词向量文本挖掘技术在建筑设施管理应用研究
2021-12-17蒋海刚
蒋海刚

摘要:该文挖掘是自然语言处理技术(NLP)在人工智能应用领域的一个重要落地场景。文章以建筑设施运维工单短文本分类器构建为背景,分析了具有稀疏特征的短文本分类技术难点,提出了基于Word2vec算法模型构建建筑运维工单文本词向量特征,通过有监督机器学习模型将强关联规则加入短文本分类器训练过程中,通过短文本词向量特征改善,优化短文本分类准确率、召回率和 F1 值。通过验证,建筑运维工单专业自动分类识别成功率达89%,为分析建筑运维服务诉求提供数据依据和基础。
关键词: 词向量;短文本挖掘;非结构化数据;建筑数据管理
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2021)33-0022-04
开放科学(资源服务)标识码(OSID):
1引言
近年來,随着信息技术的日新月异,尤其是人工智能技术的发展,在建筑运维领域也开始探索应用人工智能赋能建筑数字化运维服务。建筑运维工单是建筑运维过程中描述性的非结构化文本数据,其中包括对建筑维保对象故障、专业、维修记录的描述性信息。传统的基于结构化数据的数值分析方法较难适用于这类非结构化文本数据的分析和挖掘工作[1]。因此需要引入自然语言处理(NLP)中的文本挖掘技术,将文本数据进行结构化的向量处理,形成工单文本的词频、词性、关键词等特征标注信息,并对建筑运维工单文本进行语料库构建,应用机器学习算法对文本完成预训练结果集输出,形成建筑维保工单文本语义的深度挖掘能力,最终输出建筑运维工单可视化分析报告,为建筑运维服务提供主动式建筑设施维保建议,是当前建筑运维领域应用自然语言处理(NLP)技术进行建筑运维非结构化数据应用的人工智能应用场景之一[2]。
2建筑运维工单文本特征
建筑运维工单主要分为维修工单、维保工单。维修工单内容通常是用户报修信息和维修人员维修记录其工单文本长度统计一般都在200字符以内,具有明显的短文本特征如图1所示,且属于非规范性口语化严重的短文本[3]。建筑运维工单文本描述通常不遵守语法规则;且工单描述信息由于字数少,本身所包含的有效信息也较少,这样造成工单文本的统计特征非常稀疏,并且特征集的维数非常高,因而通过机器理解短文本面临极大的技术挑战[3]。同样在建筑维保工单短文本挖掘过程中会遇到上述数据扰动的干扰,影响建筑运维文本语义真实意图的理解。短文本的特征使得传统基于词袋模型文本挖掘方法很难对其进行有效建模。近年来基于深度学习算法的应用成熟在一定程度上提升了对于语义特征稀疏的短文本挖掘效率。
3 短文本挖掘技术研究
文本挖掘是非结构化数据处理的一个重要分支,其本质是将文本数据通过向量化方式形成结构化文本信息描述,进而提炼出有价值的知识信息。文本挖掘主要步骤包括数据收集、文本预处理、数据挖掘和可视化、搭建模型和模型评估 [4]。目前文本挖掘技术已经在关键词提取、文本自动摘要、文本聚类、文本分类、文本主题模型、文本观点抽取、情感分析等领域得到广泛的应用。
词向量(Word Embedding)是为了让计算机能够处理的一种词的表示。短文本分类的关键在于词向量矩阵的降维处理,短文本向量表达特征有高维、稀疏等问题,通过降维处理可以减小数据维度和需要的存储空间、节约模型训练计算时间、去掉冗余变量、提高算法的准确度[1]。
4 文本分类方法研究
文本分类是指将文本描述归类到已知的文本类别中,其主要包括文本预处理和分类器模型构建两个过程,文本分类流程如图2所示。
4.1文本向量化预处理技术
文本挖掘是自然语言处理在主要研究内容,并且是人工智能和机器学习算法的主要应用场景。近年来,文本向量化研究已备受关注,目前大致有三种常用技术路径可供选择:基于规则特征匹配的方法;基于传统机器学习的方法(特征工程 + 分类算法);基于深度学习的方法(词向量 + 神经网络)。Word2vec是Google研究团队里的Tomas Mikolov等人于2013年的两篇研究论文中提出的一种使用一层神经网络高效训练词向量模型的方法 [5]。Word2vec 最有价值的是让不带语义信息的词带上了语义信息,其次把词语从 one-hot encoder 形式的表示降维到 Word2vec 形式的表示,是一种研究短文本分析的常用方法[5,6]。
4.2 文本语料库构建技术研究
文本向量化需依次经历分词、词向量化和词向量组合的过程。目前主流的词向量方法都存在不同的缺陷。现有的向量化方法是依赖于词袋模型产生文本向量表达,然而短文本中有些词与文本要义关联度较低,但对文本用向量表示的影响较大。因此需要抽取短文本关键词并以此和TF-IDF权重组合形成文本向量更能反映短文本语义的特征信息。因此本次研究的对象建筑运维工单短文本挖掘,通过构建建筑运维语料库提升文本向量化的准确度其技术实现方式,如图3所示。
4.3文本分类器模型构建
分类器模型构建过程即通过相应的算法,根据文本预训练后的生成训练结果生集,依据训练结果进行文本分类测试验证分类器构建的有效性。目前国内中文文本分类研究主要集中在朴素贝叶斯算法、K近邻算法、支持向量机算法、决策树算法等[5]。
4.4 分类器模型效果评估
用来评价文本分类器的指标非常多,在实际应用中需要根据场景来选择甚至是设计评价分类器的指标。在本文研究中结合建筑运维工单文本的特征,采用准确率(Accuracy,简记为A)、精确率(Precision,简记为 P)、召回率(Recall,简记为 R)、 F1 测量值(简记为 F1)4项指标用于评估分类器效果[7],相关概念和指标定义如下:
TP:被模型预测为正的正样本 TN:被模型预测为负的负样本
FP:被模型预测为正的负样本 FN: 被模型预测为负的正样本
准确率(Accuracy) 公式(1)表达式为:
精确率(Precision) 公式(2):表达式为:
召回率(Recall)公式(3):表达式为:
F1 测量值(F1 Score)公式(4):表达式为:
上述分类评估指标各有优缺点。召回率主要评估分类器的查全程度,精确率主要评估的是分类器预测的准确能力。二者指标通常有冲突,需要通过F1值进行平衡[8]。建筑运维工单维修专业分类器关注的是分类的维修专业是否精确,因此在本研究中主要侧重于对分类器模型的精确度的评估,通过F1分数平衡其与召回率的关系。
5 建筑运维工单文本挖掘应用实践
5.1 工单文本预训练
本研究以某建筑运维公司2020年1月-2020年12月期间产生的工单文本为文本预训练数据集,从工单内容出发进行中文分词、词向量计算以及TF-IDF(词频-逆向文件频率)统计,工单训练数据集记录数为19,029条。本次研究使用中文分词工具是Jieba分词,使用Python 3.8編写工单预训练脚本文件。通过完善和加入用户自定义专业词库和停用词库来优化中文分词结果,最终分词得到 49,760个建筑维保词汇,将分词结果去除停用词处理后,再进行特征降维处理,结合建筑运维专业特征从词性、词频、权重以及词义与词频关系等多维度进行特征信息选择[7],所形成的建筑运维专业特征语料分布,如图4所示。
5.2 建筑维修专业分类器模型构建
5.2.1 训练集数据选取
在建筑运维服务项目中,用户通过工单反映出的建筑设施问题多种多样,为统一、准确、详细地反映用户的建筑运行诉求,本研究以某建筑机电运维项目在建筑运维服务过程中产生的“热点词汇”为文本研究对象,如“脱落”“漏水”“空调”“照明”等,如图5所示。随机从工单中筛选出含“热点词”样本工单作为工单专业分类的训练集。
5.2.2 分类器模型确定
通过Python脚本调用文本挖掘算法库构建4个备选分类器模型,并对比分析不同分类器的分类效果,对比结果如图6所示:
由图7的可知,从箱体图上可以看出Sklearn Linear SVC (线性支持向量机)的准确率评估值达到90% 以上命中率,基于模型有效性评估结果,对比研究认为Linear SVC使用One-vs-rest来生成分类器,通过构造N个分类器,可以获取的建筑工单文本的比较重要的向量化特征[5,9]。因此,综合平衡后确定Linear SVC分类模型作为建筑运维工单专业分类器模型选择。
5.3 建筑运维专业分类评估及结果
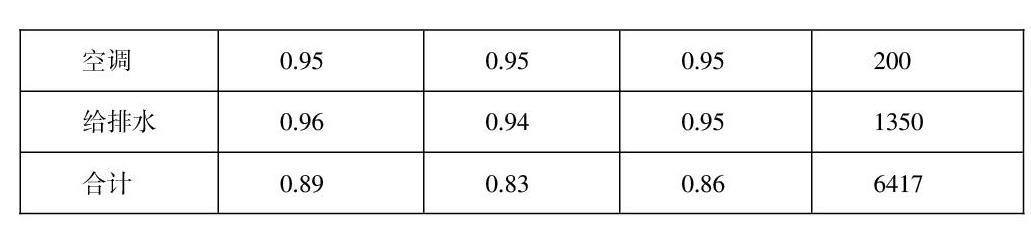
从分类结果中随机抽选 12,500张工单进行效果评估,评估结果如表1所示。
从表1的分类结果分析,模型查全率(Recall)达到50%,错误率33%。
从分类器评估结果分析该工单分类训练集识别出正确工单专业分类的概率仅为67%。因此对建筑工单专业分类模型进行调优。模型调优主要从三个方面进行改进:
1) 完善建筑运维专业词库和停用词库使中文分词结果更精准;
2) 根据工单词频统计选择更精准的特征词强化工单分类训练;
3) 调整Linear SVC模型参数,增加训练迭代次数优化分类器预测效果。
分类器模型调整后,结果评估见表2。
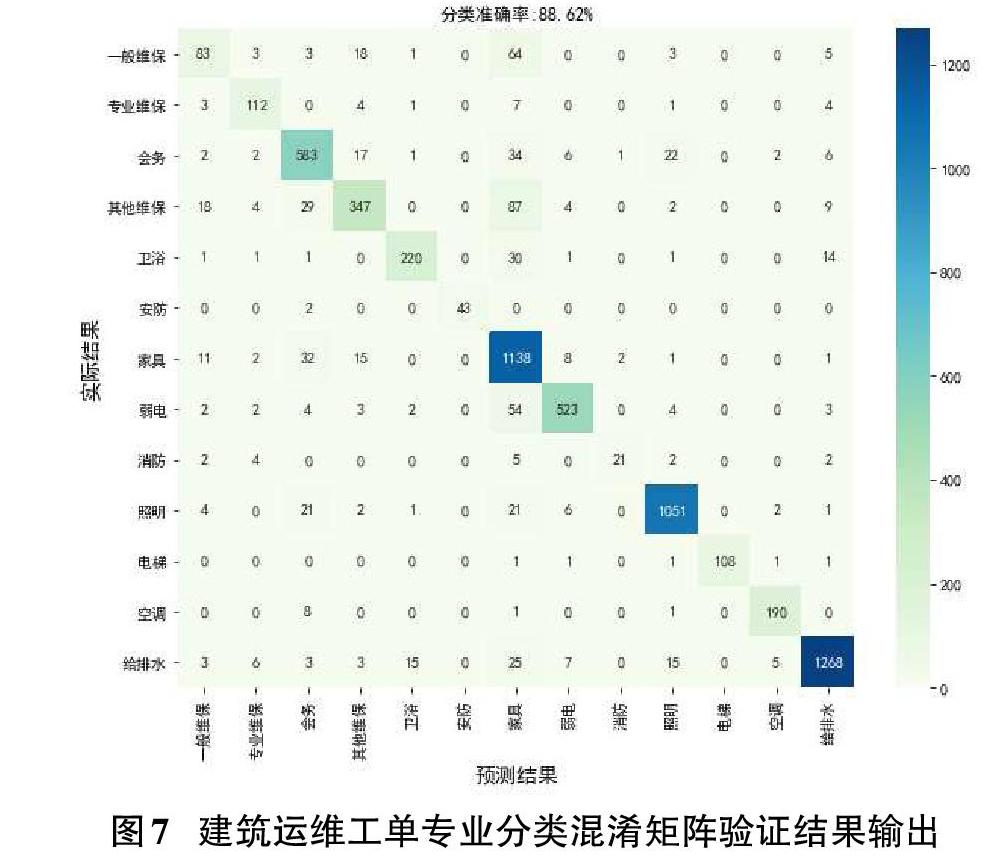
由表2可知,经过模型优化后,准确率和查准率分别提高至 89%、83%,在业务可接受范围内。通过验证对比认为,调整后的分类器模型对全量工单专业分类测试结果为正确率为88.62%,共准确识别出工单维修专业16,935张,工单专业类型识别情况如图7所示。
5.4 建筑运维工单专业自动分类器应用展望
以建筑运维质量评估可视化分析为例,在原始报告中对于工单专业的分类是以建筑系统分类为依据,例如电气、暖通、给排水、弱电等,但实际运行环境中存在着“工单是属于某建筑系统但维修专业是归属于其他专业的情况”。而用户表达的建筑问题会被忽略或者隐藏在系统分类标签下得不到反映。同时,在分配工单任务时,受到人员直觉经验、业务环境因素和固有的系统分类方法影响,使得维修专业分类结果偏离工单所需反映的问题实际。经工单专业分类器自动分类后,用户表达的诉求和反映的问题可直接以工单维修专业维度进行分类统计并进行可视化报告呈现,如图8所示。通过试点项目验证,通过维修专业分类可视化呈现,试点项目主动发现和洞悉了建筑物维修重点专业,通过文本数据可视化提升了建筑物运维服务质量和效率。
6 结束语
本文研究在当前建筑运维工单统计分析不充分,主动式建筑运维服务能力待提升的背景下,提出基于词向量Word2vec的文本挖掘技术,对建筑运维服务过程中形成的报障工单进行短文本分析应用研究,形成面向建筑运维短文本挖掘实验性研究结果。通过研究验证认为:基于工单专业分类器的算法实现可以成为工单自动化派单功能实现的基础。验证结果表明:工单专业识别准确率达到89%。原型系统验证了从工单语义描述出发,准确地将隐藏在海量工单中的关键信息进行数据特征描述和呈现,降低人为介入工单专业标识的技术可行性。此外,从分类后的工单中还能进一步提炼出建筑运维服务中相关事件的关联影响程度,通过工单溯源分析出建筑运维服务活动中存在的问题,为建筑运维服务质量的改进提供数据依据。
参考文献:
[1] 王煜,邓晖,李晓瑶,等.自然语言处理技术在建筑工程中的应用研究综述[J].图学学报,2020,41(4):501-511.
[2] 王烟.自然语言处理技术在建筑使用后评价中的应用[J].南方建筑,2019(1):82-87.
[3] 章昉,颜华驹,刘明君,等.基于词项关联的短文本分类研究[J].集成技术,2015,4(3):69-78.
[4] 李颢,张吉皓.基于文本挖掘技术的客服投诉工单自动分类探讨[J].移动通信,2017,41(23):66-72.
[5] 苏玉龙,张著洪.基于关键词的文本向量化与分类算法研究[J].贵州大学学报(自然科学版),2018,35(3):101-105.
[6] 余传明,李浩男,安璐.基于多任务深度学习的文本情感原因分析[J].广西师范大学学报(自然科学版),2019,37(1):50-61.
[7] Minaee S,Kalchbrenner N,Cambria E,et al.Deep learning—based text classification[J].ACM Computing Surveys,2021,54(3):1-40.
[8] 邹云峰,何维民,赵洪莹,等.文本挖掘技术在电力工单数据分析中的应用[J].现代电子技术,2016,39(17):149-152.
[9] Tang D Y,Wei F R,Yang N,et al.Learning sentiment-specific word embedding for twitter sentiment classification[C]//Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1:Long Papers).Baltimore,Maryland.Stroudsburg,PA,USA:Association for Computational Linguistics,2014:1555-1565.
【通联编辑:闻翔军】
