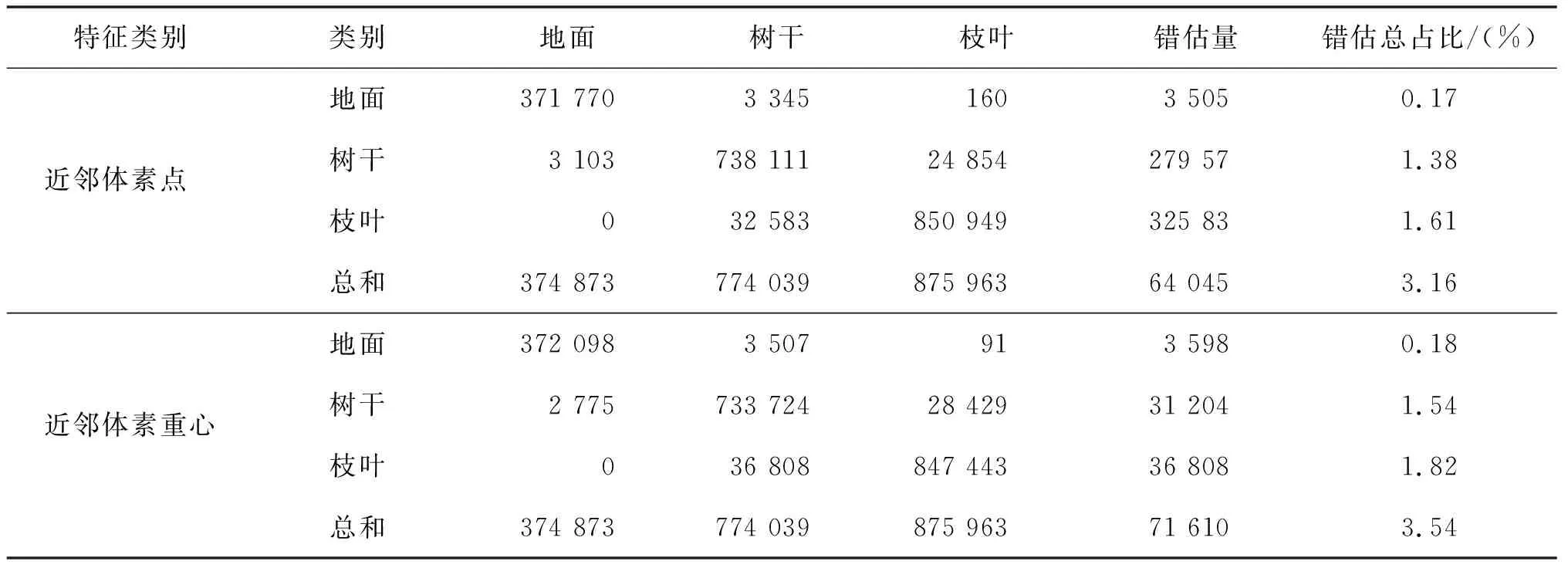
表4 测试样本的混淆矩阵与错估统计

图4 分类结果细节图
3 结束语
本研究通过计算不同分割尺度下近邻体素点集构造18维特征训练LightGBM分类器实现了林分地基激光雷达点云的分类。在特征计算过程中,为了尽量提高特征计算效率,实现了基于近邻体素点与基于近邻体素重心的两种特征计算方式,得到以下结论。
1)基于多尺度分割计算的近邻特征能够有效应用于大场景的林分点云分类任务。本研究分类准确率MF1分别达到96.84%与96.23%,地面点识别率接近100%,错分类主要集中在树干与枝叶间。
2)基于多尺度分割计算点云特征效率较高,同时使用对应分割尺度下近邻体素重心近似体素点参与特征计算可有效提高特征计算效率。本研究的训练集与测试集数据量分别为3 521 927与2 024 875,基于多尺度近邻体素点计算特征用时分别为54 s与31 s,每秒可以稳定完成65 000点特征计算;基于多尺度近邻体素重心计算计算特征用时分别为42 s与24 s,每秒可以近似完成84 000个点特征的估计。
3)基于本研究构造的特征训练分类器在类别间的空间交汇处容易产生错误估计。结合图4的错分细节图易知,本研究错误分类多集中于类别间空间存在交集处。
相较于Wang等城市建筑目标分类研究,本研究点云分类方式过程简单,特征计算过程中引入参数较少。同时,人为建筑场景中,大多目标局部空间呈现状或面状分布,本研究林分点云分类的场景变化较大需要考虑的因素多,点云分类任务稳定性较高,分类准确率稳定,居于0.96以上。本研究在特征计算过程中仅需要引入分割尺度及搜索对应尺度搜索近邻体素数量,在运行成本允许的情况下可以构造较多尺度特征,兼顾了点云的局部与整体分布。同时,引入的近邻体素重心近似局部点云分布计算特征的方式可有效提高特征计算效率,在分类过程中基于其训练的分类器准确率与MF1为0.964 6与0.969 3,分类器性能相较于基于近邻体素点特征的分类器仅降低了千分级,在大数据集大场景的点云分类任务中具有一定的借鉴意义。
同时,本研究的基于分割计算特征过程中需要考虑近邻体素搜索数量,这个参数对分类器性能与特征计算效率均有较大的影响。一般而言,这个值相对获取的大点集多计算的特征较为稳定,然而太大则容易降低特征计算效率。所以,为了兼顾特征计算效率与分类器性能,本研究近邻搜索值设置为9。相对而言,这只是一个经验值,本研究并没有设计实验探究其最优值。本研究的错分类多集中于类别间空间交汇处,在后续的研究中,将从特征搜索方式及构造更好的特征方面展开探究,以期进一步提高点云分类准确率。
