一种基于SSD的行人检测改进算法
2021-12-13李国进韦慧铃艾矫燕陈延明
李国进,韦慧铃,艾矫燕,陈延明
(广西大学 电气工程学院, 广西 南宁 530004)
0 引言
行人检测是利用计算机视觉技术判定图像或视频中是否存在行人并获取其精确位置[1],在自动驾驶、智能机器人、智能交通、智能安防等领域广泛应用,是近年来计算机视觉和数字图像处理领域的研究热点之一。由于在同一图像中,远、近距离行人目标位置所占比例差异较大,在检测过程中可能会忽略小尺寸目标造成漏检。另外存在一些客观因素给检测过程带来一定的难度,例如图像中复杂环境、光线、遮挡、部分重叠等。因此,对复杂环境下多个行人目标检测进行研究具有一定的意义和价值。
目前,行人检测算法分为传统算法以及深度学习算法。传统行人检测算法包括Haar小波特征[2],可变形部件模型(deformable part model, DPM)[3],HOG+SVM方法[4]等。其主要思想是基于人工提取图像的特征,通过特征距离或机器学习工具对提取的特征进行识别[5]。在复杂场景中,行人存在姿态变化、遮挡等因素,人工难以设计一种具有极高鲁棒性的特征,因此导致检测效果往往不理想[6]。而基于深度学习的行人检测算法解决传统目标检测算法对目标行人特征提取不全面造成检测精度和速度不高的问题。它是由卷积神经网络搭建的自动学习图像中目标特征的算法模型,首先通过卷积层设定各种卷积核的参数权重并在原图像上进行滑动获取特征图,随后通过池化层对所获取的特征图进行缩放得到不同尺寸的特征图结果,有利于不同尺寸的目标提取,并通过反向传播不断优化网络参数获取最优模型,最后筛选出置信分数高的预测框并对其进行检测。该类算法主要分为两类[7]:一是two-stage系列以R-CNN、Faster R-CNN[9]为代表的两步走的区域算法。在行人检测算法中,文献[8]首次提出基于深度学习目标检测的R-CNN算法,在PASCAL VOC数据集测试中,检测平均精度从35.1%提升到53.7%。针对上述文献行人检测精度低的问题,文献[9]提出基于Fast R-CNN中引入区域网络的Faster R-CNN算法,对行人类别的检测平均精度为76.7%,速度为7帧/s。现如今,针对分辨率较低、小尺寸行人检测存在误检和漏检问题,文献[10]通过迭代回归获取精确的候选边框位置,并利用混合相似性距离函数和中心损失函数提高对不同行人特征的区分能力,以达到对目标行人检索的目的。二是one-stage系列以YOLO、SSD为代表的端到端的回归类算法。文献[11]中提出利用回归思想的YOLO算法模型,经训练后测试得出行人类别的检测平均精度为63.5%,速度为45帧/s。文献[12]提出将YOLO回归思想和Faster R-CNN中锚框机制相结合的SSD(single shot multibox detector)算法,经训练后测试得出行人类别的检测平均精度81.4%,速度为46帧/s。在如今的行人检测算法中,针对行人检测的精度和速度不能同时兼顾的问题,文献[13]通过k-means算法获取特征图中的锚框位置,实现自动学习行人特征,从而达到提高检测精度与速度的目的。这以上两类算法中,SSD算法在行人检测中的整体效果较为优势。但由于SSD算法的浅层网络深度浅,特征提取能力较差,并且在特征提取过程中,算法中的深层网络与浅层网络之间没有任何信息交融,使得浅层卷积层在特征提取的能力上大大减弱,对复杂场景中多尺度变化行人目标检测会出现误检或漏检的问题。文献[14]针对此问题改进深层网络输出的特征图,在检测部分使用不同的卷积层分别进行检测后再融合输出的结果,提升小目标行人的检测性能。
本文针对SSD算法在复杂场景下的多尺寸变化行人检测中出现的误检或漏检问题,提出一种改进SSD的行人检测算法,将SSD算法的基础网络VGGNet16[15]替换成基于ResNet101[16]设计的算法。它是将ResNet101最后的全连接层替换为卷积层,解决全连接层限制输入图像尺寸的问题,并增加两个卷积层构建六个不同尺寸的特征图提取部分,提高对不同尺寸的行人目标特征提取能力。为了使得浅层网络的特征提取能力进一步提高,将基础网络与特征图金字塔网络[17](feature pyramid networks, FPN)网络相结合,进行卷积网络之间相融合,提高浅层网络的特征提取与提高深层网络对于目标的定位能力,从而达到提升检测精度的目的。在实验部分采用平均精度和每秒检测的帧数来评估算法模型,并验证改进算法的可行性。
1 SSD算法
SSD算法是以VGGNet16为基础的回归算法。原始的VGGNet16主要由13个卷积层(用Conv3-x表示)、5个池化层(用Max Pool-x表示)、3个全连接层(用FC-x表示)组成。总体的网络主要分为5个块结构和全连接层,其中每个模块是由卷积层与池化层构成,VGGNet16网络结构如图1所示。

图1 VGGNet16网络结构
SSD算法是将VGGNet16的两个全连接层替换为两个卷积层,并在其后添加3个卷积层和一个平均池化层作为附加的特征提取部分,构成金字塔网络结构。该算法在图像输入时,通过以VGGNet16为基础改进的Conv4_3、Conv6、Conv7、Conv8_3、Conv9_3、Conv10_3、Pool的五个不同参数设置的卷积层和一个池化层计算得出不同尺寸的特征图结果,其包含不同大小的先验框对真实行人目标进行匹配。特征图在经过检测层输出图像中每个目标的预测框与之对应的置信度后,经过非极大抑制值(non-maximum suppression, NMS)筛选出置信分数较高的预测框,减少预测框与真实框之间的损失输出一个较为精确的检测结果。SSD网络结构如图2所示。

图2 SSD网络结构
输入图像经过SSD算法卷积层与池化层的计算时,网络中不同的卷积层和池化层输出6个不同尺寸特征图结果,其包含生成不同尺寸、不同长宽比的先验框[18]。每个特征图中的先验框尺寸计算公式如下:
(1)
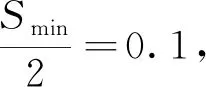
(2)
(3)
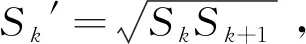
在复杂环境下的行人检测,由于图像中的远、近距离尺寸变化较大的行人目标,不能使用同一尺寸进行特征提取,使得对小目标的检测不利及定位不准确。SSD算法的提取特征部分是利用不同卷积层中不同尺寸的区域选择,使得网络能很好地预测不同尺寸的行人目标框。在分析SSD网络结构图时,附加特征提取网络的特征图不断减小,如第一个特征提取层Conv4_3所处深度较浅,特征提取和表达能力有限,而较深的特征输出层又主要负责检测较大尺寸的目标,因而导致SSD算法对于小目标的检测性能较差[19]。SSD算法特征提取的卷积层之间毫无联系,导致算法在目标特征提取时对于复杂环境下的小目标特征提取的能力不够,因此会在复杂环境下多行人目标检测中容易出现误检或漏检的情况。
2 改进的SSD的行人检测算法
2.1 基础网络的设计
首先对SSD算法的基础网络部分进行设计,本文将VGGNet16替换成ResNet101。ResNet101的网络结构如图3所示,它是由Conv1、Conv2_x、Conv3_x、Conv4_x、Conv5_x五个卷积层和全连接层组成。其中,Conv4_x是采用残差网络中的瓶颈(Bottleneck)搭建的卷积方式,在网络中使用了下采样(Down Sampling)方式,进行两种不同的卷积形式的计算,并在路径B中加入卷积层使得网络深度加深的同时,也能提升卷积神经网络计算能力的效率。

图3 ResNet101网络结构
改进算法是以ResNet101为基础,将ResNet101最后的全连接层替换为卷积层,解决全连接层对输入图像大小限制的问题,使得网络能获取不同尺寸的特征图,以构建网络中对不同尺寸的特征图检测部分。ResNet101同样分为5个卷积层,但每个卷积层的深度都高于VGGNet16,使得网络学习能力增强,进一步提高对图像中的行人目标特征提取能力。ResNet101在卷积层中引入残差模块,解决网络模型加深时会导致训练退化的问题,最后该网络的卷积计算效率较快,减少算法模型的冗余。
为了进一步提高改进算法的网络特征提取部分的能力,尤其是对网络中浅层特征提取网络深度的提升,改进的SSD算法将基础网络特征提取部分调整后,特征提取网络的维度都为256。表1为设计的ResNet101网络特征提取部分的卷积层与原SSD算法中以VGGNet16为特征提取部分的卷积网络的对比。

表1 SSD算法中VGGNet16与改进算法中ResNet101的对比
2.2 附加特征提取的设计
FPN是一种利用多尺寸特征提取的卷积网络,通过简单的网络连接并融合,提升对小尺寸的目标的检测能力。该网络包括两个计算过程:一是自下而上:通过卷积神经网络的前向传播计算,特征图的尺寸经过卷积层的计算会越来越小,但维度不变;二是自上而下:通过高层特征图进行上采样,与自下而上生成的相同尺寸,并且维度相同的特征图进行融合。
改进的SSD算法设计的附加特征提取网络相邻尺寸特征图融合示例如图4所示,利用FPN网络自上而下的横向连接性能,将ResNet101的特征提取部分(Conv3_x~Conv8_x)进行卷积网络融合。首先Conv8_x(1×1, 2 048)通过(1×1, 256)的卷积计算,降维转换为1×1×256,再经过卷积(3×3,256)缓冲计算,输出1×1尺寸的特征图;其次,Conv7_x的特征提取,通过卷积(1×1, 256)计算,得到降维后3×3尺寸的特征图,与降维后的M8经过加倍,得到相同尺寸特征图后再相加得到M7,之后经过卷积(3×3, 256)缓冲计算,输出3×3尺寸的特征图,其Conv3_x~Conv6_x的输出过程同Conv7_x;最后附加特征提取网络卷积层的输出不同尺寸但维度都是256的特征图,使得网络对于复杂的行人特征学习能力更强。

图4 相邻尺寸特征图融合示例
2.3 改进SSD的行人检测算法的网络结构
改进SSD的行人检测算法的整体网络设计是以ResNet101为基础,并引入FPN网络进行卷积融合特征图结果,增强网络的学习能力,以达到提高检测行人精度的目的。它是利用卷积层(Conv6_x)替换原ResNet101中最后的全连接层(FC6),并增加两个卷积层(Conv7、Conv8),获取Conv3_x、Conv4_x、Conv5_x、Conv6_x、Conv7_x、Conv8_x六个不同尺寸特征图结果,提升网络对图像中目标的精确分类与定位的能力。为了再次提高改进算法网络中浅层卷积对小尺寸的行人特征提取能力,在算法的附加特征提取部分添加FPN网络进行融合,利用FPN的自上而下的横向连接性能,构建一个丰富语义信息的特征表示,使得融合后的特征具有更强的描述性,有利于小目标的检测。将输出不同尺寸的特征图结果进行融合后经过检测部分生成行人目标的预测框与之对应的目标置信分数,并通过MNS筛选后得出置信分数较高且位置精准的预测框获取最终的检测结果。改进算法的网络结构如图5所示,其中左下部分线条为改进的SSD算法的基础网络部分(ResNet101),右上部分线条部分为改进的SSD算法设计的特征提取部分。

图5 改进算法的网络结构
3 实验分析
3.1 行人数据集
PASCAL VOC 2007数据集是具有代表性的公开的多类别数据集,标注了行人、车辆、牛等20个检测类别。本实验提取了VOC数据集中的行人类别图像与之相对应的xml文件作为行人数据集的一部分,其图像中的行人目标尺寸变化较大,适合本文实验训练。另一部分则是由INRIA数据集构成,它是目前应用最广泛的静态行人数据集。该数据集中图像场景复杂,行人多为站立姿势,标注准确。因此,本文实验的行人数据集由VOC数据集与INRIA数据集组成,将行人数据集的标注格式统一为VOC格式(图像+相应图像标注xml文件)。融合的行人数据集共4 010张图像,其中2 905张源于PASCAL VOC 2007数据集的行人图像作为实验的训练集,1 105张图像源于INRIA行人数据集作为实验的测试集。融合行人数据集是由在复杂场景下尺寸变化大、单个行人或多个行人的正面或背面的图像所组成,如图6所示。

图6 融合数据集部分图像
3.2 评价标准
本文使用检测精度和速度对目标检测算法模型进行评估,其采用平均精度(Average Precision,AP)来评估改进的行人检测算法模型在融合的行人数据集中检测行人目标类别的性能效果;使用每秒检测帧数(frames per second,FPS)来评估改进的行人检测算法模型检测速度。定义TP为正样本检测正确的个数;FP为负样本检测错误的个数;FN为正样本检测错误的个数,则检测目标的准确率P和召回率r的计算公式(4)、(5)如下:
(4)
(5)
其次假设行人检测样本数为N,其中检测到的个数为M,可以获得响应的召回率r,对于每个召回率r的最大精度公式(6)计算如下:
(6)
则检测行人目标精度公式如下:
(7)
3.3 实验环境与训练参数设置
训练算法模型的实验环境在电脑系统Windows10,内存12 GB,项目环境Python3.7以及项目框架PaddlePaddle2.0.0下,添加实验模型为Faster R-CNN算法、YOLO系列算法、SSD算法、改进算法;基本网络结构模型为VGGNet16、DarkNet、CSPDarkNet、ResNet101、FPN网络模型。
本文在融合行人数据集上,将改进的SSD算法与原SSD算法、Faster R-CNN算法、YOLOv3算法、YOLOv4算法的主流行人检测算法进行实验训练并对比。改进算法的训练过程如图7所示。

图7 改进算法模型的训练流程
算法训练迭代次数为30 000,其中每1 000次保存算法训练模型,在此过程比较得出最好的算法模型进行保存。在训练过程中采用动量优化方法—Momentum获取最优化算法模型,其具有加速梯度下降、减少波动使得参数更新的方向稳定的作用。假设在融合数据集中训练部分取出n个样本为n={X(1),X(2),…,X(n)},其对应真实目标的值分别为{Y(1),Y(2),…,Y(i)},则Momentum优化参数计算公式如下:
(8)
式中,υt为t时刻积攒的加速度。Wt为t时刻的卷积核权重。α为动量的大小设置为0.9,ηt为学习率,ΔJ(Wt,X(is),Y(is))为损失函数J(W)关于参数模型的偏导数,即随机选择的一个梯度方向。
改进算法在训练网络初始化输入训练参数见表2,包括网络的学习率、学习率分段衰减、优化动量、权重的衰减以及最大的迭代数。

表2 训练参数设置
3.4 实验结果分析
为了验证提出改进SSD的行人检测算法的可行性,本文在融合的行人数据集进行训练并测试实验,其实验训练后的融合测试数据集检测结果见表3,分别有YOLOv3、YOLOv4、Faster R-CNN、SSD算法与改进的算法在融合行人数据集中测试集的检测结果。

表3 融合测试数据集检测结果
由表3的算法检测结果可知:通过各算法在检测融合的行人数据集中测试部分,改进的算法整体效果要优于其他类型的行人检测算法,检测结果平均精度为87%,速度为175FPS。与主流算法YOLO系列对比:总体上比YOLOv3的效果更佳,在检测速度和精度上有大幅度的提升,而YOLOv4算法在检测精度上与改进算法相同,但是改进算法的检测速度提升132FPS,实时性较具优势;与同为以ResNet101为基础网络的Faster R-CNN算法相比较,改进算法的检测精度和速度分别提升了17%和161FPS,说明不同框架类型的算法,one-stage系列的算法效果性能较佳;改进的算法与原SSD算法相比较,检测精度提升6%,表明改进算法的基础网络ResNet101与FPN网络相融合,整体上优于其他主流行人检测算法,进一步提高了算法中卷积网络提取特征的能力,并提高改进算法的检测精度。
为进一步验证改进的算法在行人检测中的有效性,在复杂场景环境下对不同尺寸行人目标的检测来验证改进的算法模型的有效性,各算法的检测图像结果如图8所示。

(a) YOLOv3
图8为各行人检测算法检测不同图像的检测结果:在复杂场景中,图8(a)、图8(b)为YOLO系列算法检测结果,都出现了漏检和误检的情况。在第一幅图像中对小尺寸行人目标的检测结果较佳,但对大尺寸行人检测需进一步改进,在第二幅图像中都误将雕塑当作行人特征并将其识别为行人;图8(c)为Faster R-CNN算法检测结果对不同尺寸的行人检测效果较好,但对于相似的行人特征,误将雕塑当作行人特征,对检测过程造成一定影响,使之不能准确检测真实行人目标从而造成误检;图8(d)为SSD算法也将雕塑当作行人造成误检,同时在行人有遮挡的情况下也不能准确识别行人目标;改进算法在检测结果中,能正确区分行人与雕塑的目标特征,在不同的图像检测中表现效果较佳,能准确提取行人目标的特征并能准确识别出不同尺寸的行人目标。实验结果表明改进算法中基础网络ResNet101与FPN网络相结合对于不同尺寸目标特征提取能力效果较佳,提高了算法卷积网络提取小目标特征的能力,进一步提高了改进算法在行人检测中,对于不同尺寸的目标检测的可行性。
4 总结
本文提出基于SSD的行人检测改进算法,提高了基础网络对于不同尺寸的行人目标的特征提取能力,解决VGGNet16在SSD算法中对于小目标的特征提取能力弱的问题,并提高对相似目标的区分能力,能较准确地检测行人目标,提高行人检测的平均精度。后续工作将根据不同的基础网络,尝试与其他网络结构相结合,如何选择更加优秀、合适的基础网络与SSD算法相匹配,将整体上提高行人检测的精度与速度,并提高算法模型的广泛能力是今后的主要研究目的。
