面向案件审判难度预测的神经网络模型研究
2021-12-13王平辉
王 悦,王平辉,许 诺,陈 龙,杨 鹏,吴 用
西安交通大学 智能网络与网络安全教育部重点实验室,西安 710049
在经济快速发展,社会急剧转型的背景下,公民的权利意识逐渐增强,法院收案量高速增长。相关数据显示,截至2019 年7 月31 日,全国法院新收案件总数同比增加189.0 万件,上升14.54%(http://www.xinhuanet.com/2019-07/31/c_1124822269.htm),“案多人少”矛盾异常突出。准确高效地识别案件审判难度,对于缓解“案多人少”矛盾,提高审判效率具有重要意义。
审判难度预测是指在给定起诉状案情描述文本的情况下,自动预测案件审判难易程度。现阶段,案件审判难度预测工具严重依赖专家知识,其实现方式为:(1)根据办案专家经验,人工构建审判难度判别规则库。(2)对任意受理的案件,匹配相关规则,实现对案件审判难易程度的划分[1]。
现有方法过于依赖专家经验,由于不同专家对案件难易程度的判断标准具有主观性,存在较大差异,导致不同专家对相同案件的审判难度判断结果存在较大偏差。此外,现阶段审判难度预测相关研究较少,而此项工作的顺利开展对于缓解法院“案多人少”矛盾极其重要。
针对上述问题,结合审判难度预测的定义,本文将其归结为自然语言处理中的文本分类问题。通过综合考虑不同专家的判断结果对原始案件的审判难度进行标注,利用文本分类的方法,解决不同专家下,相同案件审判难度偏差大的问题。
常见的文本分类方法是基于序列建模的。然而,起诉状本身是半结构化文本,由判别要素组成,且判别要素间具有明显的结构独特性和逻辑依赖性。具体地,如图1 所示,以民事案件为例,起诉状的内容包括原告情况、被告情况、诉讼请求及事实理由四大要素,各要素位置结构相对固定:首先描述原告情况、被告信息,接着表明诉讼请求、事实理由,要素间具有明显的结构独特性;“原告、被告”是“诉讼请求、事实理由”的诉讼主体,后者内容紧紧围绕前者展开,存在着严格的关联关系,具有明显的逻辑依赖性。

Fig.1 Sample of indictment图1 起诉状示例
本文在序列建模的基础上,充分考虑起诉状中审判要素间的结构独特性和逻辑依赖性,提出了一种新的神经网络模型——基于掩码注意力拓扑关联网络的审判难度预测模型(mask-attention and topological association network,MAT-TAN)。
具体地,该模型首先采用掩码注意力网络(maskattention,MAT)聚焦审判要素特定位置,提取各要素全面、准确的特征信息,实现案情细粒度分析。其次利用拓扑关联网络(topological association network,TAN)对审判要素间的司法逻辑依赖关系进行建模,并有效融合不同要素的特征,最终实现案件审判难度预测。本文在某法院提供的真实数据集上进行了实验,实验结果表明,在审判难度预测任务上,本文方法与现有文本分类方法相比,宏平均F1 值提高0.03 以上。
本文的贡献主要包括:(1)首次将深度学习方法应用到审判难度预测任务中,实际应用中仅需输入案件内容即可预测审判难度,相比于现有方法,本文提出的MAT-TAN 模型无需人工构建审判难度判别规则库,进一步解放人力,并有效解决现有方法过于依赖专家经验导致预测结果不准确的问题。(2)相关审判要素的引入,使得神经网络具备一定的可解释性,有利于MAT-TAN 模型在各级法院推广应用。(3)基于法院真实数据的实验结果表明,本文提出的MAT-TAN 模型与基准的文本分类方法相比,宏平均F1 值提升了0.036,在审判难度预测任务上具备较好的使用效果。
1 相关工作
审判难度预测任务可归纳为自然语言处理中的文本分类问题,且与近年来利用人工智能算法辅助司法办案的研究息息相关。本章从文本分类和司法智能化系统两方面对相关工作进行介绍。
1.1 文本分类
随着深度学习在自然语言处理领域(natural language processing,NLP)研究的不断发展,卷积神经网络(convolutional neural network,CNN)[2]、循环神经网络(recurrent neural networks,RNN)[3]等各种深度学习算法被广泛应用于文本分类任务中,与传统方法相比,此类算法在许多类型的文本分类任务中都取得了优异的成绩[2-4]。
Kim[4]将CNN 模型推广用于文本分类,他直接将卷积应用于句子,这种方法通过最大池化操作获得最重要特征,轻松处理高维数据,但忽视了文本本身的顺序性质。RNN 能够很好地表达时序信息,近年来出现了多种改进方法,包括长短时记忆网络(long short term memory networks,LSTM)[5]、门控循环单元(gated recurrent unit,GRU)[6]、双向长短时记忆网络(bidirectional LSTM network,Bi-LSTM)[7]等。注意力机制[8]的出现进一步提升了深度神经网络在语义层面的理解。随之而来的层次注意力模型(hierarchical attention network,HAN)[9]在词语层和句子层分别应用注意力机制,进一步提高文本分类准确率。自注意力机制[10]是注意力机制的改进,其减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性。来自变换器的双向编码器表征量(bidirectional encoder representations from transformers,BERT)[11]的出现,刷新了11 个NLP 任务中的成绩,是一项里程碑式的工作。然而上述模型在审判难度预测任务中未考虑起诉状内要素间的结构独特性和逻辑依赖性,丢失了文本重要的结构信息和逻辑信息,很难准确识别案件的难易程度。
1.2 司法智能化系统
随着人工智能技术的飞速发展,利用深度学习算法辅助司法办案的问题引起了众多研究者的关注,为法院智能信息化应用带来了巨大便利。近些年的主要研究包括:(1)判决结果预测[12]。利用深度学习的算法学习以往案例,将案情描述作为输入,预测案件判决结果,为法官判案提供辅助性建议。(2)相似案件智能推荐[13]。利用深度学习的算法,寻找与待判案件事实相同或相似的其他案件,将其作为判案结果的参考,保证同案同判。(3)智能问答服务[14]。对于一个法律问题,利用深度学习算法检索相关法律条文,为法律专业人士和社会公众提供便捷、高效的服务。
虽然深度学习算法在司法智能化系统中取得了优秀的效果,然而针对审判难度预测任务,目前尚未有人使用此类方法进行分析。
2 问题定义
本章首先介绍了法院提供真实案例数据集的形式,然后定义了案情描述序列的概念和审判难度的划分标准,最后给出了审判难度预测问题的定义。
具体地,X=[x1,x2,…,xn]∈Rn×d,其中,xi∈Rd是案情描述中第i个单词的词向量,n是案情描述文本中的单词个数,d是词向量嵌入的维数;y∈[y1,y2,y3],其中,y1表示复杂案件,即案情疑难、复杂,社会影响较大的案件,y2表示普通案件,即案情普通,社会影响一般的案件,y3表示简单案件,即案情简单,事实条理清楚的案件。
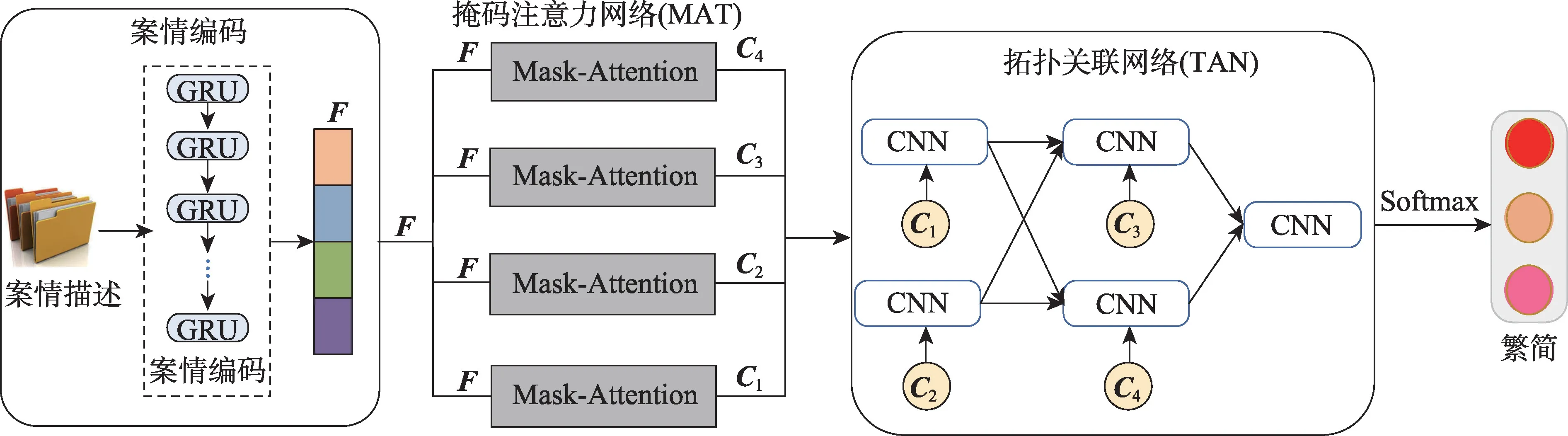
Fig.2 Framework of MAT-TAN图2 MAT-TAN 模型结构图
本文的目标是训练一个神经网络模型MAT-TAN,对于受理的任意案件Xnew,自动预测案件审判难度ynew。
3 MAT-TAN 模型
本文通过对起诉状的研究,结合案件难易审判要素,提出一种基于掩码注意力拓扑关联网络的审判难度预测模型(MAT-TAN),如图2 所示,此模型由案情编码模块、掩码注意力网络和拓扑关联网络三部分组成。其中,案情编码模块通过对原始案情描述序列编码,初步实现案情文本特征提取的功能;掩码注意力网络通过掩码机制和注意力机制,聚焦审判要素结构特征,实现对案情描述文本特征的细粒度分析;拓扑关联网络,通过充分考虑起诉状中各审判要素间的拓扑关系,关联融合不同要素及其依赖特征,实现案件审判难度预测。
3.1 案情编码模块
为初步提取案情描述文本特征,本文选择GRU网络[6]作为案情编码器。在时刻t∈[1,n],对于给定的输入xt,GRU 的隐藏层输出为ht,其计算过程如下所示:

其中,rt、zt分别代表重置门和更新门的输出结果,⊙表示对应元素相乘操作,σ是sigmoid 激活函数,W、U和b为连接两个时刻的权重矩阵和偏置向量。
对所有案情描述序列X=[x1,x2,…,xn]进行分析,得到案情文本初始特征向量F={h1,h2,…,hn}。
3.2 掩码注意力网络
起诉状是半结构化文本,其案情描述内容包含原告、被告、诉讼请求和事实理由,每个审判要素侧重内容不同且对应位置不同。不同审判要素的细节将深刻影响案件难易程度,如原告数量、被告数量、诉讼请求中标的大小等对预测案件难易程度起决定性作用。
在获得初始特征向量的基础上,为实现对各审判要素的细粒度分析,本文提出一种掩码注意力网络(MAT),如图3 所示。其中的掩码机制扮演了一个智能门控者的角色,起到了聚焦审判要素特定位置的作用,结合注意力机制,实现了各审判要素全面、准确的特征提取。
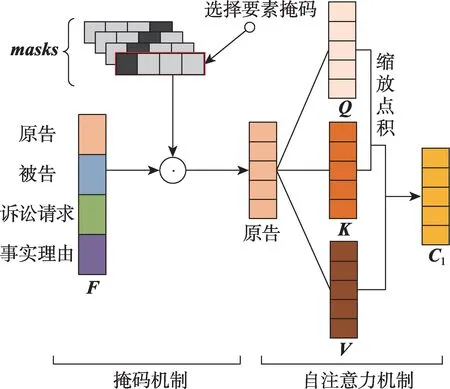
Fig.3 Framework of MAT图3 MAT 结构图
3.2.1 掩码机制
在获得初始特征向量F的基础上,为了更好地聚焦每个审判要素对应案情描述的位置结构特征,本文定义了一组可训练的掩码序列集masks,masks=[m1,m2,…,me]∈Re×n,其中e是审判要素的数量,n是起诉状内案情描述的长度。
对于任意审判要素k,如图3 所示,利用一个可训练的掩码序列作为其案情描述的位置捕获器,实现聚焦审判要素特定位置的作用。详细分析如下。
首先,初始化可训练掩码序列mk,聚焦要素特定位置。

其中,β∈{0,1},β=1 表示位置z与要素k对应关系成立。
将案情文本初始特征向量F与mk对应元素相乘,实现聚焦审判要素特定位置特征的作用。

其中,为要素k的掩码输出向量。
3.2.2 自注意力机制
在获得要素k的掩码输出向量的基础上,本文结合自注意力机制[10],提取对要素k有重要意义的信息。如图3 所示,将线性变换,得到Qk、Kk、Vk三个矩阵。具体地:

3.3 拓扑关联网络
图1 中,“原告、被告”是“诉讼请求、事实理由”的诉讼主体,它们之间存在着严格的关联依赖关系,这些关系作为审判要素的补充信息,对案件审判难度的准确预测具有重要意义。
在获得各要素掩码注意力输出向量的基础上,为正确识别并有效融合各审判要素间的司法逻辑依赖,本文提出一种拓扑关联网络(TAN),如图4 所示,通过建模各审判要素间的依赖关系并融合各审判要素的编码特征,实现案件审判难度预测。
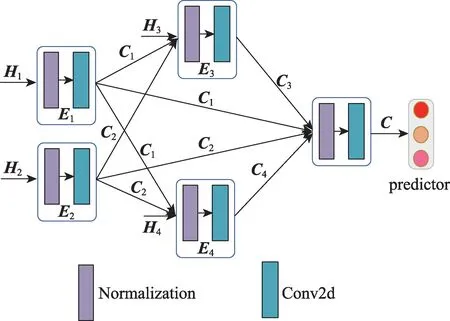
Fig.4 Framework of TAN图4 TAN 结构图
3.3.1 拓扑关系建模
为得到各审判要素间的拓扑依赖关系,假设各审判要素间的依赖关系形成一个有向无环图,用Ei→Ej定义要素j依赖于要素i,用Dj={Ei|Ei→Ej}定义依赖集合。具体地:

其中,j=1,2,3,4 时,Dj分别为“原告、被告、诉讼请求、事实理由”四大审判要素间的依赖情况。
3.3.2 特征融合
在获得要素k掩码注意力输出向量Hk的基础上,为综合考虑此要素及其依赖关系,本文遵循拓扑顺序,将Hk及其依赖要素编码向量进行拼接,并利用卷积等非线性组合操作对其建模,实现特征充分融合。具体计算公式如下:

其中,INk为要素融合输入向量,concat代表拼接操作,F(·)代表非线性组合函数,Ck为要素k的特征融合输出向量。
进一步地,定义F(·)为批量归一化(batch normalization,BN)[15]和卷积操作(convolution,conv)[4]连续执行的组合函数,则F(·)可表示为:

3.3.3 审判难度预测
在对各审判要素处理完毕之后,本文拼接所有审判要素的特征融合输出向量,其次利用非线性组合函数F(·),获得拓扑关联输出向量。

最后,TAN 网络利用非线性分类器softmax 得到审判难度预测向量,实现案件审判难度预测。
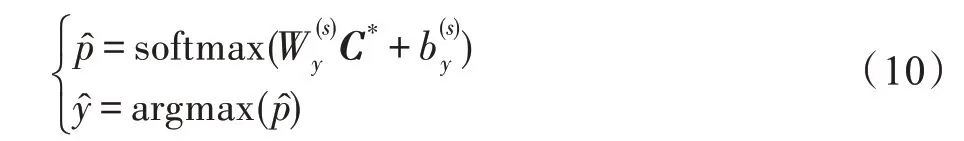
4 实验与结果分析
4.1 实验数据集
实验数据来自某法院实际审判数据,共涉及41 060 条民事案件起诉状(civil complaints,CLCT)。案件审判难度标注时,综合考虑不同专家的判断结果,保证每个案件的标注由三位专家预测结果综合判定,从而解决不同专家下,相同案件审判难度判断结果偏差大的问题。其中,训练集占80%,验证集占10%,测试集占10%。实验数据集如表1 所示。

Table 1 CLCT statistics表1 CLCT 数据集说明 条
4.2 实验设置和评估指标
本文设计了6 组对比实验,使用了不同的文本分类模型作为基准,分别为传统机器学习中的Naive Bayes[16]、SVM(support vector machine)[17]和深度学习中的GRU[6]、TEXT-CNN[4]、HAN[9]和BERT[11]。
具体实验中,本文采用Adam 算法[18]作为优化器,设置学习率为0.001,Dropout 比例[19]为0.5,批处理大小为64。所采用的评价指标包括平均准确率(averaged accuracy,Acc)、宏平均精度(macro averaged precision,MP)、宏平均召回率(macro averaged recall,MR)和宏平均F1 值(macro averagedF1,F1)。
4.3 实验结果
在相同的实验数据集、实验设置和评估指标下,模型对比实验结果如表2 所示。
由实验结果得知,针对案件审判难度预测任务,深度学习模型的效果整体上优于传统机器学习算法,这表明深度学习模型能更好地提取传统机器学习算法提取不到的文本信息。与基准模型相比,本文提出的MAT-TAN 模型在四种评价指标上分别提高0.032、0.037、0.009、0.036,这表明本文的模型更加适用于审判难度预测任务。

Table 2 Comparison result of models表2 模型对比结果 %
其原因在于,MAT-TAN 模型能够充分考虑起诉状中审判要素间的结构独特性和逻辑依赖性,更好地获取基准模型学习不到的文本细粒度结构信息和语义信息,这些信息在审判难度预测任务中是极其重要的;此外,MAT-TAN 模型通过细粒度分析不同审判要素特征并融合其拓扑关系,使获得的特征更加全面、具体,进而有利于案件审判难度的预测。
为了进一步说明考虑不同要素及其拓扑关系的意义,本文对MAT-TAN 模型进行消融实验。为了验证掩码注意力网络MAT 的有效性,本文构建了一个去除掩码注意力网络的模型(表3 中的“-no MAT”),它直接在案情文本初始特征向量F上应用TAN 来获取最终向量表示C。为了验证拓扑关联网络TAN 的有效性,建立了一个无关联网络的模型(表3 中的“-no TAN”),它直接拼接每个要素的特征向量作为最终向量表示C。消融实验结果如表3 所示。

Table 3 Ablation experiment analysis表3 消融实验分析 %
从表3 可以看出,MAT 和TAN 都有效地提高了案件审判难度预测任务的性能,这充分表明MAT 网络和TAN 网络对提高案件审判难度预测任务的准确率是极其重要的。
消融实验下,仅考虑MAT 网络能够实现细粒度聚焦不同审判要素特征的目的,而仅考虑TAN 网络,丢失了不同要素特征提取的过程,无法编码不同审判要素间的拓扑依赖,故其实验结果低于前者。这充分说明了细粒度分析不同审判要素特征,融合不同审判要素间拓扑关系的重要性。
接着,本文将语料库进一步划分,以测试模型在不同训练样本数量下的效果。
从图5、图6 可以看出,与基准模型中效果较好的HAN 和TEXT-CNN相比,本文提出的MAT-TAN 模型在不同数量的训练集下均能取得较好的效果。证明MAT-TAN 能够从训练样本中挖掘更多隐含信息,具有很强的鲁棒性。
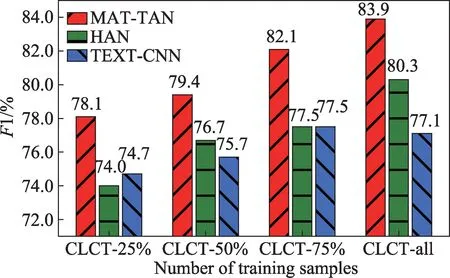
Fig.5 F1 of models under different training samples图5 不同训练样本数量下模型的平均F1 值

Fig.6 Acc of models under different training samples图6 不同训练样本数量下模型的平均准确率
最后,本文对MAT-TAN 模型的性能进行了评估,以进一步探讨其优劣。
从图7 可以看出,与基准深度学习模型相比,MAT-TAN 模型虽然准确率高,但是训练耗时较长,仅次于BERT。然而,MAT-TAN 模型测试单批数据(批处理大小为64)所需时间为0.45 s,与基准模型相差不大,这意味着MAT-TAN 模型在实际使用过程中,预测效率不会产生过多影响。
以上实验结果有力地证明了MAT-TAN 模型在解决审判难度预测问题上的使用价值和可行性。

Fig.7 Performance evaluation of experiment图7 实验性能评估
5 结束语
本文首次将神经网络引入案件审判难度预测任务,结合案件繁简判别要素,提出了一种新型的基于掩码注意力拓扑关联网络的审判难度预测模型(MAT-TAN)。
具体地,该模型首先采用一种掩码注意力网络(MAT)聚焦审判要素,实现对案情描述文本的细粒度分析。其中的掩码机制扮演智能门控者的角色,起到聚焦审判要素特定位置的作用,结合自注意力机制,实现了对各审判要素全面、准确的特征提取。其次,提出一种拓扑关联网络(TAN)对要素间的司法逻辑依赖关系进行建模,并有效地融合不同要素的特征,最终实现案件审判难度的预测。在真实数据集上的实验结果表明,本文的模型相对基准的文本分类方法,宏平均F1 值提高0.03 以上,在审判难度预测任务上具备较好的使用效果。
在未来的工作中,将研究基于本文模型的迁移学习,以适用不同法院案件审判难度预测任务。此外,将致力于数据脱敏工作,去除法院实际案件的敏感信息,补充相关手续流程,公开脱敏后的数据集,以供后续对比研究。
