基于自查询的车载多目标跟踪算法研究
2021-12-11朱程铮蔡英凤李祎承
陈 龙,朱程铮,蔡英凤,王 海,李祎承
(1.江苏大学汽车工程研究院,镇江212013;2.江苏大学汽车与交通工程学院,镇江212013)
前言
智能汽车是一个包括感知、决策与控制的复杂系统,环境感知是路径规划和决策控制的重要前提,基于摄像头的多目标跟踪是环境感知的关键内容之一,对于车辆行驶、行人预判等高级驾驶辅助系统(advanced driving assistance system,ADAS)开发和自主驾驶的路径规划具有重要影响。
多目标跟踪算法常见为基于检测算法的多目标跟踪,文献[1]~文献[3]中这些模型利用一个既定的检测器识别物体,并在之后的图像帧中将相同的物体关联起来。该方法充分利用了基于深度学习的目标检测器的性能优势,如鲁棒性强、平均精度高、速度快等,是目前主流的多目标跟踪方法。但是,此类多目标跟踪器并非完美无缺。它们往往依赖于复杂的关联策略将检测到的对象与历史信息进行关联。而这种策略却增加了训练、部署的复杂性。在实际使用中,此类多目标跟踪任务可以分为以下两个独立步骤:(1)对输入帧进行运动学模型建模和外观建模,从而分别产生运动特征和外观特征;(2)基于运动学特征与外观特征以完成帧之间的目标关联。即此类算法往往在检测结果后还需要两个不同的特征,若仅仅使用一个特征提取网络,难以产生两全其美的特征,而若使用两个独立的网络提取,又会导致模型过于复杂。基于以上种种原因,此类算法往往存在跟踪的实时性不足,需要使用抽帧法等额外方法以达到实际使用需求。
近年来,得益于深度学习的理论深入与方法的快速迭代,使得多目标跟踪领域得到进一步的发展。最近文献[4]和文献[5]中提出了将关联所使用的重识别算法的骨干网与检测算法骨干网共用的方法。该类算法往往在一个检测算法上增加一个重识别分支,有效降低了骨干网的参数量使多目标跟踪的实时性大幅提升,但却存在身份切换次数(number of identity switches,IDSW)过大的问题,使得难以满足实际使用需求。
针对多目标跟踪算法在准确性与跟踪速率存在的矛盾,本文中提出了一种准确性高且满足实时性需求的多目标跟踪算法。简单来说,就是将多目标跟踪问题简化为两个并行任务:(1)完成一个检测任务;(2)完成当前检测特征图结果与上一帧身份的匹配。最后将两个任务进行交并比关联,即可得到最终的多目标跟踪结果。具体来说,即通过骨干网,提取出当前帧的对象特征,将其同步输入至两个分支结构。分支1(即检测分支)由一组并行的卷积模块构成,其作用是快速完成对于当前图像中的感兴趣对象的检测。分支2(即查询分支)是一个由Transformer[6]组成的编码-解码器,作用是将当前特征图作为键值向量以获取上一帧的身份特征在当前帧的位置映射。最终,将检测分支的检测对象与查询分支的身份对象进行交并比匹配,即可完成对象身份分配与新身份的生成。最后将多目标跟踪模型集成到ROS(robot operating systems)[7]平台,通过智能车部署的多目标跟踪算法能够实现各类复杂交通场景下的车与行人的实时跟踪,多目标跟踪具体流程如图1所示。

图1 多目标跟踪具体流程图
此外,为解决对象临时消失的问题,还引入了记忆机制,即历史消失的身份特征将被保持一个时间阈值K,并在消失后的K个连续帧中随着上帧身份特征一并作为查询向量而输入至查询分支中。虽然此方法会因输入参数量的大幅提升而降低算法的速度,但却有效降低了跟踪过程中出现的身份切换次数。
本文的贡献可归纳如下:(1)设计了两个分支,将多目标跟踪算法拆分为两个无影响的任务,检测任务与查询任务,并通过共有骨干网的方式大幅降低了网络的参数量;(2)将跟踪常见的轨迹关联任务简化为当前帧检测对象与历史对象在当前图中的位置映射的匹配,大幅降低了后处理的计算复杂度;(3)将多目标跟踪模型集成到ROS平台,可通过智能车实现实时的车与人的跟踪。
1 检测分支与查询分支
利用多分支组成的多目标跟踪模型,其最大优势是可以降低算法的时间复杂度和解决目标外观复杂变化的跟踪问题。行人与车辆的多目标跟踪网络由3部分组成:(1)通过特征提取网提取出含有感兴趣物体特征的全局特征,得到一个高维特征图;(2)检测分支检测出当前帧的感兴趣物体,通过热图的检测与边框的回归,可以实现基于特征图的对象检测;(3)查询分支完成历史身份在当前特征图的位置查询,用以确定当前特征图上的历史对象。为加速计算,步骤2与步骤3并行计算。图2为由卷积网络组成的检测分支结构。图3为查询分支的编码-解码结构。将特征图进行展平后输入至编码-解码器中,利用Transformer结构具有自相关查询的机制,可以快速依据上一帧身份对象查询出其在当前帧的特征图中所对应的位置。

图2 卷积网络组成的检测分支结构图
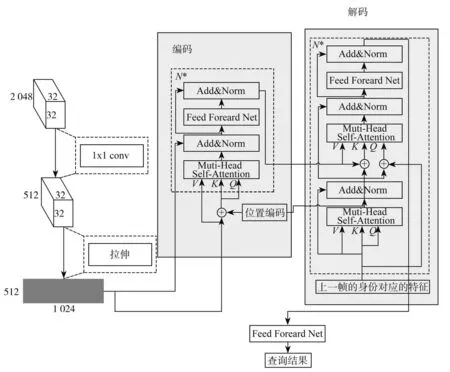
图3 查询分支的编码-解码结构
特征提取网的作用是快速从图中提取出所需要的图像特征,基于深度神经网络的骨干网可以较为快速且高效地实现此项目。基于速率与性能的考虑,本文中使用了ResNet50[8]作为特征提取网。为方便计量,不妨设当前帧的输入尺寸为3×H×W,因此,经过特征提取网后的输出尺寸为2048×H′×W′,其中
1.1 检测分支
检测分支主要依据热图响应的原理得到相应的目标对象。然而依靠简单的resnet50会因为下采样次数过多导致像素信息的丢失,具体来说就是简单的多次下采样会导致网络失去对于小目标的感知能力。为解决此问题,本文中将resnet50的每个中间层(即layer1~layer4)均作为输出层,在保留全局特征的情况下获取了对于小目标的感知能力,并使用上采样的方式完成特征对齐。如图2所示,检测分支由热图模块、边界模块、矫正模块等3部分构成。热图模块依靠中心点响应[9]即可得出车辆与行人的图像中心,而边界模块利用神经网络的回归拟合可以得到相应的对象边框。由于卷积计算的过程中必然会导致不可逆的坐标偏移,为此设置了矫正模块以修正中心点的位置。
考虑到实际场景的目标对象的中心点数远少于背景像素点,即车辆与行人的中心点像素数与背景像素极不均衡,并且实际场景中的目标变化较大,会存在大量的困难样本。因而,采取focal-loss[10]作为训练损失函数以进行中心点分支的训练。具体中心点损失函数Lh计算公式为
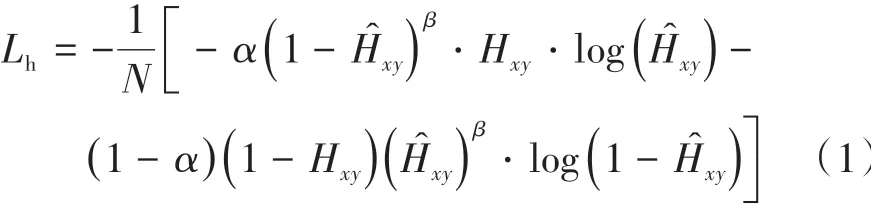
式中:N为图片的批量输入数;Ĥxy为中心点的预测值;α为正样本(即车与行人)与负样本(即不需要跟踪关注的目标)的平衡权重;β为简单样本的训练权重降低的速率权重;Hxy为样本真值。
考虑边框与矫正模块的估计更类似于一个回归任务,故而对于边界模块使用L1损失进行边界框的损失训练,对矫正模块亦使用L1损失函数进行训练。具体边框损失函数Lb与矫正损失函数Lm的计算公式为

式中:N为图片的批量输入数;b̂i为边界框的i预测值,其对应的真值为bi;ĉi为中心点i的预测值,ci为其对应的中心点真值。
1.2 查询分支
特征提取分支的网络输出为2048×H′×W′,考虑到Transformer随着通道维度的增大将导致参数大幅提升,最终会严重降低计算速度,为此使用一组卷积使得输出的通道维度降为512,即变为512×H′×W′。但是Transformer结构的输入需要为一个二维张量,为此本文先将特征图按行进行展开,得到一个二维张量512×U,其中U=H′×W′。考虑到对象数量的不确定性,将维度进行变化,得到最终的输入维度为N×512×U,其中N表示批量输入的值,对于推理时,值为1。
Transformer的结构更类似于一种键值匹配的关联方式。利用这种特征,将前帧对象身份作为解码器的查询向量Q,当前输入作为键值向量K和V,由其内部的多头注意力机制,可以得到当前的查询向量与键值向量的关联度,经过多次计算可得最终的当前帧中的历史身份对象的映射位置。具体的多头注意力公式如下:

式中dmodel为向量的维度。
在实际场景中,因为交通路况复杂多变,行人常常出现被遮挡的情况,即同一对象在连续帧中并不连续。这就导致了仅仅使用上一帧身份对象作为查询向量会导致损失很多历史轨迹,对于自动驾驶的安全性带来了挑战。为避免此类状况的出现,本文中使用了回溯机制。即对于t-2帧出现但t-1帧消失的对象,会保留其身份特征并添加至t帧的查询向量中。若连续K帧均未出现此对象,则删除此对象特征以节约计算资源。
2 分支结果的关联
将检测分支得到的检测结果与查询分支得到的身份位置进行交并比匹配[11]可以大幅降低后处理的时间以提升跟踪的速率。常见的交并比计算公式与训练损失函数Liou如式(4)所示,IoU可以实现对两个预测框相似度的测量,但是在实际训练和推理中,会存在以下3个不足:(1)在训练中,当预测框和目标框不相交时,即IoU=0,难以反映这两个框的远近程度,且此时损失函数因变为常数而导致不可导,最终使得IoU-Loss难以优化两框不相交的情况;(2)当两个预测框大小相同且此时IoU相同时,IoULoss也无法区分两者的相交情况;(3)两个大小相同且与检测框IoU相同的查询结果,难以匹配到其正确的检测对象。

式中:pre表示预测结果;GT表示真值。对于推理时,检测的结果作为真值,查询结果作为预测值。
为解决不足(1),在已有的IoU计算公式的基础上,增加了相交尺度的衡量方式。即还需要计算两个框的最小外接矩形面积,即为GIoU[12]和训练损失函数Lgiou:

式中:Ac为预测值与真值的最小矩形面积;u为预测值与真实值的并集面积。但是此方法依然无法解决问题(2)和(3),因为预测框在目标框内部且大小一致时恒成立,此时GIoU退化为IoU,难以区分相对位置关系。此外在训练过程中,会出现训练结果发散的情况。
为解决问题(2)和(3)导致的预测框与真值框内部难以测量的问题,在交并比计算过程增加了重叠面积和中心点距离的衡量即为DIoU[13]和训练损失函数Ldiou:

式中:d为预测框与真值的中心点的欧氏距离;l为预测框与真实框的最小外接矩阵的对角线距离。在实际使用中,该方法已经取得在速率与精度的平衡。但为减少训练导致的误差,本文在训练中使用了CIoU-Loss,该训练损失函数在DIoU的基础上,额外考虑了当预测框中心点相同时的损失计算。该方法使用了边框权重函数v以度量长宽比的相似性,具体公式如下:

式中:α为边框权重函数v的权重系数;wgt、hgt分别为真值框的宽、高;w、h分别为预测框的宽、高。另外,需要注意的是在推理中,依然使用DIoU。
3 标准数据集的测试
3.1 数据集介绍
MOT15[14]、MOT17、MOT20[15]数据集是用于多目标跟踪的通用数据集,该类数据集均具有人群密集的特点,为多目标跟踪带来了严峻的挑战。但是此类数据集仅具有行人视频,难以满足实际使用需求。为此本文中使用了本田泰坦数据集[16],该数据集含有行人与车辆的跟踪视频,包含有行人下车、车辆遮挡行人、行人遮挡车辆、车流相互遮挡、行人相互遮挡和行驶转弯等多种不同的场景。本研究采用包含74 641张图片的数据集作为训练集,13 542张图片作为验证集。此外,为进一步提升网络的拟合能力,将BDD 100K[17]数据集进行了一定的标签修改,将标签为car、Truck、Bus的3类对象统一为vehicle,并仅保留行人与车辆两类(即仅保留标签类别为Person和vehicle的标签)。为测试本算法的性能,本文在MOT15、MOT17、MOT20上进行了迁移学习并完成测试。
3.2 网络训练
本算法实现基于python语言,使用pytorch==1.5框架搭建多目标跟踪网络部分。试验平台主要参数:(1)处理器为Inter(R)core(TM)i7-9900K CPU@3.60 GHz;(2)内存为64 GB;(3)显卡为NVIDIA GeForce RTX2080Ti*2。首先使用BDD 100K数据集的7万张训练集进行backbone与检测分支的预训练。Epoch设 为30,batch-size取为16,初始学习率 为0.000 1,并在之后的每个epoch线性增长0.000 2,直至epoch=5时升至0.001,并在之后的epoch=25降为0.000 2,epoch=27时进一步降为0.000 05。在之后使用泰坦数据集进行整个网络的训练,加载上一步的预训练模型并设epoch为20,初始学习率为0.001,并在epoch=15时降为0.000 5。
3.3 标准数据集的评测
为验证本文所提算法在多目标跟踪领域所达到的准确性和快速性,并方便与其他现有算法进行横向对比,本文中使用了含有4 479张图片的MOT20测试集。将本算法与文献[18]中所提算法(在检测分支上增加重识别分支,利用重识别完成历史身份的关联从而达到多目标跟踪的效果)进行了测试,评测指标主要为多目标跟踪准度(multiple object tracking accuracy,MOTA)、识别F值(ID F1 Score,IDF1)、身份切换次数(number of identity switches,IDSW)、跟踪完整率(mostly tracked targets,MT)、每秒运行帧数(frames per second,FPS)等参数,结果如表1所示。可以看出在大多数数据集中,本文算法比文献[18]中在识别F值、身份切换次数和运算时间等指标均具有明显优势。例如在MOT20测试集中,本算法的身份切换次数仅有2 239,远低于文献[18],证明本算法可以有效降低同一身份的切换频率,为智能驾驶提供更好的支持。此外虽然在多目标跟踪准度指标均有些许不如,但是因为本方法的速度显著,达到22.7 fps,这点性能的损失依然可以满足智能驾驶的安全性需求。

表1 各数据集上的指标对比
4 实车试验
4.1 利用ROS平台将所提算法快速部署
ROS是用于编写机器人软件程序的一种具有高度灵活性的软件架构。其拥有信息传递与分布式计算等显著优势。为实现多目标跟踪模型在ROS平台的集成,本文中建立了多目标跟踪节点以及网络连接方式的话题结构图,如图4所示。首先创建lane_node节点,该节点实时订阅由USB摄像头驱动发布的视频图像的话题/usb_cam/image_raw,并通过调用ROS库中的cv_bridge模块将图像信息转化为OpenCV可识别的格式,再根据多目标跟踪模块对图像数据进行推理,最终将结果实时地以会话形式发布,订阅该会话即可得到多目标跟踪结果。

图4 话题结构图
4.2 实车试验结果
将摄像头、工控机分别安装在智能车上。摄像头输入像素为1080×720,摄像机每秒采集60帧图像。工控机显卡型号为RTX 2080TI。智能车行驶速度约为20 km/h,图像数据格式为RGB格式。为了验证该算法的实时性及准确性,分别在不同场景下进行试验,并通过调用ROS的Rviz模块,可实现多目标跟踪的结果可视化。图5展示了在某一实际路段中的多目标跟踪结果,为节约篇幅只截取了典型的6帧(图5(a)~图5(f))进行展示。可视化结果格式为(id,类别),对于类别,0表示行人,1表示车辆。

图5 基于车载场景下的多目标跟踪结果的6个代表帧
图5 (a)表示刚刚开始跟踪,此时环境较为复杂,树林导致的阴影出现了严重的遮挡问题,与此同时,行人较为密集,对多目标跟踪算法提出了较高的要求。可以看出智能车在此时可有效检测并跟踪到前方区域中较为明确的对象,且对于车辆和行人的区分明确。此外由于本算法的检测分支属于无锚框检测,有效缓解了锚框重叠导致的漏检情况。当车辆进入图5(b)场景时,此时行人数量进一步增加,但是因为与智能车的距离缩近,行人在视频中的像素大幅提升,且遮挡有所下降。此时本算法可很好完成历史身份的分配和新身份的生成任务。尤其对于对象19,虽然较为模糊且遮挡严重,但此时本算法却能很好识别出其对应的种类与历史身份是否映射,并成功为其赋予了出生id。图5(c)为中短间隔的跟踪场景,可以看到在一段时间内,基于身份查询的跟踪依然可有效实现身份的关联匹配,尤其是对象16,19虽然其初次出现在场景中的外观特征并不明显,但是在历史身份特征迭代的过程,其身份特征得到了增强,使得它们在图5(c)中被有效跟踪。图5(d)为另一个短时间间隔后的跟踪。体现了本算法在对象数量短时间大量变少的情况下的身份分配能否准确。可以看到对于对象16,此时已经多次角度变换,但受益于身份特征的稳定性,依然可以为其匹配出历史身份。对于图5(e),展示了长距离跟踪后的结果,可以看到本算法对于历史已有对象持续跟踪效果良好,且本车载算法依然可以完成新对象的身份添加,未出现长时间运行后的性能下降情况。令人意外的是,本算法在训练时并未对骑电动车的人(即类别为rider的对象)进行训练,但在实际使用中依然能检测出骑车的行人,如对象29。最后,图5(f)展示了极长时间跟踪(5 min以上)后的结果,可以看到此时对象5依然可以跟踪成功。
5 结论
本文中针对车载状况下的多目标跟踪难题,提出了一种基于自查询的车载多目标跟踪器。设计了两个分支分别完成检测任务与身份查询任务,其中检测分支使用了基于热图的方法能够快速检测出行人与车辆,而查询分支将历史身份作为查询向量匹配出其对应的当前特征图上的位置映射。本算法在满足实时性的基础上可以实现较为精确的行人与车辆的跟踪。使用了多种数据集的训练有效避免了单一训练集因样本数较少出现过拟合的情况,有效增加了本算法的泛化能力。而在多个标准数据集的测试表明,本算法的实时性较好,且性能也达到主流水平。最后,将本模型集成到基于ROS的智能车平台进行测试,实现了复杂交通场景下的多目标实时跟踪,算法具有很好的实际应用价值。
