基于机器学习的生活号敏感内容感知与预警系统设计
2021-12-09张维蒋颖楼斐王庆娟陈齐瑞
张维, 蒋颖, 楼斐, 王庆娟, 陈齐瑞
(国网浙江省电力有限公司 营销服务中心(计量中心), 浙江 杭州 310014)
0 引言
智能移动设备的普及使得移动互联网的发展更加迅猛,上网不再局限于时间和地点。同时,信息的开放性也丰富了互联网信息资源数量[1]。而网络的开放性与自由性导致了一些别有用心的人在生活号中发布一些不健康或敏感信息,由此造成不必要损失的情况也越来越普遍。更重要的是,青少年是我国庞大网民中的重要部分,一些敏感信息会影响青少年的价值观以及心理健康[2-3]。因此,对生活号发布信息中的敏感内容进行有效的感知和预警对于营造良好的网络环境具有重要的社会意义。传统的敏感内容感知预警系统,如社交网络敏感内容检测系统[4]和无线局域网内敏感信息安全检索系统[5],在词向量维度增大的情况下对敏感内容的感知准确率会降低。因此,本研究利用机器学习技术中的卷积神经网络模型设计了生活号敏感内容感知与预警系统。
1 生活号敏感内容感知与预警系统设计
本研究设计的系统期望实现的目标主要包括两部分,一是尽可能快且全面地发现被监测生活号发布内容中的敏感信息;二是实现预警功能。本文在设计系统时沿用传统系统的硬件物理架构,主要针对软件方面进行详细的优化设计。系统软件执行架构如图1所示。

图1 系统软件执行架构图
图1所示的软件执行架构的主要作用是通过监测生活号队列对生活号进行爬取,并计算爬取路径的MD5值,然后连接网页的预处理、信息提取、敏感信息检索、预警信息构建等内容。其中,数据层主要对信息数据库进行管理和访问[6-7]。在此基础上,对系统的敏感内容感知以及预警功能进行详细的研究。
1.1 网页内容提取
在互联网中,敏感内容主要是指未经授权人接触或修改后散布的损害国家、政府或个人权利的信息。为了实现对敏感信息的有效感知,首先需要对网页内容进行提取[8]。在这一过程中,需要用到网页爬虫技术。网页爬虫是在搜索系统基础构件的基础上,从若干个指定链接出发构建爬行队列。其提取流程如下:从生活号中选择部分链接作为种子,将初始爬行的URL组成一个队列,然后将种子URL加入到待爬行队列中,从待爬行队列依次取出每个URL下载网页,将源码进行存储,提取网页中的URL链接并完成去重处理,添加到待爬行队列中。不断重复上述操作,直到待爬行队列为空[9]。
在上述的网页提取过程中,待抓取的URL队列是程序中重要的组成部分,且URL的排列顺序会影响网页提取的爬行效果,因此在抓取时需要遵循宽度优先、非完全PageRank、OPIC以及大站优先策略。
1.2 抓取内容预处理
生活号所发布的信息主要包括文字和图片。为了提高后续对敏感内容的感知和识别能力,需要对抓取到的内容执行预处理操作[10]。
对于文本信息来说,需要对其中的分词和禁用进行处理。首先将原始字符串进行原子切分得到原子系列,通过最短路径粗切分得到最优的y个结果,通过简单未登录词的识别得到修正后的y个结果,并将其嵌套在未登录词识别中[11-13]。文本中包含的人名和复杂地名机构名等会被单独分列出来,规划到二元切分词图当中,在此基础上基于词类得到HMM分词系列,包括词类的HMM标注信息。最后得到初步的词法分析,并对其进行简单处理,对最后得到的信息进行分类处理,分类的内容如表1所示。

表1 汉语词性标记分类内容
除了表1中的分类以外,对文本内容的分类还包括时间词、处所词、方位词、区别词、量词、副词、介词、连词、助词、叹词、语气词、拟声词、前缀、后缀、字符串等,这些是表示文本内容某种属性的分类。经过上述分类,可有效减轻对生活号网页中敏感内容关联词挖掘的难度。结合关联词挖掘的意义,选取其中的一些具有特殊属性的词进行保留,过滤掉其他类别的词语[14-16]。
对于生活号网页中的图片信息来说,根据图片大小特征和颜色等信息,在导入图片信息后,可得到其宽w和高h的信息,图片大小的判别条件如式(1)。
w≤200∪h≤300
(1)
当图片的大小满足式(1)时,说明图片过小可以直接过滤。对于大小满足式(1)的图片,根据其颜色直方图来获取图片的颜色特征。这一过程中使用的方法通常包括颜色模型转换、非均匀量化和直方图相似性度量这3种方法[17-19]。可根据图片的实际情况,选择适合的方法来提取图片的颜色特征。经过灰度化和二值化处理后,对图片进行2次过滤完成倾斜校正。
1.3 基于机器学习的敏感内容感知与预警
在完成对生活号信息的预处理后,本研究将机器学习技术中的卷积神经网络模型作为敏感信息感知与预警的主体。卷积神经网络模型中包含一定数量的滤波器,可以同时并行处理文本和图片,节省了建模时间,且能够保证感知结果的准确性[20]。卷积神经网络模型建模过程如图2所示。

图2 卷积神经网络模型建模过程示意图
由图2可知,建立卷积神经网络模型后,模型主要在系统第二层:检测核心功能层训练子模块,将上层模块输出的内容输入到Text-CNN中,最后输出成功训练的模型。模型使用子模块主要用来感知生活号网页内容的待查文本,并将检测结果传递给输出子模块,再由子模块发布警告信息。至此,完成了对基于机器学习的生活号敏感内容感知与预警系统的设计。
2 性能测试与分析
为验证本文设计的基于机器学习的生活号敏感内容感知与预警系统的实际应用性能,设计如下性能验证实验。为突出实验结果的有效性和本文系统的应用性能,将传统的社交网络敏感内容检测系统与无线局域网内敏感信息安全检索系统作为对照,共同完成性能验证。
2.1 实验环境及数据集准备
在系统性能测试过程中,为了保证测试结果的可靠性,需要对实验环境和使用的软件版本进行统一的设定,尽可能将实验误差降到最小。实验环境以及工具版本如表2所示。
表2 实验环境及软件版本
为了有效实现机器学习,需要对数据集进行采集与积累。为了保证系统感知和预警精度,因此数据集的质量和来源非常重要。本研究中的实验数据主要来源于维基解密、搜狐等数据集。根据实际收集到的文本数据情况,将得到的数据集按照一定比例划分成训练集、验证集和测试集,具体的数据集数量以及拆分情况如表3所示。
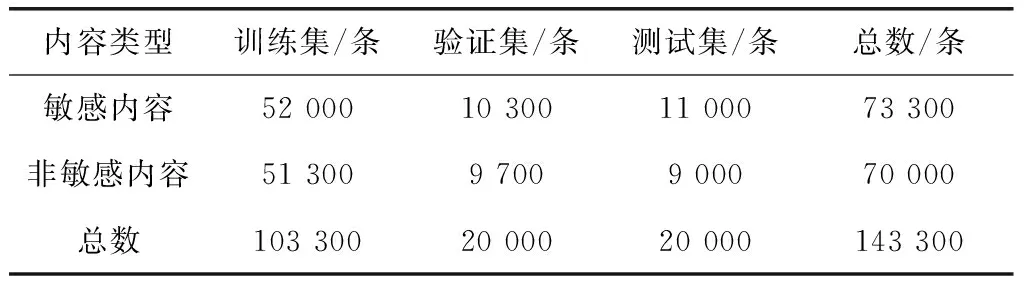
表3 数据集条目拆分情况
首先,调整词向量维度,再利用本文对数据集中的所有数据条目进行扫描,扫描界面如图3所示。

图3 敏感信息扫描界面
由图3可知,利用本文系统可有效扫描数据集中含有敏感信息的数据条目,初步证明了本文方法的有效性。
在此基础上,以信息查全率和敏感信息查准率为测试指标,对本文系统、社交网络敏感内容检测系统、无线局域网内敏感信息安全检索系统展开性能检测。
其中,信息查全率是指系统对其所感知的信息作出正确分类的样本数与信息实际样本数的比值,查全率越高,说明系统在敏感信息感知与预警过程中漏掉的样本数量越少,查全率计算式如式(2)。
(2)
其中,R表示信息查全率;n表示信息分类正确的数量;N表示信息的实际数量。
敏感信息查准率表示不同系统对敏感信息的正确判断数量与实际敏感信息数量的比值,计算式如式(3)。
(3)
其中,P表示敏感信息查准率;m表示分类正确的敏感信息数量;M表示敏感信息的实际数量。
2.2 不同词向量维度下查全率对比分析结果
实验中利用word2vec实现词向量化,然后统计本文系统、社交网络敏感内容检测系统、无线局域网内敏感信息安全检索系统的信息查全率,实验结果如表4所示。
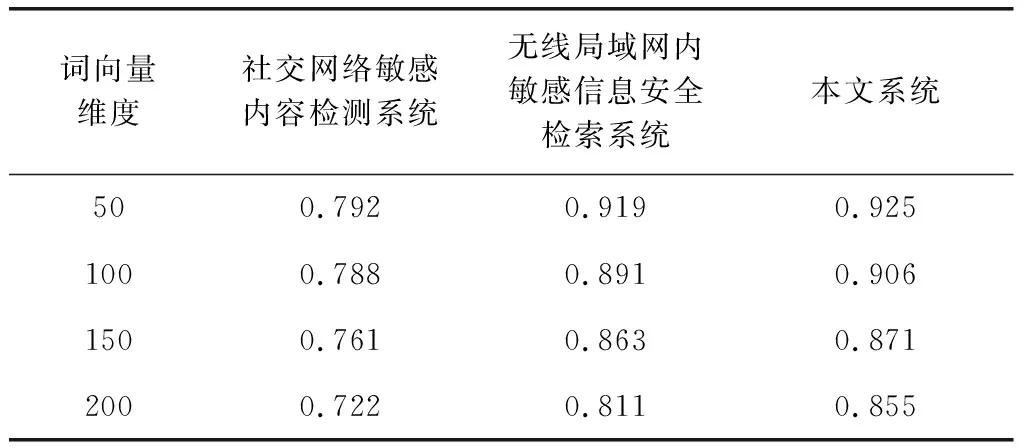
表4 不同词向量维度下不同系统查全率对比
分析表4所示的查全率结果可知,随着词向量维度的增加,3个系统的查全率均有所下降。但是根据3个系统之间横向比较可以看出,相对于2个传统系统,本文系统的查全率更高。
2.3 不同词向量维度下查准率对比分析结果
在对比分析不同系统的信息查全率的基础上,统计不同系统的敏感信息查准率,结果如表5所示。
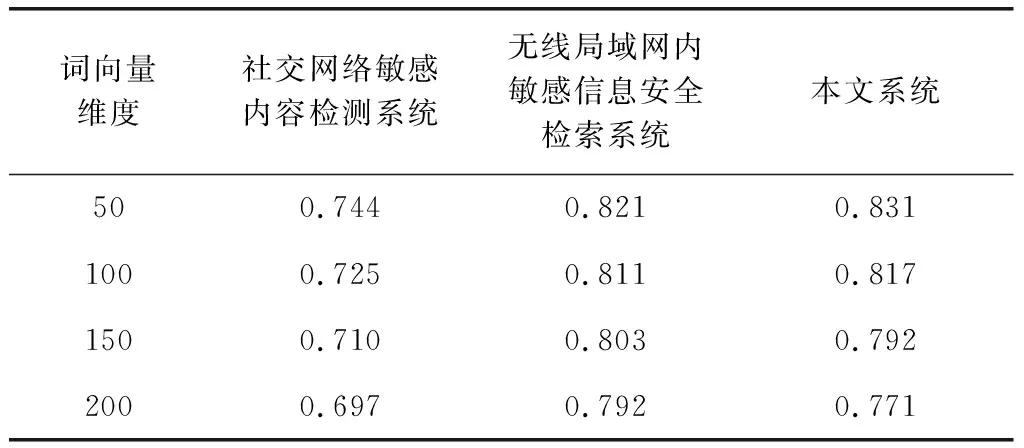
表5 不同词向量维度下不同系统查准率对比
分析表5所示的查准率结果可知,随着词向量维度的增加,3个系统的查准率均有所降低。通过3个系统之间横向比较可以看出,本文系统在词向量维度较高时的查准率略低于无线局域网内敏感信息安全检索系统,但始终高于社交网络敏感内容检测系统。
为了综合考量信息查全率和敏感信息查准率,应用求商比较法全面反映系统性能,其计算过程如式(4)。
(4)
经过计算,在不同词向量维度下,本文系统的平均F值为0.844,无线局域网内敏感信息安全检索系统的平均F值为0.835。因此,本文方法的综合性能更优。
对于本文要解决的生活号敏感内容感知与预警的问题,应该保守地进行敏感内容的识别,因此要在能够保证F值的情况下,获得更高的R值,系统在现实应用中的效果才能更好。
3 总结
互联网的普及促进了一些自媒体生活号的发展,一些自媒体生活号在发布内容时会带有一些敏感信息。敏感信息的泄露不仅会造成巨大的资源损失,对于一些未成年人的身心成长也具有一定的消极影响。针对这种隐藏的威胁,敏感内容感知预警系统能够有效地对敏感内容进行检测。本文主要从软件方面进行设计,将机器学习技术作为主体,结合卷积神经网络模型对敏感信息进行归类辨识,有效地提高了不同词向量维度下的识别精度。
