应用轻量级YOLOv2模型实现口罩佩戴检测的方法
2021-12-12陈旭君王承祥陈民慧纪娟娟朱德泉
陈旭君,王承祥,陈民慧,廖 娟,纪娟娟,朱德泉*
(1.安徽农业大学工学院,安徽 合肥 230036;2.安庆师范大学电子工程与智能制造学院,安徽 安庆 246133)
新冠疫情爆发以来,佩戴口罩成为人们出行的“标配”[1]。佩戴口罩能减少空气中的飞沫、细菌等颗粒物的吸入量,有效降低感染病毒的概率[2]。为提升佩戴口罩的执行率,需要对公共场合行人是否佩戴口罩进行检测,但人工监测方法耗时,效率低,且工作人员长时间与行人频繁接触也有感染风险。因此,研究自动检测行人是否佩戴口罩的方法非常必要。随着公共场所监控摄像头的普及,研究人员开展了智能视频监控研究,采用计算机视觉技术,自动分析实时图像,检测监控场景目标,并进行目标分析。覃剑[3]使用高斯模型拟合行人尺寸分布,提出了一种基于在线高斯模型的行人目标框的快速生成法,减少了运算复杂度,但使用场景有限,对动态行人的检测效果较差。陈丽枫[4]将HOG与Adaboost-BP模型相结合,利用边缘检测技术对行人目标进行检测,该方法在单人或者人流量较小的情况下效果较好,但不适合在人流量大的公共场合应用。上述方法通常是由人工选取如颜色、纹理等浅层特征,在复杂多变的环境下没有足够的鲁棒性,检测场景单一,且时间复杂度高[5-6],检测速度也难以满足实际需求。
深度卷积网络具有自学习能力、泛化能力强等特点,数据集越丰富,算法对多变环境的鲁棒性越好,被广泛应用于目标检测和分类中。牛作东[7]在RetinaFace的基础上,改进网络分类损失函数,增加注意力机制,实现了对行人口罩佩戴状态的检测,其平均精度为87.7%。UCloud团队[8]采用深度学习技术,将人脸检测、人脸关键点检测、口罩实例分割算法相结合,其检测是否佩戴口罩的精度为99%,是否正确佩戴口罩的精度为95.1%。这些深度卷积网络算法实现了对人脸口罩目标的高精度检测,但通常是加深网络以提高目标检测精度,增加了算法复杂度,对网络模型所占用的存储空间以及设备计算性能需求均不断提高,不利于在移动端开发应用。
针对网络参数量过大、不适合应用于常规移动设备、应用成本高等问题,本文提出一种改进的YOLOv2口罩佩戴检测方法,以轻量级网络ShuffleNet为主干网络,与YOLOv2进行重构组合,充分利用两个网络的优点,解决深度网络占用存储空间大、对设备计算性能要求高的问题,并且保证检测精度和速度。该方法可部署于常规计算性能的移动设备,实时检测行人是否佩戴口罩。
1 轻量级YOLOv2网络的口罩佩戴检测方法
1.1 整体框架
目前,公共场所监控所用的相机多为网络摄像头,且无线网络摄像头具有安装简便、信号传输距离远、易操作等特点。因此,本文采用无线网络摄像头采集监控场景图像,基于局域网信息传输和深度卷积神经网络进行检测,整体框架主要包括图像采集、口罩佩戴检测和异常报警,如图1所示。图像采集相机分辨率为2 304×1 296的TP-LINK无线网络摄像头,水平视角360°,垂直视角163°。根据摄像头的IP地址,在GUI界面中配置计算机的局域网通信信息,计算机读取网络摄像头视频图像,然后使用Shuffle-YOLOv2网络对图像中行人佩戴口罩情况进行检测。若出现行人未佩戴口罩的情况,则计算机发出信号,通过局域网传输信号触发扬声器报警,提醒行人或者工作人员。
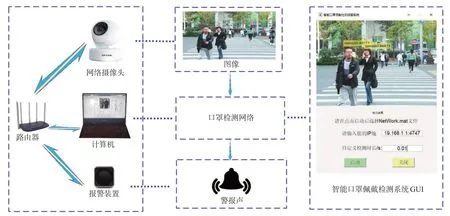
图1 整体结构
1.2 口罩佩戴检测网络模型构建
YOLOv2是一种端到端的卷积神经网络模型[9],该模型将目标检测视为求解回归问题[10],在网络训练中省去提取候选区域步骤,并引入BN(Batch Normalization)、K-Means聚类评估锚框、新的主干网络、高分辨率分类器等[11],极大地提高了卷积神经网络的运行速度。YOLOv2将Conv2D、BN和Leaky ReLU组成如图2所示的DBL单元[12],但基于卷积和下采样的特征提取方式会增加网络深度,网络特征信息在逐层传递时丢失[13],造成检测精度下降。
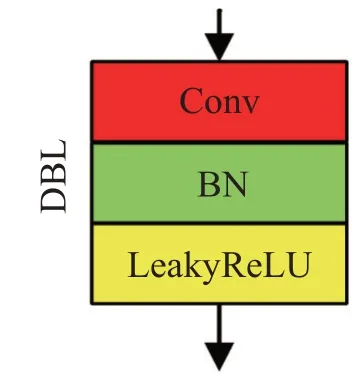
图2 DBL单元
ShuffleNet是针对计算性能有限的移动设备而设计的轻量级网络[14],采用逐点分组卷积方式对输入的特征向量进行组别划分,并使用通道重排操作增强不同组别特征向量之间的信息交换,提高特征提取效率。Shuffle通道如图3所示,Shuffle通道中特征向量重排如图4所示。逐点分组卷积使网络轻量化,但ShuffleNet在分类过程中采用全连接层拉平3维特征向量,并将其映射到标记空间,破坏了网络空间结构,且从全局特征中提取目标信息的方法限制了特征图的大小,造成网络空间冗余,增加了网络过拟合的风险。
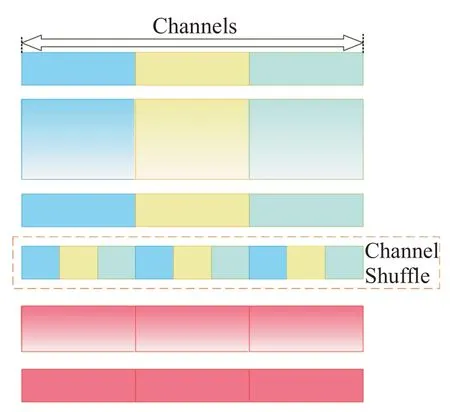
图3 Shuffle通道

图4 特征向量重排
综合ShuffleNet和YOLOv2的优点,将ShuffleNet作为YOLOv2的主干网络,构建如图5所示的Shuffle-YOLOv2。输入分辨率为416×416的图像,初步卷积下采样和池化下采样后由Shuffle单元提取特征信息,经28通道的1×1卷积核做分类卷积处理,由锚框预测目标框和置信度分数。采用多个Shuffle_a单元组合成1个Shuffle_b单元的下采样以增加网络深度,提取更多图像特征信息。输入Shuffle单元的特征图大小为104×104,经过Shuffle单元处理后其大小为13×13。整个Shuffle单元共使用了3个Shuffle_b单元和13个Shuffle_a单元。Shuffle单元带有残差结构,网络前向传播时可保持特征信息的完整性。
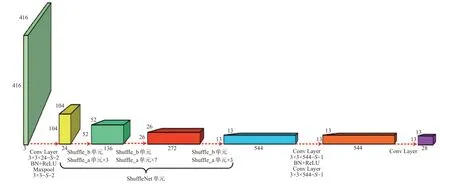
图5 Shuffle_YOLOv2结构图
两种带有残差结构的Shuffle单元如图6所示,GConv中的28个1×1卷积核对特征图进行逐点分组卷积处理,Channel Shuffle对不同组别的特征向量进行通道重排,深度卷积使用1个卷积核对1个通道进行卷积,使其在卷积过程中不会创建新的输出特性[15],前后两次GConv操作确保其输入通道与输出通道相匹配。经过Channel Shuffle处理输出的特征图与前层的特征图进行通道级联,既可降低计算复杂度,又可增加通道维度。Shuffle_a单元中深度卷积的stride为1,其输出的特征图大小不变,而Shuffle_b单元中stride为2,特征图经过卷积下采样和池化下采样后进行通道级联,其宽高缩小为原来的一半。

图6 两种不同的Shuffle单元
Shuffle-YOLOv2通过逐点分组卷积有效减少了网络参数,且Shuffle单元的残差结构通过恒等映射,将前后层特征信息进行通道级联,确保有足够的特征信息传递给下一层神经元,在加深网络层数的同时可防止网络退化。Shuffle-YOLOv2分类层中使用1×1小卷积核对特征图进行局部特征提取,网络空间结构不变,避免网络参数增多和破坏网络空间结构,且使用K-Means聚类从训练集中自动评估锚框,在目标预测过程中减少了人为主观因素的影响,网络模型更容易自主学习,泛化性增强。
1.3 Shuffle-YOLOv2训练方法
Shuffle-YOLOv2的训练流程如下。
(1)图像归一化。将输入图像归一化为416×416像素。
(2)锚框提取。计算聚类锚框与真实目标框的交并比,采用K-Means聚类算法自动提取训练集图像中锚框,计算公式为

其中,P(b,c)表示真实目标框与聚类锚框的交并比,b表示真实目标框,c表示K-Means聚类算法提取出的中心框。d(b,c)越小,说明聚类锚框和真实目标框的宽与高更接近[16],聚类评估效果越好。实验设置4个聚类锚框,经K-Means评估的锚框大小分别为303×230、51×31、208×122、117×71。
(3)预测目标框与置信度得分。Shuffle-YOLOv2将特征图分成13×13个网格单元,输出13×13×4个锚框,每个网格单元预测的目标框输出5个参数,分别为tx、ty、tw、th和置信度得分C。计算预测目标框的位置bx、by、bw、bh的公式为

其中,cx、cy表示预测目标中心所在网格单元相对于图像左上角的距离,σ(tx)和σ(ty)表示预测目标中心与所在单元格左上角的距离,pw、ph表示聚类锚框的宽度与高度。
预测目标的置信度分数C,即预测目标框和真实目标框的交并比P与目标预测概率Pr的乘积[17],其计算公式为

若该网格单元里含有目标,则Pr为1,否则为0。
2 实验与分析
2.1 数据集制作与实验环境设置
实验采用10 000张图像作为数据集,为了增强网络模型的泛化能力,使用添加噪声、垂直镜像、调节亮度和饱和度共4种方式对数据集进行扩增处理,将数据集扩充为50 000张。
实验硬件设备为Intel core i5-8300H CPU@2.3GHz,Nvidia GTX1050Ti GPU 4GB,运行内存16 G,存储为固态硬盘500 G,操作系统为Windows10,代码运行环境为Matlab2020a。训练参数设置:学习回合为30次,最小训练批次为10,初始学习率为0.001。训练过程采用SGDM算法对网络模型进行优化,为保证训练出来的网络检测性能稳定,在每回合训练前对训练数据进行随机重新排列。训练集和测试集的比例为8:2。
2.2 网络性能评估分析
为了验证Shuffle-YOLOv2的口罩佩戴检测效果,根据实际监控场景,将图像中口罩佩戴情况分为3类:佩戴口罩、未佩戴口罩、佩戴口罩和未佩戴口罩。Shuffle-YOLOv2的检测效果如图7所示可以看出,Shuffle-YOLOv2能够准确识别出口罩佩戴的3类情况,识别效果良好。

图7 基于Shuffle-YOLOv2的实际检测效果。(a)佩戴口罩;(b)未佩戴口罩;(c)佩戴口罩和未佩戴口罩
为了量化分析Shuffle-YOLOv2的口罩佩戴检测准确性,采用平均精度作为检测性能优劣的衡量指标。图8为Shuffle-YOLOv2平均精度统计图,横坐标为召回率,纵坐标为精确率,平均精度为带三角的蓝色曲线与横纵坐标包围的面积在整个统计图中的占比,3类情况的检测精度分别为0.98、0.94和0.93,模型的检测精度较高。

图8 Shuffle-YOLOv2的平均精度曲线
为了进一步验证Shuffle-YOLOv2的性能,将DarkNet19、轻量级网络SqueezeNet、轻量级网络MobileNetv2作为YOLOv2的主干网络(分别称为DarkNet19-YOLOv2、Sequeeze-YOLOv2、Mobile-YOLOv2)与Shuffle-YOLOv2进行对比。4个网络模型的平均精度、检测速度、Matlab2020a环境下占用存储空间和训练损失对比如表1所示。Dark-Net19-YOLOv2模型虽具有较高的检测精度和较好的训练收敛效果,但该模型参数量大,占用存储空间已超100 MB,加上后期环境配置等会导致占用存储空间过大,不适合应用于常规移动设备,而3个轻量级YOLOv2模型占用存储空间都比较小,适合在移动设备端进一步开发。在训练损失和检测速度对比上,Shuffle-YOLOv2收敛程度优于Squeeze-YOLOv2和Mobile-YOLOv2。在检测精 度上,Squeeze-YOLOv2在3种情况下的平均精度都低于Shuffle-YOLOv2,Mobile-YOLOv2仅在未佩戴口罩情况下与Shuffle-YOLOv2持平。由此可见,Shuffle-YOLOv2模型检测性能较优,更适合在移动设备上进一步开发部署。

表1 不同网络模型的性能参数对比
3 结论
综上所述,本文提出了一种集图像采集、口罩佩戴检测、异常报警于一体的轻量化口罩佩戴检测方法,计算机通过局域网读取网络摄像头的图像信息,使用Shuffle-YOLOv2网络检测行人口罩佩戴情况,出现行人未佩戴口罩情况时会触发报警器报警。Shuffle-YOLOv2网络使用ShuffleNet作为主干网络,实现网络的轻量化,减少了网络参数,提高了模型的检测速度。在同等实验条件下,Shuffle-YOLOv2大小仅有22.2 MB,检测速度为0.029 fps,占用存储空间小,且检测精度、检测速度也符合要求。实验通过进一步优化网络模型,减少网络训练参数,降低网络模型对设备计算性能的需求,使其可在普通办公电脑或者手机上使用。相较于目前所公开的一些深度网络模型以及一些成本高昂的检测设备,本研究有望降低人工智能产品的使用成本,提高产品的实用性。
